聚合函数
准备数据
创建 customers 表:
CREATE TABLE customers (
id INT PRIMARY KEY,
customer_id INT,
customer_name VARCHAR(50)
);
插入数据到 customers 表:
INSERT INTO customers (id, customer_id, customer_name)
VALUES
(1,0001,'John'),
(2,0010, 'Jane'),
(3,0011, 'Smith'),
(4,0100, 'Michael'),
(5,0101, NULL),
(6,NULL, 'JACK'),
(7,0111, 'Sarah');
创建 orders 表:
CREATE TABLE orders (
id INT PRIMARY KEY,
order_id INT,
customer_id INT,
order_date DATE,
amount DECIMAL(10, 2)
);
插入数据到 orders 表:
INSERT INTO orders (id, order_id, customer_id, order_date, amount)
VALUES
(1, 1,0001, '2023-01-01', 100.00),
(2, 1,0010, '2023-02-01', 150.00),
(3, 2,1001, '2023-03-01', 200.00),
(4, 3,0011, NULL, 50.00),
(5, 4,NULL, '2023-04-01', NULL),
(6, NULL,NULL, NULL, NULL);
mysql> select * from customers;
+----+-------------+---------------+
| id | customer_id | customer_name |
+----+-------------+---------------+
| 1 | 1 | John |
| 2 | 10 | Jane |
| 3 | 11 | Smith |
| 4 | 100 | Michael |
| 5 | 101 | NULL |
| 6 | NULL | JACK |
| 7 | 111 | Sarah |
+----+-------------+---------------+
7 rows in set (0.00 sec)
mysql> select * from orders;
+----+----------+-------------+------------+--------+
| id | order_id | customer_id | order_date | amount |
+----+----------+-------------+------------+--------+
| 1 | 1 | 1 | 2023-01-01 | 100.00 |
| 2 | 1 | 10 | 2023-02-01 | 150.00 |
| 3 | 2 | 1001 | 2023-03-01 | 200.00 |
| 4 | 3 | 11 | NULL | 50.00 |
| 5 | 4 | NULL | 2023-04-01 | NULL |
| 6 | NULL | NULL | NULL | NULL |
+----+----------+-------------+------------+--------+
6 rows in set (0.00 sec)
聚合函数
AVG和SUM函数
可以对
mysql> SELECT * FROM orders;
+----+----------+-------------+------------+--------+
| id | order_id | customer_id | order_date | amount |
+----+----------+-------------+------------+--------+
| 1 | 1 | 1 | 2023-01-01 | 100.00 |
| 2 | 1 | 10 | 2023-02-01 | 150.00 |
| 3 | 2 | 1001 | 2023-03-01 | 200.00 |
| 4 | 3 | 11 | NULL | 50.00 |
| 5 | 4 | NULL | 2023-04-01 | NULL |
| 6 | NULL | NULL | NULL | NULL |
+----+----------+-------------+------------+--------+
6 rows in set (0.00 sec)
mysql> SELECT AVG(amount), SUM(amount) FROM orders;
+-------------+-------------+
| AVG(amount) | SUM(amount) |
+-------------+-------------+
| 125.000000 | 500.00 |
+-------------+-------------+
1 row in set (0.00 sec)
MIN和MAX函数
可以对
mysql> SELECT * FROM orders;
+----+----------+-------------+------------+--------+
| id | order_id | customer_id | order_date | amount |
+----+----------+-------------+------------+--------+
| 1 | 1 | 1 | 2023-01-01 | 100.00 |
| 2 | 1 | 10 | 2023-02-01 | 150.00 |
| 3 | 2 | 1001 | 2023-03-01 | 200.00 |
| 4 | 3 | 11 | NULL | 50.00 |
| 5 | 4 | NULL | 2023-04-01 | NULL |
| 6 | NULL | NULL | NULL | NULL |
+----+----------+-------------+------------+--------+
6 rows in set (0.00 sec)
mysql> SELECT * FROM customers;
+----+-------------+---------------+
| id | customer_id | customer_name |
+----+-------------+---------------+
| 1 | 1 | John |
| 2 | 10 | Jane |
| 3 | 11 | Smith |
| 4 | 100 | Michael |
| 5 | 101 | NULL |
| 6 | NULL | JACK |
| 7 | 111 | Sarah |
+----+-------------+---------------+
7 rows in set (0.00 sec)
mysql> SELECT MAX(amount), MIN(amount), MAX(order_date), MIN(order_date) FROM orders;
+-------------+-------------+-----------------+-----------------+
| MAX(amount) | MIN(amount) | MAX(order_date) | MIN(order_date) |
+-------------+-------------+-----------------+-----------------+
| 200.00 | 50.00 | 2023-04-01 | 2023-01-01 |
+-------------+-------------+-----------------+-----------------+
1 row in set (0.00 sec)
mysql> SELECT MAX(customer_name),MIN(customer_name) FROM customers;
+--------------------+--------------------+
| MAX(customer_name) | MIN(customer_name) |
+--------------------+--------------------+
| Smith | JACK |
+--------------------+--------------------+
1 row in set (0.00 sec)
COUNT函数
COUNT(*)返回表中记录总数,适用于任意数据类型 。COUNT(字段) 返回字段不为空的记录总数 。
mysql> SELECT * FROM orders;
+----+----------+-------------+------------+--------+
| id | order_id | customer_id | order_date | amount |
+----+----------+-------------+------------+--------+
| 1 | 1 | 1 | 2023-01-01 | 100.00 |
| 2 | 1 | 10 | 2023-02-01 | 150.00 |
| 3 | 2 | 1001 | 2023-03-01 | 200.00 |
| 4 | 3 | 11 | NULL | 50.00 |
| 5 | 4 | NULL | 2023-04-01 | NULL |
| 6 | NULL | NULL | NULL | NULL |
+----+----------+-------------+------------+--------+
6 rows in set (0.00 sec)
mysql> SELECT AVG(amount), SUM(amount)/COUNT(amount),COUNT(amount),COUNT(1),COUNT(*), SUM(amount)/6 FROM orders;
+-------------+---------------------------+---------------+----------+----------+---------------+
| AVG(amount) | SUM(amount)/COUNT(amount) | COUNT(amount) | COUNT(1) | COUNT(*) | SUM(amount)/6 |
+-------------+---------------------------+---------------+----------+----------+---------------+
| 125.000000 | 125.000000 | 4 | 6 | 6 | 83.333333 |
+-------------+---------------------------+---------------+----------+----------+---------------+
1 row in set (0.00 sec)
-
问题:用count(*),count(1),count(列名)谁好呢?
其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。
Innodb引擎的表用count(*),count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。但好于具体的count(列名)。
-
问题:能不能使用count(列名)替换count(*)?
不要使用 count(列名)来替代
count(*),count(*)是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
GROUP BY
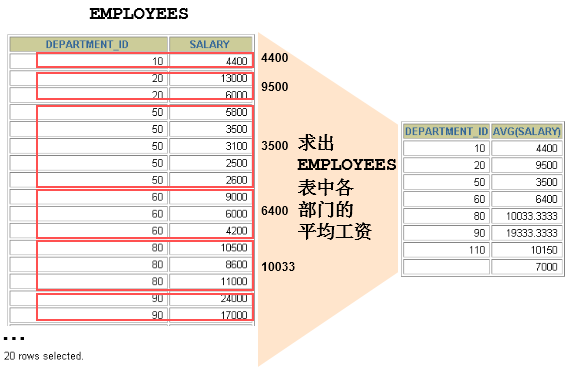
可以使用GROUP BY子句将表中的数据分成若干组
明确:WHERE一定放在FROM后面
mysql> SELECT * FROM orders;
+----+----------+-------------+------------+--------+
| id | order_id | customer_id | order_date | amount |
+----+----------+-------------+------------+--------+
| 1 | 1 | 1 | 2023-01-01 | 100.00 |
| 2 | 1 | 10 | 2023-02-01 | 150.00 |
| 3 | 2 | 1001 | 2023-03-01 | 200.00 |
| 4 | 3 | 11 | NULL | 50.00 |
| 5 | 4 | NULL | 2023-04-01 | NULL |
| 6 | NULL | NULL | NULL | NULL |
+----+----------+-------------+------------+--------+
6 rows in set (0.00 sec)
mysql> SELECT order_id,AVG(amount) FROM orders GROUP BY order_id;
+----------+-------------+
| order_id | AVG(amount) |
+----------+-------------+
| 1 | 125.000000 |
| 2 | 200.000000 |
| 3 | 50.000000 |
| 4 | NULL |
| NULL | NULL |
+----------+-------------+
5 rows in set (0.00 sec)
mysql> SELECT AVG(amount) FROM orders GROUP BY order_id;
+-------------+
| AVG(amount) |
+-------------+
| 125.000000 |
| 200.000000 |
| 50.000000 |
| NULL |
| NULL |
+-------------+
5 rows in set (0.00 sec)
HAVING
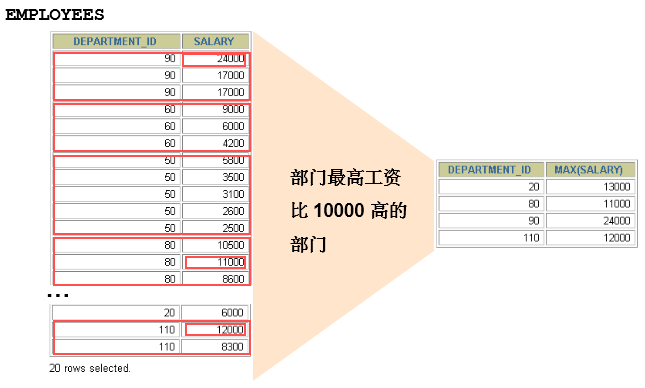
过滤分组:HAVING子句
- 行已经被分组。
- 使用了聚合函数。
- 满足HAVING 子句中条件的分组将被显示。
- HAVING 不能单独使用,必须要跟 GROUP BY 一起使用。
非法使用聚合函数 : 不能在 WHERE 子句中使用聚合函数。如果过滤条件中使用了聚合函数,则必须使用HAVING来代替WHERE,否则,报错
WHERE和HAVING的对比
区别1:WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。
这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为,在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成的。另外,WHERE排除的记录不再包括在分组中。
区别2:如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。 这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。
小结如下:
| 优点 | 缺点 | |
|---|---|---|
| WHERE | 先筛选数据再关联,执行效率高 | 不能使用分组中的计算函数进行筛选 |
| HAVING | 可以使用分组中的计算函数 | 在最后的结果集中进行筛选,执行效率较低 |
开发中的选择:
WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号