


1.2
一..接口测试:通过相应的工具或者人工对某一个接口的工作状态进行测试的过程
二..接口测试点:
1.测试接口正确性:保证接口地址与请求方法是正确的
2.测试接口的安全性:有一些接口不能直接暴露,我们需要对它进行炎症之后才可以去调用
3.测试接口的性能:例如:我们需要考虑某一个接口在N多个用户访问的时候工作的压力
4.测试接口的数据:保证接口返回的数据与预期是一样的.
1.3Restful风格:
一..定义:是一种接口架构的风格,他不是一个具体的接口
二..restful风 格具体的体现:
1.http:网络传输协议
2.服务器地址:就是我们当前项目存在的所在的ip地址.[域名和ip]
3.端口号:就是当前服务在服务器上所具有的编号.
4.服务/版本:当前项目的相关信息
5.资源:通过当前的接口我们肯定是相对服务器上的数据进行操作,此时被我们操作的数据就是资源
6.资源集合:http://武汉/洪山区/光谷....光谷是一个地方,在细小的还可以划分
7.单个资源:单个资源我们一般都是相当于某一个集合来说
三:常见的http状态码:
1.Get 查询数据 200
2.Post 新增数据 200/201
3.Put 更新数据 200/201
4.Delete 删除数据 204
1.4Jmeter工具
1.定义:基于java有apche开源组织开发和维护的一款测试工具.
2.测试计划:在jmeter里面所有的测试都是基于一个测试计划.
3.接口测试原理:通过工具模拟客户端向服务器发送请求.
4.jmeter就是一款帮我们操作上述的动作,所以在它本身就定义了一些专门来与实际操作相对应的模块,我们把这些模块称之为元件.
5.线程组就是我们的用户
6.测试片段:相当于一个临时的位置,帮我们 存放一些东西,它里面的内容并不会执行
7.测试元件:当我们有测试计划和线程组的时候就可以开始完成实际的测试,此时,jmeter就准备了元件帮我们完成具体的事情.
1.5jmeter八大元件
1.它就是我们jmeter本身存在的固定模块
2.元件分类和作用基本介绍:
1.逻辑控制器:该元件主要的内容就是管理它下面的取样器以及控制相关取样器的执行顺序.
2.配置元件:它主要就是为当前测试提供数据.
3.定时器:它可以用来控制当前取样器的执行时机.
4.前置处理器:它主要是完成某一个请求发生之前需要做的事情.
5.取样器:完成具体发送请求的工作.
6.后置处理器:完成,某一个求发生之后需要做的事情.
7.断言:当前请求的实际结果与我们预期结果进行比较判断.
8.监听器:我们接口请求是没有界面的,所以它就可以帮我们提供一些可视化的界面.
1.6元件的执行顺序和作用域
1.6.1.执行顺序:当八个援建都存在的时候,默认执行的顺序是:逻辑控制器-->配置元件-->定时器-->前置处理器-->取样器-->后置处理器-->断言-->监听器.如果多个同类型的元件都存在的时候就是按着顺序执行.
1.6.2.元件作用域:
1.作用域定义:在jmeter里我们就可以把元件作用的范围称之为作用域.
2作用域:
01.我们将八个元件分为三类:
逻辑控制器:它只对它下面的内容起作用.
取样器:不论它放在那里都会执行.
其它:如果当前元件的父级是一个取样器,那么它会对这个取样器下面的所有的内容起作用,如果当前元件的父级不是取样器那么它就会对这个节点下的所有的子(儿子/孙子)都起作用.
1.7jmeter参数化
1.参数化我们可以理解为,试讲接口测试中出现那的一些数据通过变量的形式体现出来
一.用户参数:
1.添加一个用户参数前置处理器---->一般是用户参数
2.在该元件中设置需要的变量名及变量值-->注意变量名可以随意取,但是变量值的形式是${变量值}
3.如果有多个值我们可以在线程组中设置多个线程来循环拿出
二.用户定义的变量
1.添加一个用户定的变量配置元件,在他里面书写上相应的变量规则[一般就是相同的前缀和多个值]
2.将我们的取样器和配置元件放到foreach逻辑控制器中[foreach就会自动的去帮我们遍历元件中的多个值]
(1)输入变量前缀:在元件中我们自己定义的前缀
(2)Start index end index :编号从0开始,分别用来设置当前遍历的开始和结束位置
(3)输入变量名:具体我们将来想要引用的变量名
(4)是否添加_:如果我们元件中的变量名后面有_就勾选,否则不选.
三.读取外部文件
1.本质就是添加一个叫csv data set config 的配元件,通过它去读取一个外部存放数据的文件[就是一个文本文件]
2在文件中按着格式来定义我们想要的数据[将分隔符确定]
3.元件相关参数:
(1)写入存放文件的路径[绝对+相对都可以]
(2)文件编码 utf-8
(3)变量名称,多个之间用逗号隔开[具体数据引用名]
(4)分隔符 和 是否允许数据中出现分隔符
(5)数据读取文件结尾之后是否允许循环,默认是true表示允许
(6)数据读到结尾之后之后是否停止线程,默认是false
(7)数据共享模式
1.8jmeter集合点
1.定义:就是在jmeter中通过添加一些配置元件来还原大批量用户同事访问一个接口的场景
2.Synchronizing Timer通过添加该元件来设置我们想要的集合的用户信息,第一个参数就是我们想要集合的用户量,第二个参数就是我们希望的集合时间,其中第二点需要注意
(1)如果我们填写的集合用户数大于了实际的用户量[此时没有办法执行]
(2)如果我们设置等待时间内没有将所有的用户集齐,那么就执行当前准备好的.
1.9jmeter关联
1.关联就是将我们多个操作关联起来
2.正则表达式提取器介绍:
01正则表达式就是一种能够帮我们从一堆字符中提取相应内容的规则
02正则元字符:[所谓的元字符就是正则这门语言里的标记]
. 表示任意字符
* 表示0个或者多个
+ 表示1或者多个
? 表示匹配一次
03引用名称:给我们提取的数据设置一个变量名
04正则表达式:要求讲规则写在()
05匹配数据:0表示从匹配到的是护具中随机获取一个值,1表示将所有的匹配结果都输出
1.10 Json-path插件
1对于我们接口来说,早实际的生产环境中有很多的数据都是以json字符串的形式返回,此时我们就需要从这种格式中提取数据.
2.为了我们可以很方便的从json串里获取到某个值的路径,我们可以给Chrome浏览器安装一个json-handle插件[拖拽安装--启用].
3.在相应的取样器后添加json--path后置处理器,然后在它里面设置好相应的变量名与值得路径,将json修改为$即可.
4.debug取样器:它的功能就是可以将我们当前的jmeter所有可用的变量与变量值都列出来.
1.11断言
1.响应断言:在他里面可以选择不同的判断模式.其中分两组,前两者 为一组可以写正则,而后两者只能写具体的字符串.包括的含义是只要实际结果中有我们期望值我们就认为断言通过,而匹配的含义就是实际值与与我们的期望值必须完全一样.
2. 断言持续时间:可以对某一个接口的请求响应时长做判断
1.12逻辑控制器
1.include controller : 它的功能就是引入一个当前脚本之外的测试片段,被引入的文件中一定不能有线程组.
2.switch: 它下面可以存放多个取样器,通过设置条件可以选择具体执行哪一个,其中不写则默认执行第一个,如果写数字编号从0开始,还可以写具体的请求名称.
3while:他用来控制下面取样器的循环执行,默认不写时所有的子取样器都会循环执行,如果此时最后一个取样器错误,那么它只循环一次,第一个错误或者中间错误不影响循环执行.如果写LAST,基本和不斜视杨的,区别在于此时循环的前面如果有一个错误请求,那么循环就不会开启.
2.jmeter函数
jmeter中的函数我们一般不用自己去写,只要知道函数助手来自动生成即可调用,它的主要功能就是想在准备一个变量
01. csvRead; 可以在jmeter中读取一个外部文件数据,其中第一个参数只能书写绝对路径,第二个参数是一个数值,从0 开始,表示当前想要使用数据的列号(比如:001,ws,123.....写的0就是001,写1就是ws,2就是123).如果存在多条数据的时候可以设置多个线程数来进行遍历.
02.counter:可以调用一个计数器,每次步增为1给我们产生计数,其中一个参数设置为FALSE的时候表示所有线程(3个线程)共用一个计数器(num=1,2,3),而设置为TRUE的时候表示每个用户都有一个计数器(num=1,1,1)
03.threadNum: 可以返回当前请求的是第几个线程.
04.random: 可以返回一个随机数值, 大小在我们设置的开始和结束值之间.
05.randdomString: 返回一个随机字符串,有两个参数分别表示随机字符的长度与随机的内容取样范围.
06.setproperty: 设置一个全局属性,其中需要在bean shell取样器中执行这个函数.然后在需要的地方调用.
07.property:该函数就是用来调用全局的属性.
08.默认情况下一个测试计划下的多个线程组之间的数据不是能通用的,我们需要自行设置才可以
1.2jmeter数据库相关
一.如何连接数据库[以mysql为例]
1.mysql与jmeter本身都是独立的软件,所以我们必须将二者建立一个链接之后才能使用.
2.在jmeter中通过一个叫数据库连接池的配置元件进行链接,其中第一个参数写的就是自定义得了链接名称,我们后续就用它来代表我们的数据库链接,最后一个参数模块包含了我们需要的链接信息.
(1)数据地址:jdbc:mysql://127.0.0.1:3306/数据库名
(2)数据库连接驱动:将相应的安装包安装到lib目录下,然后重启jmeter之后在这里填写com.jdbc.mysql.Driver
(3)填写数据库用户名和密码.
3.上述操作完成之后我们就相当于已经把jmeter和数据库建立了一个链接,然后我们就可以发送请求来执行相关的操作,此请求叫 jdbc_request[取样器]
4.相对于这个请求来说,我们必须要填的是'链接名称'和响应的操作语句,其中除了select操作之外其它的操作模式都需要设置为updata
5.如果想要对获取到的数据库进行操作,我们可以在它下面定义一个变量名,此时它会将所有的数据都会以这个变量名为前缀给罗列出来
1.3逻辑控制器
1.交替控制器:该控制器下可以有多个取样器,此时如果有多个循环次数那么这些取样器会交替来执行
2.如果(if)控制器:下面存放多个取样器,然后可以通过条件判断当前执行哪一个,条件可以使包含jmeter变量表达式.但是如果勾选第一个参数选项则要求这里的条件必须为TRUE的时候才会执行它下面的取样器.
3.仅一次控制器:不论外层的线程组如何去执行它下面的取样器,只会执行一次.
4.循环控制器:当我们想要设置一个取样器循环执行的时候,建议通过这里来设置,因为他的效率会比线程组中设置高一些.
5.模块控制器:和include类似,它是用来引入当前jmx脚本里的测试模块,一般用于做某些通用模块的存放.
6.简单控制器:专门用来对取样器进行分组.
7.随机控制器:下面存放多个取样器,但是每次只执行一个.
8.随机顺序控制器:下面有多个取样器,每次生成一个随机的执行顺序.
1.4 API文档的由来和作用
1.API文档最初会有转么的人设计,然后交由我们进行测试.
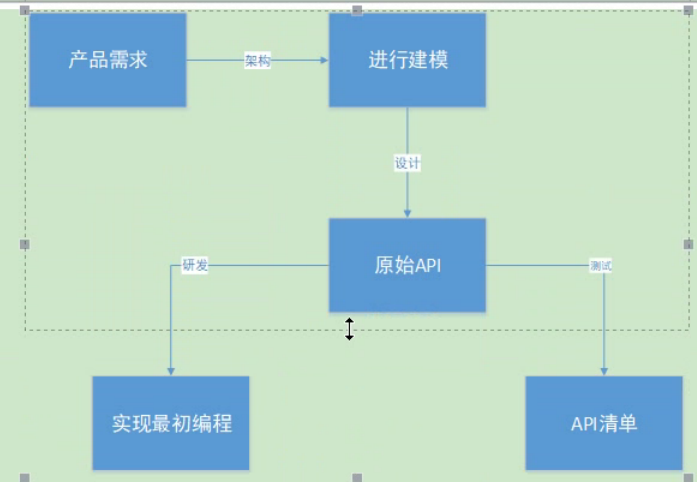
2.有了原始的API文档之后,我们需要最终产出具体测试需要的脚本及用例
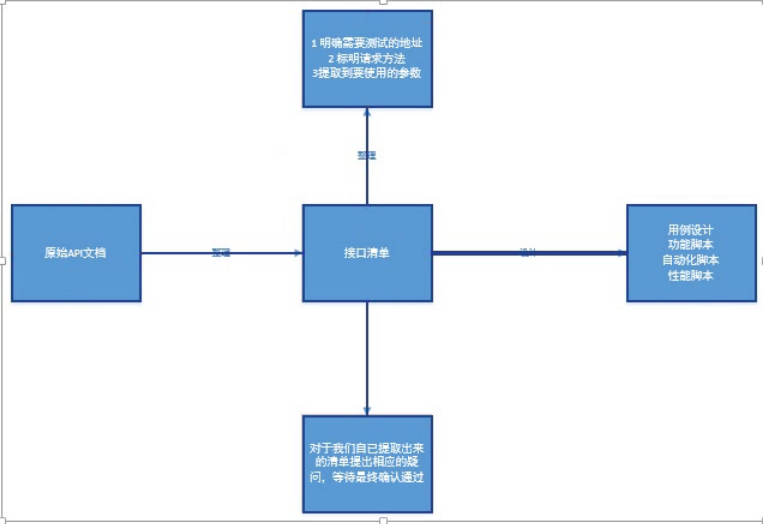
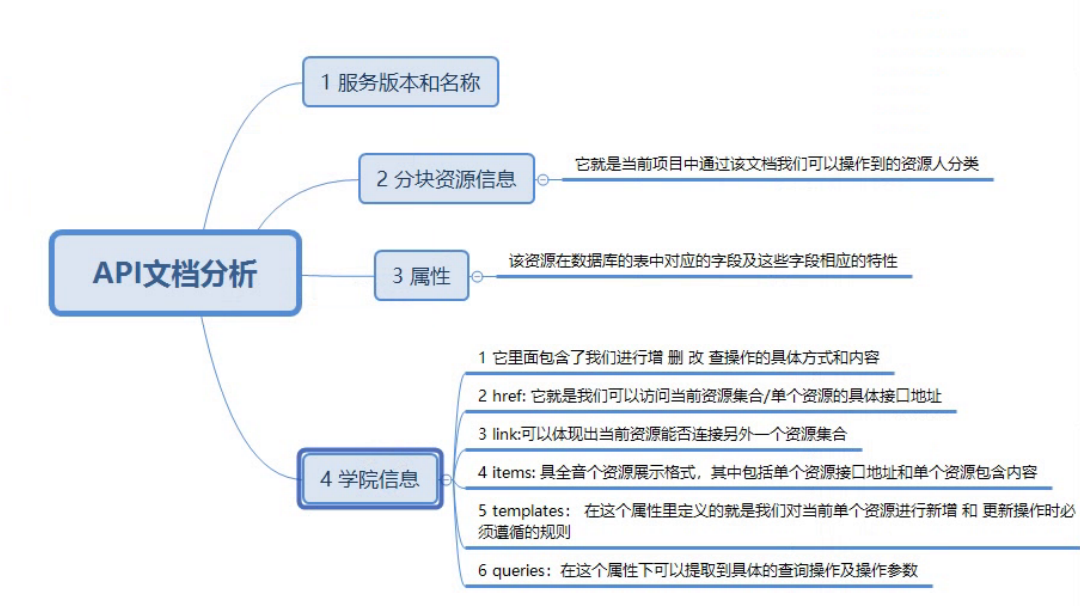
3.1功能脚本设计
1.当我们整理完接口清单之后,需要将它们放到相应的测试工具当中,而此时在工具的脚本,我们就称之为功能脚本.
2.基本步骤:
1.将接口中相同的url地址及http信息管理分别用配置元件中的http请求默认值与http信息头管理器来定义,其中信息头当中填写的就是[Content-Type--application/json;charset=utf8]
2.给每一个接口分配到具体的线程组里面,发送请求执行,此时当中出现的数据我们为了后续的用例设计,所以采用csv读取外部文件操作.
4.1自动化脚本
1.自动化脚本我们可以认为是在某一个程序或者功能测试结果结束之后需要上线之前我们要进行的测试,这个测试的目的就是保证当前程序以及功能是真正可用的.
2自动测试相关原则:
01当中的测试用例是可以独立运行且重复执行.
02该种测试完成之后对原始数据没有污染.
03一定要勾选测试计划下面的"独立运行每个线程组"来保证我们的线程组执行顺序.
04将每个小线程组中的 查看结果树删除 ,只保留测试计划本身即可
05如果脚本内部有虚幻,那么我们建议在当前线程下面新增循环控制器(效率高一些).
二.jmeter如何连接sqlite
1.我们需要一个数据库图形化管理软件.
2.新建数据库连接池,对于sqlite来说,我们需要安装相应的驱动类,同时定义链接名称以及相应的必填项[jdbc:sqlite:数据库具体地址 || org.sqlite.JDBC]
三.通过 set teardown 线程组来新增删除测试学院数据
1.先完成学院的新增,此过程建议给该学员分配一个非常明显的前缀,用于后面获取.
2.向数据库发送 jdbc 请求 将我们上述的学院 id 拿到.
3.生成相应的 setproperty 函数,同事在 bean shell 取样器中执行相应的SQL语句.
4.在需要使用该全局属性额地方通过 property 函数进行获取使用.
5. Jmeter性能脚本设计
1.我们可以将性能脚本理解为是在我们设计的执行环境下来考验当前接口的响应能力.
2.我们将接口分为 查询和非查询两类:
01对于查询类我们一般的性能测压方法就是让当前接口在固定的时间内不停的去执行,然后通过相应的监听器来得到具体的数据.
02非查询类:一般我们就准备相应的数据用户,然后在规定的时间内让这些接口执行,然后查看数据.
3.在jmeter中我们常用的监听器有三种: 聚合报告,平均响应时间rt,每秒事务处理能力tps
5.Jmeter 导出html测试报告
1.该操作只支持jmeter3.1之后的版本,需要在cmd中执行jmeter.
2.有了html报告的好处就是我们可以很方便的去查看以及分析相关的数据,同时会将当前的脚本保留,如果下次更新了脚本之后,我们还可以通过这份报告来回滚之前的内容.
6.接口用例设计
1.对于接口测试来说当我们有了具体的功能脚本之后,我们需要做的事情就是需要准备更多的测试数据让这些脚本来执行,从而确定我们当前脚本在某种情况下的执行结果.
2.用参数化来覆盖我们的测试用例.此时我们一般分为正向和逆向两个方向:
01 正: 传入所有的必须数据
02 逆: 参数不存在,参数为空,参数格式不正确(超长,包含特殊字符,空格,大小写.....)

