XPath
什么是XPath
XPath (XML Path Language) 是一门在 HTML\XML 文档中查找信息的语言,
可用来在 HTML\XML 文档中对元素和属性进行遍历。
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
节点选择语法

查找某个特定的节点或者包含某个指定的值的节点
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De</author>
<year>2005</year>
<price>30.0</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning xpath</title>
<author>Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
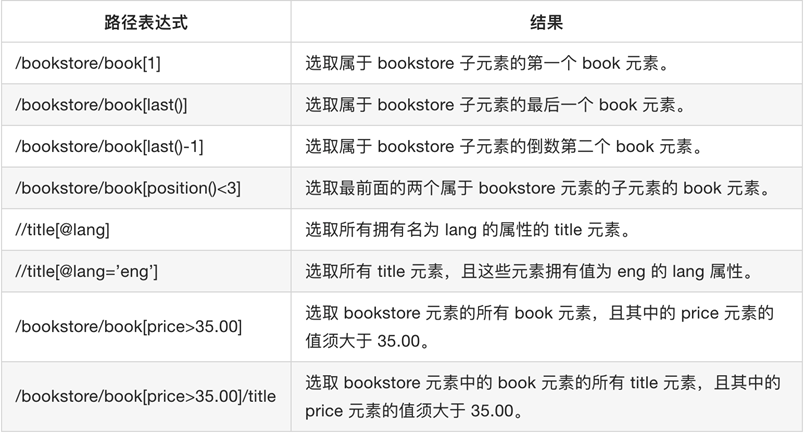
选择未知节点
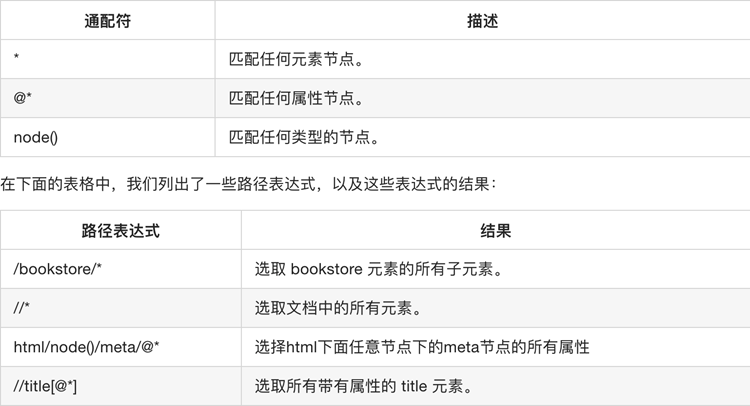
选取若干路径

常用语法技巧
获取文本
- 'a/text()' :获取a标签下的文本
- 'a//text()' : 获取a标签下所有标签的文本
- '//a[text()='下一页']' : 选择文本为“下一页” 三个字的a标签
@符号
- 'a/@href'
- 'ul[@id="center"]'
//符号
- 在xpath开始的是偶表示从当前html中任意位置开始选择
- 'li//a' : 表示的是li下任何一个标签
包含
- '//div[contains(@class, 'i')]' : 表示获取div标签中,class属性中,属性值包含 i 的。
例如:
<div class="i"></div>
<div class="i d"></div>
# 选择不包含class属性的节点
".//span[not(@class)]"
# 选择不包含class和id属性的节点
".//span[not(@class) and not(@id)]"
# 选择不包含class="expire"的span
".//span[not(contains(@class,'expire'))]"
# 选择包含class="expire"的span
".//span[contains(@class,'expire')]"
# 选择text()中包含价格的div节点
'//div[contains(.//text(),"价格")] '
position() 选择当前的第几个节点
//*[@class='result'][position()=1] 选择@class='result'的第一个节点
//*[@class='result'][position()<=2] 选择@class='result'的前两个节点
last() 选择当前的倒数第几个节点
//*[@class='result'][last()] 选择@class='result'的最后一个节点
//*[@class='result'][last()-1] 选择@class='result'的倒数第二个节点
following-sibling 选取当前节点之后的所有同级节点
preceding-sibling 选取当前节点之前的所有同级节点
//div[@class='result']/following-sibling::div 选择@class='result'的div节点后所有同级div节点
找到多个节点时可通过position确定第几个如://div[@class='result']/following-sibling::div[position()=1]
其他HTML解析工具
| 抓取工具 | 速度 | 使用难度 | 安装难度 |
|---|---|---|---|
| 正则 | 最快 | 困难 | 无(内置) |
| BeautifulSoup | 慢 | 最简单 | 简单 |
| lxml | 快 | 简单 | 一般 |
和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
Beautiful Soup 3 目前已经停止开发,推荐现在的项目使用Beautiful Soup 4。使用 pip 安装即可:pip install beautifulsoup4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号