
day30学习笔记,(4月14日)
awk
awk是什么
- grep,擅长单纯的查找或匹配文本内容
- sed,更适合编辑、处理匹配到的文本内容
- awk,更适合格式化文本内容,对文本进行复杂处理后、更友好的显示
三个命令称之为Linux的三剑客
awk的关键行和列
-
如何分割数据
-
如何输出数据
awk的语法格式
awk 指令是由模式,动作,或者模式和动作的组合组成.
- 模式即 pattern,可以类似理解成 sed 的模式匹配,可以由表达式组成,也可以使两个正斜杠之间的正则表 达式.比如 NR==1,这就是模式,可以把他理解为一个条件.
- 动作即 action,是由在大括号里面的一条或多条语句组成,语句之间使用分号隔开,如下 awk 使用格式
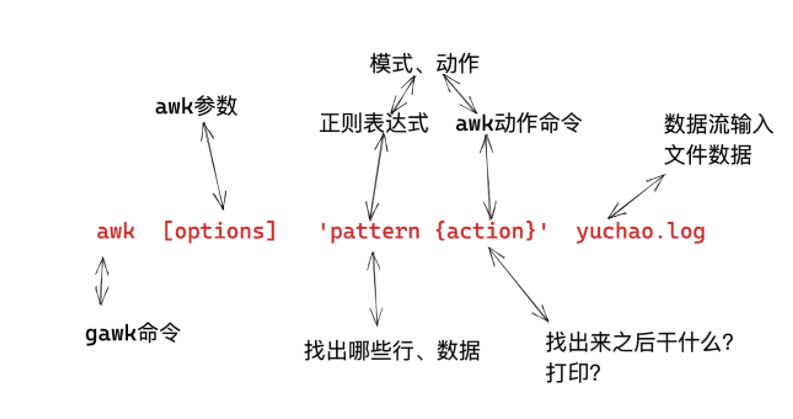
- Action指的是动作,awk擅长文本格式化,且输出格式化后的结果,因此最常用的动作就是
print
awk模式、动作
- 模式,是指要操作哪些行
- 动作,是指找到这些行之后,如何处理
- 建议每次操作都加上动作更加严谨
生成测试数据
echo cc{01..50} | xargs -n 5
cc01 cc02 cc03 cc04 cc05
cc06 cc07 cc08 cc09 cc10
cc11 cc12 cc13 cc14 cc15
cc16 cc17 cc18 cc19 cc20
cc21 cc22 cc23 cc24 cc25
cc26 cc27 cc28 cc29 cc30
cc31 cc32 cc33 cc34 cc35
cc36 cc37 cc38 cc39 cc40
cc41 cc42 cc43 cc44 cc45
cc46 cc47 cc48 cc49 cc50
写入文件,生成测试数据文件
echo cc{01..50} | xargs -n 5 > test.log
仅有动作(不加模式默认处理所有行)
关于字段的取值语法:
$0 表示所有字段数据
$1 第一列数据
$2 第二列数据
依次类推
。。。
1、输出所有的字段,即直接输出源文件的所有内容
awk '{print $0}' test_awk.log
2.输出所有行数据,只要第一列的数据
awk '{print $1}' test_awk.log
3. 输出所有行数据,只要第二列的数据
awk '{print $2}' test_awk.log
4. 输出所有行数据,只要 “第一列” 和 “第三列” 的数据
awk '{print $1,$3}' test_awk.log
行变量NR(匹配行)
- 指定对某一行处理
- 不指定行,默认是所有行
语法说明,
内置变量NR,表示awk处理的每一行
number of record (记录行数)
注意格式区分:
NR #直接打印这个内置变量,表示取当前行的号码
NR==n #表示输出第n行
NR 行
在开头显示行号
awk '{print NR,$0}' test_awk.log
在结尾显示行号
awk '{print $0,NR}' test_awk.log
------------------------------------------------------------
NR==行号 #表示输出第几行
打印第二行的所有字段数据
awk 'NR==2{print $0}' test_awk.log
打印第二行的,第1列和第4列数据
awk 'NR==2{print $1,$4}' test_awk.log
cc06 cc09
NR>= 大于等于行
NR<= 小于等于
NR>=N && NR<=M 从N行到M行
&& 且的用法(同时满足多个条件)
|| 或的用法(满足其中的条件)
示例:
提取出第二行到第五行
awk 'NR>=2&&NR<=5{print $0}' test_awk.log
列变量NF(每一列的字段)
#位置变量说明
number of field (字段的数量)
NF #表示列的总数,字段的总数
输出列:
, 输出分隔符,默认逗号,awk输出每一列的分隔符是,空格
$0 输出所有字段
$1 输出第一列
$2 输出第二列的数据
$3 输出第三类的数据
... 依次类推
$NF 输出最后一列
$(NF-1) 输出倒数第二列
。。。一次类推
注意区分:
#输出最后一列
awk '{print $NF}' test_awk.log
#在所有行后,统计出字段的总数(查看每一行有多少个字段)
awk '{print $0,NF}' test_awk.log #直接写NF变量表示每一行字段的总数
模式+动作(指定行,指定列)
#提取出第二行到第五行,并且只打印 前三列 的数据
awk 'NR>=2&&NR<=5{print $1,$2,$3}' test_awk.log
#打印所有行和列,在每行后面加上字段总数和行号
awk '{print $0,NF,NR}' test_awk.log
cc01 cc02 cc03 cc04 cc05 5 1
cc06 cc07 cc08 cc09 cc10 5 2
cc11 cc12 cc13 cc14 cc15 5 3
cc16 cc17 cc18 cc19 cc20 5 4
cc21 cc22 cc23 cc24 cc25 5 5
cc26 cc27 cc28 cc29 cc30 5 6
cc31 cc32 cc33 cc34 cc35 5 7
cc36 cc37 cc38 cc39 cc40 5 8
cc41 cc42 cc43 cc44 cc45 5 9
cc46 cc47 cc48 cc49 cc50 5 10
#打印前四行数据,要求输出每一行的行号、字段数、以及对应行的数据
awk 'NR<=4{print NR,NF,$0 }' test_awk.log
1 5 cc01 cc02 cc03 cc04 cc05
2 5 cc06 cc07 cc08 cc09 cc10
3 5 cc11 cc12 cc13 cc14 cc15
4 5 cc16 cc17 cc18 cc19 cc20
图解模式、动作
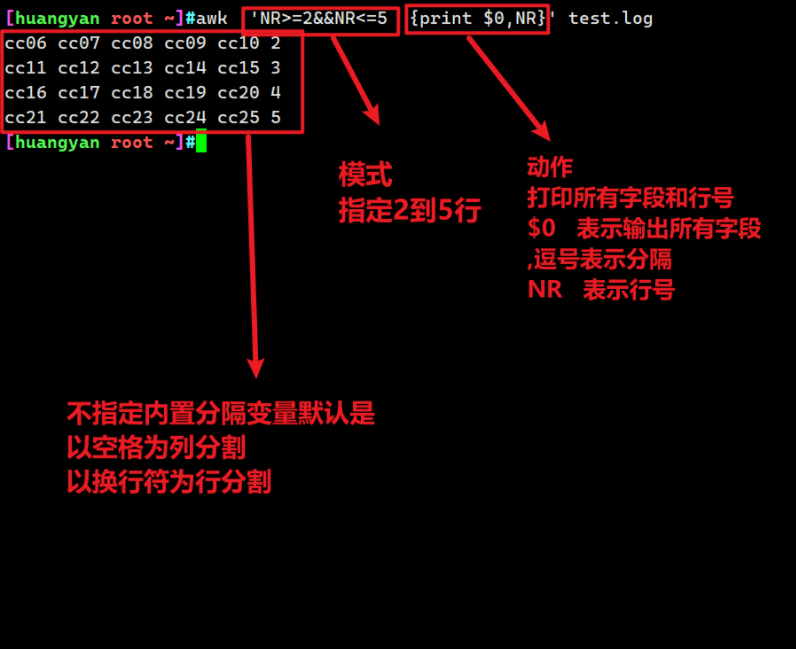
只有模式,不写动作(不建议使用)
awk不指定动作,默认打印整行信息
提取前五行的数据,请务必加上动作,且显示行号在前面
awk 'NR<=5{print NR,$0}' test_awk.log
awk快速入门小结
-
pattern和action都要用单引号,防止shell作特殊解释(是交给awk去执行的,而不是bash)
-
不指定模式,awk默认处理输入的文件数据,每一行,每一列
- 如果指定模式,例如指定的行,awk就处理指定那一行的数据
-
awk的动作,必须写在花括号里
{print},括号里写入awk提供的命令。
- 如果没有
{ }花括号,就会被识别为patter,而不是action
- 如果没有
-
注意给awk传入数据,一般都是file
-
也可以是管道传递的数据
拿到第二行的,倒数第二列的数据
cat test_awk.log | awk 'NR==2{print $(NF-1)}'
cc09
awk参数
-F 指定分割字符段
-v 定或修一个awk内部变量
awk内置变量
| a作用wk内置变量 | 名称翻译 | 作用 |
|---|---|---|
| NR | Number of Record(行号记录) | NR行号,NR==n处理文本的行号 |
| NF | Number of Filed(字段数量) | 字段的数量,表示这一行数据分了几列 |
| FS | Filed Separator(字段分割) | 输入字段的分隔符,默认为空白字符 |
| OFS | Output Filed Separator(输出字段分割) | 输出字段分隔符,默认为空白字符 |
| RS | Record Separator(记录分割) | 输入换行字符,指定输入时的换行字符 |
| ORS | Output Record Separator(输出记录分割) | 输出是指定符号代替换行符 |
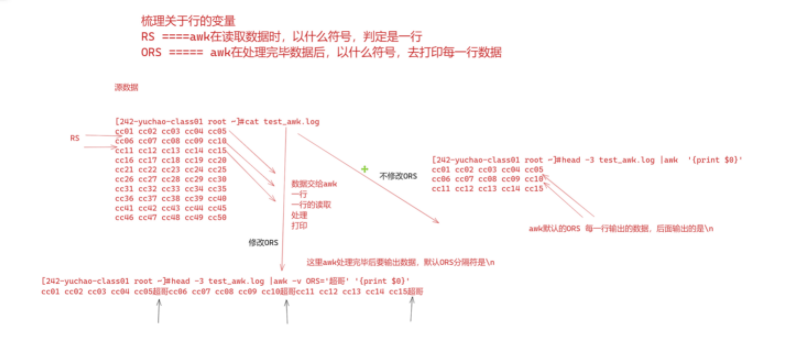
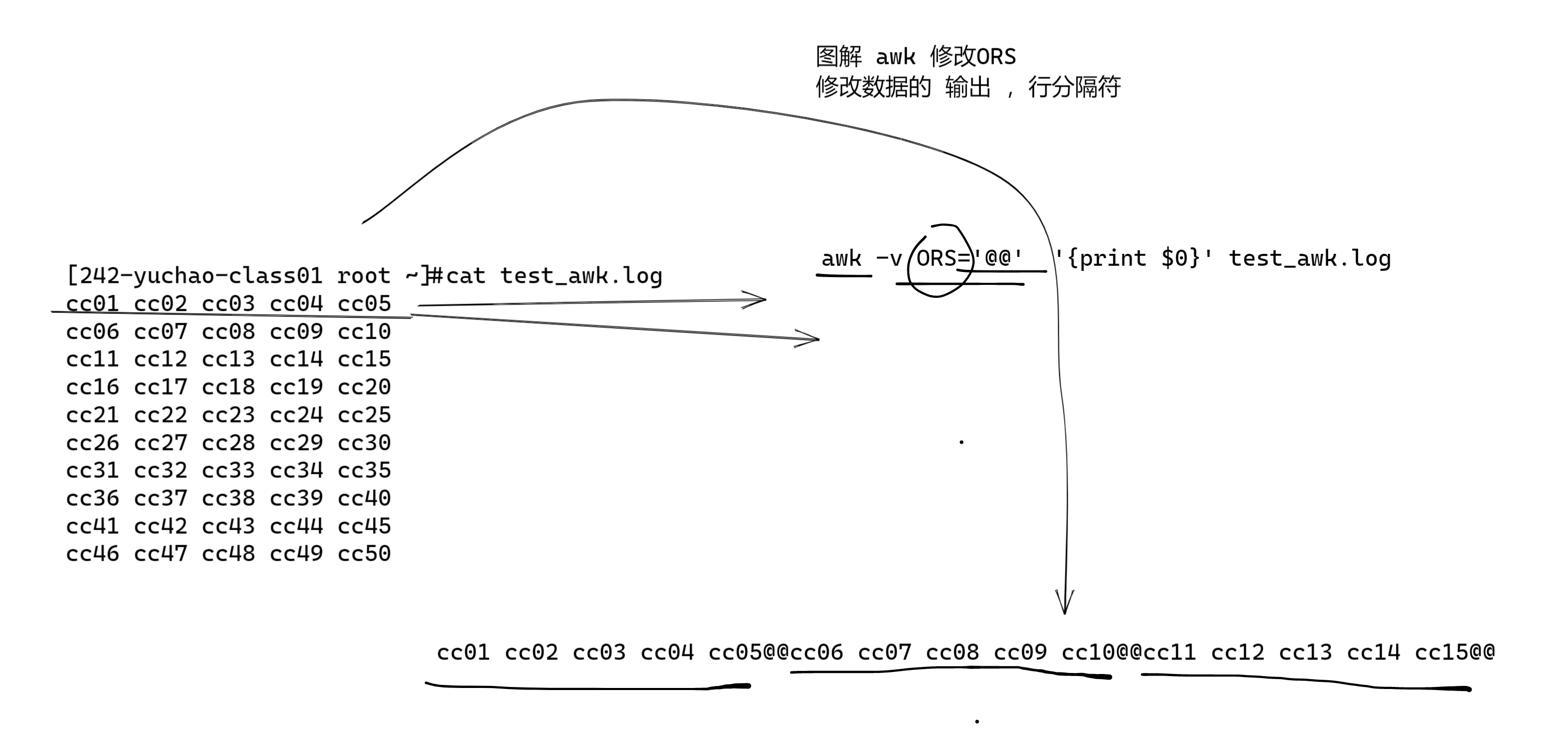
图解FS内置变量(列分割变量)

图解RS(行变量)

修改FS和OFS效果

修改RS和ORS效果
实践练习
测试数据:
cc01 cc02 cc03 cc04 cc05
cc06 cc07 cc08 cc09 cc10
cc11 cc12 cc13 cc14 cc15
cc16 cc17 cc18 cc19 cc20
cc21 cc22 cc23 cc24 cc25
cc26 cc27 cc28 cc29 cc30
cc31 cc32 cc33 cc34 cc35
cc36 cc37 cc38 cc39 cc40
cc41 cc42 cc43 cc44 cc45
cc46 cc47 cc48 cc49 cc50
要求修改每一个数据之间的分隔符,改为#号
awk -v OFS='#' '{print $1,$2,$3,$4,$5}' test_awk.log
($1 ,$2 是字段之间的逗号,和OFS对应)
修改/etc/passwd的格式
修改原本用户信息的冒号分隔符、改为---
提取出 root、家目录、登录解释器
head -5 /etc/passwd|awk -v FS=':' -v OFS='---' 'NR==1{print $1, $(NF-1),$NF}'
总结
- RS和ORS
- RS、输入记录分隔符,决定awk如何分隔每一行(默认是\n)
- ORS,输出记录分隔符,决定awk如何输出每一行(默认是\n)
- FS和OFS
- FS是输入字段分隔符,决定awk输入数据后的每一个字段分隔符是什么,默认是空格
- OFS是输出字段分隔符,决定awk输出每个字段的分隔符是什么,默认是空格
总结行、列
- RS、ORS、代表了awk的输入、输出、关于
行的分隔符 - FS、OFS、代表了awk的输入、输出、关于
列的分隔符- 对于不同的文本,需要选择合适的FS、合适的菜刀,来分割出左右可以便于提取的数据
- NR表示行号、记录号
- NF表示每一行的字段数、有多少列
- $符号一般用于提取某一列的数据,如$1、$2
- $NF表示最后一列的数据
面试题,统计单词出现频率
I have a dog, it is lovely, it is called Mimi. Every time I go home from school, Mimi always cruising around me, I will go to the kitchen to get a piece of meat to it, it lay on the floor to eat. My legs and then jump to bark "Wang "called, so I picked up Mimi, it is the opportunity to lick my hand, making me laugh.I like Mimi, like puppies.
答题思路:
1.将一整行的数据,改为,每一个单词,就是一行
2.改为这样后,就可以交给sort -r去排序了
3.再去uniq 去重 -c 统计重复的次数
4、重新逆序排序,更加直观
awk答题
关键点:
修改awk输入内置分隔变量RS,设置空格或者标点作为分隔的标准
awk -v RS='[^a-zA-Z]+' '{print $0}' test.log |sort | uniq -c | sort -nr
sed答题
关键点:
将标点符号或者空格替换成换行符,实现一个单词一行
sed -r 's#[^a-zA-Z]+#\n#gp' test.log |sort | uniq -c | sort -nr
grep答题
关键点:
直接用正则表达式(一个或多个连续的字母),找出所有的单词即可
grep -Eo '[grep -Eoa-zA-Z]+' test.log |sort | uniq -c | sort -nr
awk结合正则使用
1.显示root行所有信息
awk -v FS=':' '/root/{print $0}' /etc/passwd
2.仅显示root用户名、家目录、登录解释器
awk -v FS=':' '/^root/{print $1,$(NF-1),$NF}' /etc/passwd
3.awk提取出允许登录的用户名
awk -v FS=':' '/bash$/{print $1}' /etc/passwd
4.提取出禁止登录的用户(nologin用户,非bash用户)
awk -F ':' '$NF ~ "/sbin/nologin" {print $1,$5,$NF}' /etc/passwd
awk -F ':' '$NF ~ "/bin/bash" {print $1,$5,$NF}' /etc/passwd
5、找出root到nobody的行
awk -v FS=':' '/root/,/nobody/{print $0}' /etc/passwd
特殊模式
BEGIN模式
- BEGIN模式作用是在awk开始读取文件行数据、之前就先执行,一般用于预定义一些操作,比如数据的表头格式化等。
- BEGIN后面必须跟上action动作
语法
awk 'BEGIN{print "你好"}{print $0}'
END{} 特殊模式
语法
awk 'BEGIN{print "你好 "} 模式 {动作} END{print "awk完事了"}'
格式化制表符column -t
实践
提取nobody用户名、uid、登录解释器,且添加该行首字段,格式化显示,以及添加结尾动作,awk格式化完毕
awk -F ":" 'BEGIN{print "用户名","uid","登录解释器"}/^nobody/{print $1,$3,$NF}END{print "awk格式化完毕"}' /etc/passwd |column -t
用户名 uid 登录解释器
nobody 99 /sbin/nologin
awk格式化完毕

 浙公网安备 33010602011771号
浙公网安备 33010602011771号