序列化组件serializer之序列化与反序列化(一)
一、知识补充
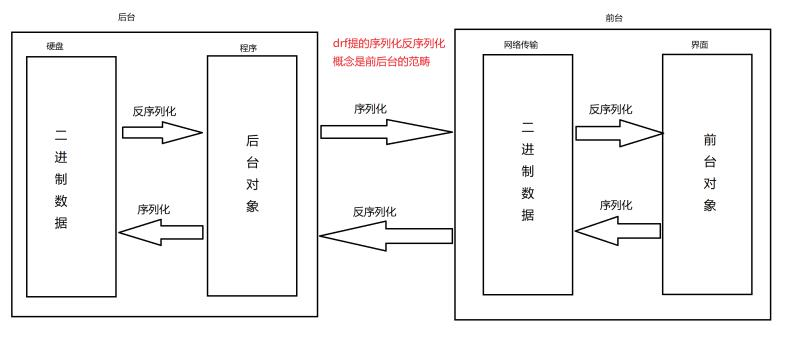
1、序列化与反序列化
""" 1)序列化组件 单表序列化(后台数据返回给前台):将后台的数据对象,转换成能用于网络传输的过程,即又是将对象转换成二进制字符串 单表反序列化(前台提交数据给后台):拿内存的数据转换成对象,展示给用户看 注意:我们接下来说的序列化反序列化都是基于drf前后台分离的序列化组件提出的,只是考虑后台前台之间的过程,不考虑后台从数据库拿数据的过程,
如果严格说序列化与反序列化过程就是数据库数据先反序列成对象,再序列化给前台;反之,前台要将前台的数据对象,先序列化成可以传输的数据,到了后台, 后台再将数据反序列化成后台对象,再序列化到数据库中。 序列化:将数据转换为能传输的数据 反序列化:将传输的数据解析处理 """
2、内部类
# 概念:将类定义在一个类的内部,被定义的类就是内部类 # 特点:内部类及内部类的所有名称空间,可以直接被外部类访问的 # 应用:通过内部类的名称空间,给外部类额外拓展一些特殊的属性(配置),典型的Meta内部类 - 配置类 class Book(model.Model): class Meta: db_model = "owen_book" # 配置自定义表名 class BookSerializer(serializers.ModelSerializer): class Meta: model = "Book" # 配置序列化类绑定的Model表 单列容器:字符串、元组、列表(数组)、集合 双列容器:字典(Map、Hash、obj)
二、DRF响应类:Response
""" def __init__(self, data=None, status=None, template_name=None, headers=None, exception=False, content_type=None): pass data:响应的数据 - 空、字符串、数字、列表、字段、布尔 status:网络状态码 template_name:drf说自己也可以支持前后台不分离返回页面,但是不能和data共存(不会涉及) headers:响应头(不用刻意去管) exception:是否是异常响应(如果是异常响应,可以赋值True,没什么用) content_type:响应的结果类型(如果是响应data,默认就是application/json,所以不用管) """ # 常见使用 from rest_framework import status from rest_framework.response import Response Response( data={ 'status': 0, # 自定义数据状态码 'msg': 'ok', 'result': '正常数据' } ) Response( data={ 'status': 1, 'msg': '客户端错误提示', }, status=status.HTTP_400_BAD_REQUEST, # 网络状态码 exception=True )
三、序列化基类控制的初始化参数
""" def __init__(self, instance=None, data=empty, **kwargs): pass instance:是要被赋值对象的 - 对象类型数据赋值给instance data:是要被赋值数据的 - 请求来的数据赋值给data kwargs:内部有三个属性:many、partial、context many:操作的对象或数据,是单个的还是多个的 partial:在修改需求时使用,可以将所有校验字段required校验规则设置为False context:用于视图类和序列化类直接传参使用 """ # 常见使用 # 单查接口 UserModelSerializer(instance=user_obj) # 群查接口 UserModelSerializer(instance=user_query, many=True) # 增接口 UserModelSerializer(data=request.data) # 整体改接口 UserModelSerializer(instance=user_obj, data=request.data) # 局部改接口 UserModelSerializer(instance=user_obj, data=request.data, partial=True) # partial=True局部 # 删接口,用不到序列化类
四、反序列化
views.py
from rest_framework.views import APIView from rest_framework.response import Response from . import models, serializers from rest_framework import status class UserAPIView(APIView): # 序列化 def get(self, request, *args, **kwargs): pk = kwargs.get('pk') if pk: # 单查 # 1) 数据库交互拿到资源obj或资源objs # 2) 数据序列化成可以返回给前台的json数据 # 3) 将json数据返回给前台 try: obj = models.User.objects.get(pk=pk) serializer_obj = serializers.UserModelSerializer(obj, many=False) return Response({ 'status': 0, # 数据状态码,自己约定的 'msg': 'ok', 'result': serializer_obj.data }) except: return Response( data={ 'status': 1, 'msg': 'pk error' }, status=status.HTTP_400_BAD_REQUEST, # 这是网路状态码 exception=True ) else: # 群查 # 1)数据库交互拿到资源obj或资源objs # 2)数据序列化成可以返回给前台的json数据 # 3)将json数据返回给前台 objs = models.User.objects.all() # 操作多个数据many=True serializer_obj = serializers.UserModelSerializer(objs, many=True) return Response({ 'status': 0, # 数据状态码,自己约定的 'msg': 'ok', 'results': serializer_obj.data }) # 反序列化 def post(self, request, *args, **kwargs): # 单增 # 1)从请求request中获取前台提交的数据 # 2)将数据转换成model对象,并完成数据库入库操作 (序列化组件完成) # 3)将入库成功的对象序列化成可以返回给前台的json数据(请求与响应数据不对等:请求需要提交密码,响应一定不展示密码) # 4)将json数据返回给前台 # ------------------------ # 1)将前台请求的数据交给序列化类处理 # 2)序列化类执行校验方法,对前台提交的所有数据进行数据校验:校验失败,就是异常返回,成功才能继续 # 3)序列化组件完成数据入库操作,得到入库对象 # 4)响应结果给前台 # 获取前台请求的数据 # request_data = request.data # 注意对象要赋值给对象,数据要赋值给数据 # serializer_obj = serializers.UserModelSerializer(data=request_data) # 可简写为 serializer_obj = serializers.UserModelSerializer(data=request.data) if serializer_obj.is_valid(): # 校验成功 => 入库 =>正常响应 # serialize还提供了save obj = serializer_obj.save() return Response({ 'status': 0, 'msg': 'ok', 'result': '新增的那个对象' }, status=status.HTTP_201_CREATED ) else: # 校验失败 => 异常响应 return Response({ 'status': 1, 'msg': serializer_obj.errors, }, status=status.HTTP_400_BAD_REQUEST )
serializers.py
from rest_framework import serializers from rest_framework import exceptions # 异常 # 序列化 from . import models class UserModelSerializer(serializers.ModelSerializer): # 自定义反序列化字段(所有校验规则自己定义,也可以覆盖model已有的字段,自定义字段明确write_only) # 覆盖model已有的字段,不明确write_only会参与序列化过程 password = serializers.CharField(min_length=4, max_length=8, write_only=True) # 覆盖 # 自定义字段不明确write_only会报错,因为序列化会从model 中强行反射自定义字段,但是model没有对应该字段 re_password = serializers.CharField(min_length=4, max_length=8, write_only=True) # 自定义 # # 配置类 class Meta: # # 自定义该序列化类是辅助于那个model类 model = models.User # # # 设置参与序列化与反序列化字段 # # 插拔式:可以选择性返回给前端字段(插头都是在model类中制作) # # fields = ['name', 'age', 'height', 'sex', 'icon', 'gender'] # 第一波分析 # 1)name和age在fields中标明了,且没有默认值,也不能为空,入库时必须提供,所以校验时必须提供 # 2)height在fields中标明了,但是有默认值,所以前台不提供,也能在入库时采用默认值 # 3)password没有在fields中标明,所以校验规则无法检测password情况,但是即使校验通过了,也不能完成入库 # 原因是password是入库的必备条件 # 4)gender 和img是自定义插拔@propetry字段,默认就不会进行校验 # fields = ['name', 'age', 'height', 'img', 'gender'] # 第二波分析 # 问题1)如何区分序列化字段反序列化字段 | 只序列化字段(后台到前台)| 只反序列化字段(前台到后台) # 不做write_only和read_only任何限制=>序列化反序列化字段 # 只做read_only限制=>只序列化字段(后台到前台) # 只做write_only限制=>只反序列化字段(前台到后台) # 2)对前台到后台的数据,指定基础的校验规则(了解) # 问题3)如果一个字段有默认值或是可以为空,比如height,如何做限制 # 虽然有默认值或是可以为空,能不能强制必须提供可以required是True # 前台提交了我就校验,前台没提交,我就不校验1)required是False 2)有校验规则 fields = ['name', 'age', 'password', 'height', 'img', 'gender', 're_password'] # 第三波分析 # 1)对指定的简易校验规则(或没有指定校验规则),可以再通过字段的局部钩子对该字段进行复杂校验 # 2)每个字段逐一进行复杂校验后,还可以进行集体 的全局钩子校验 extra_kwargs = { 'name': { # 'write_only': True, # 'read_only': True }, 'password': { 'write_only': True, 'min_length': 3, 'max_length': 8, 'error_messages': { # 可以被国际化替代 'min_length': '太短', 'max_length': '太长', } }, 'height': { # 'required': True, # 是强制限制必填 'min_value': 0, } } # 注:局部钩子全局钩子,是和Meta同缩进,属于序列化类的 # 局部钩子:validate_要校验的字段(self,要校验的字段值) # 全局钩子:validate(self,所有字段值的字典) 全局钩子一般涉及到自定义反序列化字段比如:re_password # 自定义反序列化字段特点:要参与校验,但不会入库 # 校验规则;成功返回传来的数据|失败抛出异常 def validate_name(self, value): if 'g' in value.lower(): raise exceptions.ValidationError('这个g不行') else: return value def validate(self, attrs): # print(attrs) password = attrs.get('password') # 只是拿出来校验 re_password = attrs.pop('re_password') # 必须取出来校验因为不能入库 if password != re_password: raise exceptions.ValidationError({'re_password': '两次密码不一致'}) else: return attrs
models.py
from django.db import models from django.conf import settings # Create your models here. from django.conf import settings class User(models.Model): SEX_CHOICES = ((0, '男'), (1, '女')) name = models.CharField(max_length=64, verbose_name='姓名') password = models.CharField(max_length=64, verbose_name='密码') age = models.IntegerField() height = models.DecimalField(max_digits=5, decimal_places=2, default=0) sex = models.IntegerField(choices=SEX_CHOICES, default=0) # sex = models.CharField(choices=[('0', '男'), ('1', '女')]) icon = models.ImageField(upload_to='icon', default='icon/default.png') # 自定义序列化给前台的字段 # 1)可以格式化数据库原有字段的数据 # 2)可以对外隐藏原有数据字段名 # 3)可以直接链表 # 制作插头 @property def gender(self): return self.get_sex_display() # get_sex_display()展示性别 @property def img(self): # print(type(self.icon), self.icon) # res = settings.BASE_URL + settings.MEDIA_URL + str(self.icon) # 或者直接拿name也可以 res = settings.BASE_URL + settings.MEDIA_URL + self.icon.name return res def __str__(self): return self.name
五、小结
""" 标注:序列化 => 后台到前台(读) | 反序列化 => 前台到后台(写) 1)不管是序列化还是反序列化字段,都必须在fields中进行声明,没有声明的不会参与任何过程(数据都会被丢弃) 2)用 read_only 表示只读,用 write_only 表示只写,不标注两者,代表可读可写 3) i)自定义只读字段,在model类中用@property声明,默认就是read_only @property def gender(self): return self.get_sex_display() ii)自定义只写字段,在serializer类中声明,必须手动明确write_only re_password = serializers.CharField(write_only=True) 特殊)在serializer类中声明,没有明确write_only,是对model原有字段的覆盖,且可读可写 password = serializers.CharField() 4)用 extra_kwargs 来为 写字段 制定基础校验规则(了解) 5)每一个 写字段 都可以用局部钩子 validate_字段(self, value) 方法来自定义校验规则,成功返回value,失败抛出 exceptions.ValidationError('异常信息') 异常 6)需要联合校验的 写字段们,用 validate(self, attrs) 方法来自定义校验规则,,成功返回attrs,失败抛出 exceptions.ValidationError({'异常字段': '异常信息'}) 异常 7)extra_kwargs中一些重要的限制条件 i)'required':代表是否必须参与写操作,有默认值或可以为空的字段,该值为False;反之该值为True;也可以手动修改值 """ """ 开发流程: 1)在model类中自定义 读字段,在serializer类中自定义 写字段 2)将model自定义字段和所有自定义字段书写在fields中,用write_only和read_only区别model自带字段 3)可以写基础校验规则,也可以省略 4)制定局部及全局钩子 """
Only you can control your future
You're not alone. You still have family,peopel who care for you and want to save you.

