
C#常见的数据结构
数据结构:
1.Set集合,纯粹的容器,无需存储,就是一个容器
2.线型结构:在存储的时候,一对一存储
3.树形结构:表达式目录树(二叉树)、菜单结构:一对多
4.图形结构:扩扑图、网状结构(地图开发,用C#高级–常用数据结构
一.线程结构
1.线程结构:Array/ArrayList/List/LinkedList/Queue/Stack/HastSet/SortedSer/Hashtable/SortedList
Dictionaty/SortedDictionary
2.数组:内存连续储存,节约空间,可以索引访问,读取快,增删慢
Array:在内存上连续分配的,而且元素类型是一样的可以坐标访问,读取快---增减慢,长度不变
ArrayList:在以前的开发中使用不较多,不定长度,连续分配的元素没有限制,任何元素都是当成Object处理,如果是值类型,会有装箱操作读取快,增删慢
List:是Array,内存上都是连续摆放,不定长度,泛型,保证类型安全,避免装箱拆箱 性能也比ArrayList高读取快,增删慢以上特点:读取快,增删相对慢
3.非连续摆放,存储数据+地址,找数据的话就只能顺序查找,读取慢,增删快
3.1.LinkedList:泛型的特点:链表,元素不连续分配,每个元素都有记录前后节点,节点值可以重复能不能以下标访问:不能没找元素只能遍历,查找不方便增删 就比较方便LinkedList<int> node123 = linkedList.Find(123);得到节点
3.2.Queue 就是链表 先进先出 放任务延迟执行,A不断写入日志任务 B不断获取任务去执行
Queue queue = new Queue();
queue.Equals(); //添加数据
queue.Dequeue(); //获取并移除数据
3.3.Stack 就是链表 先进先出 解析表达式目录树,先产出的数据后使用,
操作记录为命令,撤销的时候是倒序
Stack stack = new Stack();
stack.Push();//添加数据
stack.Pop();//获取并移除数据
二.Set纯粹的集合,容器,东西丢进去,唯一性,无序的
1.集合:hash分布,元素间没有关系,动态增加容量,去重
统计用户IP:IP投票 交叉并补---二次好友/间接关注/粉丝合集
2. 排序的集合:去重 而且排序
统计排名 -- 没统计一个就丢进集合里
IComparer<T> comparer 自定义对象的排序,就用这个指定
3.Hashtable Key-value 体积可以动态增加 拿着Key计算一个地址,然后放入Key-value
object - 装箱拆箱 如果不同的key得到相同的地址,第二个在前面地址上+1 浪费了空间,Hashtable是基于数组实现
4.线程安全
ConcurrentQueue 线程安全版本的Queue
ConcurrentStack 线程安全版本的Stack
ConcurrentBag 线程安全的对象集合
ConcurrentDictionary 线程安全的Dictionary
BlockingCollection
一、常见的数据结构
1、集合[Set]
2、线性结构
3、树形结构
4、图形结构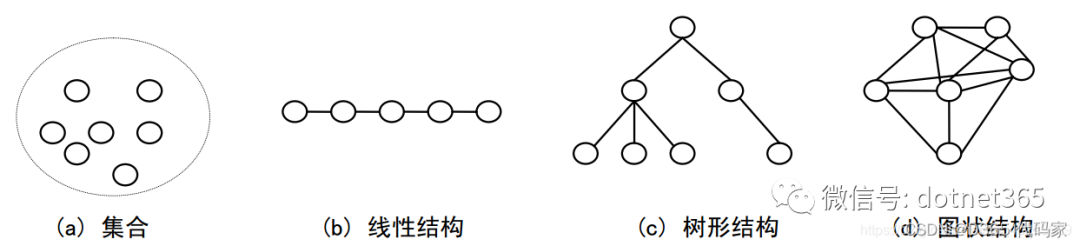
二、Array/ArrayList/List
内存上连续存储,节约空间,可以索引访问,读取快,增删慢
1、Array
元素类型是一样的,定长
int[] list = new int[3];
list[0] = 123;
string[] stringArray = new string[] { “123”, “234” };
for (int i = 0; i < list.Length; i++)
{
Console.WriteLine(list[i]);
}
2、ArrayList
元素没有类型限制,任何元素都是当成object处理,如果是值类型,会有装箱操作,不定长
ArrayList list = new ArrayList();
//增加元素,增加长度
list.Add(“张三”);
list.Add(“Is”);
list.Add(32);
//索引赋值,不会增加长度,索引超出长度直接报错
list[2] = 26;
list.AddRange(new ArrayList() { “李四”,135});
//删除数据
list.RemoveAt(0);
list.Remove(“张三”);
list.RemoveRange(0, 1);//index,count
for (int i = 0; i < list.Count; i++)
{
Console.WriteLine(list[i]);
}
//转换成Arrary
object[] list2 = (object[])list.ToArray(typeof(object));
object[] list3 = new object[list.Count];
list.CopyTo(list3);
3、List
也是Array,泛型,保证类型安全,避免装箱拆箱,性能比Arraylist高,不定长
List list = new List();
list.Add(123);
list.Add(123);
//list.Add(“123”);类型确定,类型安全,不同类型无法添加
list[0] = 456;
for (int i = 0; i < list.Count; i++)
{
Console.WriteLine(list[i]);
}
三、LinkedList/Queue/Stack
非连续存储,存储数据和地址,只能顺序查找,读取慢,增删快
1、LinkedList
链表,泛型,保证类型安全,避免装箱拆箱,元素不连续分配,每个元素都记录前后节点,不定长
LinkedList list = new LinkedList();
//list[3] //不能索引访问
list.AddFirst(123);//在最前面添加
list.AddLast(456); //在最后面添加
//是否包含元素
bool isContain = list.Contains(123);
//元素123的位置 从头查找
LinkedListNode node123 = list.Find(123);
//某节点前后添加
list.AddBefore(node123, 123);
list.AddAfter(node123, 9);
//移除
list.Remove(456);
list.Remove(node123);
list.RemoveFirst();
list.RemoveLast();
foreach (var item in list)
{
Console.WriteLine(item);
}
//清空
list.Clear();
2、Queue
队列,就是链表,先进先出
Queue numbers = new Queue();
//入队列
numbers.Enqueue(“one”);
numbers.Enqueue(“two”);
numbers.Enqueue(“two”);
numbers.Enqueue(“three”);
numbers.Enqueue(“four”);
foreach (string number in numbers)
{
Console.WriteLine(number);
}
//移除并返回队首元素
Console.WriteLine(" D e q u e u e n u m b e r s . D e q u e u e ( ) " ) ; f o r e a c h ( s t r i n g n u m b e r i n n u m b e r s ) C o n s o l e . W r i t e L i n e ( n u m b e r ) ; / / 不移除返回队首元素 C o n s o l e . W r i t e L i n e ( "Dequeue {numbers.Dequeue()}"); foreach (string number in numbers) { Console.WriteLine(number); } //不移除返回队首元素 Console.WriteLine("Dequeuenumbers.Dequeue()");foreach(stringnumberinnumbers)Console.WriteLine(number);//不移除返回队首元素Console.WriteLine(“Peek { numbers.Peek()}”);
foreach (string number in numbers)
{
Console.WriteLine(number);
}
//拷贝一个队列
Queue queueCopy = new Queue(numbers.ToArray());
foreach (string number in queueCopy)
{
Console.WriteLine(number);
}
//判断包含元素
Console.WriteLine(" q u e u e C o p y . C o n t a i n s ( f ¨ o u r ) ¨ = q u e u e C o p y . C o n t a i n s ( " f o u r " ) " ) ; / / 清空队列 q u e u e C o p y . C l e a r ( ) ; C o n s o l e . W r i t e L i n e ( "queueCopy.Contains(\"four\") = {queueCopy.Contains("four")}"); //清空队列 queueCopy.Clear(); Console.WriteLine("queueCopy.Contains(
f
¨
our
)
¨
=queueCopy.Contains("four")");//清空队列queueCopy.Clear();Console.WriteLine(“queueCopy.Count = {queueCopy.Count}”);
3、Stack
栈,就是链表,先进后出
Stack numbers = new Stack();
//入栈
numbers.Push(“one”);
numbers.Push(“two”);
numbers.Push(“two”);
numbers.Push(“three”);
numbers.Push(“four”);
numbers.Push(“five”);
foreach (string number in numbers)
{
Console.WriteLine(number);
}//获取并出栈
Console.WriteLine(" P o p n u m b e r s . P o p ( ) " ) ; f o r e a c h ( s t r i n g n u m b e r i n n u m b e r s ) C o n s o l e . W r i t e L i n e ( n u m b e r ) ; / / 获取不出栈 C o n s o l e . W r i t e L i n e ( "Pop {numbers.Pop()}"); foreach (string number in numbers) { Console.WriteLine(number); } //获取不出栈 Console.WriteLine("Popnumbers.Pop()");foreach(stringnumberinnumbers)Console.WriteLine(number);//获取不出栈Console.WriteLine(“Peek { numbers.Peek()}”);
foreach (string number in numbers)
{
Console.WriteLine(number);
}
//拷贝一个栈
Stack stackCopy = new Stack(numbers.ToArray());
foreach (string number in stackCopy)
{
Console.WriteLine(number);
}
//判断包含元素
Console.WriteLine(" s t a c k C o p y . C o n t a i n s ( f ¨ o u r ) ¨ = s t a c k C o p y . C o n t a i n s ( " f o u r " ) " ) ; / / 清空栈 s t a c k C o p y . C l e a r ( ) ; C o n s o l e . W r i t e L i n e ( "stackCopy.Contains(\"four\") = {stackCopy.Contains("four")}"); //清空栈 stackCopy.Clear(); Console.WriteLine("stackCopy.Contains(
f
¨
our
)
¨
=stackCopy.Contains("four")");//清空栈stackCopy.Clear();Console.WriteLine(“stackCopy.Count = {stackCopy.Count}”);
四、HashSet/SortedSet
纯粹的集合,容器,唯一,无序
1、HashSet
集合,hash分布,动态增加容量,去重数据或者引用类型地址
应用场景:去重可以统计用户IP,计算集合元素的交叉并补,二次好友/间接关注/粉丝合集
HashSet hashSetA = new HashSet();
hashSetA.Add(“123”);
hashSetA.Add(“456”);
//系统为了提高性能,减少内存占用,字符串是设计成池化的,字符串也是引用类型的,同一个字符串地址是相同的,所以会去重
string s1 = “12345”;
hashSetA.Add(s1);
string s2 = “12345”;
hashSetA.Add(s2);
//hashSet[0];//不能使用索引访问
//判断包含元素
Console.WriteLine($“hashSetA.Contains(“12345”) = {hashSetA.Contains(“12345”)}”);
//集合的计算:交叉并补
Console.WriteLine(“集合A******************”);
foreach (var item in hashSetA)
{
Console.WriteLine(item);
}
HashSet hashSetB = new HashSet();
hashSetB.Add(“123”);
hashSetB.Add(“789”);
hashSetB.Add(“12435”);
Console.WriteLine(“集合B******************”);
foreach (var item in hashSetB)
{
Console.WriteLine(item);
}
Console.WriteLine(“交:属于A且属于B的元素******************”);
//拷贝一个集合
HashSet hashSetCopy4 = new HashSet(hashSetB);
hashSetCopy4.IntersectWith(hashSetA);
foreach (var item in hashSetCopy4)
{
Console.WriteLine(item);
}
Console.WriteLine(“差:属于B,不属于A的元素******************”);
HashSet hashSetCopy3 = new HashSet(hashSetB);
hashSetCopy3.ExceptWith(hashSetA);
foreach (var item in hashSetCopy3)
{
Console.WriteLine(item);
}
Console.WriteLine(“并:属于A或者属于B的元素******************”);
HashSet hashSetCopy2 = new HashSet(hashSetB);
hashSetCopy2.UnionWith(hashSetA);
foreach (var item in hashSetCopy2)
{
Console.WriteLine(item);
}
Console.WriteLine(“补:AB的并集去掉AB的交集******************”);
HashSet hashSetCopy = new HashSet(hashSetB);
hashSetCopy.SymmetricExceptWith(hashSetA);
foreach (var item in hashSetCopy)
{
Console.WriteLine(item);
}
//转换成List集合
hashSetA.ToList();
//清空集合
hashSetA.Clear();
//添加对象引用去重
HashSet peoples = new HashSet();
People people = new People()
{
Id = 123,
Name = “小菜”
};
People people1 = new People()
{
Id = 123,
Name = “小菜”
};
peoples.Add(people);
peoples.Add(people1);//内容相同也是不同的对象
peoples.Add(people1);//同一个对象会去重
foreach (var item in peoples)
{
Console.WriteLine(item);
}
2、SortedSet
排序的集合,去重,排序
应用场景:名字排序
SortedSet sortedSet = new SortedSet();
sortedSet.Add(“123”);
sortedSet.Add(“689”);
sortedSet.Add(“456”);
sortedSet.Add(“12435”);
sortedSet.Add(“12435”);
sortedSet.Add(“12435”);
//判断包含元素
Console.WriteLine($“sortedSet.Contains(“12435”) = {sortedSet.Contains(“12435”)}”);
//转换成List集合
sortedSet.ToList();
//清空集合
sortedSet.Clear();
五、Hashtable/Dictionary/SortedDictionary/SortedList
读取,增删都快,key-value,一段连续有限空间放value,基于key散列计算得到地址索引,读取增删都快,开辟的空间比用到的多,hash是用空间换性能
基于key散列计算得到地址索引,如果Key数量过多,散列计算后,肯定会出现散列冲突(不同的key计算出的索引相同)
散列冲突之后,据存储就是在索引的基础上往后找空闲空间存放,读写增删性能就会下降,dictionary在3W条左右性能就开始下降
1、Hashtable
哈希表,元素没有类型限制,任何元素都是当成object处理,存在装箱拆箱
Hashtable table = new Hashtable();
table.Add(“123”, “456”);
//table.Add(“123”, “456”);//key相同 会报错
table[234] = 456;
table[234] = 567;
table[32] = 4562;
foreach (DictionaryEntry item in table)
{
Console.WriteLine(KaTeX parse error: Expected 'EOF', got '}' at position 39: …item.Value}"); }̲ //移除元素 table.R…“table.ContainsKey(“123”) ={table.ContainsKey(“123”) }”);
Console.WriteLine($“table.ContainsValue(“456”) ={table.ContainsValue(“456”) }”);
//清空
table.Clear();
2、Dictionary
字典,支持泛型,有序的
Dictionary<int, string> dic = new Dictionary<int, string>();
dic.Add(1, “HaHa”);
dic.Add(5, “HoHo”);
dic.Add(3, “HeHe”);
dic.Add(2, “HiHi”);
foreach (var item in dic)
{
Console.WriteLine($“Key:{item.Key} Value:{item.Value}”);
}
3、SortedDictionary
字典,支持泛型,有序
SortedDictionary<int, string> dic = new SortedDictionary<int, string>();
dic.Add(1, “HaHa”);
dic.Add(5, “HoHo”);
dic.Add(3, “HeHe”);
dic.Add(2, “HiHi”);
dic.Add(4, “HuHu1”);
dic[4] = “HuHu”;
foreach (var item in dic)
{
Console.WriteLine($“Key:{item.Key} Value:{item.Value}”);
}
4、SortedList
排序列表是数组和哈希表的组合,使用索引访问各项,则它是一个动态数组,如果您使用键访问各项,则它是一个哈希表。集合中的各项总是按键值排序。
SortedList sortedList = new SortedList();
sortedList.Add(“First”, “Hello”);
sortedList.Add(“Second”, “World”);
sortedList.Add(“Third”, “!”);
sortedList[“Third”] = “~~”;
sortedList.Add(“Fourth”, “!”);
//使用键访问
sortedList[“Fourth”] = “!!!”;
//可以用索引访问
Console.WriteLine(sortedList.GetByIndex(0));
//获取所有key
var keyList = sortedList.GetKeyList();
//获取所有value
var valueList = sortedList.GetValueList();
//用于最小化集合的内存开销
sortedList.TrimToSize();
//删除元素
sortedList.Remove(“Third”);
sortedList.RemoveAt(0);
//清空集合
sortedList.Clear();
六、迭代器模式
1、迭代器模式
迭代器模式是设计模式中行为模式(behavioral pattern)的一种。迭代器模式使得你能够使用统一的方式获取到序列中的所有元素,而不用关心是其类型是array,list,linked list或者是其他什么序列结构。这一点使得能够非常高效的构建数据处理通道(data pipeline)。
在.NET中,迭代器模式被IEnumerator和IEnumerable及其对应的泛型接口所封装。
IEnumerable:如果一个类实现了IEnumerable接口,那么就能够被迭代,IEnumerable接口定义了GetEnumerator方法将返回IEnumerator接口的实现,它就是迭代器本身。
IEnumerator:IEnumerator接口定义了访问数据的统一属性和方法object Current:当前访问的数据对象,bool MoveNext():移动到下一个位置访问下一个数据的方法,并判断是否有下一个数据;void Reset():数据列表改变或者重新访问重置位置
Console.WriteLine(“迭代器模式–各自遍历***”);
//数组的遍历
int[] list = new int[3] { 1, 2, 3 };
for (int i = 0; i < list.Length; i++)
{
Console.WriteLine(list[i]);
}
//List遍历
List list2 = new List() { 1, 2, 3 };
for (int i = 0; i < list2.Count; i++)
{
Console.WriteLine(list[i]);
}
Console.WriteLine(“迭代器模式–foreach通用遍历***”);
//通用遍历
foreach (var item in list)
{
Console.WriteLine(item);
}
foreach (var item in list2)
{
Console.WriteLine(item);
}
Console.WriteLine(“迭代器模式–迭代器遍历***”);
//迭代器访问真相
var list3 = list.GetEnumerator();
while (list3.MoveNext())
{
Console.WriteLine(list3.Current);
}
//迭代器访问真相
var list4 = list2.GetEnumerator();
while (list4.MoveNext())
{
Console.WriteLine(list4.Current);
}
2、Yield原理
Yield关键字其实是一种语法糖,最终还是通过实现IEnumberable、IEnumberable、IEnumberator和IEnumberator接口实现的迭代功能,含有yield的函数说明它是一个生成器,而不是普通的函数。Yield必须配合IEnumerable使用。
当程序运行到yield return这一行时,该函数会返回值,并保存当前域的所有变量状态,等到该函数下一次被调用时,会从上一次中断的地方继续往下执行,直到函数正常执行完成。
当程序运行到yield break这一行时,程序就结束运行退出。
方法定义
// Yield方法
public static IEnumerable Yield()
{
for (int i = 0; i < 5; i++)
{
if (i > 2 && i < 4)
{
yield break;
}
else
{
yield return Get(i);
Console.WriteLine($“Yield执行第{i + 1}次”);
}
}
}
///
/// 普通方法的遍历
///
///
public static IEnumerable Common()
{
List intList = new List();
for (int i = 0; i < 5; i++)
{
intList.Add(Get(i));
Console.WriteLine($“Common执行第{i + 1}次”);
}
return intList;
}
private static int Get(int num)
{
Thread.Sleep(500);
return num * DateTime.Now.Second;
}
程序调用
var yieldlist = Yield();
foreach (var item in yieldlist)
{
Console.WriteLine(item);//按需获取,要一个拿一个
}
var commonlist = Common();
foreach (var item in commonlist)
{
Console.WriteLine(item);//先全部获取,然后一起返回
}
运行结果
0
Yield执行第1次
19
Yield执行第2次
40
Yield执行第3次
Common执行第1次
Common执行第2次
Common执行第3次
Common执行第4次
Common执行第5次
0
21
42
66
88
本文来自博客园,作者:{春光牛牛,yak},转载请注明原文链接:https://www.cnblogs.com/yakniu/p/17143971.html
欢迎各位大佬们评论指正
QQ讨论群:610129902



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?