
Python实现wc.exe
项目相关要求
- 基本功能
-c file.c 返回文件file.c的字符数 (实现)
-w file.c 返回文件file.c的词的数目(实现)
-l file.c 返回文件file.c的行数(实现) - 扩展功能
-s 递归处理目录下符合条件的文件(实现)
-a 返回更复杂的数据(代码行 / 空行 / 注释行)(实现)
文件名支持通配符(*, ?)(实现) - 高级功能
-x 程序会显示图形界面,用户可以通过界面选取单个文件,程序就会显示文件的字符数、行数等全部统计信息。(未实现)
解题思路
刚看到这个题目的时候觉得这个项目的主要内容没有什么难度,但是对于扩展功能中的代码行、空行、注释行的含义理解不是很懂,仔细看了几次文档和反复用IDE进行验证才搞懂。考虑到项目主要是对文件的IO和对String的解析,所以选择了开发效率较高的python。但由于以前从来没有开发过使用命令行参数启动的程序,所以查阅了许多网站后最终选择了argparse模块解析命令行参数。
设计实现过程和代码说明
设计思路:
以main()为中心,通过command_parse()获取操作与参数,根据是否查询子目录调用get_file_recursive()和get_file()获取需要遍历的文件list,最后根据相应的操作对相应的文件使用相应的get_?()方法。
在main()中调用command_parse()解析命令行参数并返回,使用argparse模块
def command_parse():
parser = argparse.ArgumentParser()
parser.add_argument('-c', action='store_true', default=False, help='计算文件的字符数')
parser.add_argument('-w', action='store_true', default=False, help='计算文件词的数目')
parser.add_argument('-l', action='store_true', default=False, help='计算文件的行数')
parser.add_argument('-s', action='store_true', default=False, help='递归处理目录下符合条件的文件')
parser.add_argument('-a', action='store_true', default=False, help='返回更复杂的数据(代码行 / 空行 / 注释行)')
parser.add_argument(action="store", dest="file")
args = parser.parse_args()
file_path = args.file
# 通过往字符串中加入各操作的字母传递信息
param = ''
if args.c:
param = param + 'c'
if args.w:
param = param + 'w'
if args.l:
param = param + 'l'
if args.s:
param = param + 's'
if args.a:
param = param + 'a'
# 如果输入的是相对路径,自动补充当前路径
if "\\" not in file_path:
file_path = os.path.abspath(os.path.join(os.getcwd(), "..")) + "\\" + file_path
return param, file_path
根据有无-s参数决定是否递归子目录和文件(调用get_file_recursive()和get_file()),并使用正则表达式处理通配符(*, ?)的问题
# 如果有通配符,识别符合的目录,返回符合的文件路径
if "*" in file_path or "?" in file_path:
pattern = r"^" + file_path.split("\\")[-1].replace("*", "[0-9a-zA-Z]*").replace("?", "[0-9a-zA-Z]*") + "$"
# 获取根路径
root = os.path.abspath(os.path.join(file_path, ".."))
file_list = get_file_recursive(root, pattern)
# 没有通配符,先检测路径是否正确,然后递归
else:
if not os.path.isdir(file_path):
print("输入的路径不是目录!")
print("ERROR: " + file_path)
exit()
# 无通配符,匹配任意字符
file_list = get_file_recursive(file_path, "[\s\S]*")
查找需要查询的filelist
def get_file_recursive(root, pattern):
file_list = []
dir_list = os.listdir(root)
for i in range(len(dir_list)):
path = os.path.join(root, dir_list[i])
if os.path.isdir(path):
file_list.extend(get_file_recursive(path, pattern))
elif os.path.isfile(path) and re.match(pattern, dir_list[i]):
file_list.append(path)
return file_list
基本功能:
def get_chars(file):
with open(file, 'r') as f:
data = f.read()
print("文件(" + file + ")的字符数: " + str(len(data)))
def get_words(file):
with open(file, 'r') as f:
data = f.read()
# 将所有不是英文的字符replace成空格,使用split查询list长度即可
data = re.sub('[^a-zA-Z]', '', data)
print("文件(" + file + ")的词的数目: " + str(len(data.split())))
def get_lines(file):
with open(file, 'r') as f:
data = f.read()
print("文件(" + file + ")的行数: " + str(len(data.split("\n"))))
扩展功能的-a:
def get_appends(file):
with open(file, 'r') as f:
data = f.read()
empty = 0
code = 0
annotation = 0
# 标识多行注释
is_annotation = False
for line in data.split('\n'):
if is_annotation:
annotation = annotation + 1
if '*/' in line:
is_annotation = False
continue
# 去除空格等无用字符
visual_line = line.replace('\t', '').replace(' ', '')
if len(visual_line) < 2:
empty = empty + 1
elif '/*' in visual_line:
annotation = annotation + 1
is_annotation = True
elif '//' in visual_line:
annotation = annotation + 1
else:
code = code + 1
print("文件(" + file + ")的空行数: " + str(empty))
print("文件(" + file + ")的代码行数: " + str(code))
print("文件(" + file + ")的注释行数: " + str(annotation))
测试运行
空文件测试:
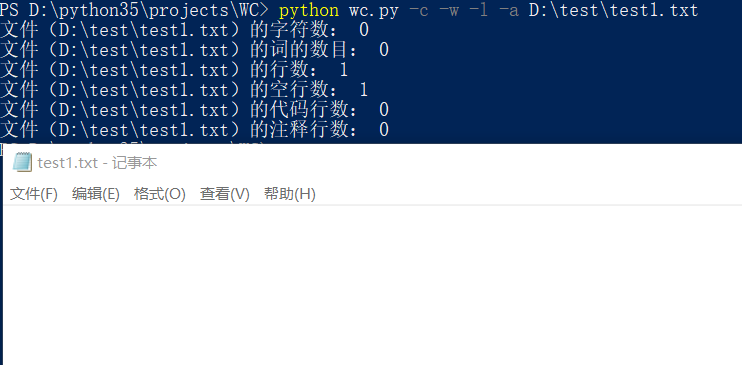
只有一个字符的文件:
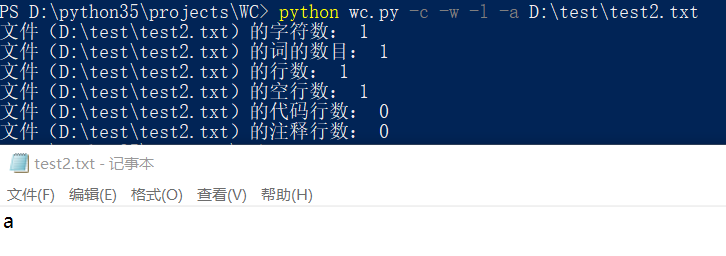
只有一个词的文件:
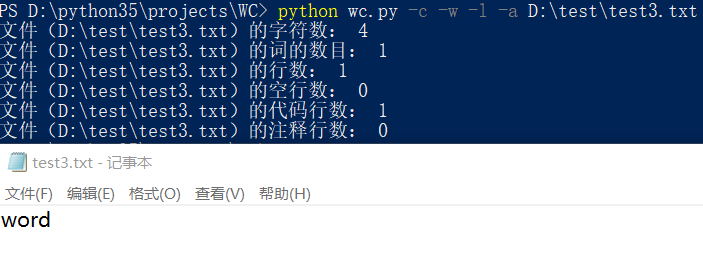
只有一行的文件:
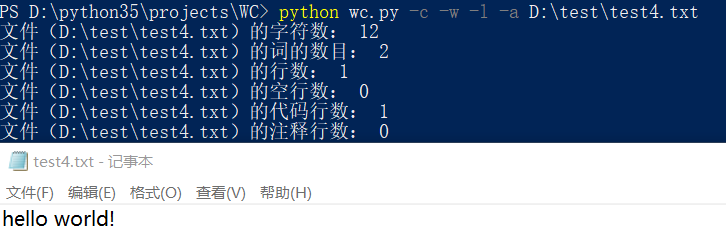
一个典型的源文件:
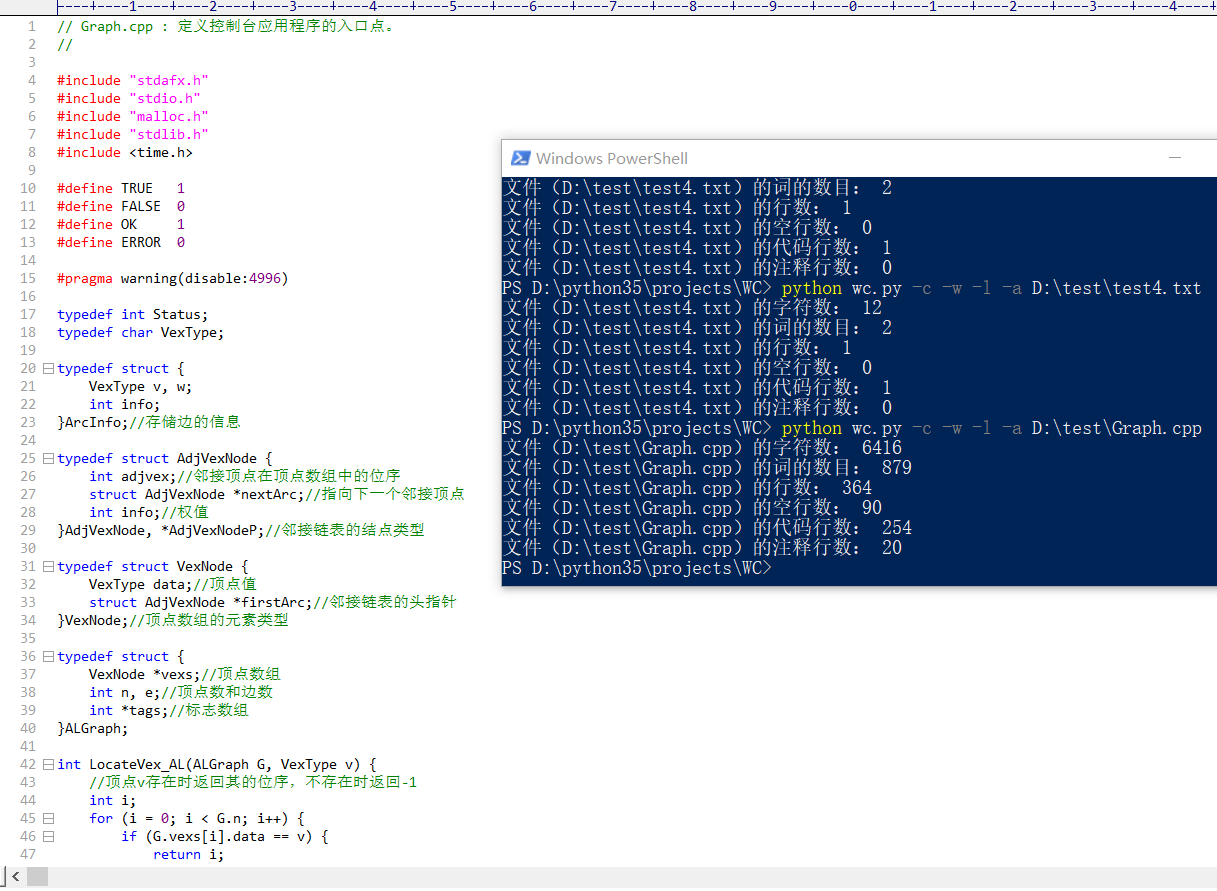
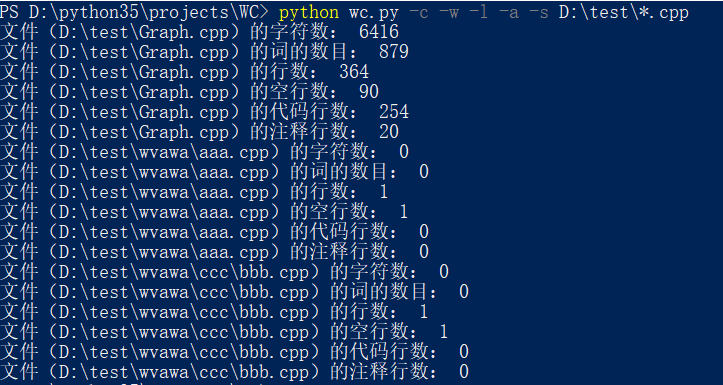
-a 命令和通配符测试:
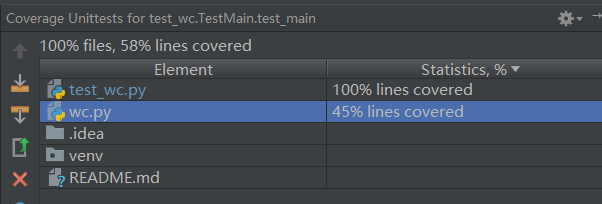
代码覆盖率:
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 410 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 60 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 15 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 10 |
| · Design | · 具体设计 | 120 | 150 |
| · Coding | · 具体编码 | 120 | 300 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 65 | 85 |
| · Test Report | · 测试报告 | 20 | 40 |
| · Size Measurement | · 计算工作量 | 15 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 505 | 815 |
项目小结
从PSP表可以看出我在拿到这个题目之后低估了题目的难度,没有在计划和需求分析上花太多的时候,文档也没有太仔细看,所以开发前的设计文档不能很好的完成需求,导致后来基本处于一种边写代码边改结构的地步,开发效率大大降低,也因为经常改动代码所以bug很多。当然,也和自己开发时不是特别专注有关(边做其他事情边开发)
这次的项目让我了解到自己对于python并不是特别的熟练,对正则表达式的不熟悉也让我吃了很多亏。总体来说,这次经历受益匪浅,让我了解到了自己的不足,也让我知道做项目不能太急,要按流程合理地分配时间才能真正地提高开发效率和代码质量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号