基本概念理解
引入
先来看一道题:
如果 a+b+c=1000,且 \(a^2+b^2=c^2\)(a,b,c 为自然数),如何求出所有a、b、c可能的组合?
按照我们常规的思路,都是会进行穷举,就是把所有的可能都试一次,穷举所有的可能情况,最终得出结果
import time
start_time = time.time()
# 注意是三重循环
for a in range(0, 1001):
for b in range(0, 1001):
for c in range(0, 1001):
if a**2 + b**2 == c**2 and a+b+c == 1000:
print("a, b, c: %d, %d, %d" % (a, b, c))
end_time = time.time()
print("elapsed: %f" % (end_time - start_time))
print("complete!")
运行结果:
a, b, c: 0, 500, 500
a, b, c: 200, 375, 425
a, b, c: 375, 200, 425
a, b, c: 500, 0, 500
elapsed: 1146.944293 【绝了!大约相当于19分钟。。。。】
complete!
使用另一种算法:
import time
start_time = time.time()
# 注意是两重循环
for a in range(0, 1001):
for b in range(0, 1001-a):
c = 1000 - a - b
if a**2 + b**2 == c**2:
print("a, b, c: %d, %d, %d" % (a, b, c))
end_time = time.time()
print("elapsed: %f" % (end_time - start_time))
print("complete!")
运行结果:
a, b, c: 0, 500, 500
a, b, c: 200, 375, 425
a, b, c: 375, 200, 425
a, b, c: 500, 0, 500
elapsed: 0.653515
complete!
结果显而易见啊,好的算法,可以大大提高程序运行的效率!
数据结构与算法的概念
数据结构是一门研究非数值计算的程序设计问题中的操作对象,以及它们之间的关系和操作等相关问题的学科。
1968年,美国的高德纳(Donak E. Knuth)教授在其所写的《计算机程序设计艺术》第一卷《基本算法》中,较系统地阐述了数据的逻辑结构和存储结构及其操作,开创了数据结构的课程体系。同年,数据结构作为一门独立的课程,在计算机科学的学位课程中开始出现。
之后,70年代初,出现了大型程序,软件也开始相对独立,结构程序设计成为程序设计方法学的主要内容,人们越来越重视“数据结构”,认为程序设计的实质是对确定的问题选择一种好的结构,加上设计一种好的算法。
算法是计算机处理信息的本质,因为计算机程序本质上是一个算法来告诉计算机确切的步骤来执行一个指定的任务。一般地,当算法在处理信息时,会从输入设备或数据的存储地址读取数据,把结果写入输出设备或某个存储地址供以后再调用。
算法是独立存在的一种解决问题的方法和思想。
算法(Algorithm)这个单词最早出现在波斯数学家阿勒·花刺子密在公元825年(相当于我们中国的唐朝时期)所写的《印度数字算术》中。
对于算法而言,实现的语言并不重要,重要的是思想。
算法可以有不同的语言描述实现版本(如C描述、C++描述、Python描述等)。
基本概念与术语
- 数据
是描述客观事物的符号,是计算机中可以操作的对象,是能被计算机识别,并输入给计算机处理的符号集合。
数据不仅仅包括整型、实型等数值类型,还包括字符及声音、图像、视频等非数值类型。 - 数据元素
是组成数据的、有一定意义的基本单位,在计算机中通常作为整体处理。也被称为记录。
比如,在人类中,数据元素是人。 - 数据项
一个数据元素可以由若干个数据项组成。数据项是数据不可分割的最小单位。
比如人这样的数据元素,可以有眼、耳、鼻、嘴、手、脚这些数据项,也可以有姓名、年龄、性别、出生地址、联系电话等数据项,具体有哪些数据项,要视你做的系统来决定。 - 数据对象
是性质相同的数据元素的集合,是数据的子集。
逻辑结构与物理结构
逻辑结构
逻辑结构是指数据对象中数据元素之间的相互关系。逻辑结构分为以下四种:
- 集合结构
集合结构中的数据元素除了同属于一个集合外,它们之间没有其他关系。各个数据元素是“平等”的,它们的共同属性是“同属于一个集合”。数据结构中的集合关系就类似于数学中的集合。
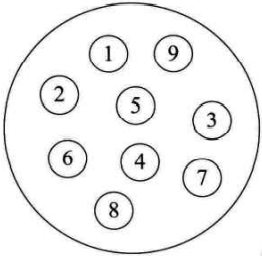
- 线性结构
线性结构中的数据元素之间是一对一的关系
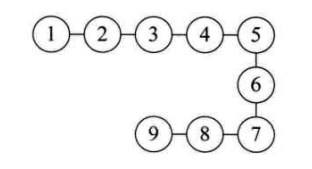
- 树形结构
树形结构中的数据元素之间存在一种一对多的层次关系
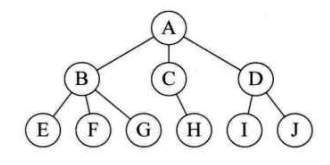
- 图形结构
图形结构的数据元素是多对多的关系
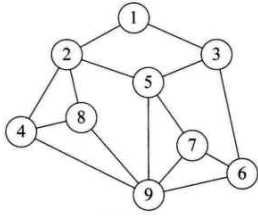
物理结构
物理结构(也叫做存储结构):是指数据的逻辑结构在计算机中的存储形式。
数据元素的存储结构形式有两种:顺序存储和链式存储。
- 顺序存储结构
是把数据元素存放在地址连续的存储单元里,其数据间的逻辑关系和物理关系是一致的。

- 链式存储结构
链式存储结构是把数据元素存放在任意的存储单元里,这组存储单元可以是连续的,也可以是不连续的。数据元素的存储关系并不能反映其逻辑关系,因此需要用一个指针存放数据元素的地址,这样通过地址就可以找到相关联数据元素的位置。
算法的五大特性
- 输入: 算法具有0个或多个输入
- 输出: 算法至少有1个或多个输出
- 有穷性: 算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在可接受的时间内完成
- 确定性:算法中的每一步都有确定的含义,不会出现二义性
- 可行性:算法的每一步都是可行的,也就是说每一步都能够执行有限的次数完成
算法设计的要求
-
正确性
算法的正确性是指算法至少应该具有输入、输出和加工处理无歧义性、能正确反映问题的需求、能够得到问题的正确答案。
但是算法的“正确”通常在用法上有很大的差别,大体分为以下四个层次。
1.算法程序没有语法错误。
2.算法程序对于合法的输入数据能够产生满足要求的输出结果。
3.算法程序对于非法的输入数据能够得出满足规格说明的结果。
4.算法程序对于精心选择的,甚至刁难的测试数据都有满足要求的输出结果。
对于这四层含义,层次1要求最低,但是仅仅没有语法错误实在谈不上是好算法。这就如同仅仅解决温饱,不能算是生活幸福一样。而层次4是最困难的,我们几乎不可能逐一验证所有的输入都得到正确的结果。
因此算法的正确性在大部分情况下都不可能用程序来证明,而是用数学方法证明的。证明一个复杂算法在所有层次上都是正确的,代价非常昂贵。所以一般情况下,我们把层次3作为一个算法是否正确的标准。 -
可读性
算法设计的另一目的是为了便于阅读、理解和交流。
可读性高有助于人们理解算法,晦涩难懂的算法往往隐含错误,不易被发现,并且难于调试和修改。 -
健壮性
当输入数据不合法时,算法也能做出相关处理,而不是产生异常或莫名其妙的结果。 -
时间效率高和存储量低
时间效率指的是算法的执行时间,对于同一个问题,如果有多个算法能够解决,执行时间短的算法效率高,执行时间长的效率低。
存储量需求指的是算法在执行过程中需要的最大存储空间,主要指算法程序运行时所占用的内存或外部硬盘存储空间。设计算法应该尽量满足时间效率高和存储量低的需求。
算法效率衡量
执行时间反应算法效率
对于开篇的同一问题,我们给出了两种解决算法,在两种算法的实现中,我们对程序执行的时间进行了测算,发现两段程序执行的时间相差悬殊(1146.944293秒相比于0.653515秒)
由此我们可以得出结论:实现算法程序的执行时间可以反应出算法的效率,即算法的优劣。
单纯依靠运行的时间来比较算法的优劣并不一定是客观准确的!
假设我们将第二次尝试的算法程序运行在一台配置古老性能低下的计算机中,情况会如何?很可能运行的时间并不会比在我们的电脑中运行算法一的1146.944293秒快多少。
程序的运行离不开计算机环境(包括硬件和操作系统),这些客观原因会影响程序运行的速度并反应在程序的执行时间上。那么如何才能客观的评判一个算法的优劣呢?答案是时间复杂度与“大O记法”
时间复杂度与“大O记法”
对于算法进行特别具体的细致分析虽然很好,但在实践中的实际价值有限。对于算法的时间性质和空间性质,最重要的是其数量级和趋势,这些是分析算法效率的主要部分。而计量算法基本操作数量的规模函数中那些常量因子可以忽略不计。例如,可以认为\(3n^2\)和\(100n^2\)属于同一个量级,如果两个算法处理同样规模实例的代价分别为这两个函数,就认为它们的效率“差不多”,都为\(n^2\)级。
最坏时间复杂度
分析算法时,存在几种可能的考虑:
-
算法完成工作最少需要多少基本操作,即最优时间复杂度
对于最优时间复杂度,其价值不大,因为它没有提供什么有用信息,其反映的只是最乐观最理想的情况,没有参考价值。 -
算法完成工作最多需要多少基本操作,即最坏时间复杂度
对于最坏时间复杂度,提供了一种保证,表明算法在此种程度的基本操作中一定能完成工作。 -
算法完成工作平均需要多少基本操作,即平均时间复杂度
对于平均时间复杂度,是对算法的一个全面评价,因此它完整全面的反映了这个算法的性质。但另一方面,这种衡量并没有保证,不是每个计算都能在这个基本操作内完成。而且,对于平均情况的计算,也会因为应用算法的实例分布可能并不均匀而难以计算。
通常,我们主要关注算法的最坏情况,亦即最坏时间复杂度。
时间复杂度的几条基本计算规则
- 基本操作,即只有常数项,认为其时间复杂度为O(1)
- 顺序结构,时间复杂度按加法进行计算
- 循环结构,时间复杂度按乘法进行计算
- 分支结构,时间复杂度取最大值
- 判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略
- 在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度
举例:
1、第一种算法
for a in range(0, 1001):
for b in range(0, 1001):
for c in range(0, 1001):
if a**2 + b**2 == c**2 and a+b+c == 1000:
print("a, b, c: %d, %d, %d" % (a, b, c))
时间复杂度:
我们把1000换成 n 的数量级进行计算
2、第二种算法
for a in range(0, 1001):
for b in range(0, 1001-a):
c = 1000 - a - b
if a**2 + b**2 == c**2:
print("a, b, c: %d, %d, %d" % (a, b, c))
时间复杂度:
我们把1000换成 n 的数量级进行计算
由此可见,第二种算法要比第一种算法的时间复杂度好多的。
常见时间复杂度
| 执行次数函数举例 | 阶 | 非正式术语 |
|---|---|---|
| \(12\) | \(O(1)\) | 常数阶 |
| \(2n+3\) | \(O(n)\) | 线性阶 |
| \(3n^2+2n+1\) | \(O(n^2)\) | 平方阶 |
| \(5log_2n+20\) | \(O(logn)\) | 对数阶 |
| \(2n+3nlog_2n+19\) | \(O(nlogn)\) | nlogn阶 |
| \(6n^3+2n^2+3n+4\) | \(O(n^3)\) | 立方阶 |
| \(2^n\) | \(O(2^n)\) | 指数阶 |
| 注意,经常将\(log_2n\)(以2为底的对数)简写成\(logn\) |
常见时间复杂度之间的关系
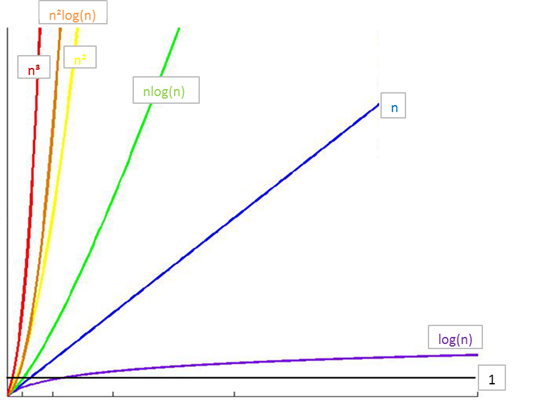
所消耗的时间从小到大
\(O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n) < O(n!) < O(n^n)\)
Python内置类型性能分析
timeit模块
timeit模块可以用来测试一小段Python代码的执行速度。
class timeit.Timer(stmt='pass', setup='pass', timer=< timer function >)
- Timer是测量小段代码执行速度的类。
- stmt参数是要测试的代码语句(statment);
- setup参数是运行代码时需要的设置;
- timer参数是一个定时器函数,与平台有关。
timeit.Timer.timeit(number=1000000)
- Timer类中测试语句执行速度的对象方法。
- number参数是测试代码时的测试次数,默认为1000000次。
- 方法返回执行代码的平均耗时,一个float类型的秒数。
list的操作测试
def test0():
l = []
for i in range(1000):
l += [i]
def test1():
l = []
for i in range(1000):
l = l + [i]
def test2():
l = []
for i in range(1000):
l.append(i)
def test3():
l = [i for i in range(1000)]
def test4():
l = list(range(1000))
from timeit import Timer
t0 = Timer("test0()", "from __main__ import test0")
print("l += [i]: ", t0.timeit(number=1000), "seconds")
t1 = Timer("test1()", "from __main__ import test1")
print("l = l + [i]: ", t1.timeit(number=1000), "seconds")
t2 = Timer("test2()", "from __main__ import test2")
print("l.append(i): ", t2.timeit(number=1000), "seconds")
t3 = Timer("test3()", "from __main__ import test3")
print("[i for i in range(1000)] :", t3.timeit(number=1000), "seconds")
t4 = Timer("test4()", "from __main__ import test4")
print("list(range(1000)) :", t4.timeit(number=1000), "seconds")
运行结果:
l += [i]: 0.1102801 seconds
l = l + [i]: 1.4991847 seconds
l.append(i): 0.09112730000000013 seconds
[i for i in range(1000)] : 0.04096459999999991 seconds
list(range(1000)) : 0.017700100000000107 seconds
li = li + [i] 与 li += [i] 不同
li = li + [i]:可以理解为 li + [i]两个东西(li和[i])相加然后合并出一个新的东西,再由li指向(赋值)这个新的东西
li += [i]:有优化,和li.extend([i])差不多,就是在对原有的li添加,不开辟新的东西
所以尽量少用加号!
pop操作测试
x = range(2000000)
pop_zero = Timer("x.pop(0)","from __main__ import x")
print("pop_zero ",pop_zero.timeit(number=1000), "seconds")
x = range(2000000)
pop_end = Timer("x.pop()","from __main__ import x")
print("pop_end ",pop_end.timeit(number=1000), "seconds")
# ('pop_zero ', 1.9101738929748535, 'seconds')
# ('pop_end ', 0.00023603439331054688, 'seconds')
测试pop操作:从结果可以看出,pop最后一个元素的效率远远高于pop第一个元素
list内置操作的时间复杂度
| Operation | Big-O Efficiency | explain |
|---|---|---|
| indexx[] | \(O(1)\) | 使用索引取元素,是可以一步定位的,因为都有下标 |
| index assignment | \(O(1)\) | 使用索引赋值,也可以很快的定位到 |
| append | \(O(1)\) | 尾部追加,只需要执行一步 |
| pop() | \(O(1)\) | 从尾部往外弹出元素,也只需要一步 |
| pop(i) | \(O(n)\) | pop(i)表示弹出第i个元素,考虑最坏情况,弹出第一个元素,那么n是整个数据量,它要从后往遍历前找到第一个元素 |
| insert(i,item) | \(O(n)\) | insert(i,item)在第i的位置上,插入元素item。也是考虑最坏的情况,在n级别的数据量中,在第0的位置上插入一个元素,那么后面的元素都要往后移动 |
| del operator | \(O(n)\) | 比如删除列表,表示要把列表中的元素,一个一个的都要清空,如果有[1,2,...,n],那么就要删除n个元素,也就是相当于n次 |
| iteration | \(O(n)\) | 迭代元素,有几个元素,迭代几次 |
| contains(in) | \(O(n)\) | 查看是否存在否个元素,肯定时需要遍历的,考虑最坏情况,可能需要全部都遍历一遍,才知道是否存在该元素 |
| get slice[x:y] | \(O(K)\) | 取切片,K是常数,定位到下标x只需要一步,但是 x与y之间 有多少是K,也就是说k的大小只和x与y的距离有关 |
| del slice | \(O(n)\) | 删除一个切片,比如[1,2,3,4,5...,n],我把[2,3,4]这个切片删除,那么后面的所有元素都需要往前移动 |
| set slice | \(O(n+K)\) | 设置添加切片,可以理解为先删除那部分的切片del slice 然后 补充K个元素 |
| reverse | \(O(n)\) | 逆置 |
| concatenate | \(O(K)\) | |
| sort | \(O(nlogn)\) | 和排序算法有关 |
| multiply | \(O(nK)\) | 列表是n,乘数是K。例如:li = [1,2] li*10 |
dict内置操作的时间复杂度
| Operation | Big-O Efficiency | explain |
|---|---|---|
| copy | \(O(n)\) | 把所有的元素都复制一份 |
| get item | \(O(1)\) | |
| set item | \(O(1)\) | |
| delete item | \(O(1)\) | |
| contains (in) | \(O(1)\) | 维护了一个键值对,可以快速找到 |
| iteration | \(O(n)\) |
数据结构
我们如何用Python中的类型来保存一个班的学生信息? 如果想要快速的通过学生姓名获取其信息呢?
实际上当我们在思考这个问题的时候,我们已经用到了数据结构。列表和字典都可以存储一个班的学生信息,但是想要在列表中获取一名同学的信息时,就要遍历这个列表,其时间复杂度为O(n),而使用字典存储时,可将学生姓名作为字典的键,学生信息作为值,进而查询时不需要遍历便可快速获取到学生信息,其时间复杂度为O(1)。
我们为了解决问题,需要将数据保存下来,然后根据数据的存储方式来设计算法实现进行处理,那么数据的存储方式不同就会导致需要不同的算法进行处理。我们希望算法解决问题的效率越快越好,于是我们就需要考虑数据究竟如何保存的问题,这就是数据结构。
在上面的问题中我们可以选择Python中的列表或字典来存储学生信息。列表和字典就是Python内建帮我们封装好的两种数据结构。
算法与数据结构的区别
数据结构只是静态的描述了数据元素之间的关系。
高效的程序需要在数据结构的基础上设计和选择算法。
程序 = 数据结构 + 算法
总结:算法是为了解决实际问题而设计的,数据结构是算法需要处理的问题载体
抽象数据类型(Abstract Data Type)
抽象数据类型(ADT)的含义是指一个数学模型以及定义在此数学模型上的一组操作。即把数据类型和数据类型上的运算捆在一起,进行封装。引入抽象数据类型的目的是把数据类型的表示和数据类型上运算的实现与这些数据类型和运算在程序中的引用隔开,使它们相互独立。
最常用的数据运算有五种:
- 插入
- 删除
- 修改
- 查找
- 排序
参考:
[1]程杰.大话数据结构[M].清华大学出版社:北京,2017
[2]www.itcast.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号