提高泛化能力的方法
数据增强
所谓数据增强,就是样本数据有限的情况下,通过对样本图像进行平移、旋转或者镜像翻转等方式进行变换,来得到更多新的样本。
除此之外,变换方式还包括几何变换、对比度变换、颜色变换、添加随机噪声以及图像模糊等。
在对图像进行平移或旋转处理时,可能会出现样本偏离图像区域的情况,需要特别注意。
例如:使用ImageNet数据集的样本进行物体识别时,如下图所示,把原始样本的中央区域设定为感兴趣区域后,可以对该区域进行偏移或旋转,像这样进行图像变换可以防止变换后的样本偏离图像区域。

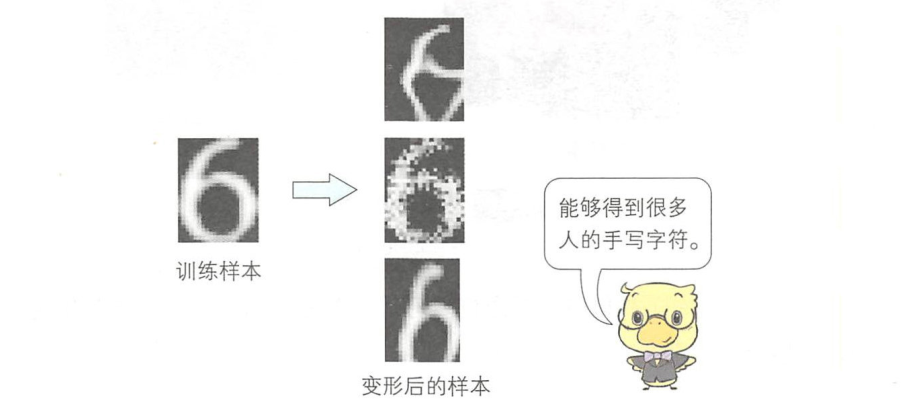
对于手写字符识别等样本会产生形状变化的情况,可以先改变其形状(变形)再进行数据增强。
变形方法可以使用弹性变换算法( elasticdistortion ) 。弹性变换算法可以使用双线性插值( bilinear interpolation)或双三次插值( bicubic interpolation)等插值法,处理流程如下图所示:
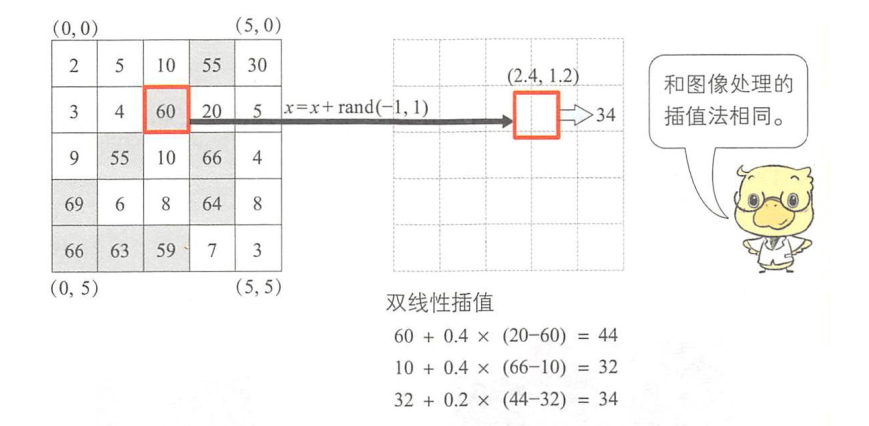
首先选取感兴趣像素(2,1),并使用随机数确定移动量。这里假设移动范围为±l。因为移动量是实数,所以我们假设感兴趣像素移动后的新位置为(2.4,1.2)。根据(x,y)位置周围像素点的像素值进行双线性插值,就可以得到(x,y)的像素值。对全部像素进行相同处理后,就可以对原始样本添加手写字符中可能会出现的形状变化,如下图:
预处理
均值减法
大规模的物体识别经常使用均值减法进行预处理。如下图所示计算所有训练样本的均值图像时,可使用下述公式:
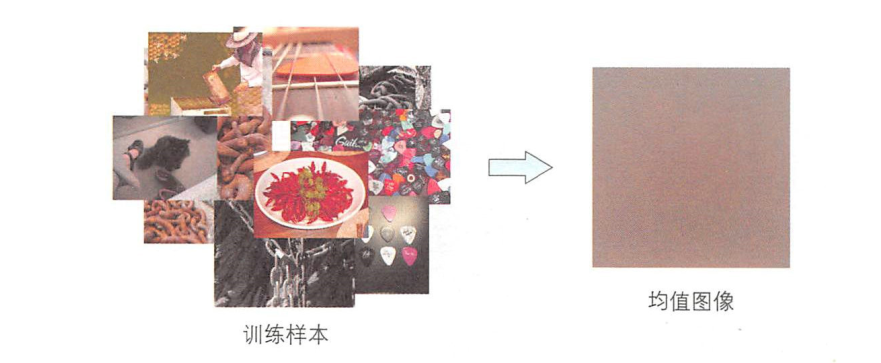
然后,训练样本和均值图像相减可得到差分图像 \(\bar{x}\) ,这里将其作为样本数据输入网络,
这样一来,各数据的平均值就会变为零,图像整体的亮度变化就能得到抑制。如下图所示:

均一化
均一化( normalization)是为样本的均值和方差添加约束的一种预处理方法。
均值减法是使各数据的均值为零,而均一化是将方差设为1以减少样本数据的波动。
首先计算各数据的标准差\(\sigma _i\):
然后对样本图像进行均值减法后,再除以标准差:
这样就能得到均值为0、方差为1的标准化数据。
对物体识别使用的CIFAR-10数据集中的图像进行均一化处理后,结果如下图所示。

可见,和只进行均值减法时相比,均一化处理后的图像之间亮度差异更小。
白化
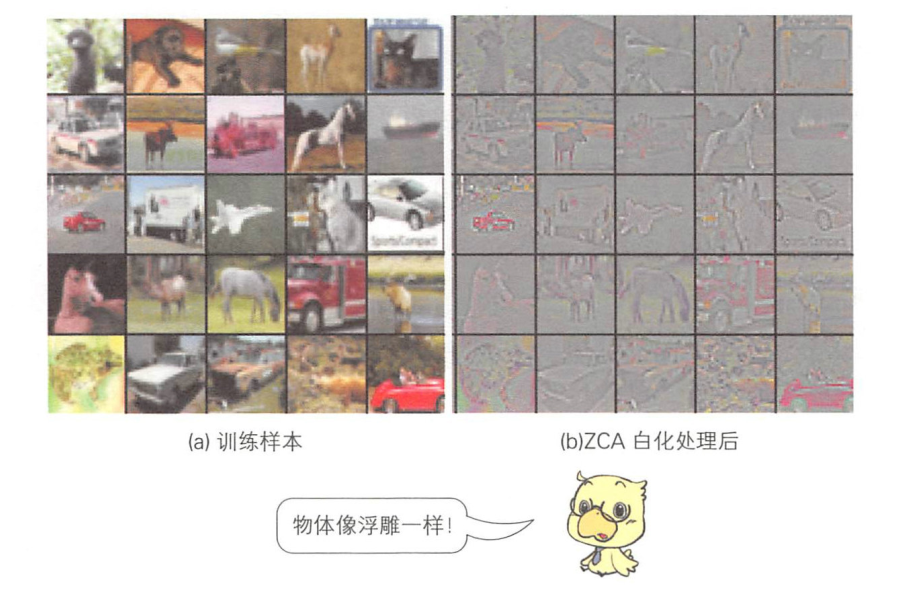
白化( whitening)是一种消除数据间相关性的方法。
经过白化处理后,数据之间相关性较低,图像边缘增强。这样就可以消除直流分量等相关性较高的像素的信息,只保留边缘等相关性较低的像素。像这样提取图像特征,能够提高图像识别性能。
Dropout
Dropout是由辛顿等人提出的一种提高网络泛化能力的方法。
过拟合问题是神经网络中的常见问题。在20世纪80年代至20世纪90年代神经网络的鼎盛时期,用来训练神经网络的数据量远不及现在多。如果训练时使用的数据过少,那么神经网络的训练会比较简单,对训练数据的识别准确率接近于100%,但也会出现对测试数据的识别性能较差的情况。
过拟合指的就是能够很好地拟合训练数据,却不能很好地拟合测试数据的现象。
当处于过拟合状态时,神经网络就无法发挥其巨大的潜能。
这些年,人们提出了很多方案去解决过拟合问题,其中一种就是Dropout。所谓Dropout,是指在网络的训练过程中,按照一定的概率将一部分中间层的单元暂时从网络中丢弃,通过把该单元的输出设置为О使其不工作,来避免过拟合。
Dropout可用于训练包含全连接层的神经网络。神经网络的训练过程就是对每个Mini-Batch 使用误差反向传播算法不断迭代调整各参数的值,而 Dropout就是在每次迭代调整时,随机选取一部分单元将其输出设置为0。
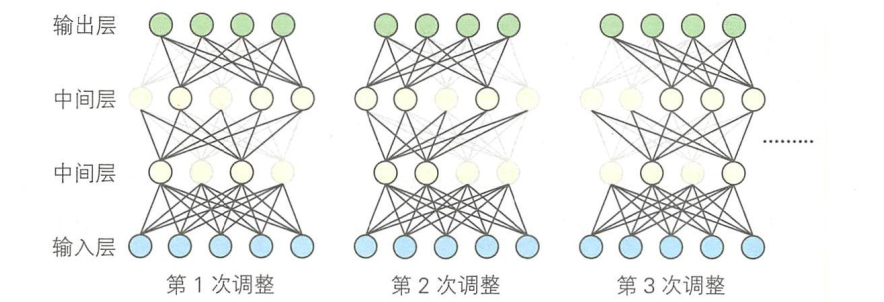
计算误差时原本是使用所有单元的输出值,但是由于有部分单元被丢弃,所以从结果来看,Dropout起到了与均一化方法类似的作用。
但是,对被舍弃的单元进行误差反向传播计算时,仍要使用被舍弃之前的原始输出值。
Dropout的概率通常会设置为50%,即单元输出值有50%的概率被设置为0。但这个数值并非绝对,也可以不同层使用不同的舍弃概率,有事例显示这样也能提高性能。自Dropout被提出以来,人们已通过各种基准测试证明了其有效性,它已经成为深度学习中不可或缺的一种技术。
利用训练好的网络进行识别时,需要输入样本并进行正向传播,此时进行过Dropout处理的层,其输出值需要在原始输出的基础上乘以训练时使用的 Dropout概率。
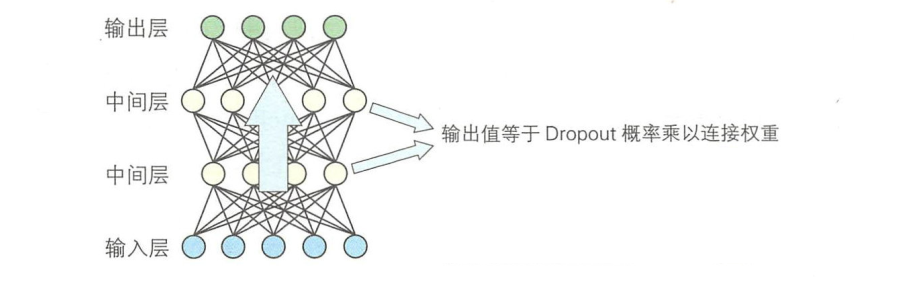
虽然训练时网络通过Dropout舍弃了一定概率的单元,但是在识别时仍要使用所有单元。所以,有输出值的单元个数会增加 Dropout概率的倒数倍。由于单元之间通过权重系数相连接,所以这里还需要乘以 Dropout的概率。像这样对网络进行参数约束后仍然能训练出合理的网络,这就达到了抑制过拟合的目的。
DropConnect
和 Dropout一样,DropConnect也是通过舍弃一部分单元来防止过拟合问题的方法。
Dropout是把单元的输出值设置为0,而DropConnect是把一部分连接权重设置为0。
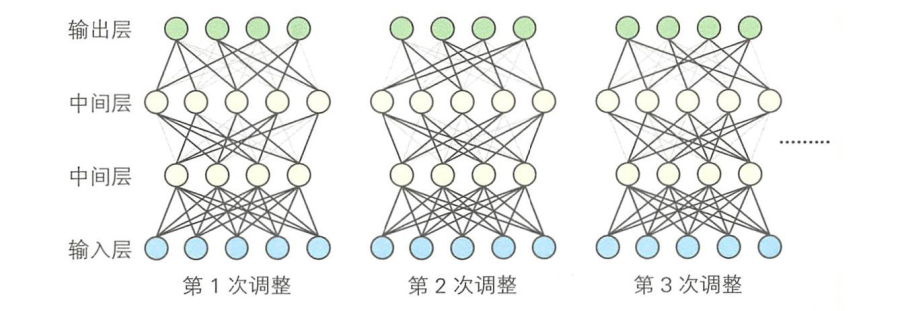
下图显示了使用MNIST数据集进行训练和测试时的误差变化情况。
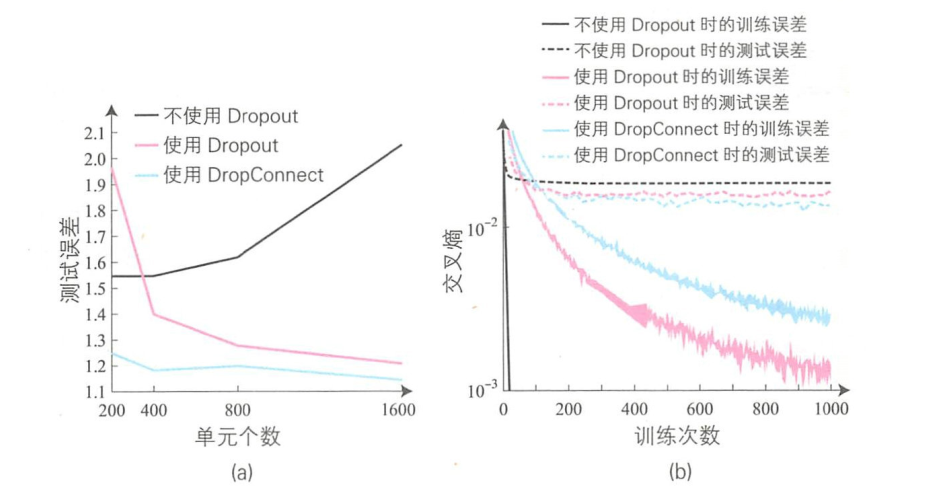
图(a)是针对不使用Dropout、使用 Dropout、使用 DropConnect这三种情况下,测试误差随着中间层单元个数的推移而变化的趋势。这里的神经网络有两个中间层。不使用 Dropout时,如果选取的单元个数太多,测试误差就会上升。这是由于训练数据过多导致了过拟合。
使用Dropout时,测试误差先是随着单元个数的增加而急剧下降,而当单元个数达到400后,下降速度逐渐缓慢。
使用DropConnect时,即使单元个数只有200,测试误差也低于使用Dropout时的情况。并且这种情况下,单元个数增多时,测试误差也不会发生太大变化,单元个数较少时也能得到很好的识别性能。
图(b)显示了训练误差和测试误差随着训练次数的推移而变化的趋势。
不使用Dropout时,训练误差在很早的阶段就开始下降,但是测试误差一直很大且没有显著变化。从这个结果也能看出这里发生了过拟合问题。
使用Dropout时的训练误差要小于使用DropConnect时的,但是测试误差则比使用DropConnect时的要稍微高一些。使用DropConnect时,由于连接权重设置为0,所以被舍弃单元的组合数远大于使用Dropout时的。
因此,相比 Dropout,使用 DropConnect 时更不容易发生过拟合。
虽然 DropConnect的识别性能优于Dropout,但是其训练难度也高于Dropout。DropConnect是随机将单元的连接权重设置为0的,如果随机数的生成方法不同,就很难得到相同的识别性能,这是 DropConnect的一个主要问题。所以现在人们更多使用的是 Dropout,因为它对随机数的依赖性比较低。
对于深度学习中提高泛化能力的方法来说,重要的并不只是算法,还有训练样本。收集海量的训练样本非常困难,最方便的做法是使用ImageNet和 Places等公开的数据集。除了使用这些数据集,通过预处理抑制样本各类别内的变动也非常重要。另外在算法方面,我们还可以使用Dropout和 DropConnect,这些都是能够有效防止过拟合问题的方法,也是当前深度学习中必不可少的技术。
参考: [1]图解深度学习/(日)山下隆义著;张弥译.--北京:人民邮电出版社,2018.5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号