

http缓存中etag的生成原理
文章原文:https://www.cnblogs.com/yalong/p/15207547.html
说到http缓存中的etag应该都知道, 但是etag具体是怎么生成的,不太清楚,所以特意研究了下
源码是看的 koa-etag 这个npm包
先上总结, koa2中etag生成原理:
- 对于静态文件,比如html, css,js, png等这些,
etag生成的方式就是文件的size加mtime - 对于字符串 或者
Buffer类型的,etag生成的方式就是 字符串、Buffer的长度 加上 对应的hash值
koa-etag使用方式
const conditional = require('koa-conditional-get');
const etag = require('koa-etag');
const Koa = require('koa');
const app = new Koa();
// etag works together with conditional-get
app.use(conditional());
app.use(etag());
app.use(function (ctx) {
ctx.body = 'Hello World';
});
app.listen(3000);
console.log('listening on port 3000');
koa-etag的源码以及注释如下:
'use strict'
/**
* Module dependencies.
*/
const calculate = require('etag')
const Stream = require('stream')
// 用于将老式的 Error first callback 转换为 Promise 对象
const promisify = require('util').promisify
const fs = require('fs')
const stat = promisify(fs.stat)
/**
* Expose `etag`.
*
* Add ETag header field.
* @param {object} [options] see https://github.com/jshttp/etag#options
* @param {boolean} [options.weak]
* @return {Function}
* @api public
*/
module.exports = function etag (options) {
// 返回的就是个中间件函数
return async function etag (ctx, next) {
await next()
// 获取响应体
const entity = await getResponseEntity(ctx)
setEtag(ctx, entity, options)
}
}
async function getResponseEntity (ctx) {
const body = ctx.body
// !body -- 没有 body 就不用设置 etag 了;
// ctx.response.get('etag') -- 如果已经设置过etag了也不用再设置etag了
if (!body || ctx.response.get('etag')) return
// 看下status是数字几开头的, 比如2xx, 4xx, 3xx
const status = ctx.status / 100 | 0
// 如果不是2xx的 就相当于请求失败,也不用设置了
if (status !== 2) return
if (body instanceof Stream) { // 看body是不是流对象(Stream), 是的话, 根据对应的 path, 调用fs.stat 返回对应的stats
if (!body.path) return
return await stat(body.path)
} else if ((typeof body === 'string') || Buffer.isBuffer(body)) { // 看body是不是 string 或 Buffer
return body
} else { // 一般是对象
return JSON.stringify(body)
}
}
function setEtag (ctx, entity, options) {
if (!entity) return // entity 没有的话 就不用设置etag了, 对应 getResponseEntity 方法里面的直接 return
// 调用 etag 模块,计算并生成 etag
ctx.response.etag = calculate(entity, options)
}
核心就是 先调用 getResponseEntity 获取响应实体
然后调用 etag 计算生成 etag
注意, ctx.body 有如下类型
string written
Buffer written
Stream piped
Object || Array json-stringified
null no content response
然后body大致可以分为三种
- body instanceof Stream // stream 类型,平常的css、js、html、png等 这些静态资源 都是stream类型的
- typeof body === 'string' || Buffer.isBuffer(body) // 字符串类型和Buffer类型, 比如文件下载,一般就是返回二进制的Buffer
- 其他类型
etag的源码以及注释如下:
/*!
* etag
* Copyright(c) 2014-2016 Douglas Christopher Wilson
* MIT Licensed
*/
'use strict'
/**
* Module exports.
* @public
*/
module.exports = etag
/**
* Module dependencies.
* @private
*/
var crypto = require('crypto')
var Stats = require('fs').Stats
/**
* Module variables.
* @private
*/
var toString = Object.prototype.toString
/**
* Generate an entity tag.
*
* @param {Buffer|string} entity
* @return {string}
* @private
*/
// Buffer、String 类型生成 etag 依赖于 crypto 生成 hash
// hash 的生成主要依赖于sha1的加密方式
function entitytag (entity) {
if (entity.length === 0) {
// fast-path empty
return '"0-2jmj7l5rSw0yVb/vlWAYkK/YBwk"'
}
// compute hash of entity
var hash = crypto
.createHash('sha1')
.update(entity, 'utf8')
.digest('base64')
.substring(0, 27)
// compute length of entity
var len = typeof entity === 'string'
? Buffer.byteLength(entity, 'utf8')
: entity.length
return '"' + len.toString(16) + '-' + hash + '"'
}
/**
* Create a simple ETag.
*
* @param {string|Buffer|Stats} entity
* @param {object} [options]
* @param {boolean} [options.weak]
* @return {String}
* @public
*/
function etag (entity, options) {
if (entity == null) {
throw new TypeError('argument entity is required')
}
// support fs.Stats object
var isStats = isstats(entity)
var weak = options && typeof options.weak === 'boolean'
? options.weak
: isStats
// validate argument
if (!isStats && typeof entity !== 'string' && !Buffer.isBuffer(entity)) {
throw new TypeError('argument entity must be string, Buffer, or fs.Stats')
}
// generate entity tag
var tag = isStats
? stattag(entity)
: entitytag(entity)
// 弱etag 比 强etag 多了个 W
return weak
? 'W/' + tag
: tag
}
/**
* Determine if object is a Stats object.
*
* @param {object} obj
* @return {boolean}
* @api private
*/
// 判断obj 是不是 Stats 的实例
// 或者 如果 obj 里面有 ctime mtime ino size 这几个字段 并且数据类型也对的上 也行
function isstats (obj) {
// genuine fs.Stats
if (typeof Stats === 'function' && obj instanceof Stats) {
return true
}
// quack quack
return obj && typeof obj === 'object' &&
'ctime' in obj && toString.call(obj.ctime) === '[object Date]' &&
'mtime' in obj && toString.call(obj.mtime) === '[object Date]' &&
'ino' in obj && typeof obj.ino === 'number' &&
'size' in obj && typeof obj.size === 'number'
}
/**
* Generate a tag for a stat.
*
* @param {object} stat
* @return {string}
* @private
*/
// 生成 stats 类型的 etag
function stattag (stat) {
var mtime = stat.mtime.getTime().toString(16)
var size = stat.size.toString(16)
return '"' + size + '-' + mtime + '"'
}
核心就这俩函数
// generate entity tag
var tag = isStats
? stattag(entity)
: entitytag(entity)
生成etag的原理:
stattag()对应静态文件,etag生成的方式就是文件的size加mtimeentitytag()对应 字符串 或者Buffer,etag生成的方式就是 字符串 或者Buffer的长度 加上 通过sha1算法生成的hash串的前27位
关于强、弱Etag
这俩的生成方式如下
// 弱etag 比 强etag 多了个 W
return weak
? 'W/' + tag
: tag
在上述Etag方法里 其实弱Etag 就是比强Etag多了个 字母 W, 生成的原理都是一样的
使用的时候强校验的ETag匹配要求两个资源内容的每个字节需完全相同,包括所有其他实体字段(如Content-Language)不发生变化。强ETag允许重新装配和缓存部分响应,以及字节范围请求。 弱校验的ETag匹配要求两个资源在语义上相等,这意味着在实际情况下它们可以互换,而且缓存副本也可以使用。不过这些资源不需要每个字节相同,因此弱ETag不适合字节范围请求。
当Web服务器无法生成强ETag的时候,比如动态生成的内容,弱ETag就可能发挥作用了。
文件系统中 mtime 和 ctime 指什么,都有什么不同
在 linux 中,
- mtime:
modified time指文件内容改变的时间戳 - ctime:
change time指文件属性改变的时间戳,属性包括mtime。而在windows上,它表示的是creation time
http 服务中静态文件的 Last-Modified 就是根据 mtime 什么生成
Apache服务器生成etag的方式
Apache默认通过 FileEtag中 INode Mtime Size 的配置自动生成ETag(当然也可以通过用户自定义的方式)
- INode: 文件的索引节点(inode)数
- MTime: 文件的最后修改日期及时间
- Size: 文件的字节数
面试题
1.为什么大公司不太愿意用etag?
因为大公司好多是使用web集群或者说负载均衡,
在web服务器只有一台的情况,请求内容的唯一性可以由Etag来确定,但是如果是多台web服务器在负载均衡设备下提供对外服务,尽管各web服务器上的组件内容完全一致,但是由于在不同的服务器上Inode是不同的,因此对应生成的Etag也是不一样的 (关于 Inode 详细信息可以看这个 https://www.ruanyifeng.com/blog/2011/12/inode.html)
在这种情况下,尽管请求的是同一个未发生变化的组件,但是由于Etag的不同,导致Apache服务器不再返回304 Not Modified,而是返回了200 OK和实际的组件内容(尽管事实上内容不曾发生变化),大大浪费了带宽。
所以有人建议使用WEB集群时不要使用ETag
这个问题其实很好解决,因为多服务器时,INode不一样,所以不同的服务器生成的ETag不一样,所以用户有可能重复下载(这时ETag就会不准),
明白了上面的原理和设置后,解决方法也很容易,让ETag只用后面二个参数,MTime和Size就好了.只要ETag的计算没有INode参于计算,就会很准了.
或者自定义Etag 的生成规则,只要避开那些因机器不同而导致差异的字段就可以了
Koa2里面的etag由于不涉及到Inode 以及其他受机器影响的字段,所以在集群模式下是可用的
2.koa2中协商缓存是如何生效的?
在上面使用koa-etag的时候,用到了 koa-conditional-get, 而 koa-conditional-get 的源码如下:
module.exports = function conditional () {
return async function (ctx, next) {
await next()
if (ctx.fresh) {
ctx.status = 304
ctx.body = null
}
}
}
其实就用哪个调用了ctx.fresh 进行新鲜度检测
可以看到Koa在request中的fresh方法如下:
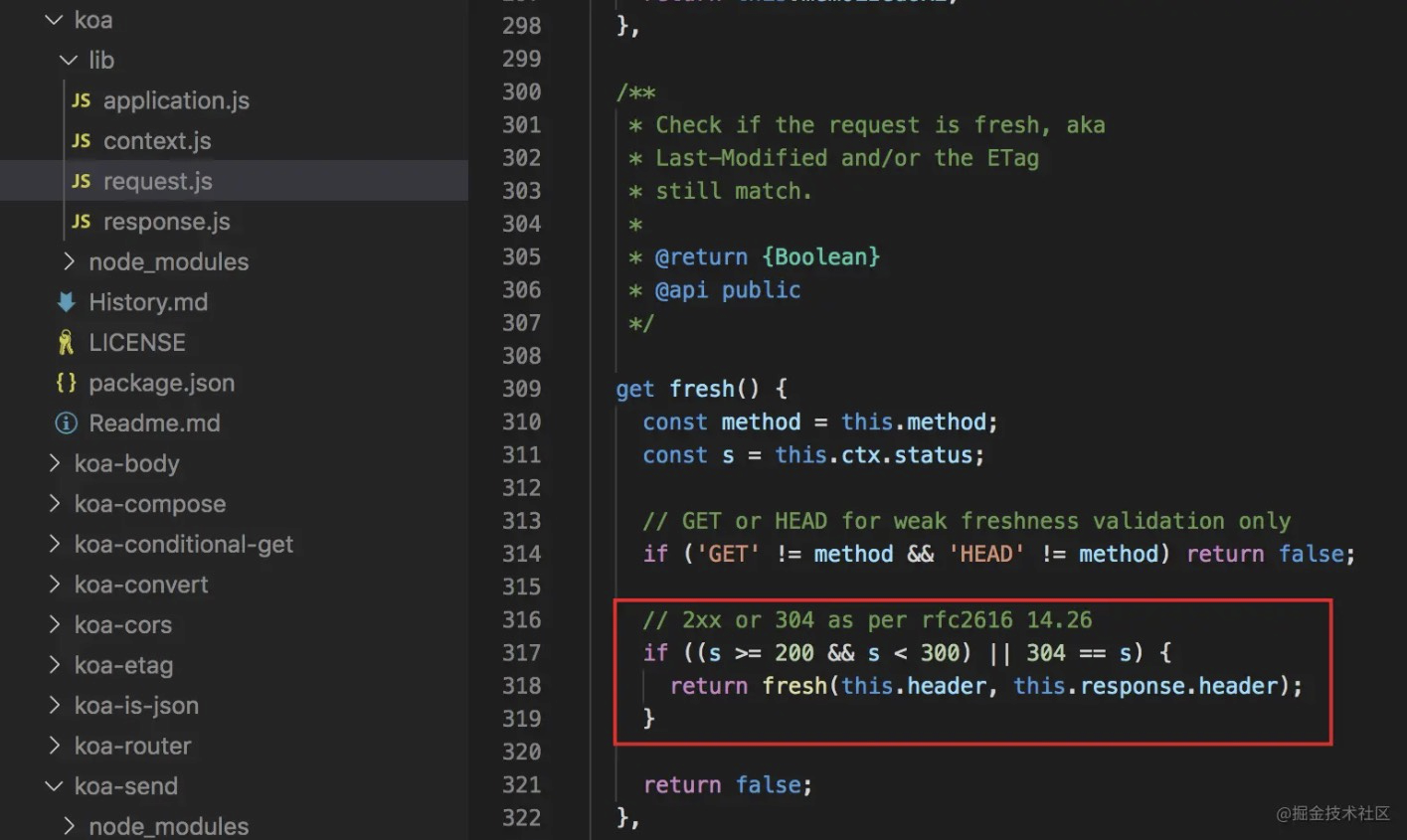
状态码200-300之间以及304调用fresh方法,判断该请求的资源是否新鲜。
fresh方法源码解读:
只保留核心代码,可以自行去看fresh的源码。
var CACHE_CONTROL_NO_CACHE_REGEXP = /(?:^|,)\s*?no-cache\s*?(?:,|$)/
function fresh (reqHeaders, resHeaders) {
// 1. 如果这2个字段,一个都没有,不需要校验
var modifiedSince = reqHeaders['if-modified-since']
var noneMatch = reqHeaders['if-none-match']
if (!modifiedSince && !noneMatch) {
console.log('not fresh')
return false
}
// 2. 给端对端测试用的,因为浏览器的Cache-Control: no-cache请求
// 是不会带if条件的 不会走到这个逻辑
var cacheControl = reqHeaders['cache-control']
if (cacheControl && CACHE_CONTROL_NO_CACHE_REGEXP.test(cacheControl)) {
return false
}
// 3. 比较 etag和if-none-match
if (noneMatch && noneMatch !== '*') {
var etag = resHeaders['etag']
if (!etag) {
return false
}
// 部分代码
if (match === etag) {
return true;
}
}
// 4. 比较if-modified-since和last-modified
if (modifiedSince) {
var lastModified = resHeaders['last-modified']
var modifiedStale = !lastModified || !(parseHttpDate(lastModified) <= parseHttpDate(modifiedSince))
if (modifiedStale) {
return false
}
}
return true
}
fresh的代码判断逻辑总结如下,满足3种条件之一,fresh为true。
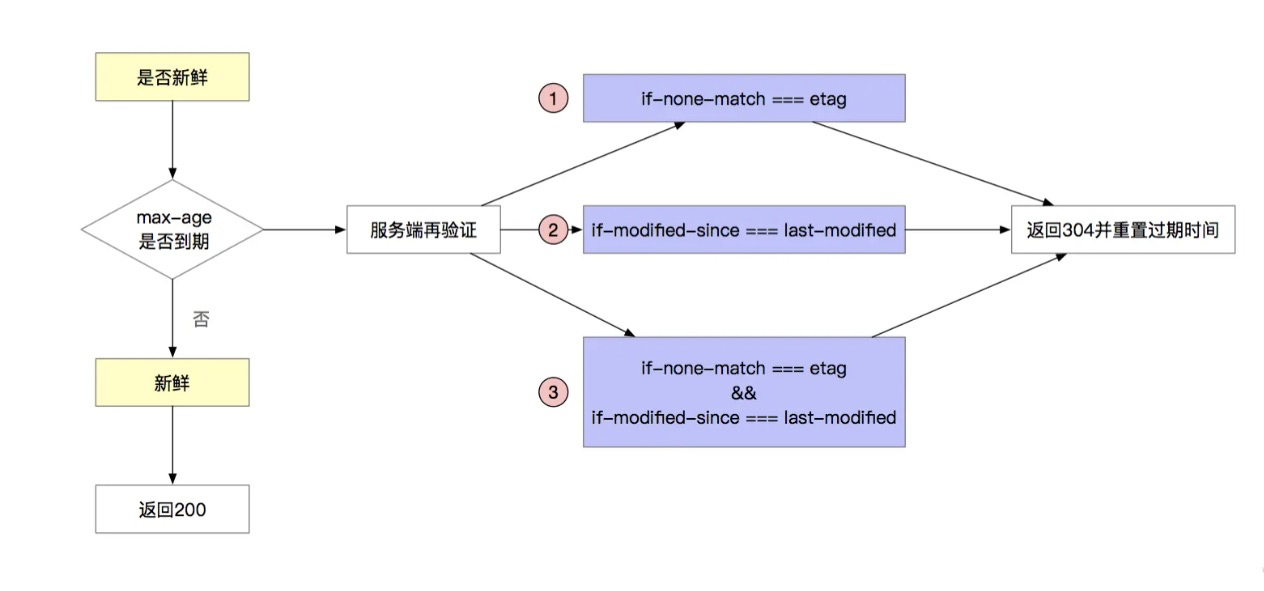
3.关于koe-etag的使用方法
看下面的代码,为啥要先 app.use(conditional()); 再 app.use(etag()); ?
const conditional = require('koa-conditional-get');
const etag = require('koa-etag');
const Koa = require('koa');
const app = new Koa();
// etag works together with conditional-get
app.use(conditional());
app.use(etag());
答:
其实这个koa2的洋葱模型原理,看下图:
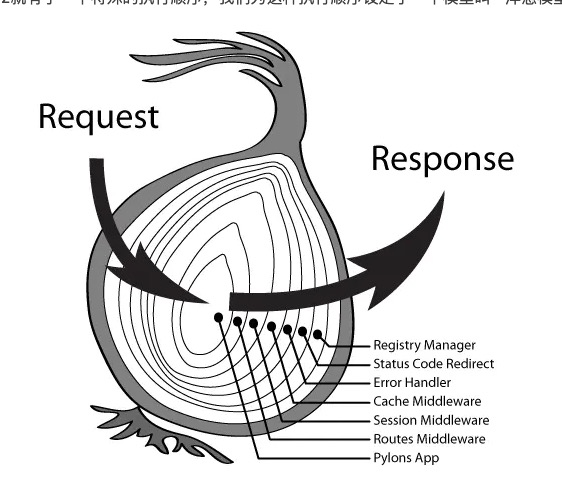
因为最后一步才进行新鲜度检测, 所以 app.use(conditional()); 要放在最前面
更多关于洋葱模型可以参考: https://www.jianshu.com/p/4cf2d9792165
浏览器缓存整体流程
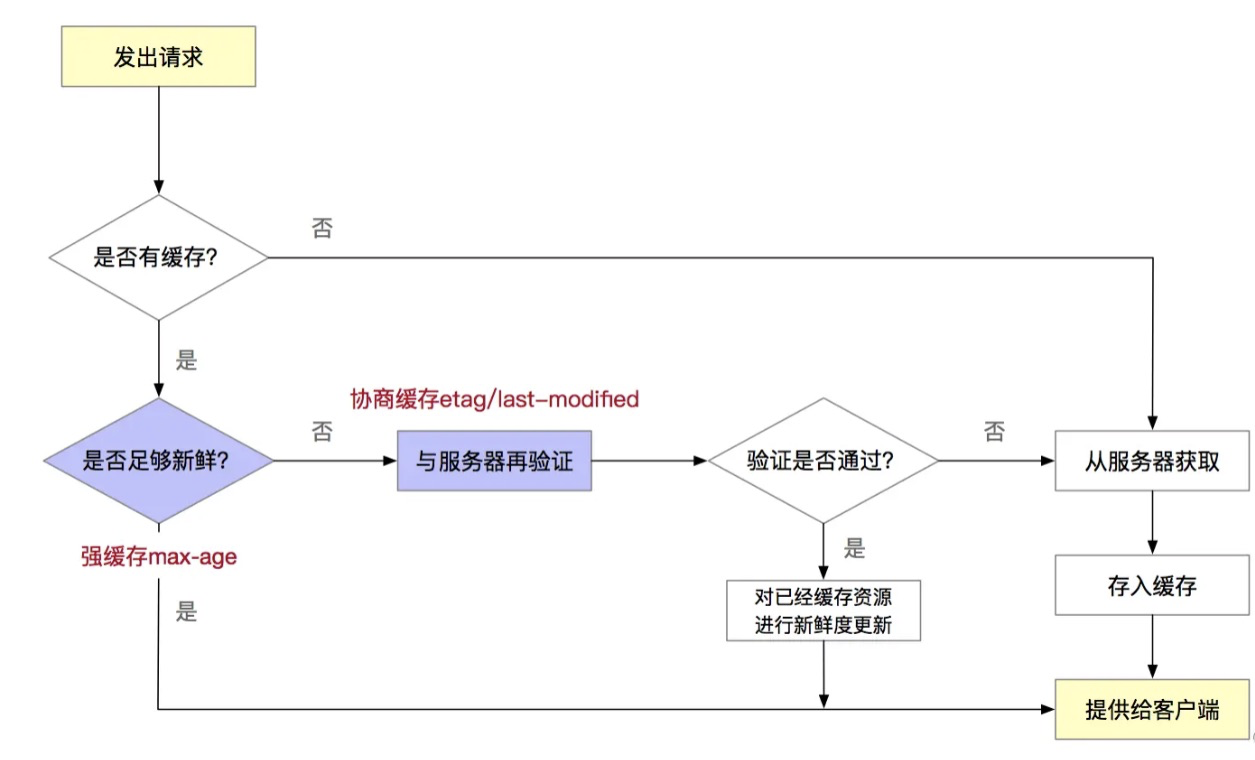
1.发出请求后,会先在本地查找缓存。
2.没有缓存去服务端请求最新的资源,返回给客户端(200),并重新进行缓存。
3.查到有缓存,要判断缓存本地是否过期(max-age等)。
4.没有过期,直接返回给客户端(200 from cache)。
5.如果缓存过期了,看是否有配置协商缓存(etag/last-modified),去服务端再验证该资源是否更新,本地缓存是否可以继续使用。
6.如果发现资源可用,返回304,告知客户端可以继续使用缓存,并根据max-age等更新缓存时间,不需要返回数据,从而减少整体请求时间。
7.如果服务端再验证失败,请求最新的资源,返回给客户端(200),并重新进行缓存。
参考资料:
https://juejin.cn/post/6844904133024022536#heading-19
https://www.sohu.com/a/328853216_463987
https://www.jianshu.com/p/4cf2d9792165
https://www.cnblogs.com/MrZhujl/p/15070866.html
https://www.ruanyifeng.com/blog/2011/12/inode.html

