

关于Java里面的String.getBytes()方法
关于Java里面的String.getBytes()方法
Java里面的String类型的编码方式是Unicode,根据你项目字符串的编码方式无关,这是写死的。但是如果你jvm平台使用的是GBK编码方式,那么你通过string里面的getBytes()方式获取的字符的字节是2。如果使用的是UTF-8编码的方式,那么一个字符getBytes()方式获取的字符的字节长度应该是3.
下面给个例子进行展示:
String str ="你好"; //project的字符集是UTF-8
byte[] B = str.getBytes(); //所以这里默认应该使用UTF-8进行编码
System.out.println(B.length);
System.out.println(Charset.defaultCharset());
//结果是:(果然是6)
//6
//UTF-8
这里的**str.getBytes()**方法官方给出的解释是:
Encodes this String into a sequence of bytes using the platform’s default charset, storing the result into a new byte array.
就是说**getBytes()**函数会根据平台的默认字符串返回byte[]数组,这个platform’s default charset并跟操作系统有关。当然你可以在Eclipse中设置你的项目使用的编码方式,更改项目文件的编码方式能改变平台的中的默认编码方式。
在Eclipse中可以通过选定项目,然后通过上方的工具栏Project–>Properties–>Resource处更改项目编写的文件的encoding方式。
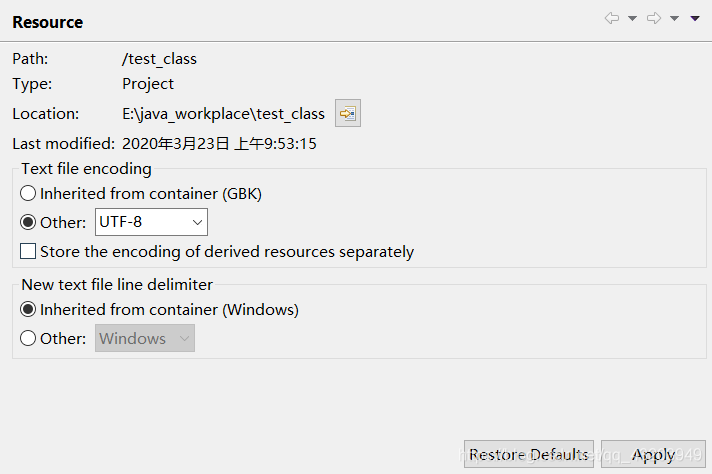
如果我更改成默认的GBK,那么下面的例子返回的字节长度就会变成4
String str ="你好"; //project的字符集是GBK
byte[] B = str.getBytes(); //
System.out.println(B.length);
System.out.println(Charset.defaultCharset());
//结果是:
//4
//GBK


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)