
nginx 代理node高并发下报错 recv() failed(104 Connection reset by peer) while reading response header from upstream
原文链接: https://www.cnblogs.com/yalong/p/16147590.html
项目背景:
我们前端项目是基于node 和 react开发的,node对接口进行转发,以及启动server,并通过pm2 守护 node server进程
到了线上,请求先通过nginx 反向代理到node, 然后node 再把接口转发到 java后端的接口
最近线上项目的接口频繁报错 错误码 502 500,查看监控,如下图所示:
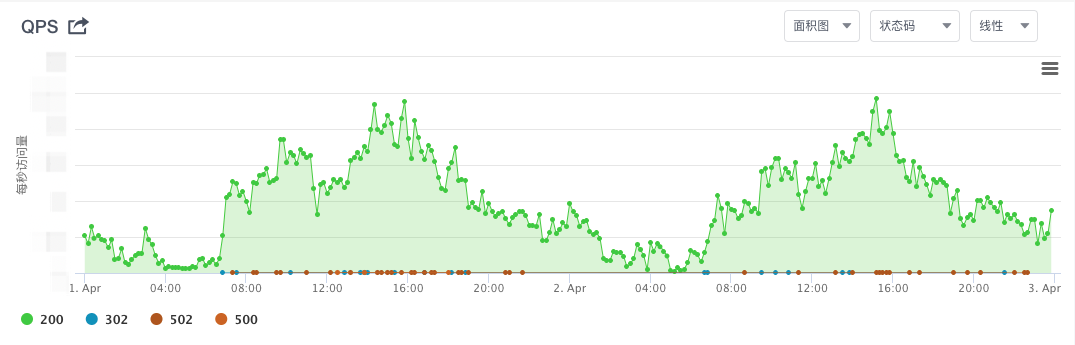
确实不少500 和 502 的错误,而且还是集中在qps高的地方,也就是说在高并发情况下,才出现这种问题
问题排查
首先看下自己的代码有有没有问题,于是查看pm2 的日志,发现没问题,查看线上机器的内存使用率, cpu使用率,也都不高
于是让java后端同学查看java端是否正常,发现也没问题
最终寻求运维同学帮助,然后运维同学查看nginx 日志,确实有问题,内容如下:
recv() failed(104 Connection reset by peer) while reading response header from upstream
那么出现问题的点就找到了
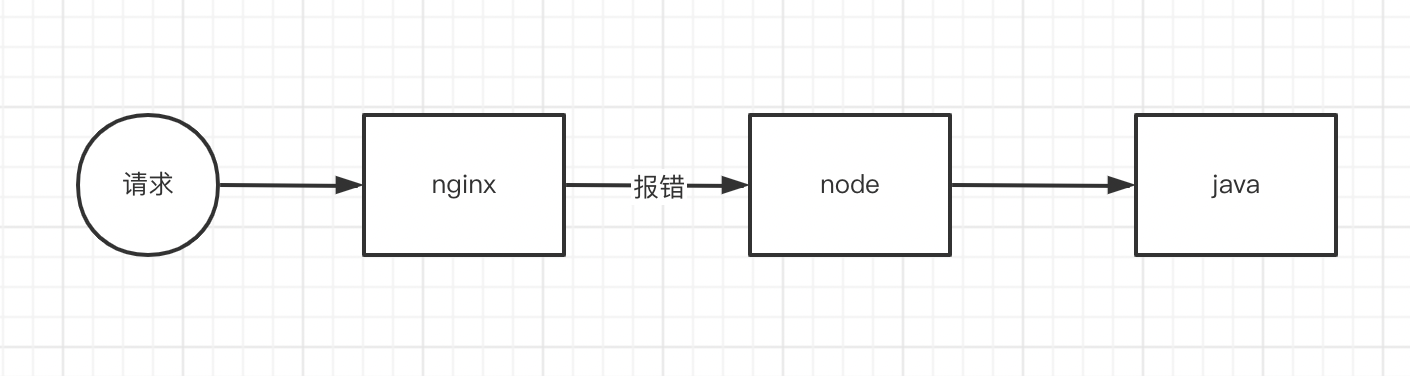
就是nginx 往node请求的时候出了问题
问题分析
网上查了下,这个报错的原因简单来说,nodejs服务已经断开了连接,但是未通知到Nginx,Nginx还在该连接上收发数据,最终导致了该报错
这里要引出长连接的概念,就是 Connection: keep-alive
keep-alive的更多资料大家可以自行百度,或者看这个:https://www.jianshu.com/p/142b35998947
早期的时候一个http请求就要创建一个TCP连接,这个请求用完,TCP连接就关闭,http1.1以后新增了 keep-alive, 可以在一个TCP连接中持续发多个http请求而不中断连接,从而减少了TCP连接的创建次数
但是开启了keep-alive 的连接不是说就一直不会断开了,tpc长连接断开的原因有好多种
导致tcp连接断开的原因:
- 连接在规定时间内没有使用,就会自动断开
- 每个tcp连接有最大请求限制,比如最大是1000, 那么该tcp连接在服务了1000个http请求后就断开了
- 服务器的tcp并发连接数超过了服务器承载量,服务器会将其中一些tcp连接关闭
解决方案
先看下nginx 的长连接配置
nginx关于长链接的配置字段如下:
keepalive_timeout: 设置客户端的长连接超时时间,如果超过这个时间客户端没有发起请求,则Nginx服务器会主动关闭长连接,Nginx默认的keepalive_timeout 75s;。有些浏览器最多只保持 60 秒,所以我们一般设置为 60s。如果设置为 0,则关闭长连接。keepalive_requests:设置与客户端的建立的一个长连接可以处理的最大请求次数,如果超过这个值,则Nginx会主动关闭该长连接,默认值为100
一般情况下,keepalive_requests 100基本上可以满足需求,但是在 QPS 较高的情况下,不停的有长连接请求数达到最大请求次数而被关闭,这也就意味着Nginx需要不停的创建新的长连接来处理请求,这样会可能出现大量的 TIME WAIT
3.keepalive: 设置到 upstream 服务器的空闲 keepalive 连接的最大数量,当空闲的 keepalive 的连接数量超过这个值时,最近使用最少的连接将被关闭,如果这个值设置得太小的话,某个时间段请求数较多,而且请求处理时间不稳定的情况,可能就会出现不停的关闭和创建长连接数。我们一般设置 1024 即可。特殊场景下,可以通过接口的平均响应时间和QPS估算一下。
上面几个参数确定没问题后,然后在node端查看关于keepAlive的配置, 看node文档, 可以看到node中的 server.keepAliveTimeout默认是5000毫秒,就是5秒, 这样如果连接超多5秒没有使用,那么node端就会把连接关闭,但是nginx端的链接还没关闭,还继续在该长连接上收发数据,就出现上面的报错了
所以我们需要增大node端 keepAliveTimeOut 的值
node端keepAlive 配置
我们的项目使用的thinkjs框架,不过无论是什么node框架,其核心都是基于http模块创建一个server,然后在此基础上进行了封装,修改keepAlive核心代码如下所示:
const http = require('http');
const server = http.createServer(this.callback());
server.keepAliveTimeout = 61 * 1000;
server.headersTimeout = 62 * 1000;
放在thinkjs项目里,就是在src/bootstrap 目录下,common.js 文件内,添加如下代码:
think.app.on('appReady', () => {
if (think.app.server) {
think.app.server.keepAliveTimeout = 61 * 1000
think.app.server.headersTimeout = 62 * 1000
}
console.log(think.app.server) // 这行代码只是为了看下server长啥样,实际用的时候注释掉
})
也就是说在thinkjs里找到server实例,然后进行设置
启动thinkjs 可以看到上面的console信息,下图所示:
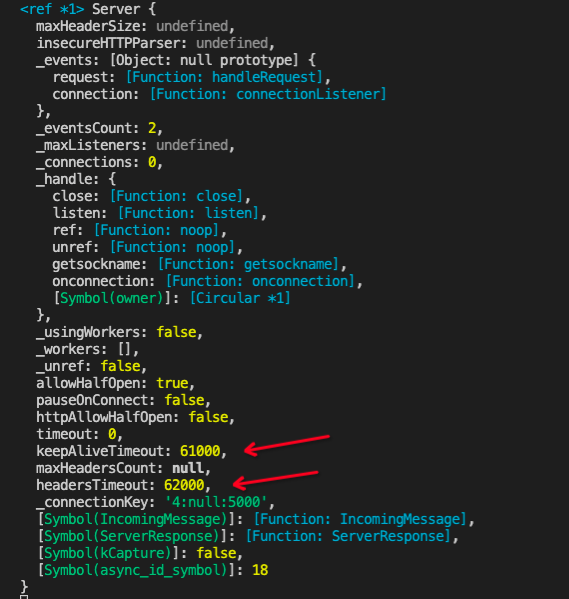
代码文本如下:
Server {
maxHeaderSize: undefined,
insecureHTTPParser: undefined,
_events: [Object: null prototype] {
request: [Function: handleRequest],
connection: [Function: connectionListener]
},
_eventsCount: 2,
_maxListeners: undefined,
_connections: 0,
_handle: {
close: [Function: close],
listen: [Function: listen],
ref: [Function: noop],
unref: [Function: noop],
getsockname: [Function: getsockname],
onconnection: [Function: onconnection],
[Symbol(owner)]: [Circular *1]
},
_usingWorkers: false,
_workers: [],
_unref: false,
allowHalfOpen: true,
pauseOnConnect: false,
httpAllowHalfOpen: false,
timeout: 0,
keepAliveTimeout: 61000,
maxHeadersCount: null,
headersTimeout: 62000,
_connectionKey: '4:null:5000',
[Symbol(IncomingMessage)]: [Function: IncomingMessage],
[Symbol(ServerResponse)]: [Function: ServerResponse],
[Symbol(kCapture)]: false,
[Symbol(async_id_symbol)]: 18
}
上线之后问题解决了
总结分析
其实开始的时候,考虑是因为qps高了,服务顶不住压力,导致了报错,当时的机器是1核CPU, 4G内存,线上就一个node实例
所以就给机器进行升级,1CPU 升级为3CPU, 1个 node实例,改为3个实例,然后重新部署上线,发现问题并没有解决,然后找才找运维查看nginx日志,得出结论是keepAlive的问题
最终修改node的keepAlive,确实问题就解决了
中间找java后端同学,运维同学,整个链路都找了一遍,不过问题总算解决,还是很开心的
参考:
https://www.cnblogs.com/satty/p/8491839.html
https://bbs.huaweicloud.com/forum/thread-75184-1-1.html
https://www.its404.com/article/u014607184/107175596
https://www.jianshu.com/p/142b35998947

 浙公网安备 33010602011771号
浙公网安备 33010602011771号