

Django之操作数据库
1:数据库:
2:MySQL驱动程序的安装
3:Django配置连接数据库
4:在Django中操作数据库
(1)原生SQL语句操作
(2)ORM模型操作
5:ORM模型的介绍
6:创建一个ORM模型并映射模型到数据库中
7:模型常用的属性
(1)常用的Field字段
(2)Field字段常用的参数
(3)模型中Meta的配置
8:外键
9:表关系
(1)一对一
(2)一对多(多对一)
(3)多对多
10:模型的操作
(1)数据的增删改查
(2)聚合函数
(3)aggregate和annotate的区别
(4)F表达式和Q表达式
11:查询集(QuerySet)
12:ORM模型迁移
-------------------------------------------------------------------------------------------------------------------------------
1数据库:简而言之就是存放数据的一个库,用户可以对数据进行增删改查;是网站重要的一个组成部分,只有提供了数据库,网站才能动态的展示。常用的数据库有MySQL,Oracle等。
2MySQL驱动程序的安装:我们使用Django来操作mysql,实际上底层使用的还是python;因此如果我们想要操作数据库首先要安装一个驱动;python3中有多个驱动可供选择如下;
(1)MySql-python :也就是MySQLdb 。是对C语言操作mysql的一个简单封装;只支持python2,不支持python3,运行速度最快。
(2)mysqlclient:是MySql-python的另一个分支,支持python3。
(3)pymsql:纯python实现的一个驱动,效率不高,可以和python无缝连接。
(4)mysql-connector-python:mysql官方推出的,纯python开发的,效率不高
本文使用的是mysqlclient: 安装方式: pip install mysqlclient
3:Django配置连接数据库:在操作数据库之前需要Django先连接上数据库,不需要单独创建一个连接对象,只需要在setting中做好相关的配置即可。
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', #数据库引擎(mysql还是Oracle) 'NAME': "my01", #数据库的名字 "USER":"root", #数据库的用户名 "PASSWORD":"qwe123", #数据库密码 "HOST":"localhost", #数据库的主机地址 "PORT":"3306" #数据库的端口号 } }
4:在Django中操作数据库:Django操作数据库有两种方式。第一种是原生的SQL语句操作,另一种是ORM模型操作
(1)原生SQL语句操作
缺点:(1)重复利用率不高(2)不易修改(3)安全问题(SQL注入)
(2)ORM模型操作
5:ORM模型的介绍
(1)ORM,全称Object Relational Mapping,中文叫做对象-关系映射。
(2)通过ORM我们可以通过类的方式来操作数据库,通过把类映射成表,把实例映射为行,把属性映射为字段;ORM在执行对象操作的时候最终还是会把对应的操作转换为SQL语句。
6:创建一个ORM模型并映射模型到数据库中
第一步:创建一个User模型类(在数据库中的表现:类--表名(app的名字_类名(小写)),属性--字段,实例-行)
class User(models.Model): username = models.CharField(max_length=10) telephone = models.CharField(max_length=11) email = models.EmailField() sex = models.BooleanField()
第二步:执行makemigrations [app_name] #后面可以跟APP的名字,生成迁移脚本文件
第三步:执行migrate [app_name] #映射到数据库中
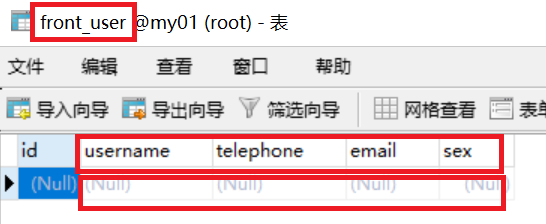
7:模型常用的属性
(1)常用的Field字段
AutoField:int类型,自动增长
BigAutoField:类似于AutoField,范围1-9223372036854775807
BooleanField:tinyint类型,True/False
CharField: varchar类型,使用时必须指定最大长度,即max_length参数必须传递
DateField: 日期类型;两个参数auto_now:每次保存的时候都是用当前的时间,比如记录一个记录修改的日期;auto_now_add:在数据第一次创建的时候用当前的时间,比如记录第一次入库的时间。
DateTimeField:日期时间类型;不仅可以存储日期还可以存储时间。两个参数(auto_now和auto_now_add)
TimeField:时间类型;
EmailField:varchar类型;最大长度254
FileField:用来存储文件的
FloatField:浮点类型
ImageField:存储图片
IntegerField:整型,-2147483648 - 2147483647
BigIntegerField:大整形,
PositiveIntegerField:正整型;0-2147483647
SmallIntegerField:小整型,-32768 - 32767
TextField:大量的文本类型,longtext
UUIDField:存储uuid格式的字符串,是一个32位的全球唯一的字符串,一般做主键
URLField:存储url格式的字符串,max_length默认是200
(2)Field字段常用的参数
null:表示映射为表的时候是否可以为空,默认为False(不能为空);在使用字符串相关的Field时(CharField、TextField)一般保持默认的False,因为即便是Flase,Django也会创建一个空字符串 " "作为默认值传递进去,如果再设置为True的话,就会用null来存储空值,默认值就变为了两个(""和null)
blank:表示验证的时候是否可以为空,默认是False。(和null的区别:null是一个数据库级别的,blank是表单验证级别的)
db_column:表示字段在数据库中的名字
default:默认值,可以是一个值或者函数,不支持lambda表达式,并且不支持列表、字典。集合等可变的数据结构
primary_key:默认值false,是否为主键
unique:是否唯一,一般手机号或者邮箱用
(3)模型中Meta的配置
对于一些模型级别的配置,我们可以在模型中定义一个类,叫做Meta,然后在这个类中添加一些类属性来控制模型。比如在映射到数据库中表的名字使用自己定义的。
from django.db import models class User(models.Model): username = models.CharField(max_length=10) telephone = models.CharField(max_length=11) email = models.EmailField() sex = models.BooleanField(db_column="sex_a") create_time = models.DateTimeField(auto_now_add=True) class Meta: db_table = "User", //表的名字 ordering = ["create_time"] //在查找数据的时候根据添加的时间排序
8:外键
如果一张表中非主键的某个字段指向了另一张表中的主键,那么这个字段就是该表的外键。
外键的作用是:防止一张表过于复杂(比如一个需求是一个名字对应一张照片,如果保存在同一种表中数据可能有些乱,最好是分开两张表,一种保存名字,另一张保存图片,同时两张表又有一种制约,可以通过名字找到这张图片,或者通过图片找到这个名字)。
在mysql中,表有两种引擎,一种是InnoDB,支持外键的使用;另一种是myisam,暂时不支持外键的使用。
Django中的外键使用ForeignKey(to,on_delete,**options),第一个参数是引用的是哪个模型,第二个参数是使用外键引用的模型被删除的时候,这个字段该如何处理。
注意:如果引用的模型在另一个APP中,则第一个参数需要添加app_name.模型名;如果引用的是模型本身自己可以用self或者模型自己的名字
from django.db import models class User(models.Model): //用户模型 username = models.CharField(max_length=10) password = models.CharField(max_length=20) class Article(models.Model): //文章模型 title = models.CharField(max_length=20) content = models.TextField() author = models.ForeignKey("User",on_delete=models.CASCADE) //外键 category = models.ForeignKey("login.Tags",on_delete=models.CASCADE) //另一个app,login中model的Tags模型 class Comment(models.Model): content = models.TextField() origin_comment = models.ForeignKey("self",on_delete=models.CASCADE,null=True) //外键是模型自己 # origin_comment = models.ForeignKey("Comment",on_delete=models.CASCADE,null=True)
外键删除操作:
如果一个模型引用了外键,在对方那个模型被删除掉,该进行什么样的操作;通过on_delete来指定:
CASCADE:级联操作,如果外键对应的那条数据被删除,那么这条数据也被删除。
PROTECT:受保护,即只要这条数据引用了外键的那条数据,那么就不能删除外键的那条数据。
SET_NULL:设置为空,如果外键的那条数据被删除,那么本条数据设置为空,前提是这个字段可以为空。
SET_DEFAULT:设置为默认值,如果外键的那条数据被删除,那么本条数据设置默认值,前提是要指定一个默认值。
SET():如果外键那条数据被删除,则调用set函数的值,作为外键的值
DO_NOTHING:不采取任何行为,看数据库级别的约束。
9:表关系:表之间的关系都是通过外键进行关联的,三种关系,一对一,一对多(多对一),多对多
(1)一对一
应用场景:一个用户和一个用户信息表
实现方式:通过OneToOneField来实现
(2)一对多(多对一)
应用场景:比如作者和文章之间的关系,一个作者可以有多篇文章,但是一篇文章只能有一个作者
实现方式:一对多或者多对一,都是通过ForeignKey来实现的
(3)多对多
应用场景:比如文章和标签之间的关系;一篇文章可以有多个标签,一个标签可以被多篇文章引用
实现方式:通过ManyToManyField来实现
表之间的查询方式:related_name和related_query_name;我们依然使用上面的User模型和Article模型来举例:
(1)如果我们想要通过文章获取该作者:
article = Article.objects.first() //获取这篇文章
print(article.author.username) //直接通过author获取作者
(2)如果想要通过作者获取其下的所有文章方式有两种:
#方式一:Django默认每个主表都有一个默认的属性来获取子表的信息,这个属性就是子表模型的小写加上_set(),默认返回一个querydict对象,可以进一步操作 author = User.objects.first() print(author.article_set.all()) #方式二:在默认中添加related_name,以后主表直接通过这个值来获取子表的信息,得到的也是一个querydict对象。 author = models.ForeignKey("User",on_delete=models.CASCADE,related_name="article") #我们可以直接使用这个值 print(author.article.first().title)
(3)relate_name=“+”,表示禁止使用反向查询
10:模型的操作:在ORM框架中,所有的模型操作其实都是映射到数据库中一条数据的操作,因此模型操作也就是数据库表中数据的操作。
(1)数据的增删改查
一:以上面表User为例:
(1)增加数据:
User.objects.create(username="王三",password="123")
(2)查数据:(all(),get(),filter())
#查找所有的数据:返回的是一个queryset集合,没有满足条件返回空列表 users = User.objects.all() for user in users: print(user.username) print(users) #查找单个的对象,返回一个对象,没有满足条件时报错 user = User.objects.get(username="张帆") print(user.username) #数据过滤查找filter;查询的时候有时需要对数据进行过滤再查询,返回所有满足条件的QuerySet集合 user = User.objects.filter(username="张帆",password="213123") print(user) #数据排序;查找数据的时候都是无序的,如果想对某个数据进行排序使用order_by,反向排序加个减号 users = User.objects.order_by("username")
(3)改数据:
#修改数据:获取这条数据,对属性修改,然后保存 user = User.objects.get(username="张帆") user.username = "李四" user.save()
(4)删除数据
#删除数据;获取数据,然后执行delete()函数 user = User.objects.get(username="李四") user.delete()
二:查询条件:查找的时候一般使用filter,get,exclude三个方法来实现,我们可以对其传递不同的参数,来实现不同的需求。格式(约束条件_查找条件)
第一组:精确和like
exact:使用精确 = 进行查找 ; User.objects.get(id_exact = 2),如果提供一个None值,sql层面被解释为null
iexact: 使用like进行查找
第二组:包含(title_contains = "hello")
contains:大小写敏感
icontains:大小写不敏感
第三组:提供包含在容器中值,容器可以是列表,元组,任意一个可迭代的对象
in:User.objects.get(id_in=[1,2,3])
也可以传递一个queryset对象进去:获取标题中包含张三的文章
username = User.objects.filter(username_contains = "张三")
user = Article.objects.filter(title_in = username)
第四组:(id__gt = 3)
gt:大于
gte:大于等于
lt:小于
lte:小于等于
第五组:判断某个字段是否以某个值为开始(结束) (title_startwith = "hello")
startwith:
istartwith:
endswith:
iendswith:
第六组:
range:判断是否在某个区间;(create_time = range(start,end))
第七组:根据时间查询
date:年月日 (create_time_date=date(2018,3,23))
year:年(create_time_year = 2108)
month:月(同上)
day:天(同上)
wek_day:星期几(1表示星期天,7表示星期六)
time:时分秒(create_time= datetime_time(2,2,2)),2点2分2秒
第八组:是否为空
isnull:(title_isnull = False) 不为空
第九组:正则
regex:大小写敏感:(title_regex=r"hello")
iregex:大小写不敏感:(title_regex=r"hello")
三:关联表查询
比如有两个模型,一个是User,一个是Article;想要获取文章标题中带有“中国”的用户
user = User.objects.filter(article_title_contains = "hello")
(2)聚合函数:聚合函数是同aggregate方法来实现的。
(1)Avg:求平均值
(2)Count:获取指定对象的个数
(3)Max和Min:获取最大值最小值
(4)Sum:求和
假设有这样一个模型:
class BookOrder(models.Model): book_name = models.CharField(max_length=12) price = models.FloatField()
数据表为:
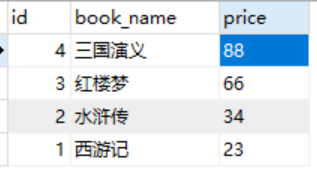
# result = BookOrder.objects.aggregate(Avg("price")) //所有书的平均价格,名字规则为field_avg组成 result = BookOrder.objects.aggregate(book_price = Avg("price")) //给这个价格指定一个名字 print(result) result = BookOrder.objects.aggregate(book_num = Count("id")) //求所有的书 print(result) result = BookOrder.objects.aggregate(book_price_max = Max("price")) //求最大值 print(result) result = BookOrder.objects.aggregate(book_price_min=Min("price")) //求最小值 print(result) result = BookOrder.objects.aggregate(books_price = Sum("price")) //求最和 print(result)
(3)aggregate和annotate的区别
(4)F表达式和Q表达式
F表达式是用来优化ORM模型操作数据库的,并不会立刻去数据库中获取数据,而是在生成SQL语句的时候,动态的获取传给F表达式的值
BookOrder.objects.update(price = F("price")+100) //更新图书的价格
Q表达式:一般查询条件比较多的时候使用,可以使用与或非,&,|,~
books = BookOrder.objects.filter(Q(id=3) | Q(book_name__contains="记"))
11:查询集(QuerySet)
(1)查询集就是通过查询后得到的一个对象集合。
Django中查询操作都是通过 模型名.objects的方式进行;这个objects是一个Manager对象,而这个Manager这个类是一个空壳的类,它本身没有任何的属性和方法;都是通过Python从QuerySet类中动态的添加过来的。
class Manager(BaseManager.from_queryset(QuerySet)): pass class BaseManager: @classmethod def from_queryset(cls, queryset_class, class_name=None): if class_name is None: class_name = '%sFrom%s' % (cls.__name__, queryset_class.__name__) return type(class_name, (cls,), { '_queryset_class': queryset_class, **cls._get_queryset_methods(queryset_class), })
class QuerySet:
"""Represent a lazy database lookup for a set of objects."""
def __init__(self, model=None, query=None, using=None, hints=None):
self.model = model
self._db = using
self._hints = hints or {}
self.query = query or sql.Query(self.model)
self._result_cache = None
self._sticky_filter = False
self._for_write = False
self._prefetch_related_lookups = ()
self._prefetch_done = False
self._known_related_objects = {} # {rel_field: {pk: rel_obj}}
self._iterable_class = ModelIterable
self._fields = None
............(后面省略)
(2)两大特性:
惰性执行:创建查询集不会立刻执行,只到调用数据时才会去数据库中查询,调用数据包括:迭代,使用步长做切片操作,调用len函数,调用list函数,判断
缓存:使用同一个查询集,第一次会发生数据库查询,然后django会把数据缓存起来,以后再使用的时候不会去数据库查询而是直接使用
(3)常用的API:
1.filter:将满足条件的数据提取出来,返回一个queryset对象
2.exclude:排除满足条件的对象,返回一个queryset对象
3.annotate:
4.order_by:排序(倒序加减号),多个order_by链式使用时,会把前面的打乱,以后面的为准
5.values:规定提取那些字段,返回的是一个字典类型。默认会把所有字段都提取出来
6.values_list:同上,不过返回的是一个元组
7.defer:过滤掉一些字段,返回的是一个模型
8.only:只保留这个字段(和上面相反)
9.all:返回queryset对象
10.select_related:
11.prefetch_related:
12.get:只返回一条满足条件的数据,如果是多条或者没有都会报错
13.create:创建一条数据,并保存
14.get_or_create:如果数据库中存在这个数据就返回,不存在就创建;返回一个元组(第一个参数是这个对象,第二个参数是boolean类型)
15.bulk_create:一次创建多个数据;bulk_create([book_name="111",book_name="222"])
16.count:获取数据的个数,比len函数高效
17.first和last:返回queryset中的第一条和最后一条
18.aggregate:使用聚合函数
19.exists:判断是否存在
20.distinct:去掉重复的数据;
21.update:更新
22.delete:删除数据
23.切片:Books.objects.all()[1:3];切片不是把数据都提取出来再做切片,而是在底层直接使用LIMIE和OFFSET
12:ORM模型迁移
(1)makemigrations:将模型生成迁移脚本
app_label:后面跟一个或者多个app,只会针对这几个app生成迁移脚本,如果没有写就是针对所有都生成
--name:给这个迁移脚本生成一个名字
--empty:生成一个空的迁移脚本
(2)migrate:将生成的迁移脚本映射到数据库中
app_label:规定那几个app
app_label migrationname;将某个app下指定名字的migration文件映射到数据库中
--fake:可以将指定的迁移脚本文件名字添加到数据库中,但是并不会把迁移脚本文件转换为sql语句,修改数据库中的表
--fake-initial:将第一次生成的迁移文件版本号记录在数据库中,但并不会执行迁移脚本
(3)showmigrations:查看某个app的迁移文件;如果后面没有app将查看所有的
(4)sqlmigrate:查看某个迁移文件映射到数据库中转换的SQL语句
