
异常检测(Anomaly detection): 异常检测算法(应用高斯分布)
估计P(x)的分布--密度估计

我们有m个样本,每个样本有n个特征值,每个特征都分别服从不同的高斯分布,上图中的公式是在假设每个特征都独立的情况下,实际无论每个特征是否独立,这个公式的效果都不错。连乘的公式表达如上图所示。
估计p(x)的分布问题被称为密度估计问题(density estimation)
异常检测算法

1>找出一些能观察出异常行为的特征,尽可能尝试选择能够描述数据相关属性的特征。
2> 根据样本估计出参数的值,有n个特征每个特征都服从不同的正态分布,有不同的u和σ2,分别对这些u和σ2进行参数估计。
3> 检测新样本是否为异常值,需要计算出它的概率p(x),在上一步我们已经各个不同features的概率分布,通过联合概率来计算p(x),如果p(x)<ε,则它为异常值。
例子
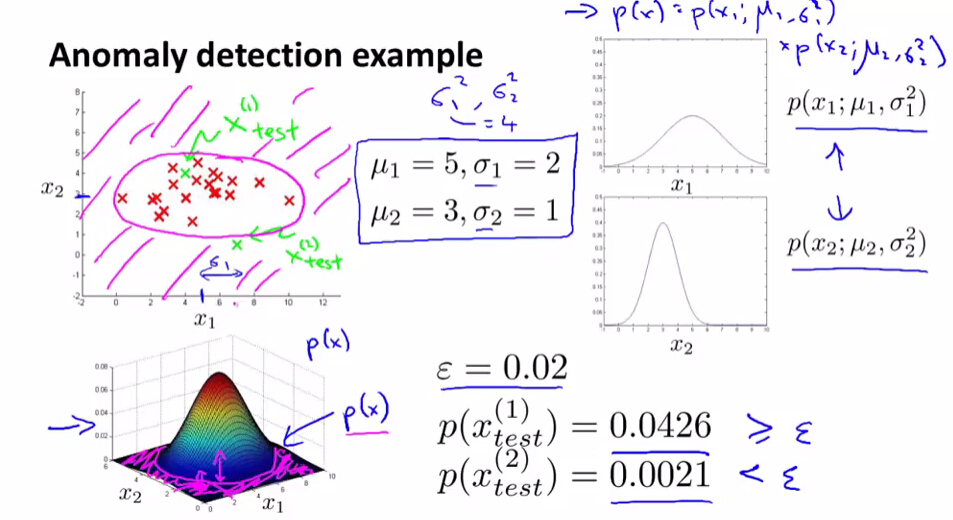
我们根据我们的样本点(红色的点)估计出参数值(u1,u2,σ1,σ2)
对于给定的点,x(1)test和x(2)test计算它的p(x)=p(x1)*p(x2),给定ε为一个较小的值(0.02,对于ε如何取值将在后面讲到),判定p(x)是否小于ε来判断它是否为异常点。
从上图所示的三维图上来看,粉红色圈里面的点的高度(即p(x)的值)较外面的高,里面的点为正常点,外面的点为异常点。
总结
1>如何计算出p(x)来开发一种异常检测算法
2>通过给出的数据集进行参数估计,得到参数u和σ,然后检测新的样本,确定新样本是否异常,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号