随机网络
随机网络模型
网络科学旨在建立能够重现真实网络性质的模型。我们遇到的大多数真实网络没有晶格所具有的那种令人愉悦的规则结构,或者蜘蛛网所具有的那种可预测的放射型结构。相反,真实网络乍一看好像是随机连接而成的。随机网络理论通过构建和刻画真正随机的网络来解释这种表面上的随机性。
从建模的角度来看,网络是一个相对简单的对象,仅由节点和链接组成。然而,真正的挑战在于,在哪些节点间放置链接才能重现真实系统的复杂性。在这一点上,随机网络背后的哲学思想很简单:在节点之间随机放置链接。
定义随机网络
随机网络有两种定义方式:
-
G(N,L)模型
N个节点通过L条随机放置的链接彼此相连。埃尔德什和雷尼在他们关于随机网络的系列论文中采用的是这种定义方式。 -
G(N,p)模型
N个节点中,每对节点之间以概率p彼此相连。该模型是由埃德加·N.吉尔伯特(Edgar N.Gilbert)提出的。G(N,p)模型固定了两个节点的连接概率p,
G (N,L)模型则固定了总链接数L。
G(N,L)模型中,节点平均度可以简单地算出,即
=2L/N。 G (N,p)模型中,网络其他特征则更容易计算。
使用G(N,p)模型生成随机网络的步骤(随机网络由N个节点组成,每对节点相互连接的概率为p。):
(1)从N个孤立节点开始。
(2)选择一对节点,产生一个0到1之间的随机数。如果该随机数小于p,在这对节点之间放置一条链接;否则,该节点对保持不连接。
(3)对所有N (N-1)/2个节点对,重复步骤(2)。
上述过程得到的网络被称为随机图或随机网络。两位数学家——保罗·埃尔德什和阿尔弗雷德·雷尼在理解随机网络的性质方面发挥了重要作用。为了纪念他们,随机网络被命名为埃尔德什―雷尼网络
链接数
由同样的参数N和p产生的随机网络,看起来会稍有不同(如下图)。这种不同不仅体现在详细的节点连接情况上,还体现在链接数L上。因此,给定参数N和p时,判定出所生成随机网络的期望链接数是有价值的。
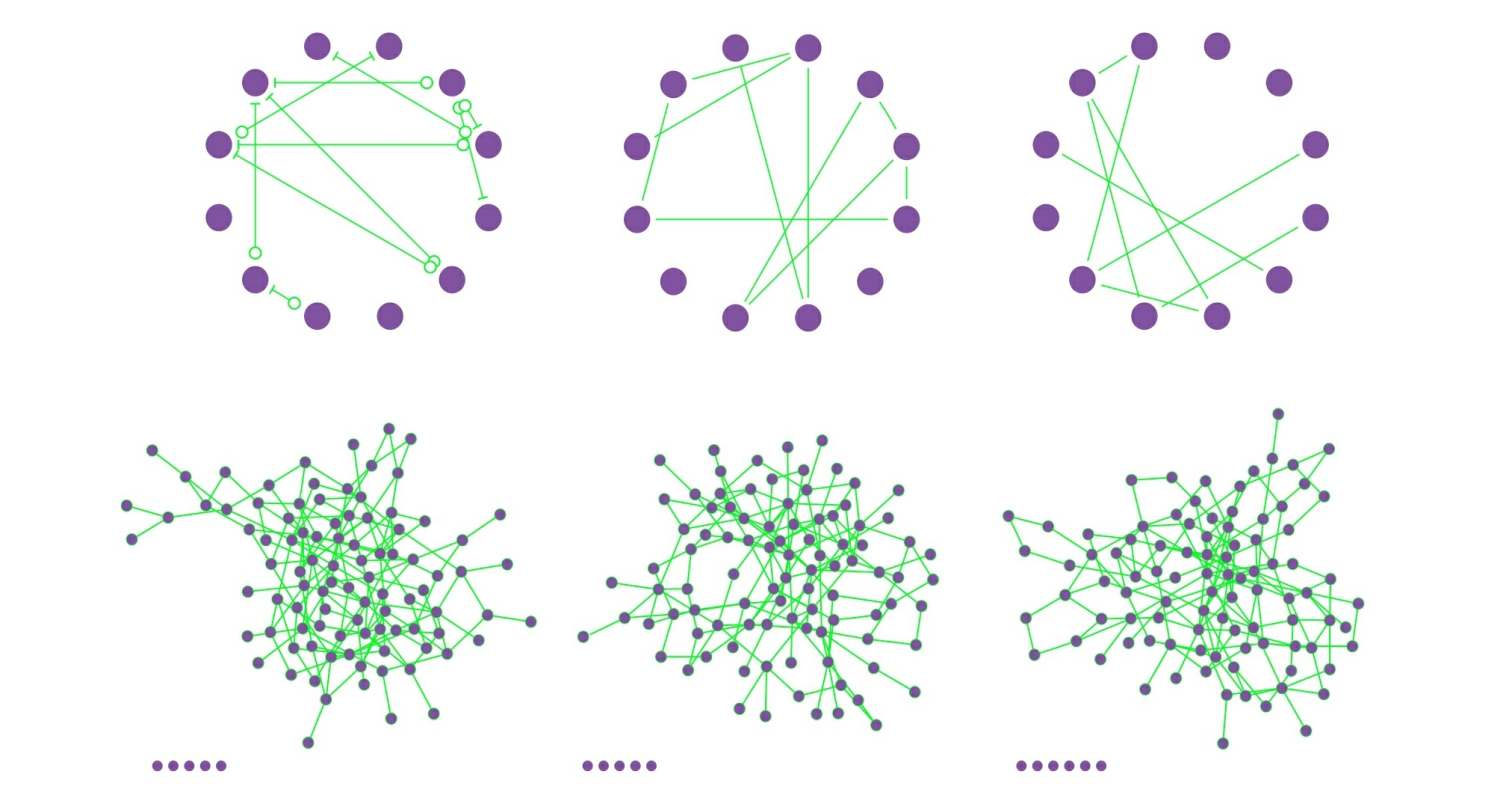
说明:
第一行图
参数均为p=1/6,N=12的三个随机网络。尽管参数相同,但这三个网络不仅看上去差别很大,链接数也不同(L=10,10,8)。
第二行图
参数均为p=0.03,N=100的三个随机网络。可以看到,图的底部有一些孤立节点,这些节点的度为k=O。
随机网络恰好有L条链接的概率:
(1)L个点对之间存在链接的概率,即\(P^L\)。
(2)剩余N(N-1)/2-L个点对之间没有链接的概率,即$ (1-P)^{\frac{N(N-1)}{2}-L}$
(3)在所有N(N-1)/2个点对中选择L个点对放置链接,所有可能的选择方式数为:\(\begin{pmatrix}\frac{N(N-1)}{2} \\L \end{pmatrix}\)
上述公式是一个二项式分布,因此随机网络的期望链接数为:
可以看出,
根据期望连接数公式,我们可以得到随机网络的平均度:
也就是说,对于节点数为N的随机网络而言,其平均度
综上所述,由相同参数N和p产生的不同随机网络,其链接数可以不同。链接数的期望值取决于N和p。增大p的值会使随机网络变得更稠密:平均链接数从
度分布
随机网络中,有些节点有许多链接,有些节点只有少量链接,甚至没有链接。这种差异可以通过度分布\(P_k\)来刻画,\(P_k\)表示一个随机选择的节点其度为k的概率。
二项分布
随机网络中,一个节点i恰好有k个链接的概率是下面三项的乘积:
(1)k个链接出现的概率,即\(P_k\)。
(2)剩下(N-1-k)个链接不出现的概率,即\((1-p)^{N-1-k}\)。
(3)节点i的N-1个可能存在的链接中选出k个,选择方式的总数为:\(\begin{pmatrix} N-1 \\ K \end{pmatrix}\)
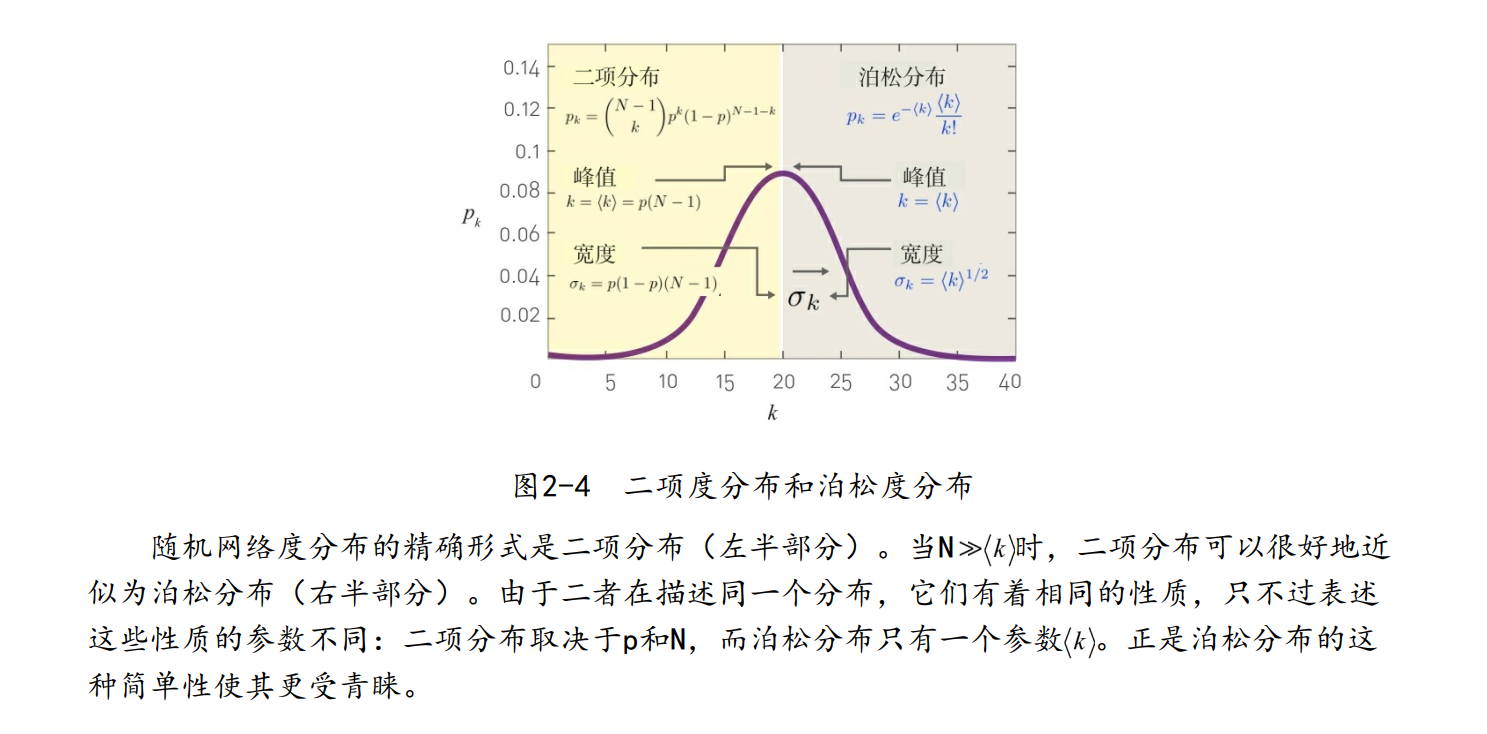
二项分布的形状取决于网络大小N和链接概率p:
泊松分布
大部分真实网络是稀疏的,意味着这些网络的平均度远小于网络大小——< k >远小于N。极限情况下,度分布可以近似为如下泊松分布
上面两个公式,通常被称为随机网络的度分布。因此它们有相似的性质 :
- 这两个分布都在
附近有一个峰值。增加p的值会使网络变得稠密,平均度 和度分布的峰值会右移。 - 分布的宽度(离散度)也由p和
控制。网络越稠密,分布越宽,节点度的差异也越大。
随机网络度分布的精确形式是二项分布。因此,只是在
远小于N的极限情况下对泊松分布近似。 由于大多数真实网络都是稀疏的,上述近似所需的条件通常会被满足。
- 泊松形式的优势是,像
、<\(k^2\)>和\(σ_k\)等网络关键特性的形式更简单,仅依赖于 这一个参数。 - \(P_k= e^{-<k>}\frac{<K>^k}{K!}\)中的泊松分布不显式地依赖节点数目N。因此,平均度
相同但大小不同的随机网络,其度分布几乎一样。
综上所述,虽然泊松分布只是随机网络度分布的一种近似,但其形式简单,便于分析,因此在刻画随机网络的度分布\(P_k\)时,人们更倾向于使用泊松形式。
泊松形式度分布的一个关键特征是,其性质与网络大小无关,仅依赖于平均度
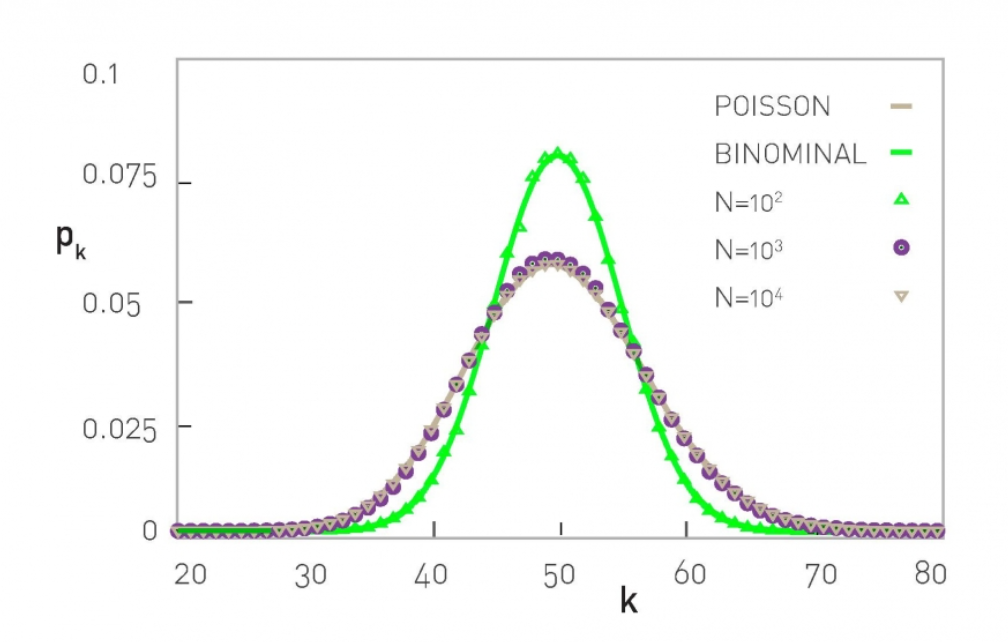
上图说明,度分布与网络大小无关。
平均度(k)=50,大小分别为N=\(10^2\)、N=\(10^3\)、N=\(10^4\)的三个随机网络的度分布。
小网络:二项分布(BINOMINAL)
对于小网络(N=\(10^2\)),由于不满足泊松近似的条件
大网络:泊松分布(POISSON)
对于大网络((N=\(10^3\),N=\(10^4\)),其度分布与灰线所示的泊松分布相差无几。因此,当网络大小N很大时,度分布和网络大小无关。为了避免随机性带来的噪声,图中所示的结果是在1 000个独立生成的随机网络上平均得到的。
真实网络不是泊松分布的
据社会学家估计,一个普通人大约认识1 000个人。因此,我们假设网络的平均度为
(1)随机社会中连通性最好的人(度最大的节点),大约有\(k_{max}\)=1 185个熟人。
(2)连通性最差的人,认识大约\(k_{min}\)=816个人,和\(k_{max}\)或
(3)随机网络度分布的标准差为\(σ_k\)=\(<k>^{1/2}\)。对于平均度
总之,在随机社会中,每个人的朋友数大体相当。因此,如果我们是随机连接在一起的,就不会有异常的人存在:没有非常受欢迎的人也没有只有少数几个朋友的人。这一惊人的结论源于随机网络的一个重要性质:在大的随机网络中,大多数节点的度分布在
上述结论明显和现实不符。实际上,很多人认识的人数远远超过1185。例如,美国总统富兰克林·德拉诺·罗斯福(FranklinDelano Roosevelt)的预约本中有22 000个名字,这些都是他要亲自会见的人。与之类似,对Facebook社交网络的一项研究表明有很多人的好友数达到了5 000——5 000是Facebook社交网络平台设置的好友数最大值。要弄清楚前述结论和现实之间这些巨大差异产生的原因,我们需要对比真实网络的度分布和随机网络的度分布。
下面三个图展示了三个真实网络的度分布以及相应的泊松拟合。展现了真实网络和随机网络之间的巨大差异:
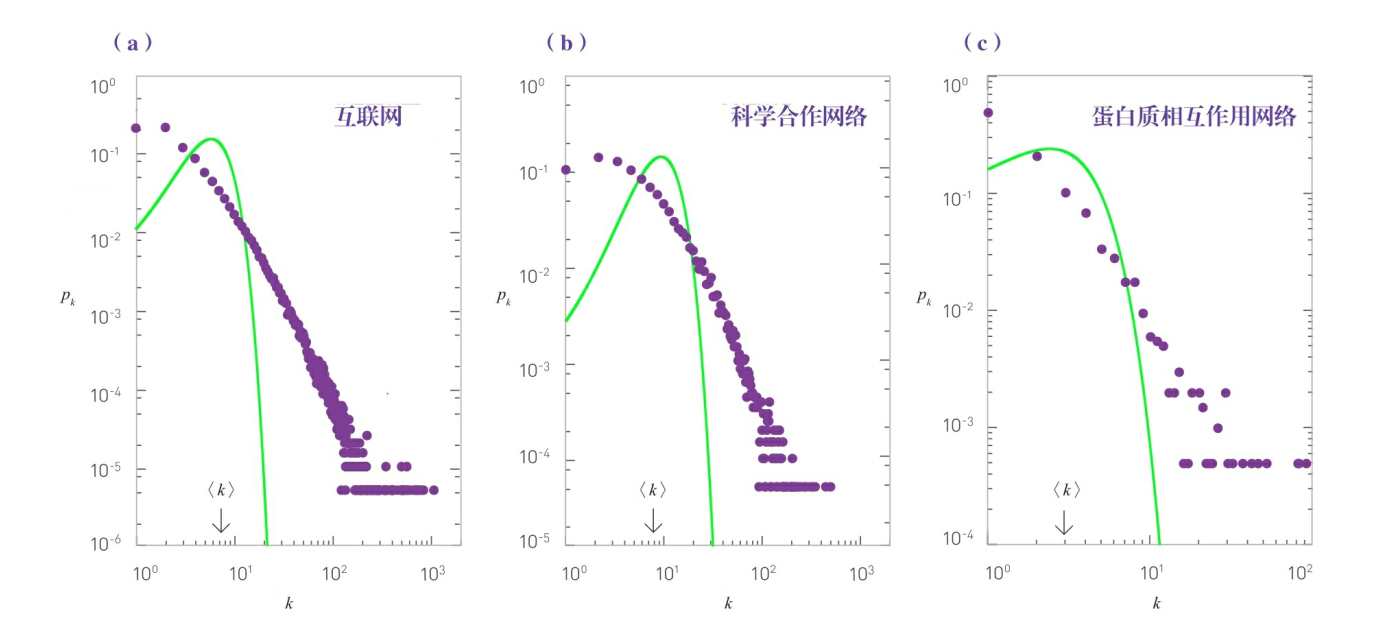
绿色的线是泊松分布——通过测量真实网络的平均度
真实数据和泊松分布之间的显著差异表明,随机网络模型低估了大度节点的度和出现概率,也低估了小度节点的数量。相反,随机网络模型预测网络中大量节点的度在平均度
(1)泊松形式明显低估了大度节点的个数。例如,根据随机网络模型,互联网的最大度预计在20左右。真实数据表明,有的路由器的度可以接近\(10^3\)。
(2)真实网络中度的分布范围比随机网络所预计的要宽得多。这种差异可以通过图2-4所示的分布离散度\(σ_k\)看出。如果互联网是随机的,则预计\(σ_k\)=2.52。而真实测量结果表明,\(σ_{internet}\)=14.14,明显高于随机网络的预计值。这些差异不仅存在于上面三个所示的网络,所有其他网络都具有该性质。
总之,和真实数据的对比表明,随机网络模型不能刻画出真实网络的度分布。随机网络中,大多数节点都有类似的度,不存在枢纽节点。与之相反,在真实网络中,我们观察到很多高度连接的节点,节点的度之间有很大的差异。
随机网络的演化
网络中最大连通分支的大小\(N_G\)是如何随着
-
当p=0时,
=0,所有节点都是孤立的。因此,最大连通分支的大小为\(N_G\)=1。对于大的N,有\(N_G\)/N→O。 -
当p=1时,
=N-1,网络是完全连通图,所有节点属于同一个连通分支。因此,\(N_G\)=N,\(N_G\)/N=1。 即:当p很小时,网络中没有巨连通分支,而当p到达临界值时,一个巨连通分支突然就出现了。
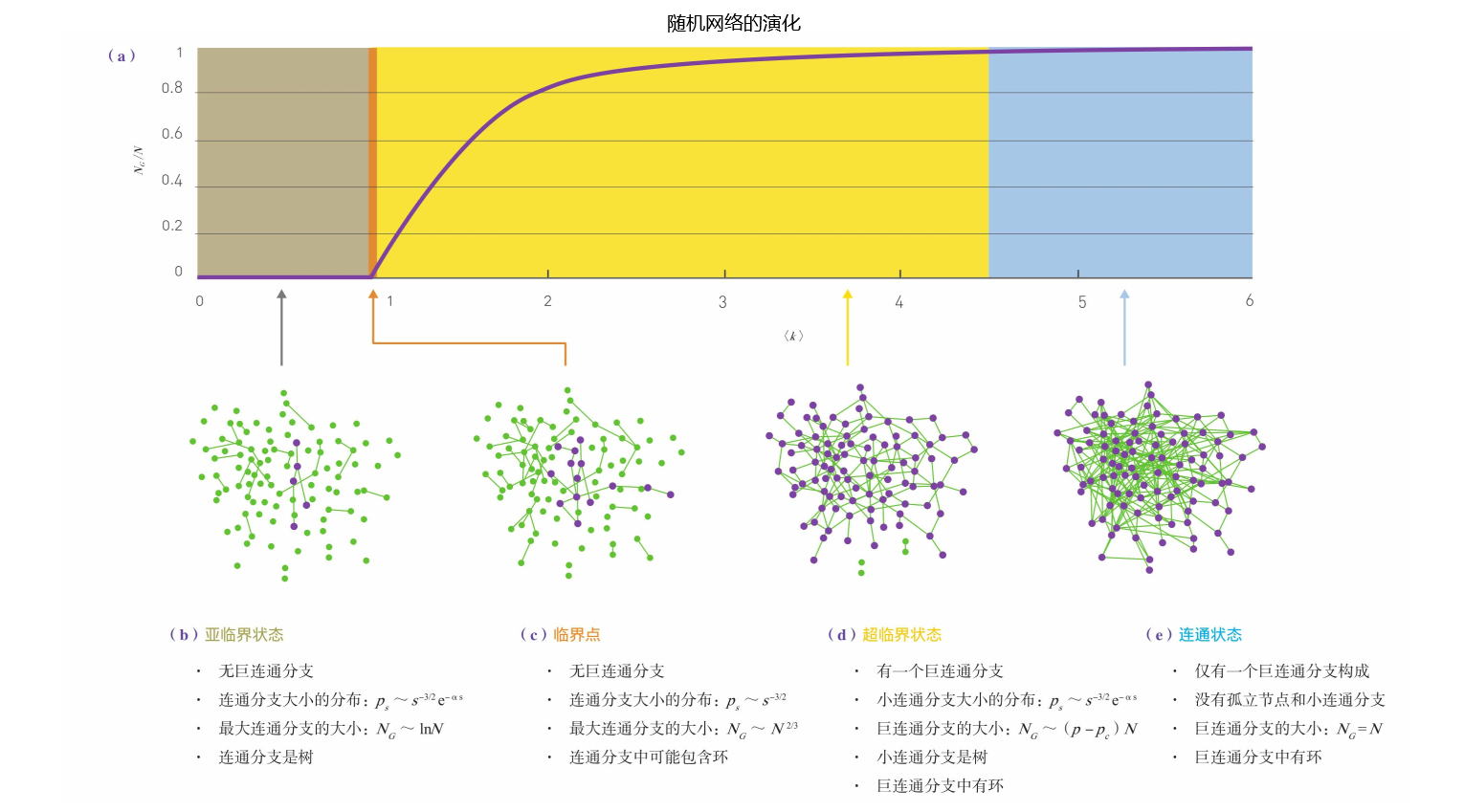
有人可能会认为,随着平均度
当
一旦
埃尔德什和雷尼在他们1959年发表的经典论文中预测了巨连通分支出现的条件:
换句话说,当且仅当每个节点平均拥有不少于一个链接时,巨连通分支才会出现。
每个节点至少需要一个链接才能使网络中出现巨连通分支,这一事实并不让人感到意外。实际上,巨连通分支的存在,要求其所包含的每个节点必须至少和一个该连通分支中的其他节点相连。巨连通分支的出现只需要每个节点拥有一个链接就足够了,这多少有点反直觉,但事实的确如此。
根据随机网络平均度公式\(<K>=\frac{2<L>}{N}=P(N-1)\),可以使用链接概率P来表示公式:
因此,网络越大,形成巨连通分支所需要的p越小。
-
亚临界状态:0<
<1 (p< \(\frac{1}{N}\) ) 当
=0时,网络由N个孤立节点构成。 的增加意味着我们往网络中增加了N =pN(N-1)/2个链接。然而,由于 <1,网络中只有少量的链接。因此在该状态下,网络中只有一些较小的连通分支 。 当然,任何时候我们都可以将最大连通分支指定为巨连通分支。然而,在这种状态下,最大连通分支的相对大小\(N_G\)/N接近于0。原因是:当
<1时,最大连通分支是一个大小为\(N_G\)~InN的树,最大连通分支大小的增加速度比网络大小的增加速度要慢得多。因此,在N→∞的极限情况下,\(N_G\)≌lnN/N→0。 总之,亚临界状态下,网络由许多较小的连通分支组成,这些分支的大小服从指数分布。因此,这些连通分支的大小相差不大,没有哪个连通分支的大小明显高于其他连通分支从而可以被指定为巨连通分支。
-
临界点:
= 1 ( p=\(\frac{1}{N}\) ) 临界点是网络从没有巨连通分支(
<1)变化到有巨连通分支( >1)的边界。当网络处于临界点时,最大连通分支的相对大小仍然趋近于零。实际上,此时最大连通分支的大小为\(N_G\)$N^{2/3}$。因此,最大连通分支的大小$N_G$比网络大小增长得慢得多,在N→∞的极限情况下,最大连通分支的相对大小$N_G$/N\(N^{-1/3}\)→0。 不过,需要注意的是,最大连通分支的绝对大小在
=1处有一个明显的跳跃。例如,对于有N=7×\(10^9\)个节点的随机网络——大小和全球社交网络相当,当 <1时,最大连通分支的大小为\(N_G\)≌lnN=ln(7×\(10^9\))≌22.7。相比之下,当 =1时,\(N_G\)~\(N^{2/3}\)=(7×\(10^9)^{2/3}≌3×106\),比 <1时提升了约5个数量级。然而,无论处于亚临界状态还是临界点,最大连通分支都只包含了网络所有节点中很小的一部分。 总之,在临界点,大多数节点出现在数量众多的小连通分支中,这些连通分支大小的分布服从公式。幂律形式意味着,大小差异很大的连通分支并存。为数众多的小连通分支主要是树,而最大连通分支则可能包含环。注意,处于临界点状态的网络,其很多性质和处于相变状态的物理系统的性质相似。
-
超临界状态:
> 1 ( p>\(\frac{1}{N}\) ) 这个状态最接近于真实系统,该状态下的最大连通分支开始像网络了。在临界点附近,最大连通分支大小的变化遵循:
\[N_G /N ~ <k>-1 \]或者
\[N_G ~ (P-P_c)N \]这里的\(P_c=\frac{1}{N-1}≈\frac{1}{N}\)。换句话说,巨连通分支的相对大小不再是零。距离临界点越远,属于巨连通分支的节点所占的比例越大。注意,上面公式只在
=1附近有效。对于大的 ,\(N_G\)和 之间的依赖关系是非线性的。 总之,在超临界状态下,许多孤立的小连通分支和一个巨连通分支并存,这些连通分支的大小服从分布。这些小连通分支大多是树,而巨连通分支则由环或回路构成。超临界状态一直持续到所有节点都被巨连通分支吸收为止。
-
全连通状态:
> lnN ( p >\(\frac{InN}{N}\)) 当p足够大时,巨连通分支吸收了所有的节点,此时有\(N_G\)≌N。由于没有孤立节点存在,整个网络变成连通的了。这种状态发生时,网络的平均度取决于N:
\[<k>=lnN \]注意,在刚进入连通状态时,网络仍然是相对稀疏的。原因是:对于大的N,ln N/N→0。只有当
=N-1时,网络才变成完全图。 总之,随机网络模型预测,网络的出现不是一个流畅的渐进过程:
较小时观测到的孤立节点和小连通分支会经历一个相变,坍缩成一个巨连通分支。通过改变 ,我们可以观测到4个拓扑结构不同的状态。
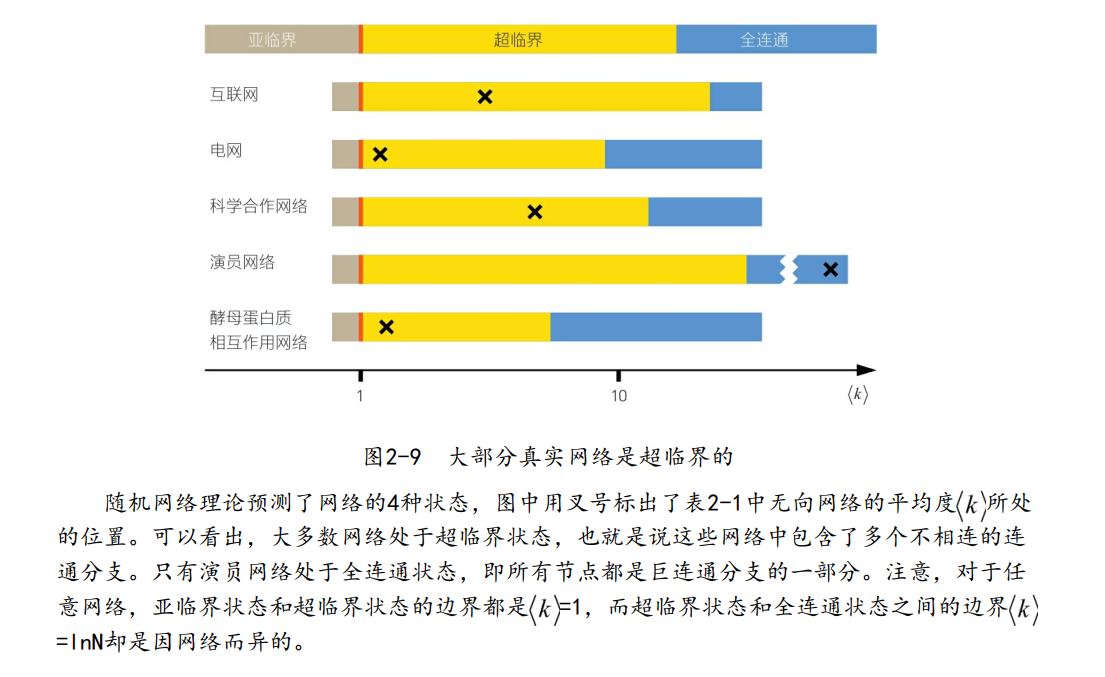
真实网络是超临界的
随机网络理论的两个预测对真实网络有着直接的重要性:
(1)一旦平均度超过
(2)当
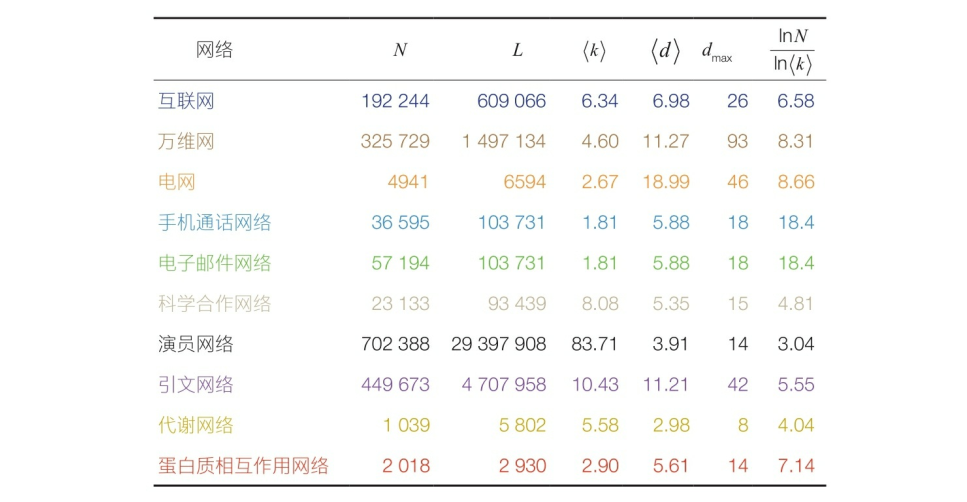
测量表明,真实网络的平均度大大超过了临界阈值
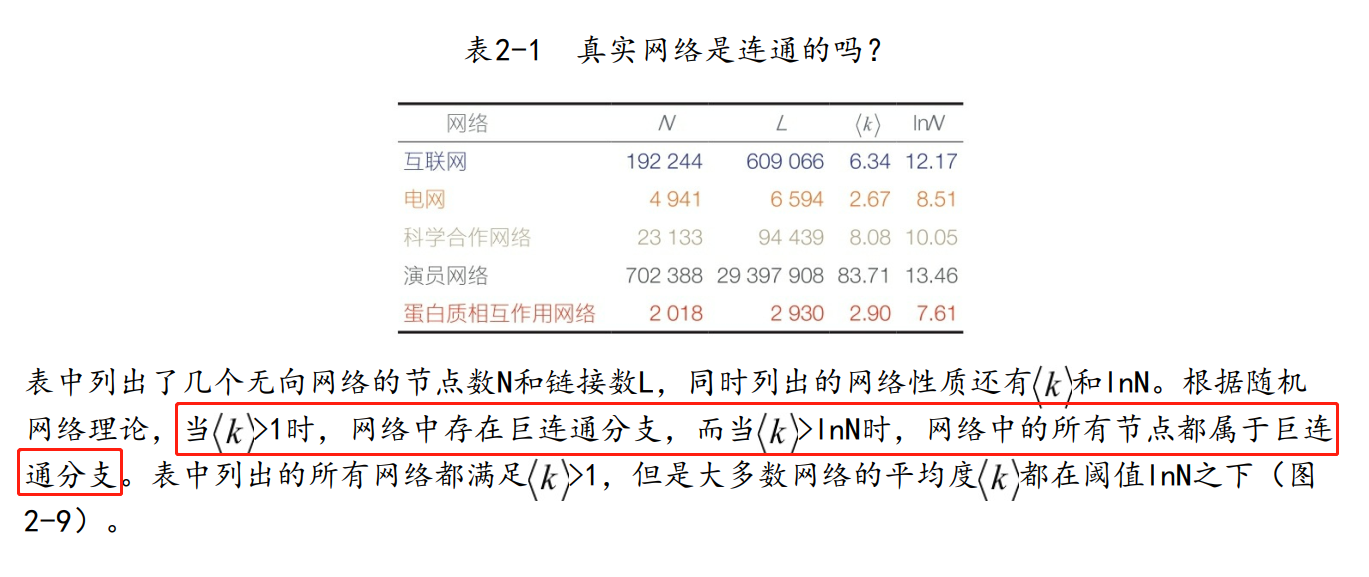
上表中列出了几个无向网络的平均度,每个网络的平均度都满足
我们现在考虑随机网络理论的第二个预测,看一下真实网络是仅由一个巨连通分支构成(
总之,我们发现大多数真实网络处于超临界状态(如下图)。因此,这些网络中存在巨连通分支,这与观察结果是一致的。不过,除了少数几个真实网络外,巨连通分支和一些彼此不连通的小连通分支同时存在。注意,这些预测只有当真实网络可以由埃尔德什―雷尼模型准确描述(真实网络是随机的)时才是有效的。
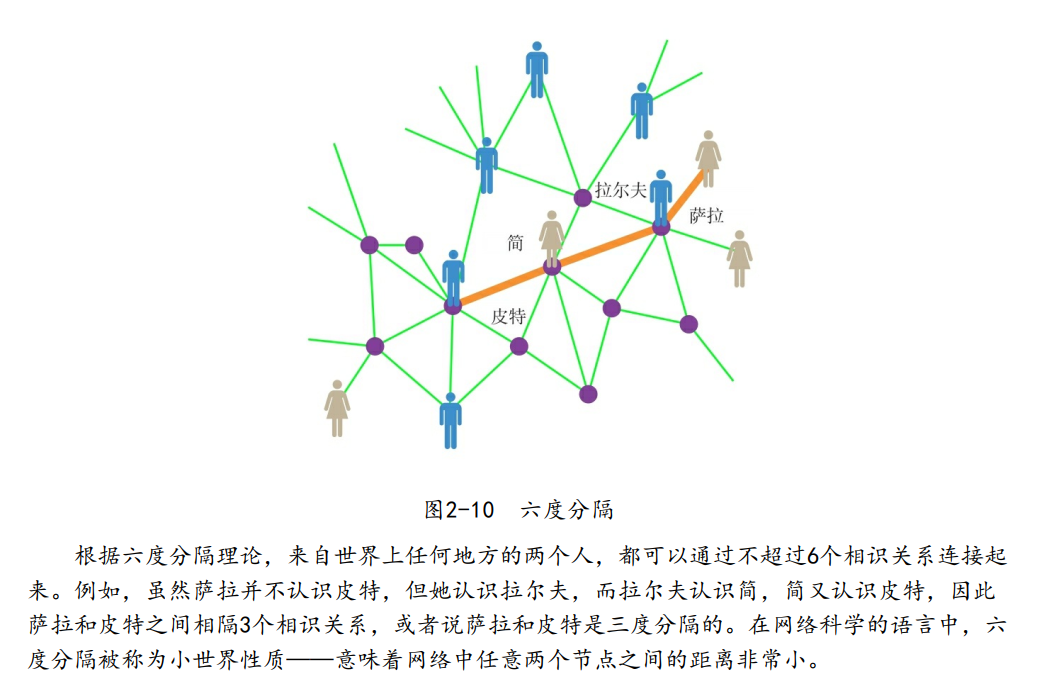
小世界
小世界现象——又称六度分隔,长期以来备受公众关注。
小世界现象指出,在地球上任意选择两个人,你会发现他们之间相隔最多6个相识关系。
如果说生活在同一个城市里的两个人彼此之间只相隔少数几个相识关系,你可能不会感到吃惊。然而,小世界概念告诉我们,即便是生活在地球上相对方位的两个人,彼此之间也只相隔少数几个相识关系。
随机网络的直径为:
该公式是小世界现象的数学表示。
公式给出了网络直径\(d_{max}\)和网络大小N之间的关系。然而,对大多数网络而言,和对网络直径\(d_{max}\)的近似相比,下面公式更好地提供了两个随机选择节点之间平均距离
公式中的项1/In(k )意味着,网络越稠密,节点间的距离越小。
真实网络中,公式需要进行系统修正。这源于这样一个事实:当d>
时,和起始节点距离为d的节点数目迅速减少。 我们现在来看一下公式对社交网络意味着什么。全球社交网络中,节点数为N≈7×\(10^9\),平均度为
≈\(10^3\),因此有:
= 3.28
因此,地球上所有人只相隔3~4个相识关系。公式的估计可能比人们经常提到的“六度”更接近真实值。
一般而言,lnN<<N。因此,平均距离
集聚系数
一个节点的度未包含该节点邻居之间关系的信息。这些邻居节点是彼此相连的还是相互孤立的?
这个问题可以用局部集聚系数\(C_i\)来回答,\(C_i\)反映了节点i的直接邻居之间的链接密度:\(C_i\)=O意味着节点i的邻居之间没有链接,\(C_i\)=1则意味着节点i的任意两个邻居之间都相互连接
对于随机网络中的一个节点i,要计算其集聚系数\(C_i\),我们需要估计出该节点的\(k_i\)个邻居之间的链接数\(L_i\)。随机网络中,节点i的两个邻居之间的链接概率是p。由于节点i的\(k_i\)个邻居之间最多有\(k_i\)(\(k_i\)-1)/2条链接,\(L_i\)的期望值为:
因此,随机网络的局部集聚系数为:
上面公式给出了两个预测:
(1)给定
(2)随机网络中,节点的局部集聚系数和节点的度相互独立。
为了测试上面公式的有效性,我们绘制了几个无向网络的
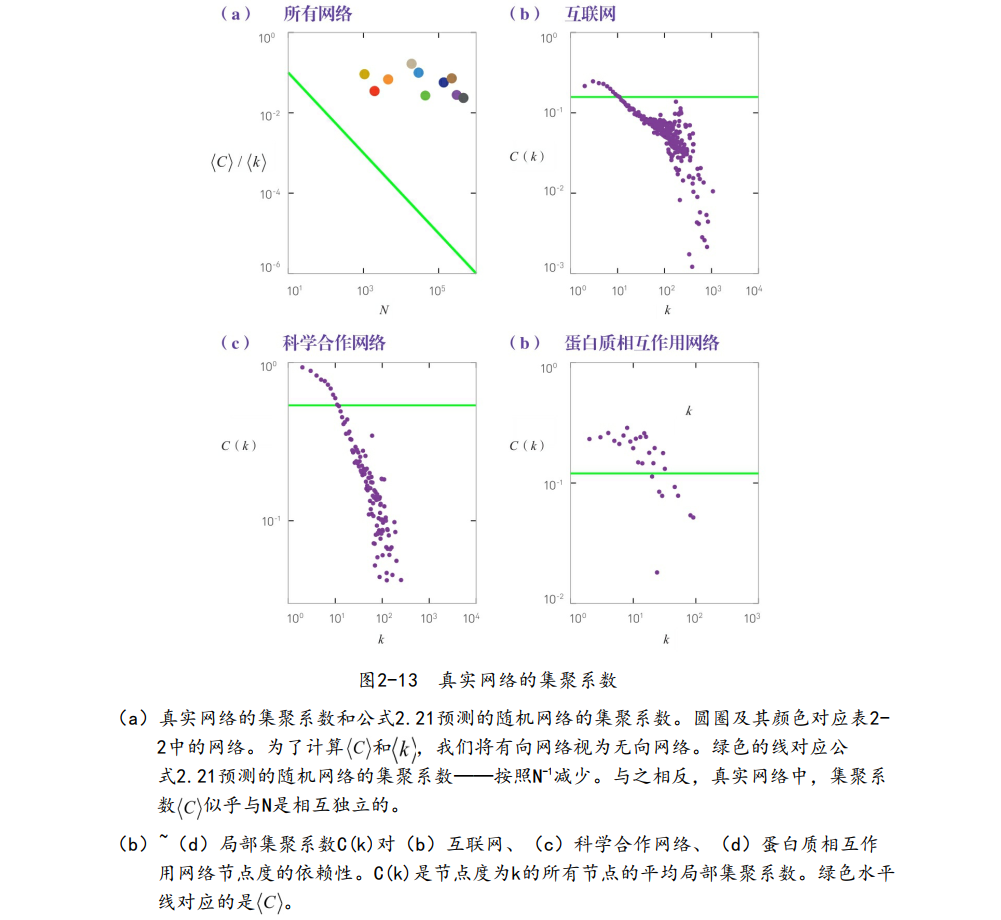
我们发现,
总之,随机网络模型不能刻画真实网络的集聚特性。相反,在具有同样的N和L的情况下,真实网络的集聚系数比随机网络预测的集聚系数要高得多。
小结∶真实网络不是随机的
我们真的相信真实网络是随机的吗?
答案显然是否定的。例如,蛋白质间的相互作用受严格的生物化学定律支配,因此,细胞要发挥其功用则其化学结构不可能是随机的。同样,在随机社会中,对一个美国学生而言,他的某个同学和中国工厂的某个工人成为他朋友的概率几乎相当。这似乎不合乎逻辑。
-
度分布
随机网络的度分布是一个二项分布,在k <<N的极限情况下可以通过泊松分布进行很好的近似。然而,泊松分布不能刻画真实网络的度分布。真实系统中,大度节点的数量要比随机网络模型预测的多得多。 -
连通性
随机网络理论预测,在
>1时,网络中会出现巨连通分支。不过,这些网络大多不满足 >lnN的条件。这意味着,除了巨连通分支,这些网络还包含一些孤立的小连通分支。实际上,除去少数几个网络,大部分真实网络中并不包含孤立的小连通分支。 -
平均路径长度
随机网络理论预测,平均路径长度服从公式\(<d> ≈ \frac{InN}{In<k>}\)。这是对实际观测路径长度的一个合理近似。因此,随机网络模型可以解释小世界现象的出现。 -
集聚系数
随机网络中,局部集聚系数和节点的度无关,以1/N依赖于网络大小N。相比之下,真实网络中实际测量出的C(k)随着节点度的增大而减小,且与网络大小基本无关。
总之,小世界现象是唯一可以由随机网络模型合理解释的性质。在真实网络中,从度分布到集聚系数等所有其他网络特性,都与随机网络有着显著差异。瓦茨和斯托加茨对埃尔德什一雷尼模型的扩展,成功地解释了高集聚系数C和低平均路径长度
这一结论自然而然地引出了一个疑问:既然真实网络不是随机的,为什么我们还要介绍随机网络模型呢?
答案很简单:在继续探讨真实网络的性质时,随机网络模型将会为我们提供一个重要参照。每当观测到某种网络性质时,我们都会问,该性质是否只是偶然出现的。为此,我们可以使用随机网络模型作为指南:如果该性质在随机网络中存在,则意味着它可以由随机性解释。如果该性质在随机网络中不存在,则它很可能标志着某种秩序——需要更深入的解释。因此,尽管随机网络模型对大多数真实系统而言可能是错误的,它对于网络科学仍然十分重要。
参考:
[1] [美] Albert-László Barabási.巴拉巴西网络科学[M].沈华伟,等,译.河南:河南科学技术出版社,2020
[2] 汪小帆,李翔,陈关荣.网络科学导论[M].北京:高等教育出版社,2012

 浙公网安备 33010602011771号
浙公网安备 33010602011771号