正则表达式
正则表达式(Regular Expression),又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
Regular Expression的“Regular”一般被译为“正则”、“正规”、“常规”。此处的“Regular”即是“规则”、“规律”的意思。
Regular Expression即“描述某种规则的表达式”之意。
匹配单个字符
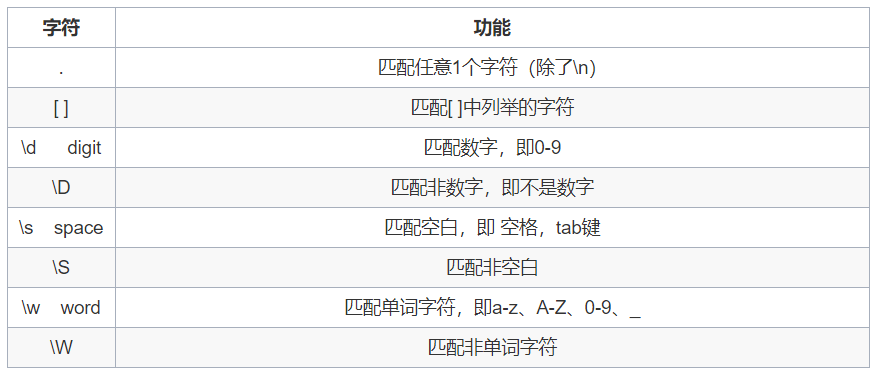
print(re.match(r"速度与激情\d","速度与激情8").group())
print(re.match(r"速度与激情\d","速度与激情8888").group())
输出:
速度与激情8
速度与激情8
print(re.match(r"速度与激情[12345678]","速度与激情8").group())
print(re.match(r"速度与激情[12345678]","速度与激情8888").group())
print(re.match(r"速度与激情[1-8]","速度与激情6").group()) # [1-8] 等价于 [12345678] ;[^1-8] 等价于不是1-8的字符
print(re.match(r"速度与激情[1-36-8]","速度与激情1").group()) # [1-36-8] 相当于剔除了4
print(re.match(r"速度与激情[1-8abc]","速度与激情a").group()) # [1-8abc] 也可以写成 [1-8a-c]
【注意:还有其他形式 [1-8a-zA-Z] 都是匹配其中的一个 相当于 \w(慎用)】
输出:
速度与激情8
速度与激情8
速度与激情6
速度与激情1
速度与激情a
print(re.match(r"速度与激情\d","速度与激情8").group())
print(re.match(r"速度与激情 \d","速度与激情 1").group())
print(re.match(r"速度与激情\s\d","速度与激情 1").group())
print(re.match(r"速度与激情\s\d","速度与激情\t1").group()) # \t 表示在电脑键盘上就是tab键
注意: \d 【只能匹配数字】,不能匹配字母等其他字符
输出:
速度与激情8
速度与激情 1
速度与激情 1
速度与激情 1
总结:
\d == [0-9]
\D == [^0-9]
\w == [a-zA-Z0-9_]
\W == [^a-zA-Z0-9_]
匹配多个字符
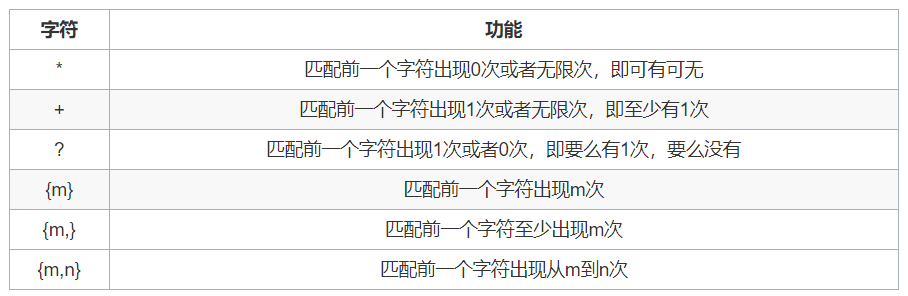
print(re.match(r"速度与激情\d\d","速度与激情88").group())
print(re.match(r"速度与激情\d\d","速度与激情8").group()) # \d 匹配数字 0-9
输出:
速度与激情88
程序报错,第二个 \d 没有可以匹配的字符
print(re.match(r"速度与激情\d{1,3}","速度与激情12").group())
print(re.match(r"速度与激情\d{1,3}","速度与激情112").group())
print(re.match(r"速度与激情\d{3}","速度与激情1222").group())
print(re.match(r"速度与激情\d{1,3}","速度与激情2").group())
print(re.match(r"速度与激情a{3}","速度与激情aaaa").group())
说明:\d{1,3} 表示限制前面那位可以匹配的个数。该表达式表示限制 \d 可以匹配1个到3个【数字】
\d{3} 表示限制前面那位【只可以】匹配的3个数
a{3} 表示只匹配三个a
输出:
速度与激情12
速度与激情112
速度与激情122
速度与激情2
速度与激情aaa
print(re.match(r"021-\d{8}","021-12345678").group())
print(re.match(r"021-?\d{8}","02112345678").group())
print(re.match(r"021-?\d{8}","021-12345678").group())
说明:? 表示前面一位可有可无
输出:
021-12345678
02112345678
021-12345678
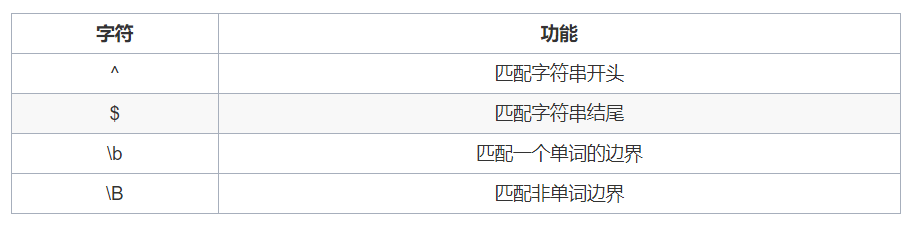
匹配开头结尾
匹配分组
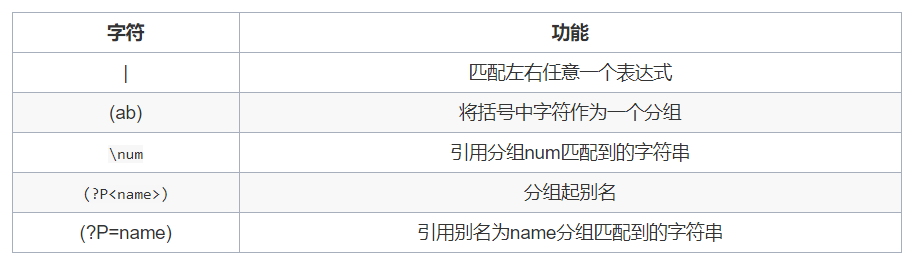
import re
【 \w 匹配单词字符,即a-z、A-Z、0-9、_ 】
html_str1 = "<h1>hahaha</h1>"
print(re.match(r"<\w*>.*</\w*>",html_str1).group())
html_str2 = "<h1>hahaha</>"
print(re.match(r"<\w*>.*</\w*>",html_str2).group())
html_str3 = "<body><h1>hahaha</h1></body>"
print(re.match(r"<(\w*)><(\w*)>.*</\2></\1>",html_str3).group())
html_str4 = "<body><h1>hahaha</h1></body>"
print(re.match(r"<(?P<p1>\w*)><(?P<p2>\w*)>.*</(?P=p2)></(?P=p1)>",html_str4).group())
"""
<( ?P<p1> \w* )> <( ?P<p2> \w* )> .* </ (?P=p2) ></ (?P=p1) >
命名p1 命名p2 使用p2 使用p1
"""
输出:
<h1>hahaha</h1>
<h1>hahaha</>
<body><h1>hahaha</h1></body>
<body><h1>hahaha</h1></body>
result = re.match(r"(<h1>).*(</h1>)","<h1>匹配分组</h1>")
result.group(1) # 输出: '<h1>'
result.group(2) # 输出: '</h1>'
result.group(0) # 输出: '<h1>匹配分组</h1>'
result.groups() # 输出: ('<h1>','</h1>')
result.groups()[0] # 输出: '<h1>'
re模块的高级用法
1、 re.compile(pattern, flags = 0):(编译)
该函数用于将正则表达式编译成_sre.SRE_Pattern 对象,该对象代表了正则表达式编译之后在内存中的对象,它可以缓存并复用正则表达式。如果程序需要多次使用同一个正则表达式字符串,则可以考虑先编译它,具有更好的性能
2、 re.match(pattern, string, flags = 0):(从头找一个)
尝试从字符串开始的位置来匹配正则表达式,如果从开始位置匹配不成功,match()函数就返回None。其中pattern参数代表正则表达式;string代表被匹配的字符串;flags代表正则表达式的匹配旗标。函数返回_sre.SRE_Match对象
import re
m1 = re.match('www', 'www.fkit.org') # 开始位置可以匹配
print(m1.span()) # (0, 3) span返回匹配的位置
print(m1.group()) # www group返回匹配的组
print(re.match('fkit', 'www.fkit.com')) # 开始位置匹配不到,返回 None
pattern = re.compile(r'\d+') # 用于匹配至少一个数字
m = pattern.match('one12twothree34four') # 查找头部,没有匹配
print (m) # 输出:None
m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
print (m) # 输出:None
m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
print (m) # 返回一个 Match 对象 输出:<_sre.SRE_Match object at 0x10a42aac0>
m.group(0) # 可省略 0 输出:'12'
m.start(0) # 可省略 0 输出:3
m.end(0) # 可省略 0 输出:5
m.span(0) # 可省略 0 输出:(3, 5)
3、 re.search(pattern, string, flags = 0): (扫描整个字符串,找第一个)
扫描整个字符串,并返回字符串中第一处匹配pattern的匹配对象。不用从头匹配,成功即可。函数返回_sre.SRE_Match对象
import re
m2 = re.search('www', 'www.fkit.org') # 扫描整个字符串
print(m2.span()) # (0, 3)
print(m2.group()) # www
m3 = re.search('fkit', 'www.fkit.com') # 中间位置可以匹配,返回Match对象
print(m3.span()) # (4, 8)
print(m3.group()) # fkit
>>> import re
>>> pattern = re.compile('\d+')
>>> m = pattern.search('one12twothree34four') # 这里如果使用 match 方法则不匹配
>>> m
<_sre.SRE_Match object at 0x10cc03ac0>
>>> m.group()
'12'
>>> m = pattern.search('one12twothree34four', 10, 30) # 指定字符串区间
>>> m
<_sre.SRE_Match object at 0x10cc03b28>
>>> m.group()
'34'
>>> m.span()
(13, 15)
4、 re.findall(pattern, string, flags = 0): (扫描整个字符串,找所有)
扫描整个字符串,并返回字符串中所有匹配pattern的子串组成的列表
import re
# 返回所有匹配pattern的子串组成的列表, 忽略大小写
print(re.findall('fkit', 'FkIt is very good , Fkit.org is my favorite' , re.I))
输出:
['FkIt', 'Fkit']
import re
pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('hello 123456 789')
result2 = pattern.findall('one1two2three3four4', 0, 10)
print (result1)
print (result2)
输出:
['123456', '789']
['1', '2']
5、 re.finditer(pattern, string, flags = 0):
扫描整个字符串,并返回字符串中所有匹配pattern的子串组成的迭代器,迭代器对象是_sre.SRE_Match对象
import re
# 返回所有匹配pattern的子串组成的迭代器, 忽略大小写
it = re.finditer('fkit', 'FkIt is very good , Fkit.org is my favorite' , re.I)
for e in it:
print(str(e.start()) + "-->" + e.group())
输出:
0-->FkIt
20-->Fkit
import re
pattern = re.compile(r'\d+')
result_iter1 = pattern.finditer('hello 123456 789')
result_iter2 = pattern.finditer('one1two2three3four4', 0, 10)
print (type(result_iter1))
print (type(result_iter2))
print 'result1...'
for m1 in result_iter1: # m1 是 Match 对象
print ('matching string: {}, position: {}'.format(m1.group(), m1.span()))
print 'result2...'
for m2 in result_iter2:
print ('matching string: {}, position: {}'.format(m2.group(), m2.span()))
输出:
<type 'callable-iterator'>
<type 'callable-iterator'>
result1...
matching string: 123456, position: (6, 12)
matching string: 789, position: (13, 16)
result2...
matching string: 1, position: (3, 4)
matching string: 2, position: (7, 8)
6、 re.fullmatch(pattern, string, flags = 0):
该函数要求整个字符串能匹配pattern,如果匹配则返回 匹配信息的_sre.SRE_Match对象,否则返回None
7、 re.sub(pattern, repl, string, count = 0, flags = 0):
该函数用于将string字符串中所有匹配pattern的内容替换成repl,repl即可是被替换的字符串,也可是一个函数,count参数控制最多替换多少次,如果指定count为0,则表示全部替换
import re
my_date = '2008-08-18'
# 将my_date字符串里中画线替换成斜线
print(re.sub(r'-', '/', my_date))
# 将my_date字符串里中画线替换成斜线,只替换一次
print(re.sub(r'-', '/', my_date, 1))
# 在匹配的字符串前后添加内容
def fun(matched):
# matched就是匹配对象,通过该对象的group()方法可获取被匹配的字符串
value = "《疯狂" + (matched.group('lang')) + "讲义》"
return value
s = 'Python很好,Kotlin也很好'
# 将s里面的英文单词(用re.A旗标控制)进行替换
# 使用fun函数指定替换的内容
print(re.sub(r'(?P<lang>\w+)', fun, s, flags=re.A))
指定re.A选项,这样“\w”就只能代表ASCII字符,不能代表汉字
输出:
2008/08/18
2008/08-18
《疯狂Python讲义》很好,《疯狂Kotlin讲义》也很好
8、 re.split(pattern, string, maxsplit = 0, flags = 0):
使用pattern对string进行分割,该函数返回分割得到的多个子串组成的列表。其中maxsplit参数控制最多分割几次
# 使用逗号对字符串进行分割
print(re.split(', ', 'fkit, fkjava, crazyit'))
# 输出:['fkit', 'fkjava', 'crazyit']
# 指定只分割1次,被切分成2个子串
print(re.split(', ', 'fkit, fkjava, crazyit', 1))
# 输出:['fkit', 'fkjava, crazyit']
# 使用a进行分割
print(re.split('a', 'fkit, fkjava, crazyit'))
# 输出:['fkit, fkj', 'v', ', cr', 'zyit']
# 使用x进行分割,没有匹配内容,则不会执行分割
print(re.split('x', 'fkit, fkjava, crazyit'))
# 输出:['fkit, fkjava, crazyit']
需求:切割字符串“info:xiaoZhang 33 shandong”
#coding=utf-8
import re
ret = re.split(r":| ","info:xiaoZhang 33 shandong") # 按分号 :和 空格 切割
print(ret)
运行结果:
['info', 'xiaoZhang', '33', 'shandong']
9、 re.purge():
清除正则表达式缓存
10、 re.escape(pattern):
对模式中除了ASCII字符、数值、下划线(_)之外的其他字符进行转义。
import re
# 对模式中特殊字符进行转义
print(re.escape(r'www.crazyit.org is good, i love it!'))
# 输出:www\.crazyit\.org\ is\ good\,\ i\ love\ it\!
print(re.escape(r'A-Zand0-9?'))
# 输出:A\-Zand0\-9\?
re模块中含有两个类,他们分别是正则表达式对象(其具体类型为_sre.SRE_Pattern)和匹配(Match)对象,其中正则表达式对象就是调用re.compile()函数的返回值。
正则表达式对象的search()、match()、fullmatch()、findall()、finditer()方法的功能更加强大,因为这些方法可以额外指定pos和endpos两个参数,用于指定只处理目标字符串从pos开始到endpos结束之间的子串
_sre.SRE_Match对象包含了如下方法或属性:- match.group([group1,...]):获取该匹配对象中指定组所匹配的字符串
- match.getiem(g):这是match.group(g)简化写法。由于match对象提供了__getiem__()方法,因此程序可以使用match[g]来代替match.group(g)
- match.groups(default=None):返回match对象中所有组所匹配的字符串组成的元组
- match.groupdict(default=None):返回match对象中所有组所匹配的字符串组成的字典
- match.start([group]):获取该匹配对象中指定组所匹配的字符串的开始位置
- match.end([group]):获取该匹配对象中指定组所匹配的字符串的结束位置
- match.span([group]):获取该匹配对象中指定组所匹配的字符串的开始位置和结束位置
import re
# 在正则表达式中使用组
m = re.search(r'(fkit).(org)', r"www.fkit.org is a good domain")
print(m.group(0)) # fkit.org
# 调用简化写法,底层是调用m.__getitem__(0)
print(m[0]) # fkit.org
print(m.span(0)) # (4, 12)
print(m.group(1)) # fkit
# 调用简化写法,底层是调用m.__getitem__(1)
print(m[1]) # fkit
print(m.span(1)) # (4, 8)
print(m.group(2)) # org
# 调用简化写法,底层是调用m.__getitem__(2)
print(m[2]) # org
print(m.span(2)) # (9, 12)
# 返回所有组所匹配的字符串组成的元组
print(m.groups())
# 正则表达式定义了2个组,并为组指定了名字
m2 = re.search(r'(?P<prefix>fkit).(?P<suffix>org)', \
r"www.fkit.org is a good domain")
print(m2.groupdict()) # {'prefix': 'fkit', 'suffix': 'org'}
正则表达式旗标
Python支持的正则表达式旗标都使用该模块中的属性来表达:
- re.A或re.ASCII:该旗标控制\w、\W、\b、\B、\d、\D、\s、\S只匹配ASCII字符,而不匹配所有的Unicode字符。也可以在正则表达式中使用(?a)行内旗标代表
- re.DEBUG:显示编译正则表达式的debug信息。 没有行内旗标
- re.I 或 re.IGNORECASE:使用正则表达式匹配时不区分大小写。对应正则表达式中的(?i)行内旗标
- re.L 或 re.LOCALE:根据当前区域设置使用正则表达式匹配时不区分大小写。该旗标只能对 bytes 模式起作用,对应正则表达式中的(?L)行内旗标
- re.M 或 re.MULTILINE :多行模式的旗标。当指定该旗标后,“^”能匹配字符串的开头和每行的开头(紧跟 每一个换行符的后面);“\(”能匹配字符串的末尾和每行的末尾(在每一个换行符之前)。在默认情况下,“^”只能匹配字符串的开头,“\)”只能匹配字符串的结尾或者匹配到字符串默认的换行符(如果有)之前。对应于正则表达式中的(?m)行内旗标。
- re.S 或 re.DOTALL:让点(.)能够匹配包括换行符在内的所有字符(默认点是不能匹配换行符的)。对应正则表达式中的(?s)行内旗标。
- re.U 或 re.Unicode:该旗标控制\w、\W、\b、\B、\d、\D、\s、\S能匹配所有的Unicode字符。但是,这个旗标对Python3.0是多余,Python3.0默认就是匹配所有的Unicode字符
- re.X 或 re.VERBOSE:通过该旗标允许分行书写正则表达式,也允许为正则表达式添加注释,提高可读性。对应正则表达式中的(?x)行内旗标。
贪婪与非贪婪
贪婪 :总是尝试匹配尽可能多的字符;
**非贪婪 ** :总是尝试匹配尽可能少的字符。
解决方式:非贪婪操作符“?”,这个操作符可以用在"*","+","?"的后面,要求正则匹配的越少越好。
>>> s="This is a number 234-235-22-423"
>>> r=re.match(".+(\d+-\d+-\d+-\d+)",s)
>>> r.group(1)
'4-235-22-423'
>>> r=re.match(".+?(\d+-\d+-\d+-\d+)",s)
>>> r.group(1)
'234-235-22-423'
>>> re.match(r"aa(\d+)","aa2343ddd").group(1)
'2343'
>>> re.match(r"aa(\d+?)","aa2343ddd").group(1)
'2'
>>> re.match(r"aa(\d+)ddd","aa2343ddd").group(1)
'2343'
>>> re.match(r"aa(\d+?)ddd","aa2343ddd").group(1) # 【先满足 aa 和 bbb 】
'2343'
使用贪婪的数量词的正则表达式 ab* ,匹配结果: abbb。
决定了尽可能多匹配 b,所以a后面所有的 b 都出现了。
使用非贪婪的数量词的正则表达式ab*?,匹配结果: a。
即使前面有 *,但是 ? 决定了尽可能少匹配 b,所以没有 b。
匹配网址
有一批网址:
http: // www.interoem.com/messageinfo.asp?id=35
http: // 3995503.com/class/class09/news_show.asp?id=14
http: // lib.wzmc.edu.cn/news/onews.asp?id=769
http: // www.zy-ls.com/alfx.asp?newsid=377&id=6
http: // www.fincm.com/newslist.asp?id=415
需要 正则后为:
http: // www.interoem.com/
http: // 3995503.com/
http: // lib.wzmc.edu.cn/
http: // www.zy-ls.com/
http: // www.fincm.com/
import re
html_str = """
http://www.interoem.com/messageinfo.asp?id=35
http://3995503.com/class/class09/news_show.asp?id=14
http://lib.wzmc.edu.cn/news/onews.asp?id=769
http://www.zy-ls.com/alfx.asp?newsid=377&id=6
http://www.fincm.com/newslist.asp?id=415
"""
ret = re.sub(r"(http://.+?/).*",lambda x:x.group(1),html_str)
print(ret)
输出:
http://www.interoem.com/
http://3995503.com/
http://lib.wzmc.edu.cn/
http://www.zy-ls.com/
http://www.fincm.com/
匹配中文
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在 [u4e00-u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
假设现在想把字符串 title = u'你好,hello,世界' 中的中文提取出来,可以这么做:
注意到,在正则表达式前面加上了两个前缀 ur,其中 r 表示使用原始字符串,u 表示是 unicode 字符串。
import re
title = '你好,hello,世界'
pattern = re.compile(r'[\u4e00-\u9fa5]+')
result = pattern.findall(title)
print (result)
输出:
['你好', '世界']
正则在线测试工具
在线正则表达式测试 :https://tool.oschina.net/regex/
regex101 :https://regex101.com/
Regulex :https://jex.im/regulex/#!flags=&re=^(a|b)*%3F%24

 浙公网安备 33010602011771号
浙公网安备 33010602011771号