
day28学习笔记(4月12日)
正则表达式和扩展正则表达式
通配符和正则的区别
1.从语法上就记住,只有awk、gre、sed才识别正则表达式符号、其他都是通配符
2.从用法上区分
- 表达式操作的是文件、目录名(属于是通配符)
- 表达式操作的是文件内容(正则表达式)
什么是正则表达式
- 正则表达式就是为了处理大量的字符串而定义的一套规则和方法。
- 通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串。
- Linux 正则表达式一般以行为单位处理的。
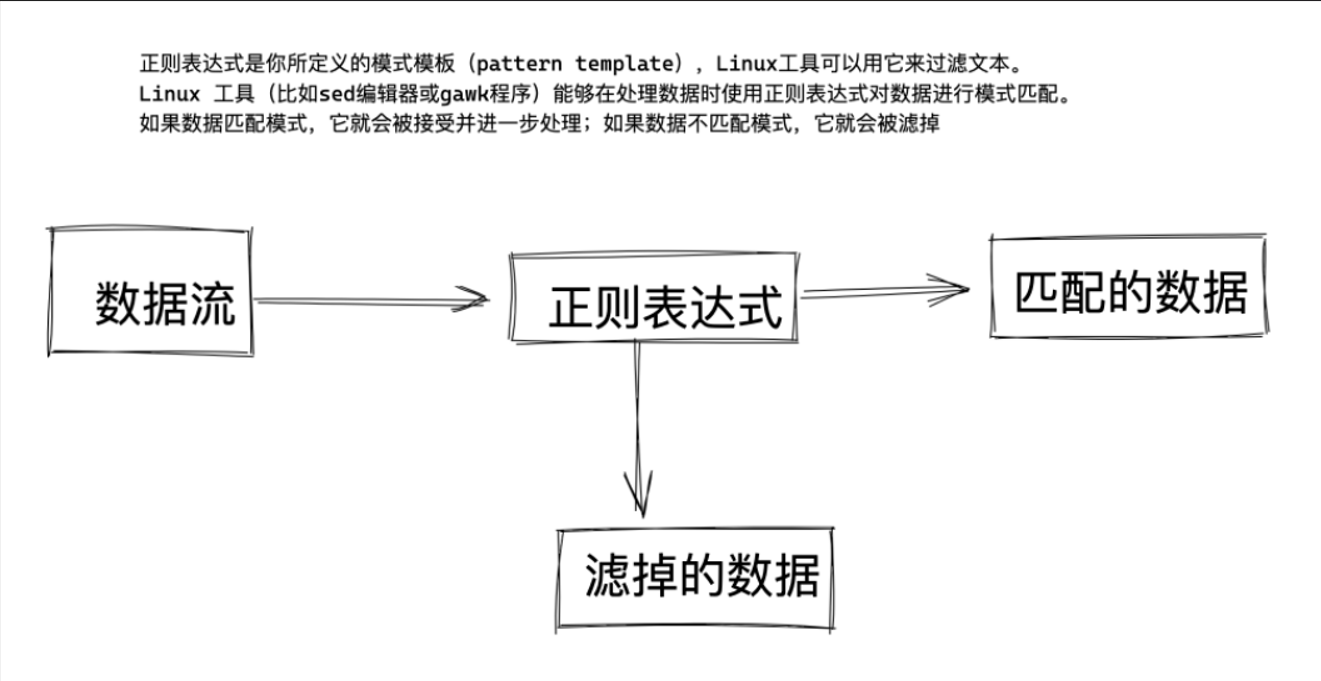
如何用正则表达式
通常Linux运维工作,都是面临大量带有字符串的内容,如
- 配置文件
- 程序代码
- 命令输出结果
- 日志文件
且此类字符串内容,我们常会有特定的需要,查找出符合工作需要的特定的字符串,因此正则表达式就出现了
- 正则表达式是一套规则和方法
- 正则工作时以单位进行,一次处理一行
- 正则表达式化繁为简,提高工作效率
- linux仅受三剑客(sed、awk、grep)支持,其他命令无法使用
学正则的注意事项
- 正则表达式应用非常广泛,很多编程语言都支持正则表达式,用于处理字符串提取数据。
- Linux下普通命令无法使用正则表达式的,只能使用linux下的三个命令,结合正则表达式处理。
- sed
- grep
- awk
- 通配符是大部分普通命令都支持的,用于查找文件或目录
- 而正则表达式是通过三剑客命令在文件(数据流)中过滤内容的,注意区别
- 以及注意字符集,需要设置
LC_ALL=C,注意这一点很重要
关于字符集设置
你会发现很多shell脚本里都有这么一个语句如下

作用是修改linux的字符集,通过locale命令可以查看本地字符集设置
linux通过如下变量设置程序运行的不同语言环境,如中文、英文环境。
[root@yuchao-tx-server ~]# locale
LANG=en_US.UTF-8
LC_CTYPE="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
LC_TIME="zh_CN.UTF-8"
LC_COLLATE="zh_CN.UTF-8"
LC_MONETARY="zh_CN.UTF-8"
LC_MESSAGES="zh_CN.UTF-8"
LC_PAPER="zh_CN.UTF-8"
LC_NAME="zh_CN.UTF-8"
LC_ADDRESS="zh_CN.UTF-8"
LC_TELEPHONE="zh_CN.UTF-8"
LC_MEASUREMENT="zh_CN.UTF-8"
LC_IDENTIFICATION="zh_CN.UTF-8"
LC_ALL=zh_CN.UTF-8
一般我们会使用$LANG变量来设置linux的字符集,一般设置为我们所在的地区,如zh_CN.UTF-8
[root@yuchao-tx-server ~]# echo $LANG
en_US.UTF-8
为了让系统能正确执行shell语句(由于自定义修改的不同语言环境,对一些特殊符号的处理区别,如中文输入法,英文输入法下的标点符号等,导致shell无法执行)
我们会使用如下语句,恢复linux的所有的本地化设置,恢复系统到初始化的语言环境。
[root@yuchao-tx-server ~]# export LC_ALL=C
正则表达式分类
使用正则表达式的问题是、有两大类正则表达式规范、linux不同的应用程序,会使用不同的正则表达式。
例如
- 不同的编程语言使用正则(python,java)
- Linux实用工具(sed、awk、grep)
- 其他软件使用正则(mysql、nginx)
正则表达式是通过正则表达式引擎(regular expression engine)实现的。正则表达式引擎是 一套底层软件,负责解释正则表达式模式并使用这些模式进行文本匹配。
在Linux中,有两种流行的正则表达式引擎:
基于unix标准下的正则表达式符号规则有两类:
POSIX基础正则表达式(basic regular expression,BRE)引擎
POSIX扩展正则表达式(extended regular expression,ERE)引擎
解释posix
POSIX(Portable Operating System Interface)是Unix系统的一个设计标准。
当年最早的Unix,源代码流传出去了,加上早期的Unix不够完善,于是之后出现了好些独立开发的与Unix基本兼容但又不完全兼容的OS,通称Unix-like OS
两类、正则表达式符号
linux规范将正则表达式分为了两种
- 基本正则表达式(BRE、basic regular expression)
BRE对应元字符有
^ $ . [ ] *
其他符号是普通字符
; \
- 扩展正则表达式(ERE、extended regular expression)
ERE在在BRE基础上,增加了
( ) { } ? + | 等元字符
- 转义符
反斜杠 \
反斜杠用于在元字符前添加,使其成为普通字符
正则符号
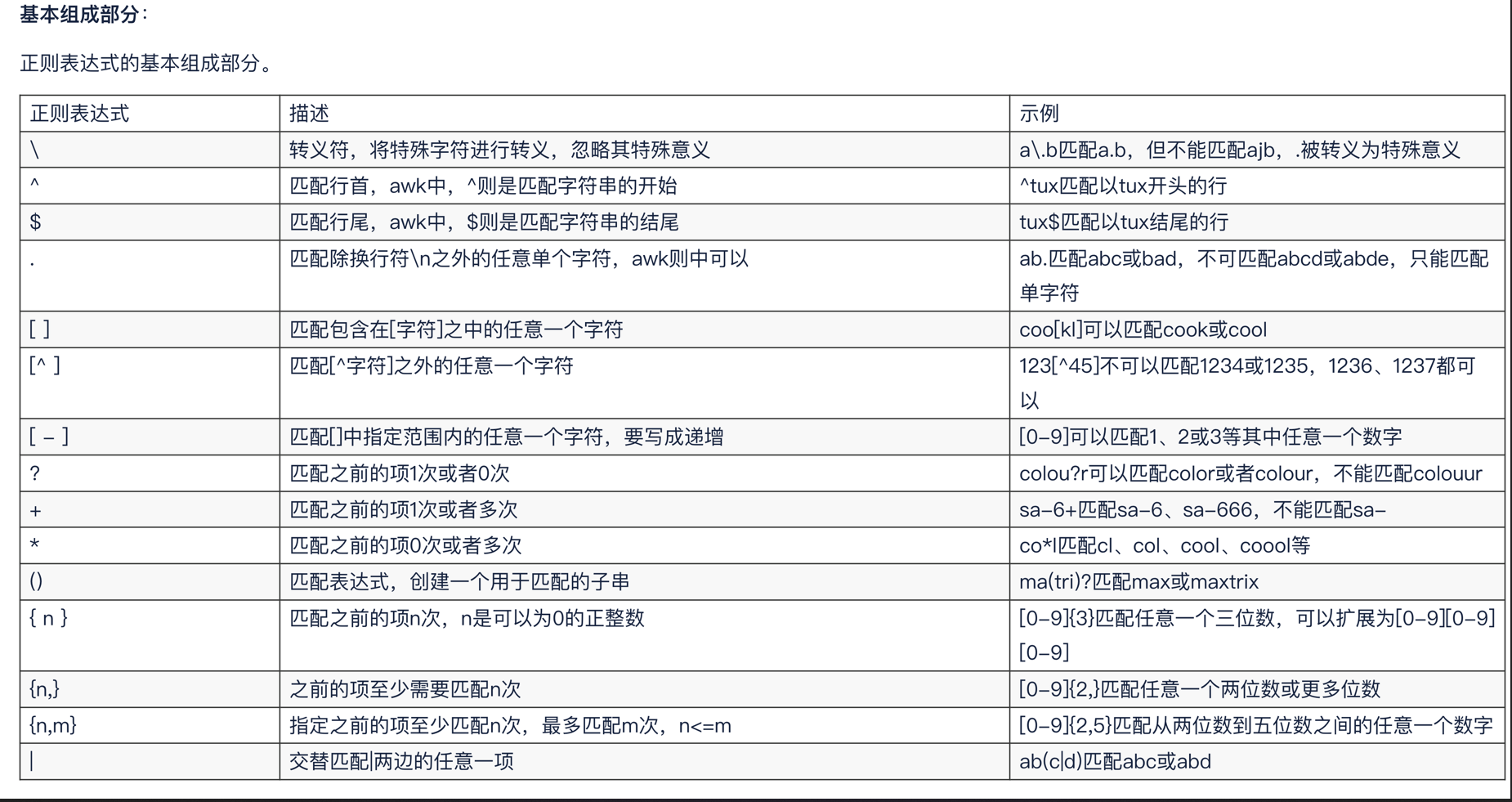
| 字符 | 描述 | 示例 |
|---|---|---|
| \ | 转义字符,将特殊符号进行转义,忽略其特殊意义 | a\.b只匹配a.b不能匹配acb |
| ^ | grep匹配最左侧字符,表示匹配以什么开头 | ^yy,表示以yy开头的行 |
| $ | grep匹配行末 | yy$表示以yy结尾 |
| ^$ | 表示空行 | |
| . | 匹配除了换行符意外的所有内容,字符+空格(不匹配换行符和空行) | ab. 能匹配abc,abd |
| .$ | 匹配任意符号结尾的行 | |
| * | 匹配前一个字符连续出现0次或n次,即匹配所有内容 | |
| .* | 匹配任意内容的行,包括空行 | |
| ^.* | 匹配任意多个字符开头的行,包括空行 | |
| [ ] | 匹配括号内的字符或数字 | [abc],a或b或c |
扩展正则符号
| 字符 | 描述 | 示例 |
|---|---|---|
| + | 前面字符出现1次或n次 | go+d 匹配结果可以是god,good,goood |
| () | 创建一个字符组 | max(tri)?匹配max或maxtri |
| ? | 匹配前一项0次或1次 | go?d 匹配结果只能是god,good |
| 匹配之前的项n次,n是可以为0的正整数 | [0-9]{3}匹配任意一个三位数,可以扩展为[0-9][0-9][0-9][0-9] |
|
| 之前的项至少需要匹配N次 | [0-9]{2,}匹配任意一个两位数或更多位数 | |
| 指定之前的项至少匹配n次,最多匹配m次,n<=m | [0-9]{2,5}匹配任意一个两位数或者更多位数 | |
| | | 交替匹配两边任意一项 | ab(c|d),匹配abc或abd |
正则记忆表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号