K-近邻算法(KNN)
K-近邻算法(k-Nearest Neighbor,KNN)
定义与理解
定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
举个例子来说明:
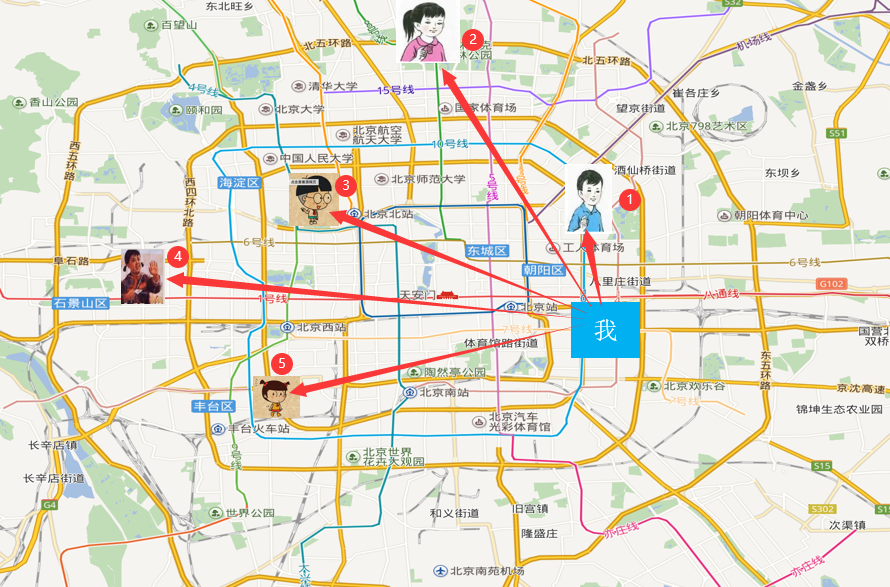
假如我在北京,我又不知道我在哪个区,但是我认识5个人,他们知道自己在哪个区,那我就打电话问他们每个人的到我的距离,1号离我最近,那么我就可以认为我和1号在一个区。即根据我的“邻居”来推断出我所在的区。
欧式距离(euclidean metric)
两个样本的距离可以通过如下公式计算,又叫欧式距离(euclidean metric,也叫欧几里得度量)
比如:\(a(a_1, a_2, a_3), b(b_1, b_2, b_3)\)
k-近邻算法优缺点
优点:
简单,易于理解,易于实现,无需估计参数,无需训练(不用迭代训练,程序运行一次就可以)
缺点:
懒惰算法,对测试样本分类时的计算量大,内存开销大,必须指定K值,K值选择不当则分类精度不能保证
使用场景
小数据场景,几千一几万样本,具体场景具体业务去测试
K取多大
-
K值取很小:容易受到异常值点影响
-
K值取很大:容易受K值数量(类别)波动,比如说,10个数据中,K取5,模型认10个中有一半是邻居
案例:预测入住位置
Facebook V: Predicting Check Ins URL:https://www.kaggle.com/c/facebook-v-predicting-check-ins/data

数据说明:
- train.csv,test.csv
- row_id:签到事件的ID
- xy:坐标
- 精度:位置精度
- 时间:时间戳
- place_id:商家的ID,这是您要预测的目标
- sample_submission.csv-带有随机预测的正确格式的样本提交文件
代码实现(sklearn库)
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:int,可选(默认=5) , k_neighbors,查询默认使用的邻居数
- algorithm: {'auto',‘ball_tree',‘kd_tree',‘brute'},可选用于计算最近邻居的算法:‘ball_ree'将会使用BallTree,‘kd_tree'将使用KDTree。‘auto'将尝试根据传递给fit方法的值来决定最合适的算法。(不同实现方式影响效率)
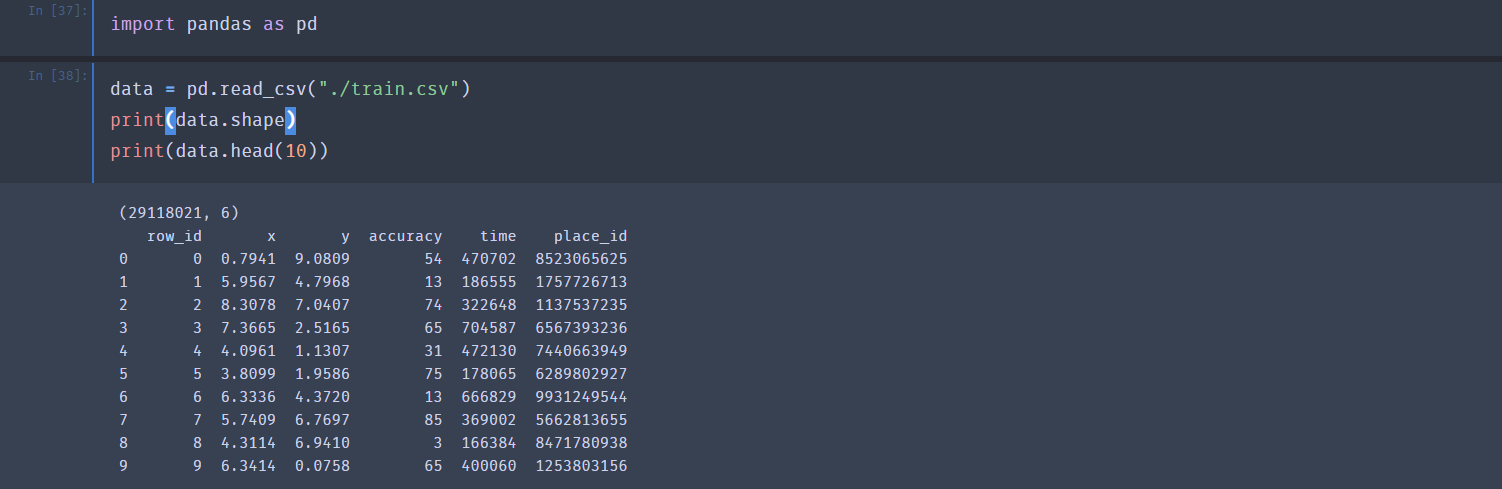
查看训练数据
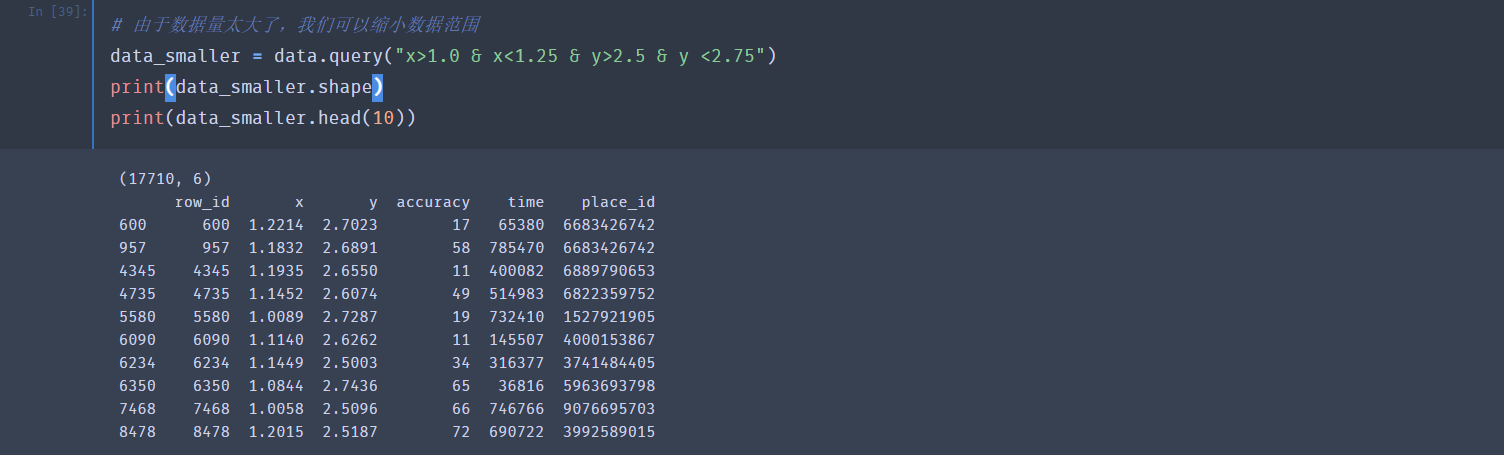
由于数据量太大了,我们可以缩小范围,取其中的一小部分
我们可以从现有的特征中构造出新的特征
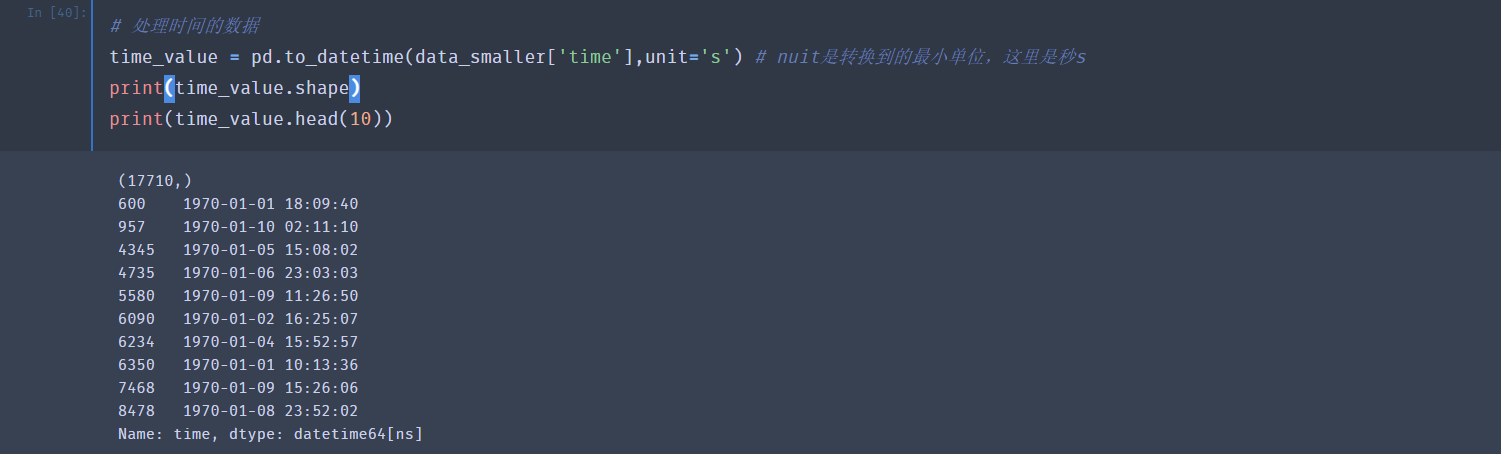
比如说这里的时间,形式是时间戳,我们可以转成年月日,形成新的特征,加入
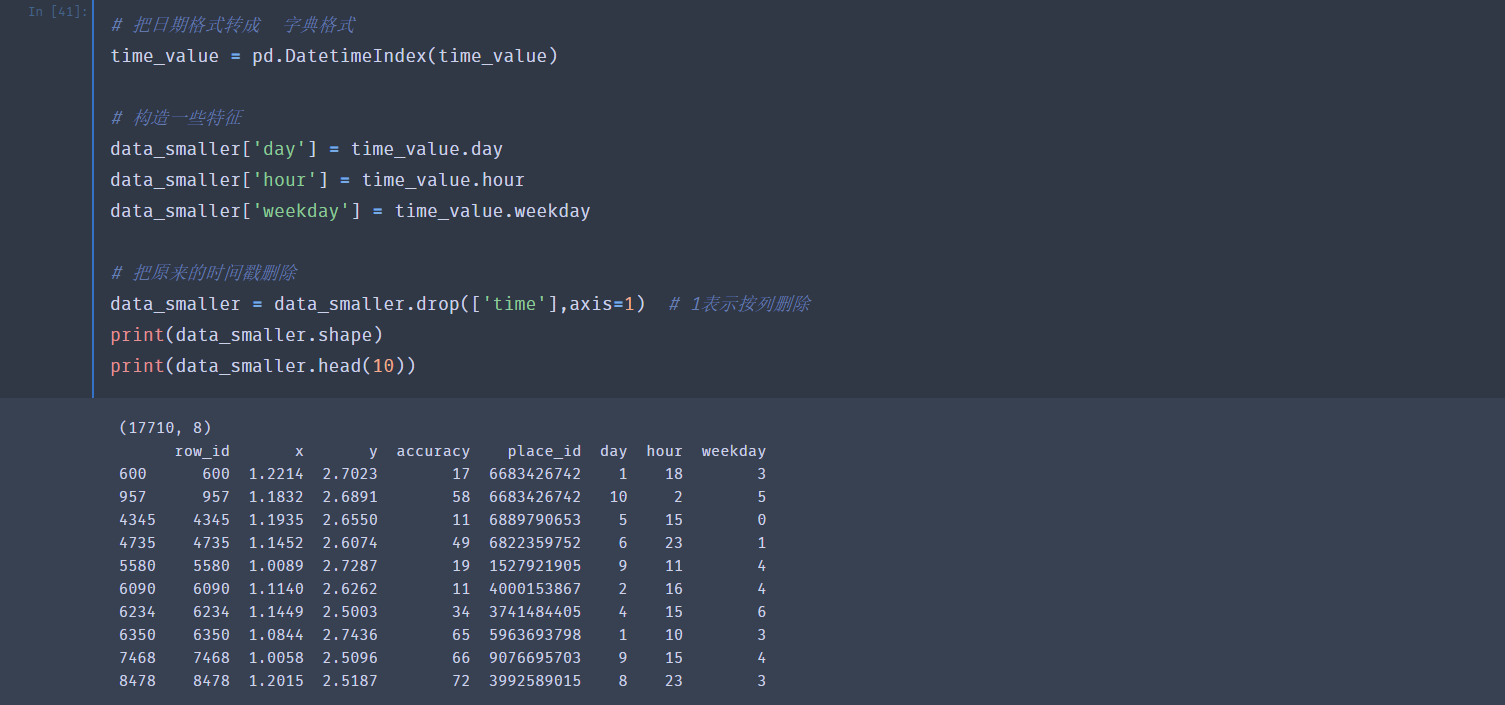
对于签到数小于3的,我们不计入(这也是偷懒)
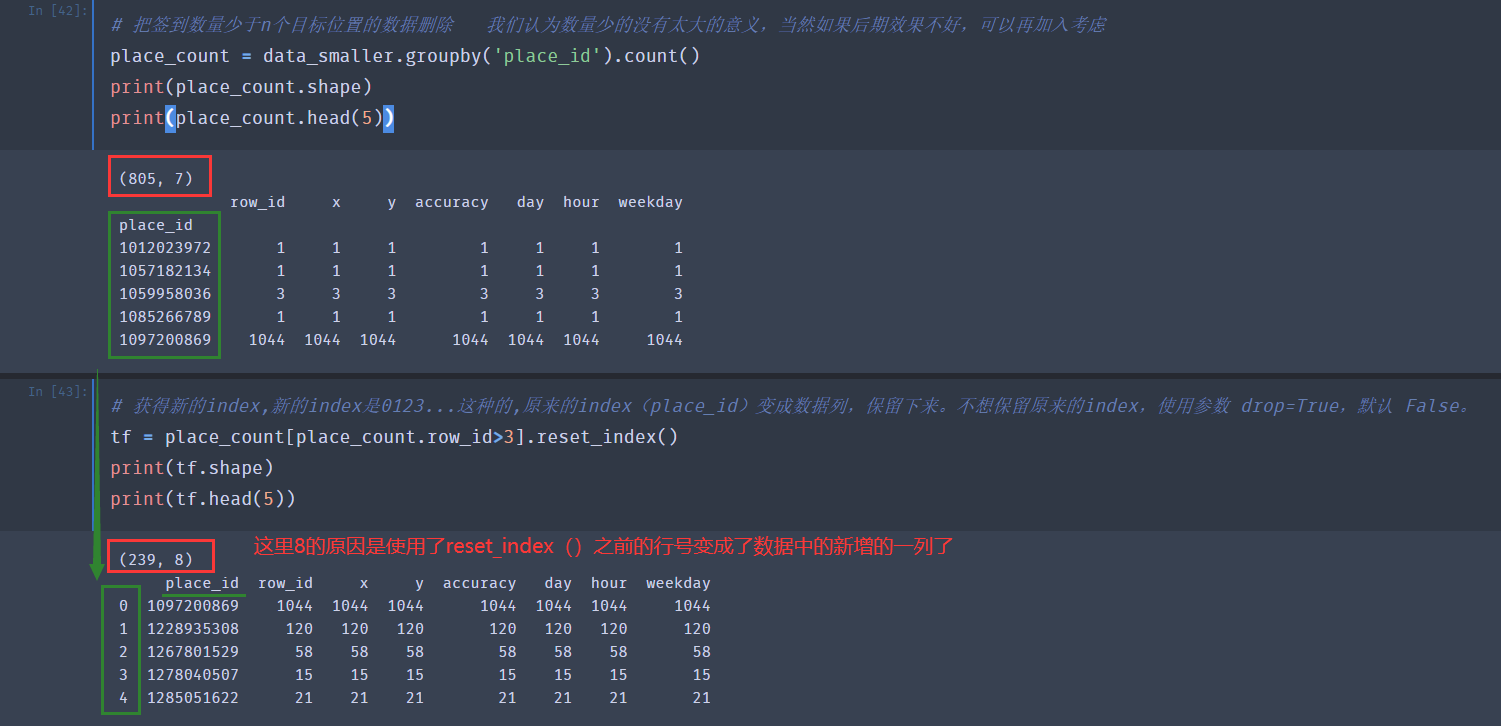
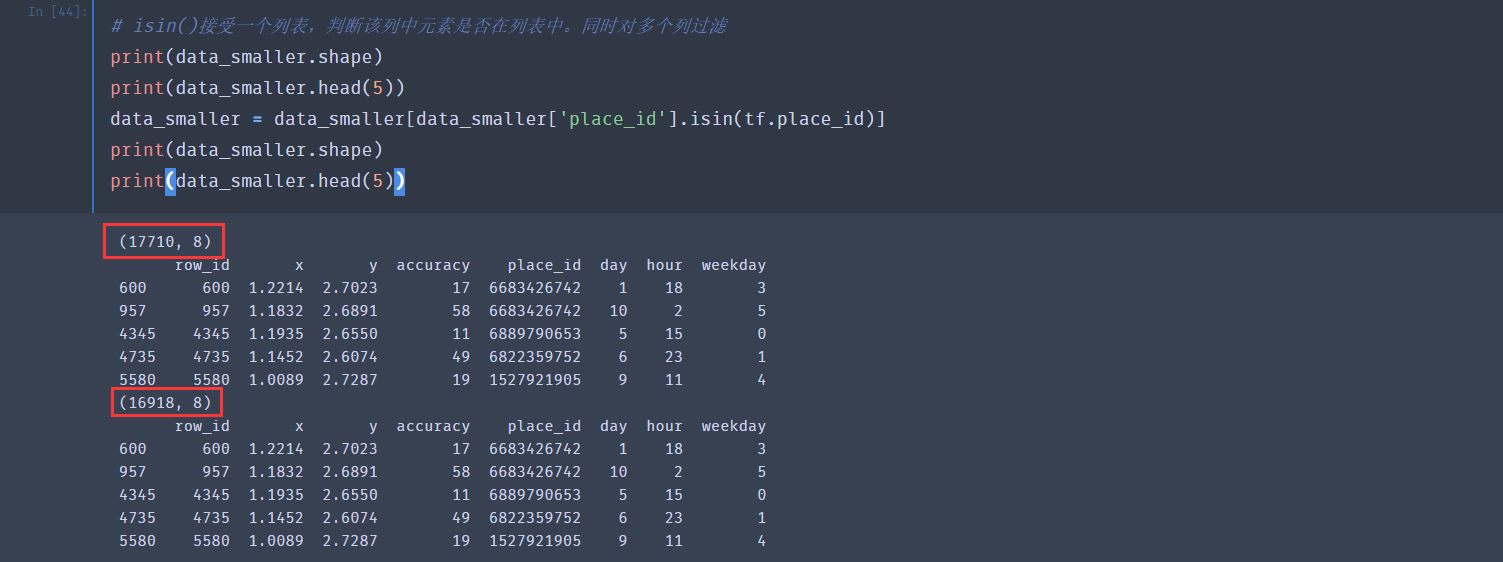
从下面的结果可以看出,经过我们的处理,数据量已经减少了不少
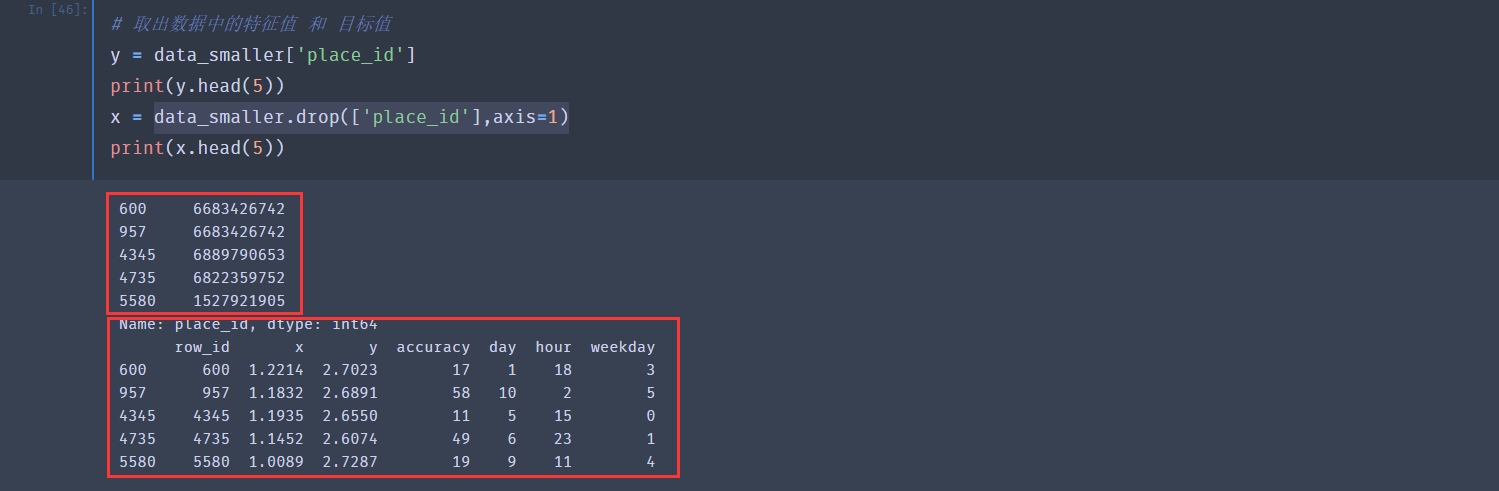
把特征值和目标值分离出来
对数据集进行划分,按照 训练集:测试集=75%:25%
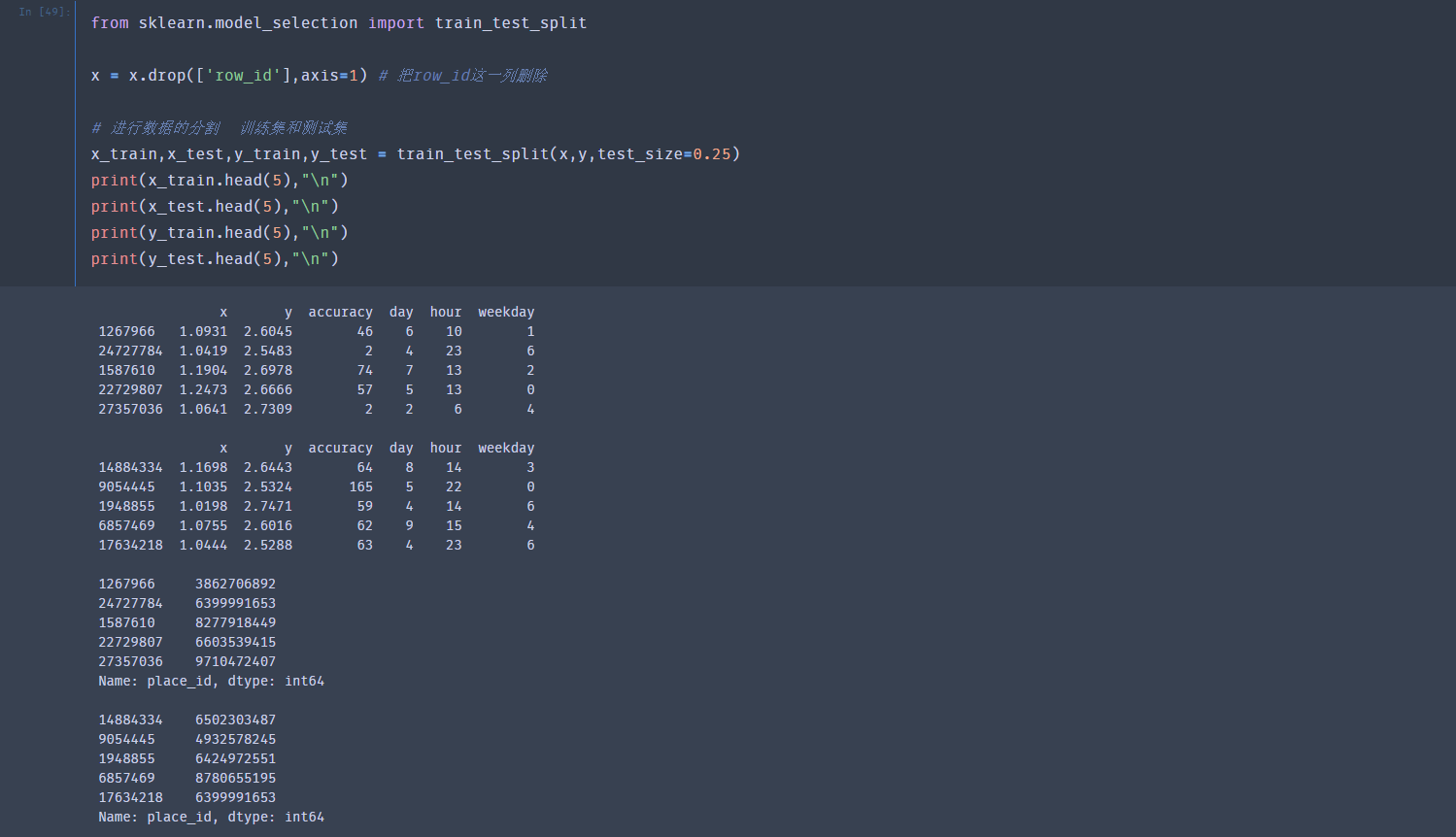
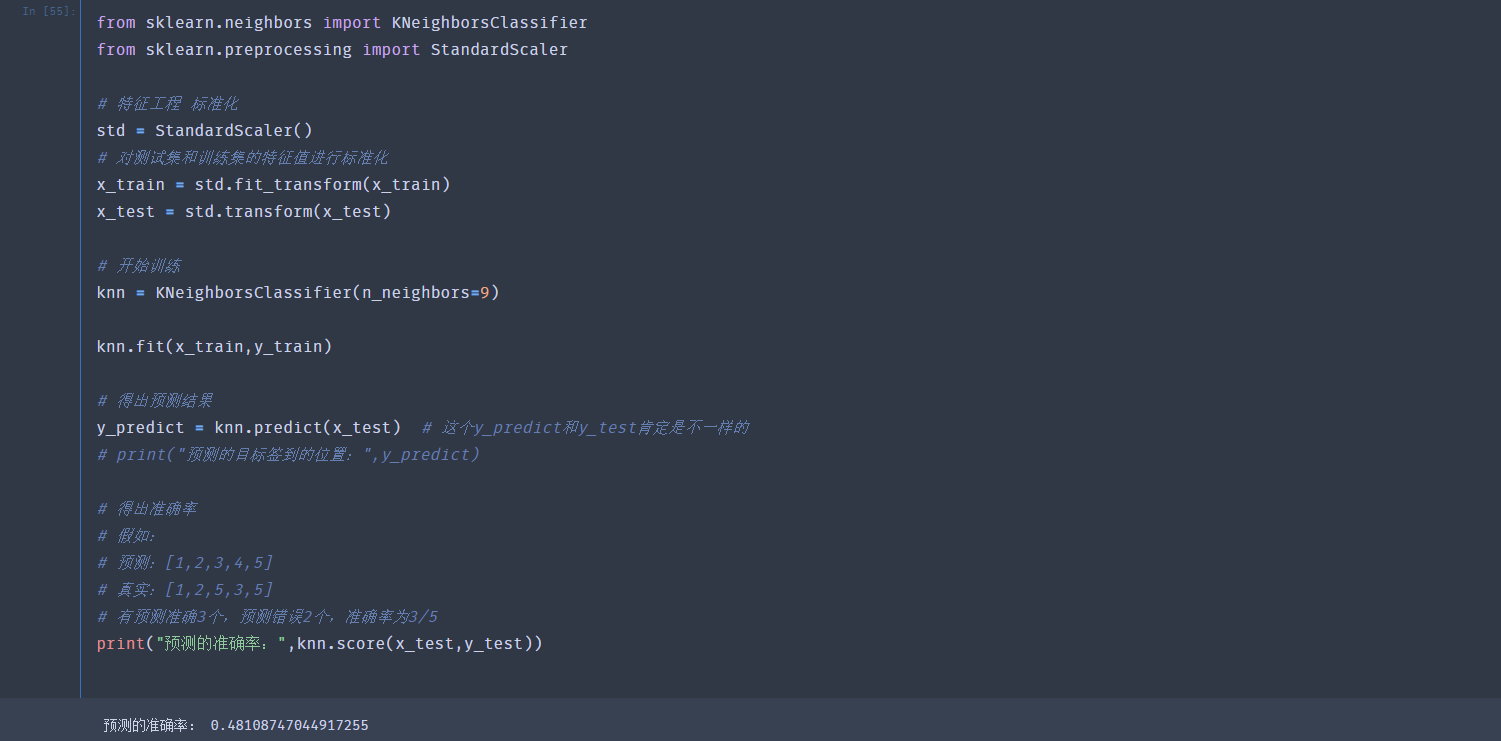
不使用交叉验证进行求解
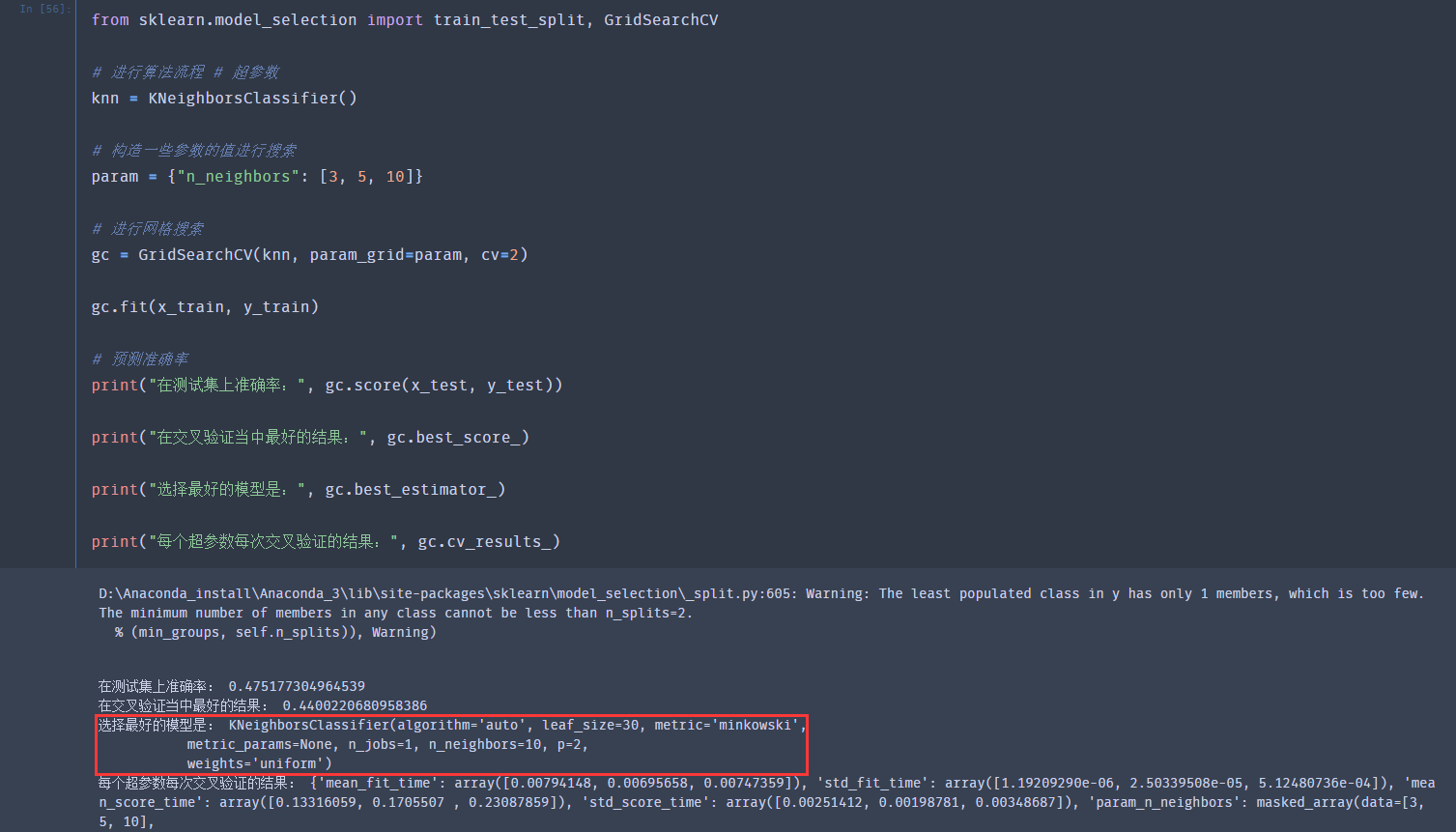
使用交叉验证进行求解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号