subprocess, re模块,logging, 包等使用方法
subprocess, re模块,logging, 包等使用方法
- subprocess
'''
subprocess:
sub: 子
process: 进程
可以通过python代码给操作系统终端发送命令,并且可以返回结果
'''
import subprocess
while True:
#1、让用户输入终端命令
cmd_str = input('请输入终端命令:').strip()
#Popen(cmd命令,shell=True,
# stdout=subprocess.PIPE,stderr=subprocess.PIPE)
#调用Popen就会将用户的终端命令传给本地的操作系统终端
#并且会得到一个对象,对象中包含着正确或错误的结果
obj = subprocess.Popen(cmd_str, shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
success = obj.stdout.read().decode('gbk')
#中国windows的操作系统默认是中文,所以需转成gbk
if success:
print(success, '正确的结果')
error = obj.stderr.read().decode('gbk')
if error:
print(error, '错误的结果')
'''
请输入终端命令:dir
驱动器 D 中的卷是 新加卷
卷的序列号是 38A2-829E
D:\python的pycharm\正式课\day17 的目录
2019/11/19 14:33 <DIR> .
2019/11/19 14:33 <DIR> ..
2019/11/19 14:33 947 subprocess模块.py
2019/11/19 08:09 459 日考.py
2 个文件 1,406 字节
2 个目录 132,886,355,968 可用字节
正确的结果
请输入终端命令:yafeng
'yafeng' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
'''

- re模块
'''
夺命三问:
1、什么是正则表达式与re模块?
-正则表达式:
-正则表达式是一门独立的技术,任何;语言都可以使用正则表达式
-正则表达式是由一堆特殊的字符组合而来
-re模块
在python中,若想要使用正则表达式,必须通过re模块使用
2、为什么要使用正则?
-比如要获取'一堆字符串'中的'某些字符',正则表达式可以帮我们过滤,
-并提取想要的字符串数据,比如从'afahafkfyafeng666'中获取'yafeng666'
-应用场景:
-爬虫:re,bs4,xpath,selector
-数据分析过滤数据:re,pandas,numpy
-用户名与密码手机认证:检测输入内容的合法性
3、如何使用?
-import re
- 字符组:
- [0-9] 可以匹配到一个0-9的字符
- [9-0]: 报错, 必须从小到大
- [a-z]: 从小写的a-z
- [A-Z]: 从大写A-Z
- [z-A]: 错误, 只能从小到大,根据ascii表来匹配大小。
- [A-z]: 总大写的A到小写的z。
注意: 顺序必须要按照ASCII码数值的顺序编写。
'''
'''
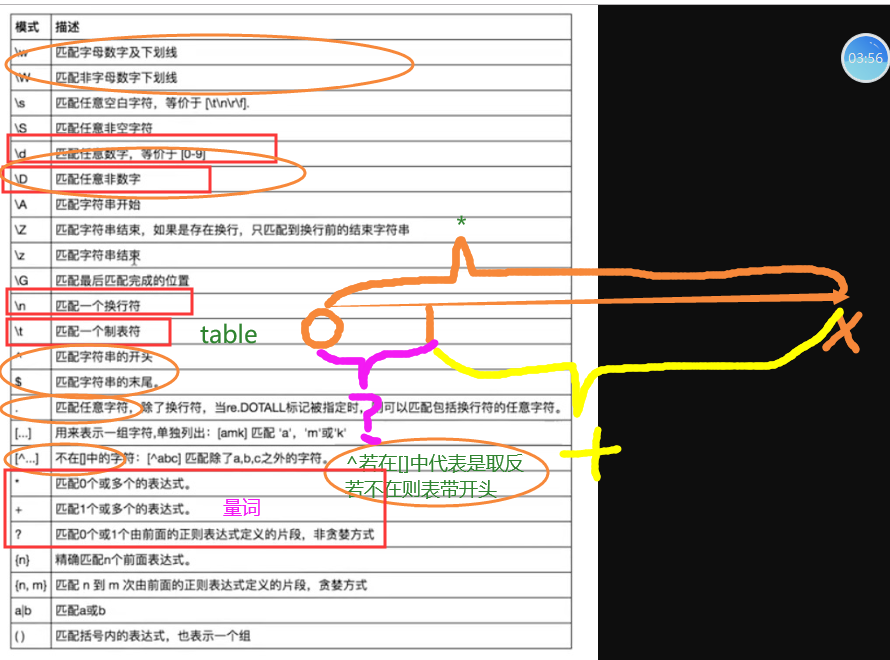
- 元字符:
*******根据博客的表格来记 (看一眼)
https://images2015.cnblogs.com/blog/1036857/201705/1036857-20170529203214461-666088398.png
- 组合使用
- \w\W: 匹配字母数字下划线与非字母数字下划线,匹配所有。
- \d\D: 无论是数字或者非数字都可以匹配。
- \t: table
- \n: 换行
- \b: 匹配单词结尾,tank jasonk
- ^: startswith
- '^'在外面使用: 表示开头。
- [^]: 表示取反的意思。
- $: endswith
- ^$: 配合使用叫做精准匹配,如何限制一个字符串的长度或者内容。
- |: 或。ab|abc如果第一个条件成立,则abc不会执行,怎么解决,针对这种情况把长的写在前面就好了,一定要将长的放在前面。
- [^...]: 表示取反的意思。
- [^ab]: 代表只去ab以外的字符。
- [^a-z]: 取a-z以外的字符。
'''
'''
re模块三种比较重要的方法:
- findall(): ----> []
可以匹配 "所有字符" ,拿到返回的结果,返回的结果是一个列表。
'awfwaghowiahioawhio' # a
['a', 'a', 'a', 'a']
- search():----> obj ----> obj.group()
'awfwaghowiahioawhio' # a
在匹配一个字符成功后,拿到结果后结束,不往后匹配。
'a'
- match():----> obj ----> obj.group()
'awfwaghowiahioawhio' # a
'a'
'wfwaghowiahioawhio' # a
None
从匹配字符的开头匹配,若开头不是想要的内容,则返回None。
'''

#re校验手机号码的合法性
# 需求: 11位、开头13/15/17开头
# import re
# while True:
# phone_number = input('请输入您的号码:').strip()
# # 需求: 11位、开头13/15/19
# # # 参数1: 正则表达式 ''
# # # 参数2: 需要过滤的字符串
# # # ^: 代表“开头”
# # # $: 代表“结束”
# # # |: 代表“或”
# # # (13|14): 可以获取一个值,判断是否是13或14.
# # # {9}: 需要获取9个值 限制数量
# # # []: 分组限制取值范围
# # # [0-9]: 限制只能获取0——9的某一个字符。
# if re.match('^(13)|(15)|(19)[0-9]{9}$', phone_number):
# print('该号码合法')
# break
# else:
# print('该号码不合法')
#>>>请输入您的号码:13012345678
#>>>该号码合法
#请输入您的号码:161234456789
#>>>该号码不合法
#match的用法
import re
str1 = 'abcdefgyafeng666'
res = re.match('[A-z0-9]', str1)
print(res)
#>>><re.Match object; span=(0, 1), match='a'>
print(res.group()) #只能获取一个值
#>>>a
#findall的用法
res = re.findall('[a-z0-9]{7}', str1)
print(res) #可以获取多个值
#>>>['abcdefg', 'yafeng6']
#search的用法
res = re.search('[a-y6-7]', str1)
print(res.group()) #只能获取一个值
#>>>a
- 利用re模块爬取豆瓣电影
'''
爬取豆瓣TOP250电影信息
第1页:
https://movie.douban.com/top250?start=0&filter=
...
第9页:
https://movie.douban.com/top250?start=200&filter=
第10页:
https://movie.douban.com/top250?start=225&filter=
爬蟲四部原理:
1.发送请求: requests
2.获取响应数据: 对方机器直接返回的
3.解析并提取想要的数据: re
4.保存提取后的数据: with open()
爬蟲三部曲:
1.发送请求
2.解析数据
3.保存数据
# 往10个链接发送请求获取响应数据
- requests模块 ---》 请求库
'''
import requests
import re
# 爬虫三部曲
# 1、发送请求
def get_page(url):
response = requests.get(url)
# response.content#获取二进制数据流,比如图片,视频
# response.text#获取响应文本,比如HTML代码
return response
# 伪代码:
# response = get_page('url地址')
# parser_page(response.text)
# 2、解析数据
def parse_page(text):
# re.findall('正则表达式', '过滤的文本')
'''
'<div class="item">.*?<a href="(.*?)">.*?<span class="title">(.*?)</span>.*?<span class="rating_num".*?>(.*?)</span>.*?<span>(.*?)人评价'
:param text:
:return:
'''
res_list = re.findall(
'<div class="item">.*?<a href="(.*?)">.*?<span class="title">(.*?)</span>.*?<span class="rating_num".*?>(.*?)</span>.*?<span>(.*?)人评价'
, text, re.S) ## response.text
for movie_tuple in res_list:
yield movie_tuple
# 3、保存数据
# 伪代码:
# res_list = parser_page(text)
# save_data(res_list)
def save_data(res_list_iter):
with open('douban.txt', 'a', encoding='utf-8')as f:
for movie_tuple in res_list_iter:
movie_url, movie_name, movie_point, movie_num = movie_tuple
# 写入文件
str1 = f'''
电影地址:{movie_url}
电影名字:{movie_name}
电影评分:{movie_point}
评价人数:{movie_num}'''
f.write(str1)
# 获取10个连接
n = 0
for line in range(10):
url = f'https://movie.douban.com/top250?start={n}&filter='
n += 25
print(url)
response = get_page(url)
res_list_iter = parse_page(response.text)
# print(res_list)
save_data(res_list_iter)
- logging
# logging的配置信息
"""
logging配置
"""
import os
import logging.config
# 定义三种日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s'
# 定义日志输出格式 结束
# ****************注意1: log文件的目录
BASE_PATH = os.path.dirname(os.path.dirname(__file__))
logfile_dir = os.path.join(BASE_PATH, 'log_dir')
# print(logfile_dir)
# ****************注意2: log文件名
logfile_name = 'user.log'
# 如果不存在定义的日志目录就创建一个
if not os.path.isdir(logfile_dir):
os.mkdir(logfile_dir)
# log文件的全路径
logfile_path = os.path.join(logfile_dir, logfile_name)
# ****************注意3: log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {},
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
},
},
}
# 注意4:
def get_logger(user_type):
# 1.加载log配置字典到logging模块的配置中
logging.config.dictConfig(LOGGING_DIC)
# 2.获取日志对象
# logger = logging.getLogger('user')
# logger = logging.getLogger('bank')
# logger = logging.getLogger('shop')
logger = logging.getLogger(user_type)
return logger
# logging.config.dictConfig(LOGGING_DIC)
# # 调用获取日志函数的到日志对象
# logger = logging.getLogger('user')
# 通过logger日志对象,调用内部的日志打印
logger = get_logger('user')
# '只要思想不滑坡,方法总比问题多!'就是需要记录的日志信息
logger.info('学习不要浮躁,一步一个脚印!')
logger.info('只要思想不滑坡,方法总比问题多!')
- 防止导入包是被自动执行
def func():
print('from test1.func...')
# func()
# __name__属于模块名称空间中的一个名字
# 当我们执行该模块时就会产生
print(__name__) # 在当前文件中名字为:__main__ 被导入时: 模块的名字
# 注意: 记住--》 main + 回车键
if __name__ == '__main__':
print('在当前模块下执行功能')
func()
else:
print('当前模块已被导入')
- 包的理论
5.包的理论
- 夺命三问:
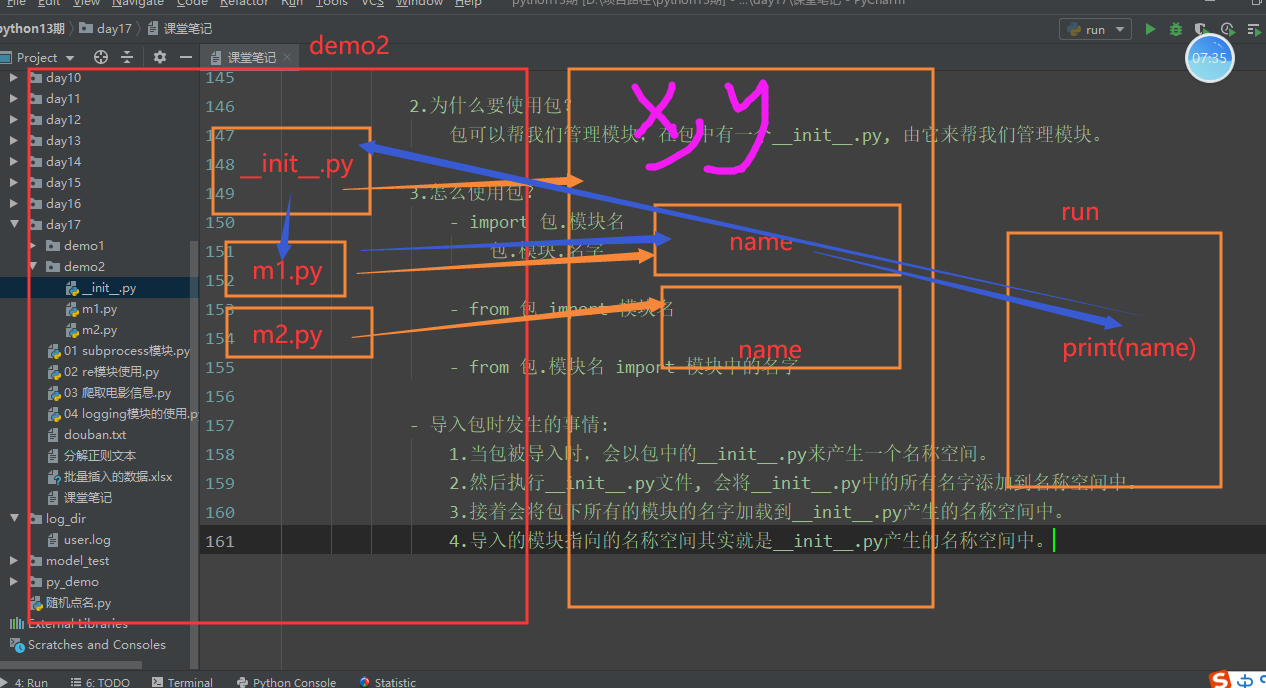
1.什么是包?
包是一个带有__init__.py的文件夹,包也可以被导入,
并且可以一并导入包下的所有模块。
2.为什么要使用包?
包可以帮我们管理模块,在包中有一个__init__.py, 由它来帮我们管理模块。
3.怎么使用包?
- import 包.模块名
包.模块.名字
- from 包 import 模块名
- from 包.模块名 import 模块中的名字
- 导入包时发生的事情:
1.当包被导入时,会以包中的__init__.py来产生一个名称空间。
2.然后执行__init__.py文件, 会将__init__.py中的所有名字添加到名称空间中。
3.接着会将包下所有的模块的名字加载到__init__.py产生的名称空间中。
4.导入的模块指向的名称空间其实就是__init__.py产生的名称空间中。
Only you can control your future
You're not alone. You still have family,peopel who care for you and want to save you.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号