列表-元组
序列:指的是一种包含多项数据的数据结构,序列包含的多个数据项(也叫成员)按顺序排列,可以通过索引来访问成员
元组:不可变,即不可以修改其中的元素
列表:可变,即可以修改其中的元素

列表和元组的通用方法
【注意:只要不涉及改变元素的操作,列表和元组的用法都是通用的】
# 使用方括号定义列表
my_list = ['crazyit', 20, 'Python']
print(my_list)
# 使用圆括号定义元组
my_tuple = ('crazyit', 20, 'Python')
print(my_tuple)
a_tuple = ('crazyit', 20, 5.6, 'fkit', -17)
print(a_tuple) # ('crazyit', 20, 5.6, 'fkit', -17)
# 访问第1个元素
print(a_tuple[0]) # crazyit
# 访问第2个元素
print(a_tuple[1]) # 20
# 访问倒数第1个元素
print(a_tuple[-1]) # -17
# 访问倒数第2个元素
print(a_tuple[-2]) # -fkit
a_list = ['crazyit', 20, 5.6, 'fkit', -17]
print(a_list) # ['crazyit', 20, 5.6, 'fkit', -17]
# 访问第1个元素
print(a_list[0]) # crazyit
# 访问第2个元素
print(a_list[1]) # 20
# 访问倒数第1个元素
print(a_list[-1]) # -17
# 访问倒数第2个元素
print(a_list[-2]) # -fkit
切片
[start (包含) : end (不包含): step(当前下标+step)]
a_tuple = ('crazyit', 20, 5.6, 'fkit', -17)
0 1 2 3 4
-5 -4 -3 -2 -1
[start:end] 左闭右开!!!!
# 访问从第2个到第4个(不包含)所有元素
print(a_tuple[1: 3]) # (20, 5.6)
# 访问从倒数第3个到倒数第1个(不包含)所有元素
print(a_tuple[-3: -1]) # (5.6, 'fkit')
# 访问从第2个到倒数第2个(不包含)所有元素
print(a_tuple[1: -2]) # (20, 5.6)
# 访问从倒数第3个到第5个(不包含)所有元素
print(a_tuple[-3: 4]) # (5.6, 'fkit')
b_tuple = (1, 2, 3, 4, 5, 6, 7, 8, 9)
0 1 2 3 4 5 6 7 8
-9 -8 -7 -6 -5 -4 -3 -2 -1
# 访问从第3个到第9个(不包含)、间隔为2的所有元素
print(b_tuple[2: 8: 2]) # (3, 5, 7)
# 访问从第3个到第9个(不包含)、间隔为3的所有元素
print(b_tuple[2: 8: 3]) # (3, 6)
# 访问从第3个到倒数第2个(不包含)、间隔为3的所有元素
print(b_tuple[2: -2: 2]) # (3, 5, 7)、
print("************")
a_list = [1, 2, 3, 4, 5, 6, 7, 8]
print(a_list[2:6:2]) # [3, 5]
a_tuple = (1, 2, 3, 4, 5, 6, 7, 8)
print(a_tuple[2:6:2]) # (3, 5)
加法
列表只能加列表,元组只能加元组,列表与元组不能互加
a_tuple = ('crazyit' , 20, -1.2)
b_tuple = (127, 'crazyit', 'fkit', 3.33)
# 计算元组相加
sum_tuple = a_tuple + b_tuple
print(sum_tuple) # ('crazyit', 20, -1.2, 127, 'crazyit', 'fkit', 3.33)
print(a_tuple) # a_tuple并没有改变 ('crazyit', 20, -1.2)
print(b_tuple) # b_tuple并没有改变 (127, 'crazyit', 'fkit', 3.33)
# 两个元组相加
print(a_tuple + (-20 , -30)) # ('crazyit', 20, -1.2, -20, -30)
# 下面代码报错:元组和列表不能直接相加
#print(a_tuple + [-20 , -30])
a_list = [20, 30, 50, 100]
b_list = ['a', 'b', 'c']
# 计算列表相加
sum_list = a_list + b_list
print(sum_list) # [20, 30, 50, 100, 'a', 'b', 'c'] 列表相加其实是在调用extend()方法
print(a_list + ['fkit']) # [20, 30, 50, 100, 'fkit']
乘法
元组和列表可以和整数执行乘法运算,使得元素重复N次
a_tuple = ('crazyit' , 20)
# 执行乘法
mul_tuple = a_tuple * 3
print(mul_tuple) # ('crazyit', 20, 'crazyit', 20, 'crazyit', 20)
a_list = [30, 'Python', 2]
mul_list = a_list * 3
print(mul_list) # [30, 'Python', 2, 30, 'Python', 2, 30, 'Python', 2]
为了表示只有一个元素的元组,必须在唯一的元组元素之后添加英文逗号,例如("th",) 如果不加,则("th")和 "th" 相同
a_tuple = ('crazyit', )
a_tuple_test1 = ('crazyit')
a_tuple_test2 = 'crazyit'
print(type(a_tuple))
print(type(a_tuple_test1))
print(type(a_tuple_test2))
print(a_tuple_test2==a_tuple_test1)
print(a_tuple_test2 is a_tuple_test1) # 这条说明,【元组,不可变】如果有该变量,python不会新创建,而是使用已有的变量!!!!!!
输出:
<class 'tuple'>
<class 'str'>
<class 'str'>
True
True
a_list = ['crazyit', ]
a_list_test1 = ['crazyit']
a_list_test2 = 'crazyit'
print(type(a_list))
print(type(a_list_test1))
print(type(a_list_test2))
print(a_list_test2 == a_list_test1)
print(a_list_test2 is a_list_test1)
输出:
<class 'list'>
<class 'list'>
<class 'str'>
False
False
a_tuple_test1 = 'crazyit'
a_tuple_test2 = 'crazyit'
print(a_tuple_test2==a_tuple_test1)
print(a_tuple_test2 is a_tuple_test1) # 这条说明,如果有该变量,python不会新创建,而是使用已有的变量!!!!!!
输出:
True
True
in运算符
用于判断列表或元组是否包含某个元素
a_tuple = ('crazyit' , 20, -1.2)
print(20 in a_tuple) # True
print(1.2 in a_tuple) # False
print('fkit' not in a_tuple) # True
长度、最大值和最小值
| len() | 长度 |
|---|---|
| max() | 最大值(要求是同一类型的且可以比较大小) |
| min() | 最小值(要求是同一类型的且可以比较大小) |
# 元素都是数值的元组
a_tuple = (20, 10, -2, 15.2, 102, 50)
# 计算最大值
print(max(a_tuple)) # 102
# 计算最小值
print(min(a_tuple)) # -2
# 计算长度
print(len(a_tuple)) # 6
# 元素都是字符串的列表
b_list = ['crazyit', 'fkit', 'Python', 'Kotlin']
# 计算最大值(依次比较每个字符的ASCII码值,先比较第一个字符,若相同,继续比较第二个字符,以此类推)
print(max(b_list)) # fkit(26个小写字母的ASCII码为97~122)
# 计算最小值
print(min(b_list)) # Kotlin (26个大写字母的ASCII码为65~90)
# 计算长度
print(len(b_list)) # 4
序列封包和序列解包
序列封包(sequence packing):程序把多个值 【赋给】 一个变量时,Python会自动将多个值封装成元组。
序列解包(sequence unpacking):将序列(元组或者列表)直接 【赋值】 给多个变量,此时序列的各元素会被依次赋值给每个变量(要求序列的元素个数和变量个数相等)
# 【序列封包】:将10、20、30封装成元组后赋值给vals
vals = 10, 20, 30
print(vals) # (10, 20, 30)
print(type(vals)) # <class 'tuple'>
print(vals[1]) # 20
a_tuple = tuple(range(1, 10, 2))
# 【序列解包】: 将a_tuple元组的各元素依次赋值给a、b、c、d、e变量
a, b, c, d, e = a_tuple
print(a, b, c, d, e) # 1 3 5 7 9
a_list = ['fkit', 'crazyit']
# 【序列解包】: 将a_list序列的各元素依次赋值给a_str、b_str变量
a_str, b_str = a_list
print(a_str, b_str) # fkit crazyit
# 将10、20、30依次赋值给x、y、z
x, y, z = 10, 20, 30
print(x, y, z) # 10 20 30
# 将y,z, x依次赋值给x、y、z
x, y, z = y, z, x
print(x, y, z) # 20 30 10
【注意】
这里相当于:
先执行封包
xyz = 10,20,30
再执行解包
x,y,z = xyz
在序列 解包是也可以只解出部分变量
剩下的依然使用列表变量保存
为了使用这种解包方式,Python允许在左边被赋值的变量之前添加 “ * ” ,那么该变量就代表一个列表,可以保存多个集合元素。
# first、second保存前2个元素,rest列表包含剩下的元素
first, second, *rest = range(10) #[0,1,2,3,4,5,6,7,8,9]
print(first) # 0
print(second) # 1
print(rest) # [2, 3, 4, 5, 6, 7, 8, 9]
# last保存最后一个元素,begin保存前面剩下的元素
*begin, last = range(10)
print(begin) # [0, 1, 2, 3, 4, 5, 6, 7, 8]
print(last) # 9
# first保存第一个元素,last保存最后一个元素,middle保存中间剩下的元素
first, *middle, last = range(10)
print(first) # 0
print(middle) # [1, 2, 3, 4, 5, 6, 7, 8]
print(last) # 9
列表
【元组不可改变,列表可以改变】
【建议:虽然大部分时候都可以使用列表来代替元组,但是,如果程序 不需要修改 列表所包含的元素,那么使用元组代替列表会更安全】
创建列表
a_tuple = ('crazyit', 20, -1.2)
# 将元组转换成列表
a_list = list(a_tuple)
print(a_list) # ['crazyit', 20, -1.2]
# 使用range()函数创建区间(range)对象
a_range = range(1, 5)
print(a_range) # range(1, 5)
# 将区间转换成列表
b_list = list(a_range)
print(b_list) # [1, 2, 3, 4]
# 创建区间时还指定步长
c_list = list(range(4, 20, 3))
print(c_list) # [4, 7, 10, 13, 16, 19]
【扩展】
Python2.x提供了一个xrange()函数,该函数与Python3.x中的range()函数基本相同。Python2.x也提供了range()函数,但是该函数>返回的是列表对象
a_list = ['crazyit', 20, -1.2]
# 将列表转换成元组
a_tuple = tuple(a_list)
print(a_tuple) # ('crazyit', 20, -1.2)
# 使用range()函数创建区间(range)对象
a_range = range(1, 5)
print(a_range) # range(1, 5)
# 将区间转换成元组
b_tuple = tuple(a_range)
print(b_tuple) # (1, 2, 3, 4)
# 创建区间时还指定步长
c_tuple = tuple(range(4, 20, 3))
print(c_tuple) # (4, 7, 10, 13, 16, 19)
| 第一个元素 | 第二个元素 | ... | 第n-1个元素 | 第n个元素 | |
|---|---|---|---|---|---|
| 用正数 | 0 | 1 | n-2 | n-1 | |
| 用负数 | -n | -(n-1) | -2 | -1 |
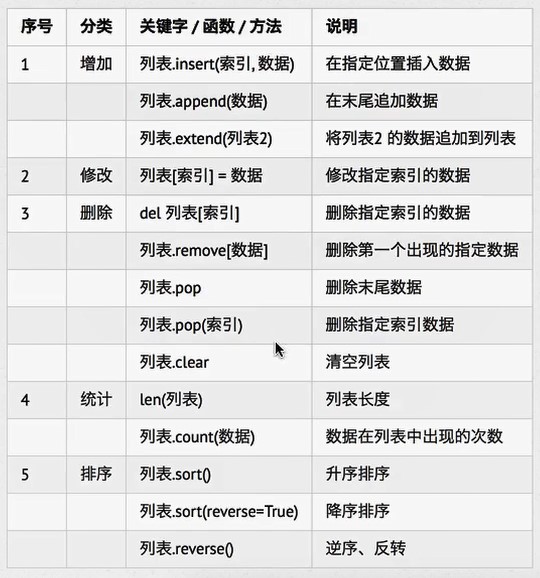
切片操作
切片操作 mylist[ start : stop : step] :不会改变列表本身
mylist=list(range(1,10,2)) #[1, 3, 5, 7, 9]
mylist1=mylist[:2] #[1, 3]
mylist2=mylist[:-1] #[1, 3, 5, 7]
print(mylist) #[1, 3, 5, 7, 9]
实现列表的反向遍历:
-
1、可以用下标 [: : -1] (即step=-1)的方式实现列表反向遍历【不改变列表本身】
mylist=list(range(1,10,2)) #[1, 3, 5, 7, 9]
mylist1=mylist[::-1]
print(mylist)
print(mylist1)输出:
[1, 3, 5, 7, 9]
[9, 7, 5, 3, 1] -
2、reversed()函数的返回值是一个迭代器,可以用list()强制转换的方式显示其取值内容 【不改变列表本身】
-
3、reverse()函数【改变列表本身】
mylist=list(range(1,10,2)) #[1, 3, 5, 7, 9] mylist1=mylist[::-1] mylist2=list(reversed(mylist)) print(mylist) #[1, 3, 5, 7, 9] print(mylist1) #[9, 7, 5, 3, 1] print(mylist2) #[9, 7, 5, 3, 1] print(mylist) #[1, 3, 5, 7, 9] mylist.reverse() print(mylist) #[9, 7, 5, 3, 1]
增加列表元素
extend与append的区别:
extend()平等追加
append()以成员身份追加
mylist=list(range(1,10,2)) #[1, 3, 5, 7, 9]
mylist1=mylist
print(mylist1+mylist) # [1, 3, 5, 7, 9, 1, 3, 5, 7, 9]
mylist1.extend(mylist)
print(mylist1) # [1, 3, 5, 7, 9, 1, 3, 5, 7, 9]
mylist1.append(mylist)
print(mylist1) # [1, 3, 5, 7, 9, 1, 3, 5, 7, 9, [...]]
a_list = ['crazyit', 20, -2]
# 追加元素
a_list.append('fkit')
print(a_list) # ['crazyit', 20, -2, 'fkit']
a_tuple = (3.4, 5.6)
# 追加元组,元组被当成一个元素
a_list.append(a_tuple)
print(a_list) # ['crazyit', 20, -2, 'fkit', (3.4, 5.6)]
# 追加列表,列表被当成一个元素
a_list.append(['a', 'b'])
print(a_list) # ['crazyit', 20, -2, 'fkit', (3.4, 5.6), ['a', 'b']]
b_list = ['a', 30]
# 追加元组中的所有元素
b_list.extend((-2, 3.1))
print(b_list) # ['a', 30, -2, 3.1]
# 追加列表中的所有元素
b_list.extend(['C', 'R', 'A'])
print(b_list) # ['a', 30, -2, 3.1, 'C', 'R', 'A']
# 追加区间中的所有元素
b_list.extend(range(97, 100))
print(b_list) # ['a', 30, -2, 3.1, 'C', 'R', 'A', 97, 98, 99]
此外,如果希望在列表中间增加元素,则可以使用 insert()方法,使用insert()方法时需要指定将元素插入列表的哪个位置。
c_list = list(range(1, 6))
print(c_list) # [1, 2, 3, 4, 5]
# 在索引3处插入字符串
c_list.insert(3, 'CRAZY' )
print(c_list) # [1, 2, 3, 'CRAZY', 4, 5]
# 在索引3处插入元组,元组被当成一个元素
c_list.insert(3, tuple('crazy'))
print(c_list) # [1, 2, 3, ('c', 'r', 'a', 'z', 'y'), 'CRAZY', 4, 5]
列表增删操作
列表 删 操作:
del语句
可以删除列表中的单个元素,也可以直接删除列表的中间一段
# 删除
a_list = ['crazyit', 20, -2.4, (3, 4), 'fkit']
# 删除第3个元素
del a_list[2]
print(a_list) # ['crazyit', 20, (3, 4), 'fkit']
# 删除第2个到第4个(不包含)元素
del a_list[1: 3]
print(a_list) # ['crazyit', 'fkit']
b_list = list(range(1, 10))
# 删除第3个到倒数第2个(不包含)元素,间隔为2
del b_list[2: -2: 2]
print(b_list) # [1, 2, 4, 6, 8, 9]
# 删除第3个到第5个(不包含)元素
del b_list[2: 4]
print(b_list) # [1, 2, 8, 9]
【扩展】del 语句还可以删除普通变量
name = 'crazyit'
print(name) # crazyit
# 删除name变量
del name
print(name) # NameError
remove()
只删除第一个找到的元素,如果找不到该元素,会引发ValueError
pop()
默认删除最后一个元素,也可以指定索引删除
clear()
删除全部元素
c_list = [20, 'crazyit', 30, -4, 'crazyit', 3.4]
# 删除第一次找到的30
c_list.remove(30)
print(c_list) # [20, 'crazyit', -4, 'crazyit', 3.4]
# 删除第一次找到的'crazyit'
c_list.remove('crazyit')
print(c_list) # [20, -4, 'crazyit', 3.4]
name_list.pop()
print(name_list) # ['张三', '小妹', 'haha', '王五', '赵六', '顺悟空', '唐山'] 【默认删除最后一个元素】
# name_list.pop(2) 删除指定索引元素
name_list.clear()
print(name_list) # [] 【删除全部元素】
修改列表元素
a_list = [2, 4, -3.4, 'crazyit', 23]
# 对第3个元素赋值【修改】
a_list[2] = 'fkit'
print(a_list) # [2, 4, 'fkit', 'crazyit', 23]
# 对倒数第2个元素赋值
a_list[-2] = 9527
print(a_list) # [2, 4, 'fkit', 9527, 23]
b_list = list(range(1, 5))
print(b_list) # [1,2,3,4]
# 将第2个到第4个(不包含)元素赋值为新列表的元素
b_list[1: 3] = ['a', 'b']
print(b_list) # [1, 'a', 'b', 4]
# 将第3个到第3个(不包含)元素赋值为新列表的元素,就是【插入】
b_list[2: 2] = ['x', 'y']
print(b_list) # [1, 'a', 'x', 'y', 'b', 4]
# 将第3个到第6个(不包含)元素赋值为空列表,就是删除
b_list[2: 5] = []
print(b_list) # [1, 'a', 4]
# Python会自动将str分解成序列
b_list[1: 3] = 'Charlie'
print(b_list) # [1, 'C', 'h', 'a', 'r', 'l', 'i', 'e']
c_list = list(range(1, 10))
# 指定step为2,被赋值的元素有4个,因此用于赋值的列表也必须有4个元素
【要求所赋值的列表元素个数与所替换的列表元素个数相等】
c_list[2: 9: 2] = ['a', 'b', 'c', 'd']
print(c_list) # [1, 2, 'a', 4, 'b', 6, 'c', 8, 'd']
name_list = ["张三", "李四", "王五", "赵六"]
print(name_list[2]) # 王五
print(name_list.index("王五")) # 2
name_list[1] = "haha"
print(name_list) # ['张三', 'haha', '王五', '赵六']
# 增加
name_list.append("王小二")
print(name_list) # ['张三', 'haha', '王五', '赵六', '王小二']
name_list.insert(1, "小妹")
print(name_list) # ['张三', '小妹', 'haha', '王五', '赵六', '王小二']
temp_list = ["顺悟空" , "唐山" , "大鸟"]
name_list.extend(temp_list)
print(name_list) # ['张三', '小妹', 'haha', '王五', '赵六', '王小二', '顺悟空', '唐山', '大鸟']
name_list = ["张三", "李四", "王五", "赵六"]
# 【知道即可】使用del关键字删除列表元素
# 提示:在日常开发中,要从列表删除数据,建议还是使用列表提供的方法
del name_list[1]
print(name_list) # ['张三', '王五', '赵六']
# del 关键字的本质是用来将一个变量从内存中删除的
name = "小明"
del name
print(name) # 报错,在会提示该变量为定义 【后面也不能继续使用该变量了】
列表的其他方法
count()
统计列表中某个元素出现的次数
name_list = ["张三", "李四", "王五", "赵六" , "张三"]
print(len(name_list)) # 5
print(name_list.count("张三")) # 2
print(name_list.remove("张三")) #None
print(name_list) # ['李四', '王五', '赵六', '张三']
【注意】
a_list = [2, 30, 'a', [5, 30], 30]
# 计算列表中30的出现次数
print(a_list.count(30)) # 2
# 计算列表中[5, 30]的出现次数
print(a_list.count([5, 30])) # 1
index()
判断某个元素在列表中出现的位置,如果无该元素,会引发ValueError
a_list = [2, 30, 'a', 'b', 'crazyit', 30]
# 定位元素30的出现位置
print(a_list.index(30)) # 1
# 从索引2处开始、定位元素30的出现位置
print(a_list.index(30, 2)) # 5
# 从索引2处到索引4处之间定位元素30的出现位置,找不到该元素
print(a_list.index(30, 2, 4)) # ValueError
reverse()
将列表中的元素反转
num_list = [2, 5 , 6 , 1]
num_list.reverse()
print(num_list) # [1, 2, 5, 6]
sort()
对列表排序
指定key参数为len,指定使用len函数对集合元素生成比较的键,也就是按字符串的长度比较大小
指定reverse=True,指定反向排序
num_list = [2, 5 , 6 , 1]
num_list.sort()
print(num_list) # [1, 2, 5, 6]
num_list.sort(reverse=True)
print(num_list) # [6, 5, 2, 1]
a_list = [3, 4, -2, -30, 14, 9.3, 3.4]
# 对列表元素排序
a_list.sort()
print(a_list) #[-30, -2, 3, 3.4, 4, 9.3, 14]
b_list = ['Python', 'Swift', 'Ruby', 'Go', 'Kotlin', 'Erlang']
# 对列表元素排序:默认按字符串包含的字符的编码大小比较
b_list.sort()
print(b_list) # ['Erlang', 'Go', 'Kotlin', 'Python', 'Ruby', 'Swift']
# 指定key为len,指定使用len函数对集合元素生成比较的键,
# 也就是按字符串的长度比较大小
b_list.sort(key=len)
print(b_list) # ['Go', 'Ruby', 'Swift', 'Erlang', 'Kotlin', 'Python']
# 指定反向排序
b_list.sort(key=len, reverse=True)
print(b_list) # ['Erlang', 'Kotlin', 'Python', 'Swift', 'Ruby', 'Go']
# 以下代码只能在Python 2.x中执行
# 定义一个根据长度比较大小的比较函数
def len_cmp(x, y):
# 下面代码比较大小的逻辑是:长度大的字符串就算更大
return 1 if len(x) > len(y) else (-1 if len(x) < len(y) else 0)
b_list.sort(len_cmp)
print(b_list) #['Go', 'Ruby', 'Swift', 'Erlang', 'Kotlin', 'Python']
pop()
用于将列表当成“栈”使用,实现元素的出栈功能
stack = []
# 向栈中“入栈”3个元素
stack.append("fkit")
stack.append("crazyit")
stack.append("Charlie")
print(stack) # ['fkit', 'crazyit', 'Charlie']
# 第一次出栈:最后入栈的元素被移出栈
print(stack.pop())
print(stack) # ['fkit', 'crazyit']
# 再次出栈
print(stack.pop())
print(stack) # ['fkit']
num_list = [2, 5 , 6 , 1]
for name in num_list:
print(name)
# 输出:
# 2
# 5
# 6
# 1
enumerate()函数
跟踪列表的下标
mylist = list(range(1, 10, 2))
print(list(enumerate(mylist)))
输出:
[(0, 1), (1, 3), (2, 5), (3, 7), (4, 9)]
zip()函数
数据科学项目中:
两个列表并列相加计算:zip()函数的功能为并行迭代
mylist=list(range(1,10,2)) #[1, 3, 5, 7, 9]
mylist1= mylist #[1, 3, 5, 7, 9]
result = [i + j for i,j in zip(mylist,mylist1)]
print(result) #[2, 6, 10, 14, 18]
print(list(zip(mylist,mylist1))) #[(1, 1), (3, 3), (5, 5), (7, 7), (9, 9)]
列表推导式:快速生成列表
print([2 for i in range(1,21)]) # 先做range(),再做i ,最后做2
# [2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
print([i for i in range(1,21)])
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
print(["input/%d.txt"%i + "dd%d"%i for i in range(5)]) # %d 为占位符,对应位置上显示的是 %i 的值
# ['input/0.txtdd0', 'input/1.txtdd1', 'input/2.txtdd2', 'input/3.txtdd3', 'input/4.txtdd4']
print([type(item) for item in [1,True,0.1,21]])
# [<class 'int'>, <class 'bool'>, <class 'float'>, <class 'int'>]
********************************解释**************************************
for item in [1,True,0.1,21]:
type(item)
等价于
[type(item) for item in [1,True,0.1,21]]
元素过滤技巧
list1 = [10,10,10,11,12,13,14,15]
print([x for x in list1 if x!=10]) # [11, 12, 13, 14, 15] 【过滤指定元素】
print(list1) # [10, 10, 10, 11, 12, 13, 14, 15]
print(list(filter(lambda i:i != 10, list1))) # [11, 12, 13, 14, 15] 【过滤指定元素】
print(list(set(list1))) # [10, 11, 12, 13, 14, 15] 【过滤重复元素】
元组
凡是用逗号分隔的都是元组
myTuple = 1,2,3,4
print(type(myTuple)) # <class 'tuple'>
不可变对象
不可以修改、赋值自身
myTuple = 1, 2, 3, 4
print(myTuple[2]) # 3
myTuple[2] = 3 # 报错!
强转
print(tuple("data")) # ('d', 'a', 't', 'a')
sorted()
myTuple = 1, 3, 4, 5
print(sorted(myTuple)) # [1, 3, 4, 5]
解释:
sorted()生成一个新的结果,其数据类型为列表
元组不存在sort()方法,因为元组是不可变对象,而sort()会改变自身
元组的频次统计
myTuple = 1, 3, 4, 5
print(myTuple.count(4)) # 1
print(max(myTuple)) # 5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号