Java第08次实验(流与文件)实验报告--网络2112-37号
第1次实验
0. 字节流与二进制文件
- 使用DataOutputStream与FileOutputStream将Student对象写入二进制文件students.data
- 二进制文件与文本文件的区别。使用wxMEdit或Visual Studio Code+ Hex Editor插件分析生成的students.data。
- try...catch...finally注意事项
- 使用try...with...resouces关闭资源
- 使用DataInputStream与FileInputStream从student.data中读取学生信息并组装成Student对象。
首先定义一个Student对象,基本要求:学号,姓名,年龄,成绩。
private int id;
private String name;
private int age;
private double grade;
然后构建所需要的各种方法。
public Student(int id, String name, int age, double grade) {
this.id = id;
this.setName(name);
this.setAge(age);
this.setGrade(grade);
}
一键生成setter与getter。
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
if (name.length()>10){
throw new IllegalArgumentException("name's length should <=10 "+name.length());
}
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
if (age<=0){
hrow new IllegalArgumentException("age should >0 "+age);
}
this.age = age;
}
public double getGrade() {
return grade;
}
public void setGrade(double grade) {
if (grade<0 || grade >100){
throw new IllegalArgumentException("grade should be in [0,100] "+grade);
}
this.grade = grade;
}
重写tostring()方法。
@Override
public String toString() {
return "Student [id=" + id + ", name=" + name + ", age=" + age + ", grade=" + grade + "]";
}
public static void main(String[] args)
{
String fileName="h:\\Students.data"; //输出的文件
try(DataOutputStream dos=new DataOutputStream(new FileOutputStream(fileName)))//写入文件
{
Student[] stu=new Student[3]; //建立Student对象数组
stu[0]=new Student(37,"hengxin",19,85.0);
stu[1]=new Student(35,"chunyu",20,95.0);
stu[2]=new Student(36,"lirong",20,90.0);
for(Student stu1:stu) { //for循环将对象写入文件
dos.writeInt(stu1.getId());
dos.writeUTF(stu1.getName());
dos.writeInt(stu1.getAge());
dos.writeDouble(stu1.getGrade());
}
} catch (FileNotFoundException e) { //没找到文件的错误
// TODO Auto-generated catch block
e.printStackTrace();
//System.out.println("no");测试代码
} catch (IOException e) { //IOException 是在使用流、文件和目录访问信息时引发的异常的基类。
// TODO Auto-generated catch block
e.printStackTrace();
// System.out.println("no2");测试代码
}
try(DataInputStream dis=new DataInputStream(new FileInputStream(fileName)))//读取文件
{
while(dis.available()!=0) { //available()读入剩下的所有字节
int id=dis.readInt();
String name=dis.readUTF();
int age=dis.readInt();
double grade=dis.readDouble();
Student stu=new Student(id,name,age,grade);
System.out.println(stu);
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
// System.out.println("no3");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
// System.out.println("no4");
}
}


1. 字符流与文本文件:使用 PrintWriter(写),BufferedReader(读)
任务:
- 将Student.txt拷贝到Eclipse项目根目录(右键点击项目-选择paste)。请不要拷贝到src目录。
- 使用BufferedReader从编码为UTF-8的文本文件Student.txt中读出学生信息,并组装成对象然后输出。
- 中文乱码问题(FileReader使用系统默认编码方式读取文件,可能会产生乱码,可使用InputStreamReader解决)。也可将Student.txt编码格式改为GBK,复现乱码。
- String的split方法使用\s+可以使用多个空格作为分隔符。
- 进阶:修改Students.txt文件,在正确的数据行中间增加一些错误行(如,每行只有3个数据,或者应该是数字的地方放入其他字符),修改自己的程序,让其可以处理出错的行(报错但可以继续运行)。
- 编写public static List
readStudents(String fileName)从fileName指定的文本文件中读取所有学生,并将其放入到一个List中后返回。 - 使用PrintWriter的println方法将Student对象写入文本文件。基础代码见后。注意:缓冲区问题。
- 可选:使用ObjectInputStream/ObjectOutputStream读写学生对象。
public class Mian {
public static void main(String[] args) throws IOException
{
String FileName="H:\\Students.txt"; //文件位置及名称
BufferedReader br = null; //缓冲区读取内容,避免中文乱码
try {
br = new BufferedReader(new InputStreamReader(new FileInputStream(FileName),"UTF-8"));
//字符转换流InputStreamReader防止中文乱码
String line = null;
while((line=br.readLine())!=null)
System.out.println(line); //打印每一行
} finally{
if (br!=null){
br.close(); //关闭文件
}
}
}
}
使用GBK输出:
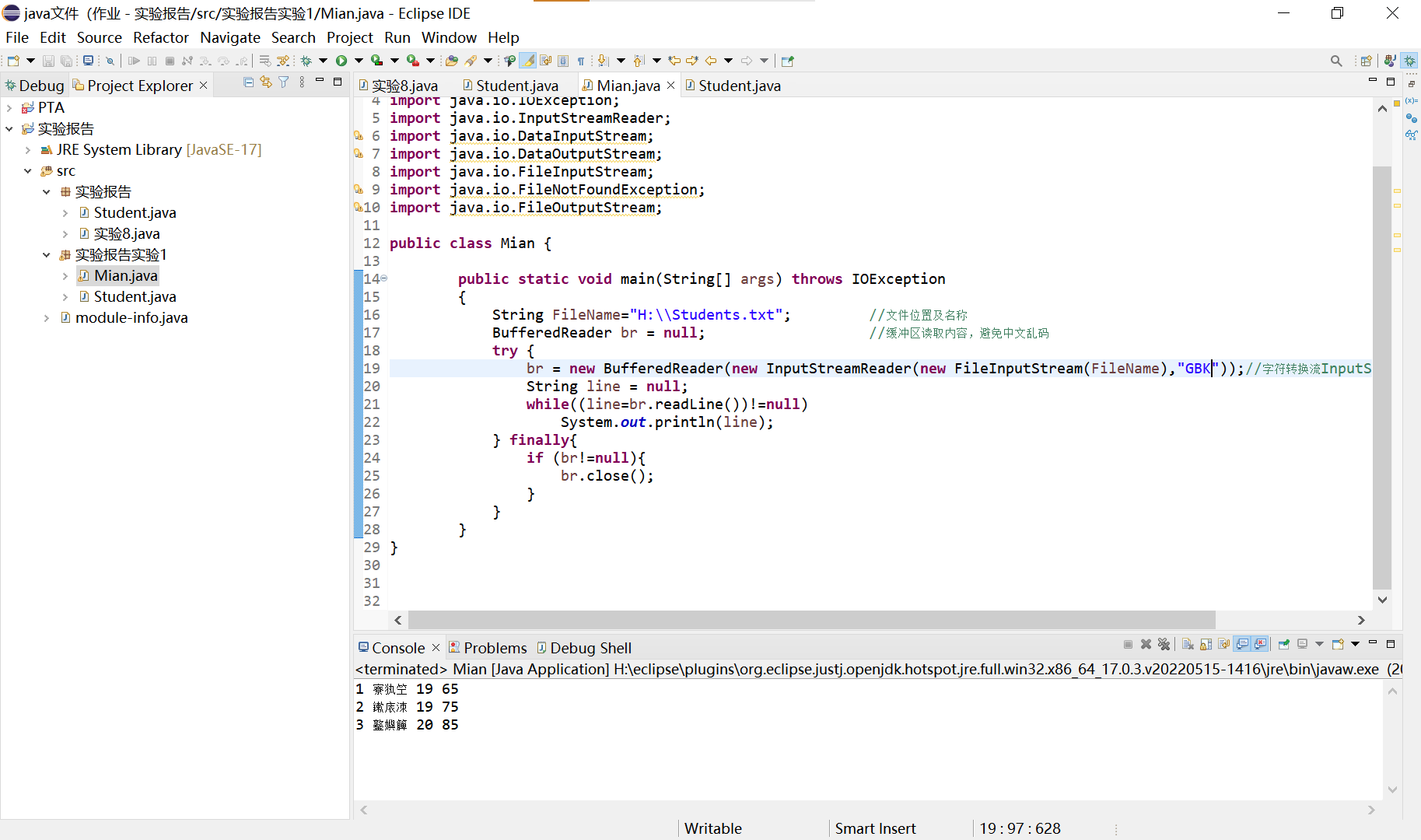
使用UTF-8输出:
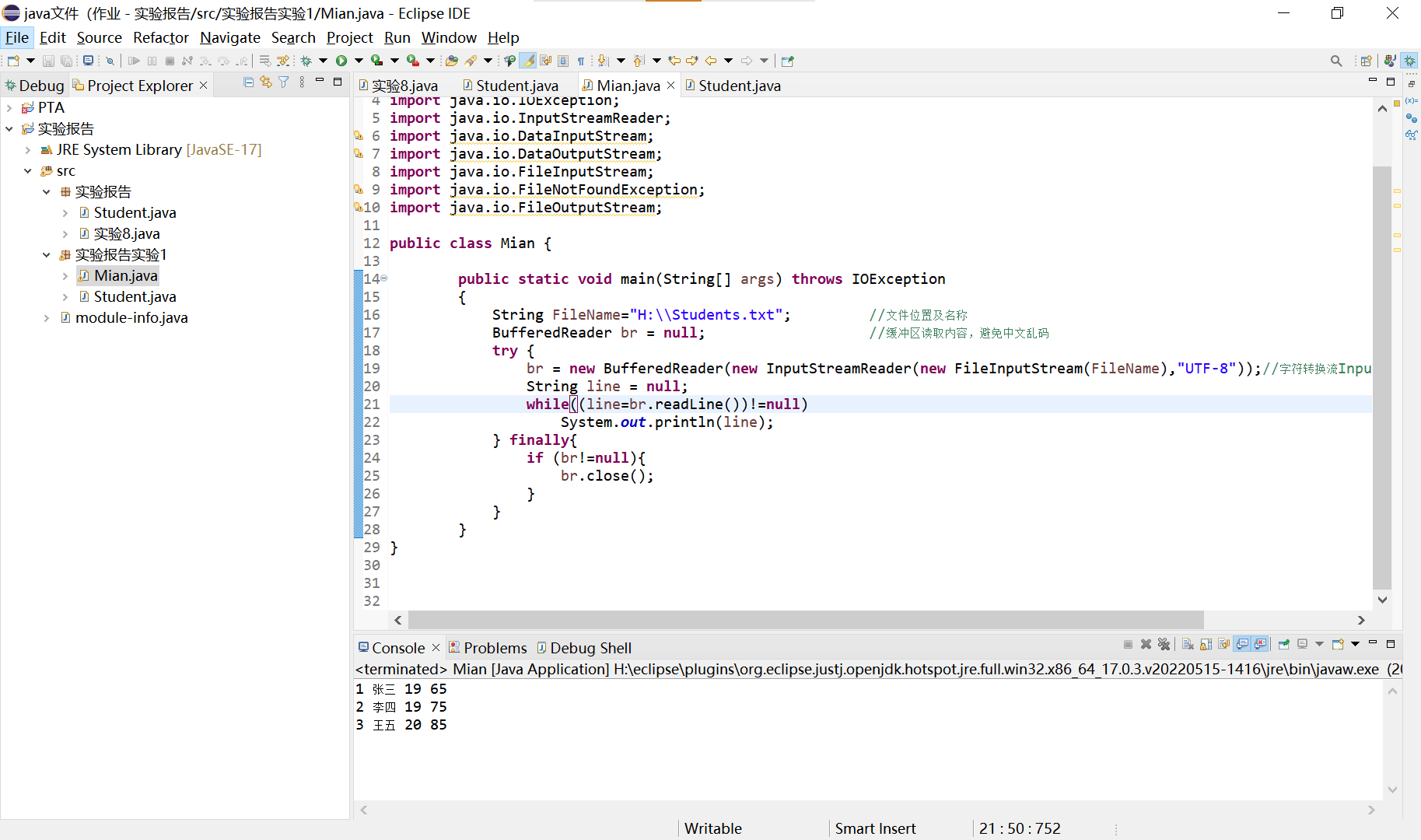
public class Mian {
public static void main(String[] args) throws IOException
{
String FileName="H:\\Students.txt"; //文件位置及名称
BufferedReader br = null; //缓冲区读取内容,避免中文乱码
PrintWriter pw=new PrintWriter(new OutputStreamWriter(new FileOutputStream(FileName,true),"UTF-8"));
//构造方法参数为String类型的对象,值应为文件全路径。若文件不存在,则会先创建文件。
pw.print("\n4 陈六 21 93"); ///n用于换行
pw.close(); //一定要关闭
}
public static void ListreadStudents(String fileName) throws IOException{
ArrayList<Student> StudentList=new ArrayList<Student>();//建立Student链表
BufferedReader br = null;
try {
br = new BufferedReader(new InputStreamReader(new FileInputStream(fileName),"UTF-8"));//读文件
while(br!=null) {
String line=br.readLine();
String[] stu=line.split("\\s+"); //正则表达式,用于判断换行等字符,如果遇到更多相同换行则会合并为一个
int id=Integer.parseInt(stu[0]);
String name=stu[1];
int age=Integer.parseInt(stu[2]);
double grade=Double.parseDouble(stu[3]);
Student Stu=new Student(id,name,age,grade);//建立对象
StudentList.add(Stu); //添加
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally{
if (br!=null){
br.close(); //关闭
}
}
}
}
运行截图:
无输出所以没有截图。
储存截图:
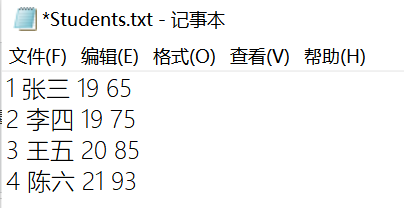
关于用ObjectInputStream/ObjectOutputStream读写学生对象,不是很理解这两个函数的使用方法,故参考网上相关代码。
public class Mian {
public static void main(String[] args) throws IOException
{
String FileName="H:\\Students.txt"; //文件位置及名称
try(
FileOutputStream fos=new FileOutputStream(FileName);
ObjectOutputStream oos=new ObjectOutputStream(fos))
{
Student ts=new Student(5,"asd",14,60);
oos.writeObject(ts);
}
catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try(
FileInputStream fis=new FileInputStream(FileName);
ObjectInputStream ois=new ObjectInputStream(fis))
{
Student newStudent =(Student)ois.readObject();
System.out.println(newStudent);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
运行截图:

无法成功运行,该错误的原因是没有对象序列化,出现这个问题的时候应该是想要将 该实体类对象保存到某个地方,那么此时必须需要序列化;一个类只有实现了Serializable接口,它的对象才是可序列化的。
解决办法:
在实例化类前面加implements Serializable即可。
2. 缓冲流(结合使用JUint进行测试)
- 使用PrintWriter往文件里写入1千万行随机整数,范围在[0,10],随机数种子设置为100.
- 从文件将每行读取出来转换成整数后相加。然后依次输出“个数 和 平均值(保留5位小数)”。
- 对比使用BufferedReader与使用Scanner从该文件中读取数据(只读取,不输出),使用哪种方法快?
测试用例基础代码:
private static int NUM = 10000000;
private static long SEED = 100;
private static String FILENAME = "data.txt";
@BeforeAll
void write2File() throws FileNotFoundException {
Random rnd = new Random(SEED);
PrintWriter pw = new PrintWriter(FILENAME);
for (int i = 0; i < NUM; i++) {
pw.println(rnd.nextInt(11));
}
pw.close();
}
注意:
- 保留5位小数,可使用System.out.format进行格式化输出。
- 要使用Scanner的hasNextXXX方法来判断是否到文件尾,否则会抛异常。
- Scanner的hasNextXXX方法应与相对应的nextXXX方法配合使用,否则容易出错。
- 请删除fail("Not yet implemented");并且在需要测试的方法上使用@Test进行标注。
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
String FILENAME = "test.txt";
double sum=0,aver;
PrintWriter pw=null;
try {
pw = new PrintWriter(FILENAME); //写入文件
for(int i = 0;i<10000000;i++){ //写入1千万行
int r=new Random().nextInt(10); //在10以内随机生成数
sum+=r;
pw.println(r);
//System.out.println(r);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}finally{
pw.close(); //关闭文件
}
aver=sum/10000000; //生成平均数
System.out.format("平均数为:%.5f\n", aver); //保留五位小数
test(); //调用函数测定时间
Bufftest();
}
public static void test() {
String FILENAME = "test.txt";
long begin = System.currentTimeMillis(); //计算任务耗费的毫秒,System.currentTimeMillis()用于获取时间
Scanner scanner=null;
try {
scanner = new Scanner(new File(FILENAME));
while(scanner.hasNextLine()){ //只是读出每一行,不做任何处理
scanner.nextLine();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}finally{
scanner.close();
}
long end = System.currentTimeMillis();
System.out.print("Scanner方法所用时间为:");
System.out.println("last "+(end-begin)); //用最后的时间减去开始的时间,得到这个程序运行的时间
}
// @Test
public static void Bufftest() { //同Scanner法
String FILENAME = "test.txt";
long begin = System.currentTimeMillis();
BufferedReader br = null;
try {
br = new BufferedReader(new FileReader(new File(FILENAME)));
while(br.readLine()!=null){}; //只是读出,不进行任何处理
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.print("BufferedReader方法所用时间为:");
System.out.println("last "+(end-begin));
}
}
存储位置:
运行截图:
从运行结果的时间上可以明显看出,Scanner方法比BufferedReader方法慢得多,所以BufferedReader方法更好。
思考题:
为什么以下代码生成的文件大小是0,而只有当count=16384(两倍的默认缓冲区大小)才可以真正写入到文件?
String fileName = "d:/Test.data";
int count = 16383;
PrintWriter pw = null;
try {
pw = new PrintWriter(fileName);
for (int i = 0; i < count; i++) {
pw.print(1);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}finally{
//pw.close();
}
答:没有调用flush方法和close方法,这样当向文件中写入数据时,数据流始终先保存到一段缓冲区中,当写入的数据流大于两倍缓冲区而没有进行刷新流操作时,JAVA会自动刷新流,将流写入到文件中。
第2次实验
3. 字节流之对象流
结合使用ObjectOutputStream、ObjectInputStream与FileInputStream、FileOuputStream实现对Student对象的读写。
编写如下两个方法:
- public static void writeStudent(List stuList)
- public static List readStudents(String fileName)
public static void writeStudent(List<Student> stuList)
{
String fileName="H:\\Student.data";
try ( FileOutputStream fis=new FileOutputStream(fileName);
ObjectOutputStream ois=new ObjectOutputStream(fis))
{
ois.writeObject(stuList);
}
catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
}
public static List<Student> readStudents(String fileName)
{
List<Student> stuList=new ArrayList<>();
try ( FileInputStream fis=new FileInputStream(fileName);
ObjectInputStream ois=new ObjectInputStream(fis))
{
stuList=(List<Student>)ois.readObject();
}
catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return stuList;
}
运行结果:

生成结果为一段乱码,但是这段代码我不是很理解,故借鉴参考代码,而且不理解为什么结果是这样的,就算改变编码格式,也还是乱码,我不理解。
5. 文件操作
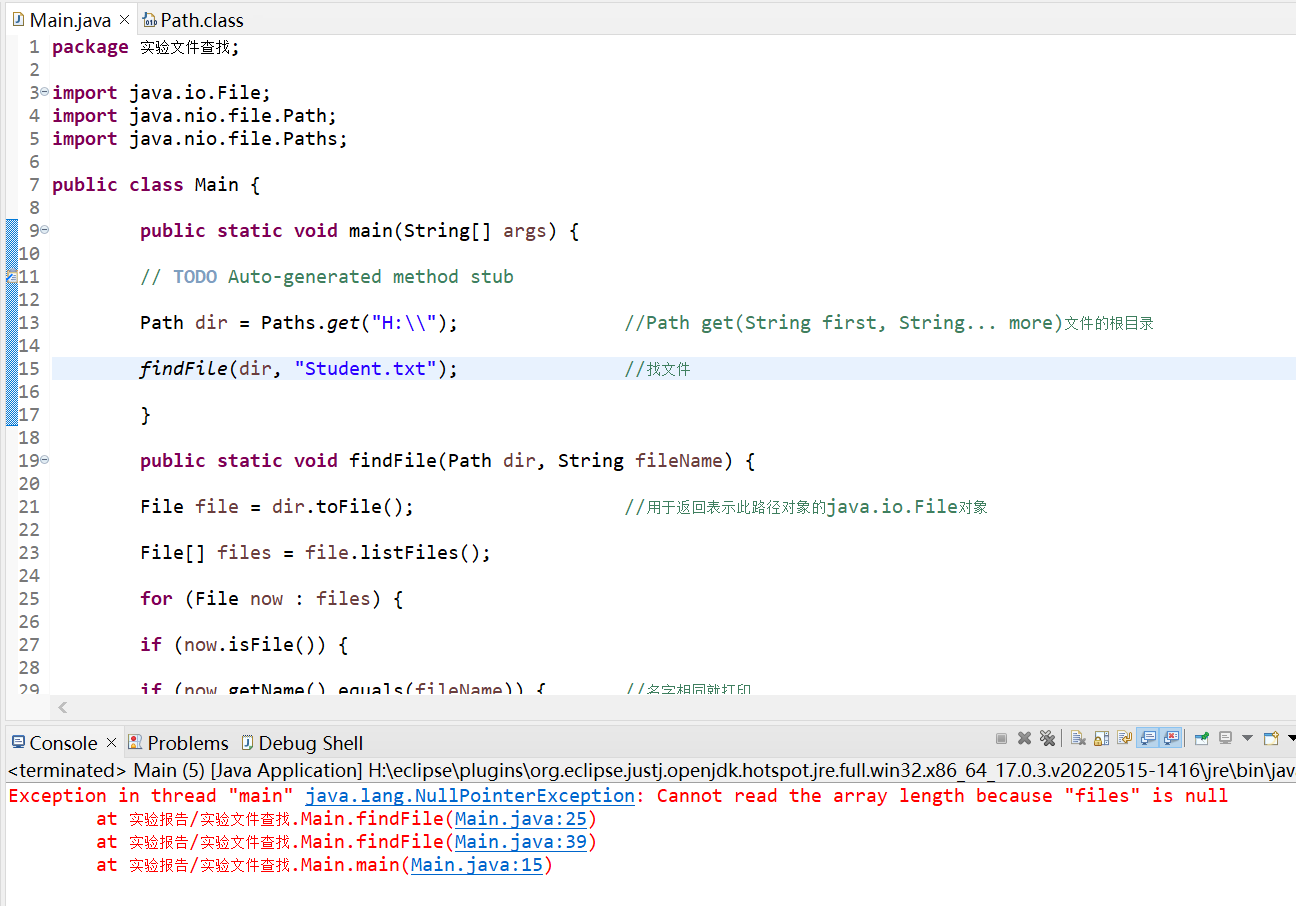
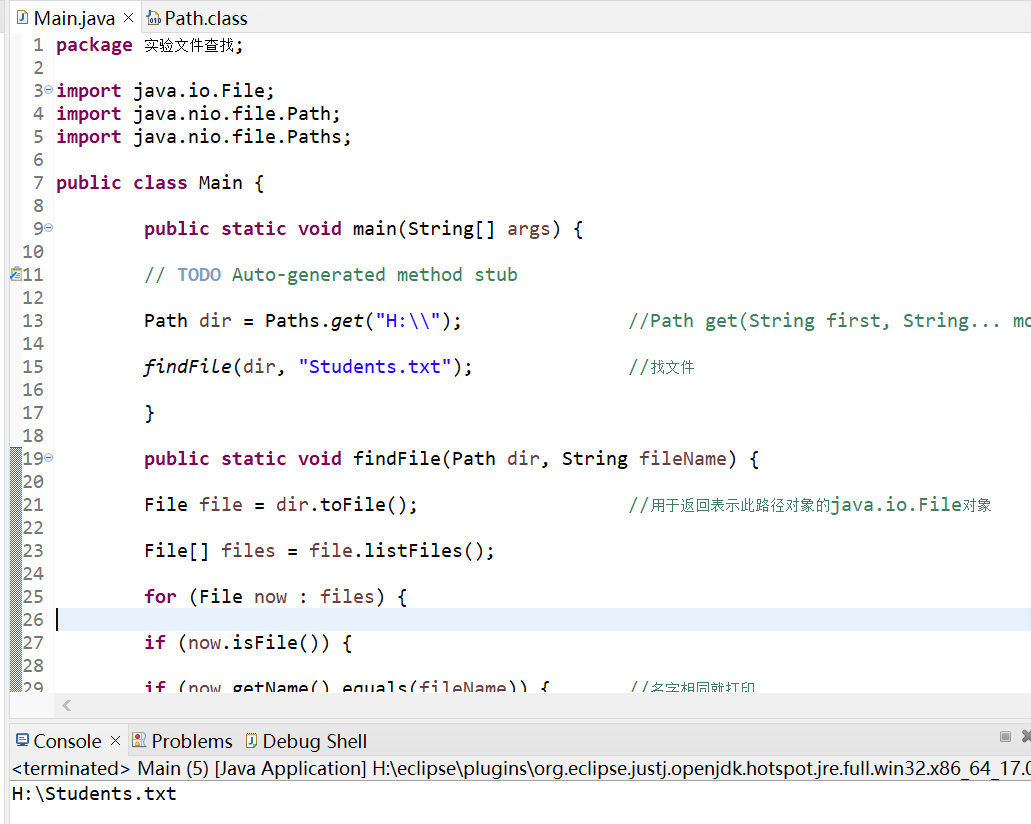
编写一个程序,可以根据指定目录和文件名,搜索该目录及子目录下的所有文件,如果没有找到指定文件名,则显示无匹配,否则将所有找到的文件名与文件夹名显示出来。
- 编写public static void findFile(Path dir,String fileName)方法.
以dir指定的路径为根目录,在其目录与子目录下查找所有和filename
相同的文件名,一旦找到就马上输出到控制台。
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
Path dir = Paths.get("H:\\"); //Path get(String first, String... more)文件的根目录
findFile(dir, "Students.txt"); //找文件
}
public static void findFile(Path dir, String fileName) {
File file = dir.toFile(); //用于返回表示此路径对象的java.io.File对象
File[] files = file.listFiles();
for (File now : files) {
if (now.isFile()) {
if (now.getName().equals(fileName)) { //名字相同就打印
System.out.println(now.getAbsolutePath());
return;
}
} else if (now.isDirectory()) { //isDirectory()是检查一个对象是否是文件夹
findFile(now.toPath(), fileName); //是则去子目录查找
}
}
}
}
运行截图:
-
没有该文件:
![]()
-
存在该文件:
![]()
实验小结
- 不是很理解ObjectOutputStream与ObjectInputStream
- ObjectOutputStream的使用
- ObjectOutputStream是一个高级流, 将 Java 对象的基本数据类型和图形写入 OutputStream。可以使用 ObjectInputStream 读取(重构)对象。通过在流中使用文件可以实现对象的持久存储。如果流是网络套接字流,则可以在另一台主机上或另一个进程中重构对象。
- ObjectInputStream的使用
- ObjectInputStream也是一个高级流,对以前使用 ObjectOutputStream 写入的基本数据和对象进行反序列化。
- ObjectOutputStream 和 ObjectInputStream 分别与 FileOutputStream 和 FileInputStream 一起使用时,可以为应用程序提供对对象图形的持久存储。ObjectOutputStream用于序列化对象,ObjectInputStream 用于恢复那些以前序列化的对象(反序列化)。其他用途包括使用套接字流在主机之间传递对象,或者用于编组和解组远程通信系统中的实参和形参。
-
在第2次的第3个实验中,我还无法理解代码以及不知道为什么一直都是乱码,这个乱码就是正确的格式吗?如何才能不是乱码呢?(未解决)
![]()
-
关于用ObjectInputStream/ObjectOutputStream读写学生对象,无法进行序列化导致运行失败(未解决)
![]()


最后总结:
通过这次实验报告,我深切的感受到了自己的编程能力的不足,而且对于各种方面知识的理解的匮乏,在做报告中我需要查询各种资料,以及jdk文档,找到各种函数的用处,这是对我能力的一次大大的提高,之后我也会对别的实验做出一些练习,提升自己的思维以及编程能力,希望下次实验报告能做的更好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号