朴素贝叶斯算法(NaïveBayes)
联合概率和条件概率
联合概率
包含多个条件,且所有条件同时成立的概率
记作:P(A,B)
\[P(A, B)= P(A)P(B)
\]
条件概率
就是事件A在另外一个事件B已经发生条件下的发生概率
记作:P(A|B)
\[P(A1,A2|B)= P(A1|B)P(A2|B)
\]
注意:此条件概率的成立,是由于A1,A2相互独立的结果
题目理解
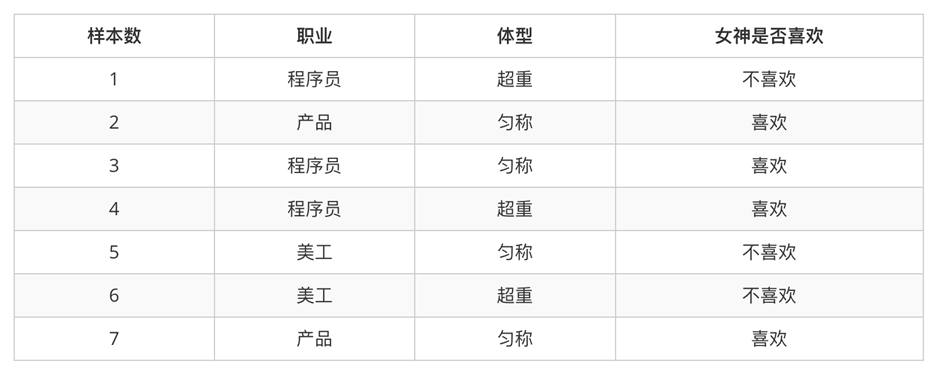
1、女神喜欢的概率?
\[7个样本,有4个喜欢,所以女神喜欢的概率为\frac{4}{7}
\]
2、职业是程序员并且体型匀称的概率?
由联合概率公式,可得
\[P(程序员,体型匀称)=P(程序员)P(体型匀称)=\frac{3}{7}*\frac{4}{7}=\frac{12}{49}
\]
3、在女神喜欢的条件下,职业是程序员的概率?
由条件概率公式,可得
\[P(程序员|喜欢)=\frac{2}{4}
\]
4、在女神喜欢的条件下,职业是产品,体重是超重的概率?
由条件概率公式,可得
\[P(产品,体型超重|喜欢)=P(产品|喜欢)P(体型超重|喜欢)=\frac{2}{4}*\frac{1}{4}=\frac{2}{16}
\]
朴素贝叶斯-贝叶斯公式
\[P(C|W) = \frac{P(W|C)P(C)}{P(W)}
\]
注:w为给定文档的特征值(频数统计,预测文档提供),c为文档类别
也可以理解为:
\[P(C|F1,F2...) = \frac{P(F1,F2...|C)P(C)}{P(F1,F2...)}
\]
公式分为三个部分:
- P(C)
每个文档类别的概率(某文档类别数/总文档数量) - P(W|C)
给定类别下特征(被预测文档中出现的词)的概率- 计算方法:P(F1|C)= Ni/N(训练文档中去计算)
Ni为该F1词在c类别所有文档中出现的次数
N为所属类别c下的文档所有词出现的次数和
- 计算方法:P(F1|C)= Ni/N(训练文档中去计算)
- P(F1,F2,...)预测文档中每个词的概率
拉普拉斯平滑
\[P(F1|C) = \frac{Ni+a}{N+am}
\]
α为指定的系数一般为1,m为训练文档中统计出的特征词个数
朴素贝叶斯分类优缺点
优点
- 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
- 分类准确度高,速度快
缺点
- 由于使用了样本属性独立性的假设,所以如果样本属性有关联时其效果不好
题目理解
我们从把一堆文章进行tf-idf计算,取出最重要的top4词汇,如下“商场”、“影院”、“支付宝”、“云计算”。
然后,我们把科技文章、娱乐文章中出现这些词的次数统计出来。列出如下表:
| 特征\统计 | 科技(30篇) | 娱乐(60篇) | 汇总(90篇) |
|---|---|---|---|
| “商场” | 9 | 51 | 60 |
| “影院” | 8 | 56 | 64 |
| “支付宝” | 20 | 15 | 35 |
| “云计算” | 63 | 0 | 63 |
| 汇总(求和) | 100 | 121 | 221 |
| 现有一篇被预测文档:出现了影院,支付宝,云计算,计算属于科技、娱乐的类别概率? | |||
| 科技: |
\[P(影院,支付宝,云计算|科技)*P(科技)=P(影院|科技)*P(支付宝|科技)*P(云计算|科技)*P(科技)=\frac{8}{100}*\frac{20}{100}*\frac{63}{100}*(\frac{30}{90})=0.00456109
\]
娱乐:
\[P(影院,支付宝,云计算|娱乐)*P(娱乐)=P(影院|娱乐)*P(支付宝|娱乐)*P(云计算|娱乐)*P(娱乐)=\frac{56}{100}*\frac{15}{100}*\frac{0}{100}*(\frac{60}{90})=0
\]
问题:从上面的例子我们得到娱乐概率为o,这是不合理的,如果词频列表里面有很多出现次数都为o,很可能计算结果都为零
解决方法:拉普拉斯平滑系数
科技:
\[P(影院,支付宝,云计算|科技)*P(科技)=P(影院|科技)*P(支付宝|科技)*P(云计算|科技)*P(科技)=\frac{8+1}{100+1*4}*\frac{20+1}{100+1*4}*\frac{63+1}{100+1*4)}*(\frac{30}{90})
\]
娱乐:
\[P(影院,支付宝,云计算|娱乐)*P(娱乐)=P(影院|娱乐)*P(支付宝|娱乐)*P(云计算|娱乐)*P(娱乐)=\frac{56+1}{100+1*4}*\frac{15+1}{100+1*4}*\frac{0+1}{100+1*4}*(\frac{60}{90})
\]
案例:朴树贝叶斯文本分类
- sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
- 朴素贝叶斯分类
- alpha:拉普拉斯平滑系数
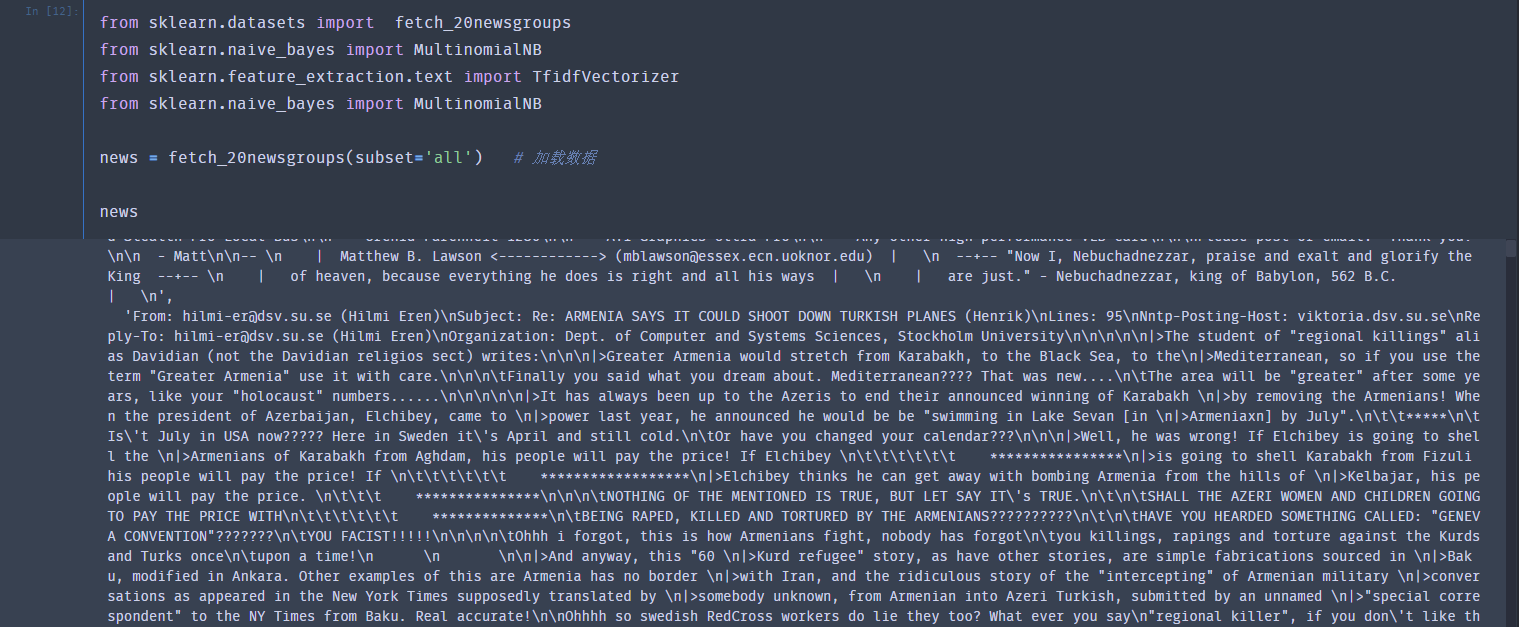
加载sklearn库中的数据
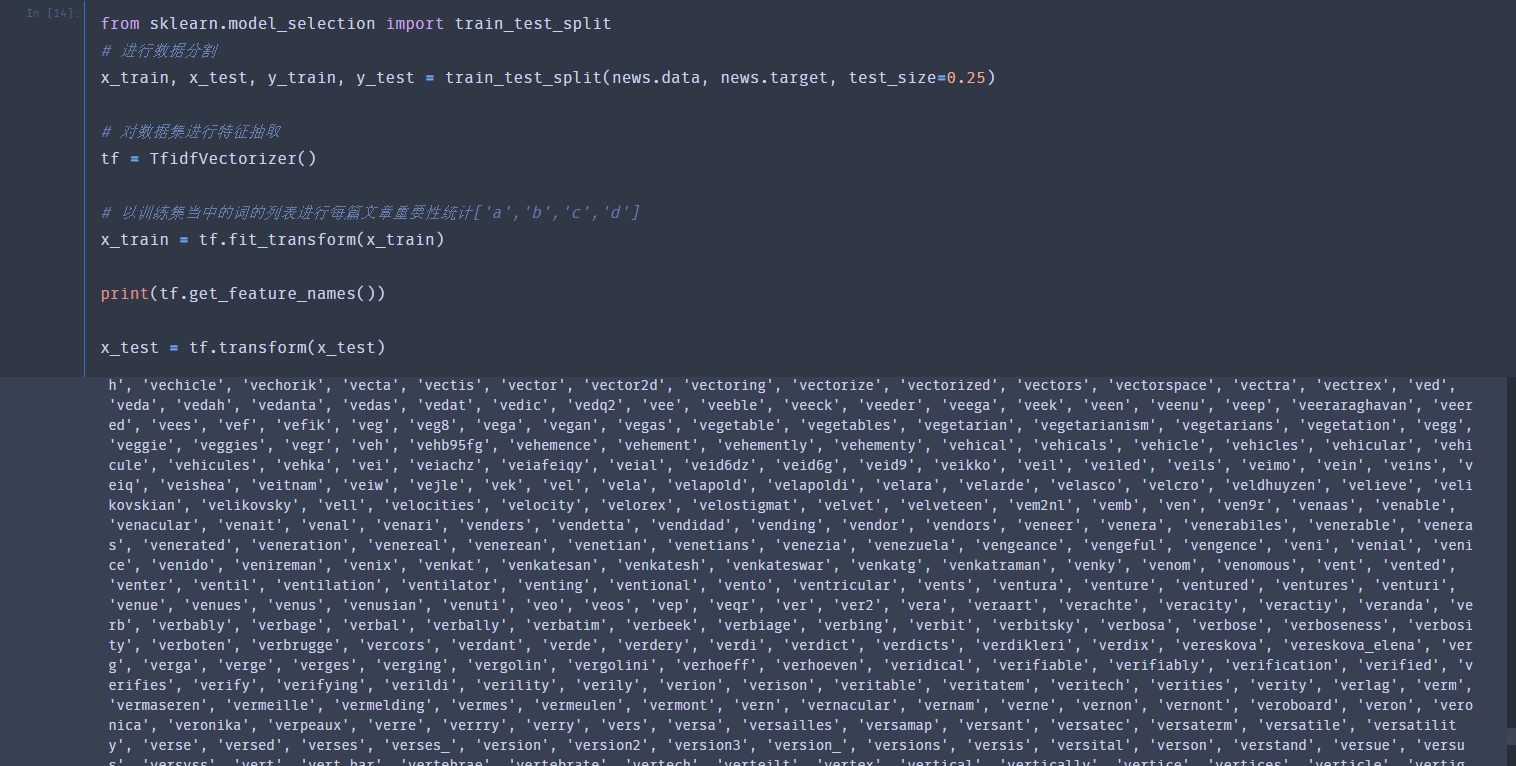
进行特征处理(文本)
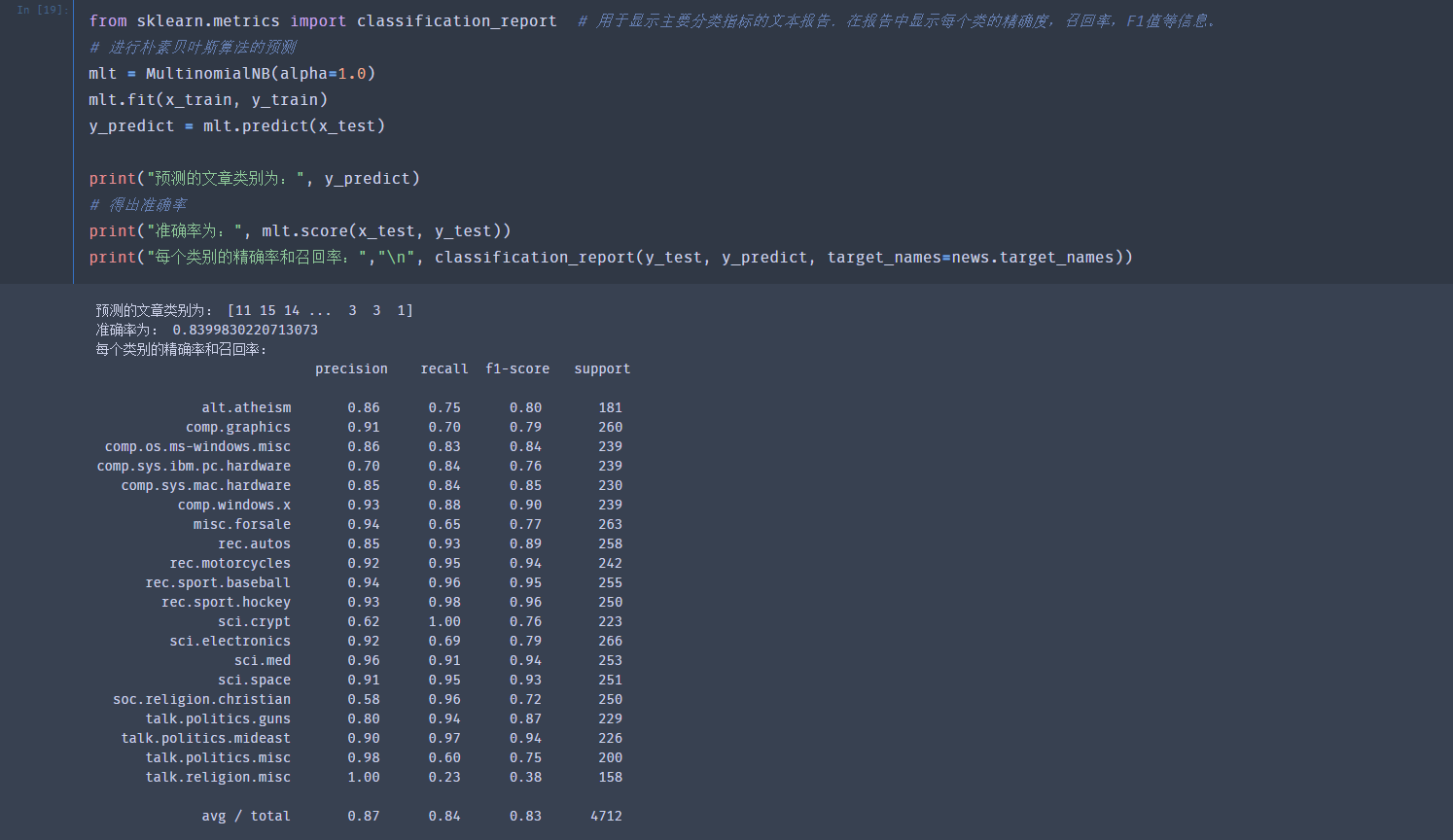
进行贝叶斯文本分类

 浙公网安备 33010602011771号
浙公网安备 33010602011771号