内置函数补充,函数递归,模块
内置函数的补充,递归,以及模块
一、内置函数的补充
'''
map: 映射
map(函数地址, 可迭代对象) ---> map对象
map会将可迭代对象中的每一个值进行修改,然后映射一个map对象中,
可以再将map对象转换成列表/元组。(以第一次要转的类型为主)
注意: 只能转一次。
reduce: 合并
reduce(函数地址, 可迭代对象, 初始值默认为0)
reduce(函数地址, 可迭代对象, 初始值)
filter: 过滤
filter(函数地址, 可迭代对象) --> filter 对象
'''
1、map
用法:map(函数地址,可迭代对象)--->map对象(本质是一个生成器即迭代器)
通过print(list(map对象))显示或for循环显示内容,但注意的是这个map对象只能够使用一次,即谁 先用就显示出来,第二次就没这个对象了,只能够得到一个空的值比如()或[]
a、通过list(map对象显示)
name_list = ['sean', 'egon', 'jason', 'tank', 'yafeng']
map_obj = map(lambda name: name + '666' if name == 'yafeng' else name + '_大宝剑', name_list)#得到一个map对象
print(map_obj)
>>> <map object at 0x000002855AC051C8>
print(list(map_obj))#map_obj ---> 生成器(迭代器) ----> 返回的是一个map对象
#通过list(map_obj)显示,,注意不是列表不能直接输出,可以通过for循环或者list()来显示。
>>>['sean_大宝剑', 'egon_大宝剑', 'jason_大宝剑', 'tank_大宝剑', 'yafeng666']
b通过for循环显示
name_list = ['sean', 'egon', 'jason', 'tank', 'yafeng']
map_obj = map(lambda name: name + '666' if name == 'yafeng' else name + '_大宝剑', name_list)#得到一个map对象
print(map_obj)
>>><map object at 0x000002855AC051C8>
#也可以通过for循环来取出内容
ls = []
for i in map_obj:
ls.append(i)
print(ls)
>>>['sean_大宝剑', 'egon_大宝剑', 'jason_大宝剑', 'tank_大宝剑', 'yafeng666']
#值得注意的是该map_obj只能使用一次,用完就没了,谁先用谁先得,所以如果同时使用后面打印的结果是一个空列表
2、reduce
用法:reduce(函数地址,可迭代对象,起始值)#起始值默认为0 --->reduce对象
#需求:求1--100的和
#普通方法
sum = 0
for i in range(1, 101):
sum += i
print(sum)
>>>5050
# reduce方法(需要先导入这个模块才可以使用)
from functools import reduce
res = reduce(lambda x, y: x + y, range(1, 101), 0)
print(res)
>>>5050
#也可以改变起始值
from functools import reduce
res = reduce(lambda x, y: x + y , range(1, 101), 1000)
print(res)
>>>6050
3、filter(过滤)
用法:filter(函数地址,可迭代对象) ---->filter对象
name_list = ['egon_大宝剑', 'jason_大宝剑',
'sean_大宝剑', 'tank_大宝剑', 'yafeng']
# 需求将后缀为_大宝剑的名字 “过滤出来”(我要拿到的,不是舍去)
filter_obj = filter(lambda name: name.endswith('_大宝剑'), name_list)
print(filter_obj)#得到一个filter对象<filter object at 0x0000026E2FD02208>
print(list(filter_obj))#通过列表显示
>>>['egon_大宝剑', 'jason_大宝剑', 'sean_大宝剑', 'tank_大宝剑']
二、函数递归
'''
函数递归:
函数递归指的是重复 “直接调用或间接调用” 函数本身,
这是一种函数嵌套调用的表现形式。
直接调用: 指的是在函数内置,直接调用函数本身。
间接调用: 两个函数之间相互调用间接造成递归。
了解:
面试可能会问:
python中有递归默认深度: 限制递归次数
998, 1000
PS: 但是在每一台操作系统中都会根据硬盘来设置默认递归深度。
获取递归深度: 了解
sys.getrecursionlimit()
设置递归深度: 了解
sys.setrecursionlimit(深度值)
注意: 单纯的递归调用时没有任何意义的。
'''
- 直接调用
直接调用: 指的是在函数内置,直接调用函数本身。
def func():
print('from func')
func()
func()
- 间接调用
间接调用: 两个函数之间相互调用间接造成递归。
def foo1():
print('from foo1')
foo2()
foo1()
def foo2():
print('from foo2')
foo1()
foo2()
- 递归深度
python中有默认的递归深度1000(实际上只能到998)
但其实在每一台操作系统中都会根据硬盘来设置默认递归深度
#获取操作系统资源的模块
import sys
print(sys.getrecursionlimit())#获取递归深度
#设置递归深度
sys.setrecursionlimit(2000)#后面加你想要设置的递归深度
#获取你当前的递归深度
num = 1
def func():
global num
print('from func', num)
num += 1
func()
func()
'''
想要递归有意义,必须遵循两个条件:
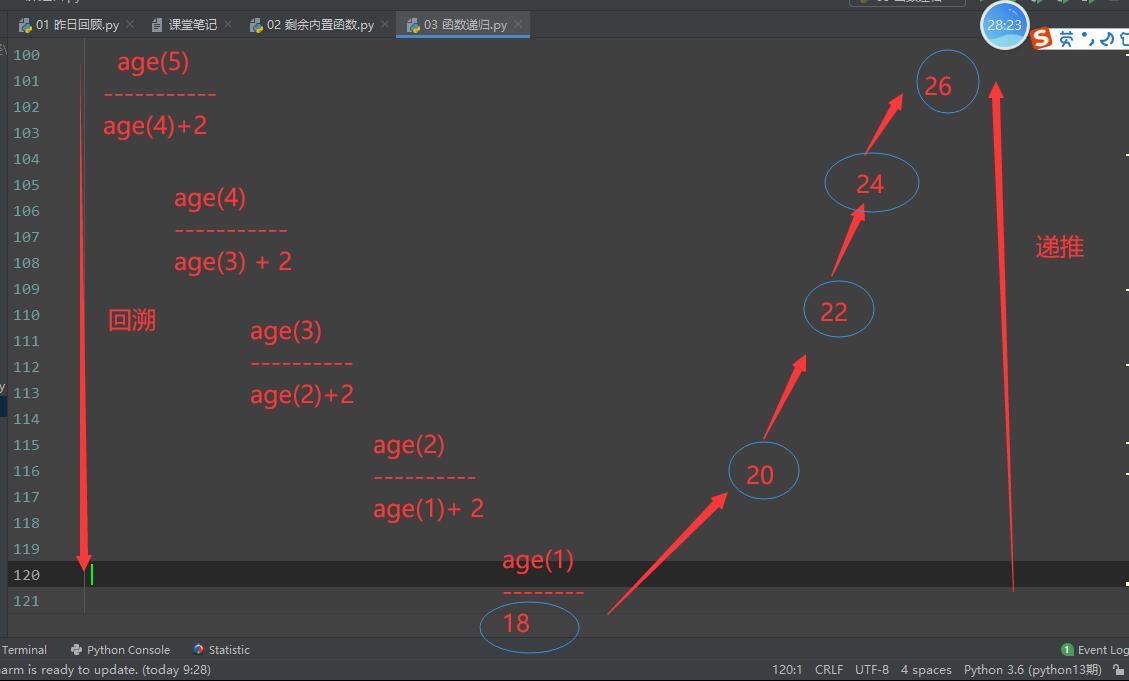
- 回溯:(*****) 是向下的过程
指的是重复地执行, 每一次执行都要拿到一个更接近于结果的结果,
回溯必要有一个终止条件。
- 递推:(*****) 是向上的过程
当回溯找到一个终止条件后,开始一步一步往上递推。
age5 == age4 + 2
age4 == age3 + 2
age3 == age2 + 2
age2 == age1 + 2
age1 == 18 # 回溯终止的结果
# age(n) == age(n - 1) + 2(n>1)
'''
def age(n):
if n == 1:
return 18
#这里后面要写return才能实现递归
return age(n - 1) + 2
res = age(5)
print(res)
>>>26
三、模块
- 什么是包?
包指的是内部包含__init__.py的文件。
- 包的作用
存放模块,包可以更好的管理模块
- 什么是模块?
模块是一系列功能的结合体
模块的本质是一个个的.py文件
- 模块的三种来源
1、python内置的模块
如:sys\time\os\turtle
2、第三方的模块:
如:requests
3、自定义的模块:
如:自己定义的demo.py
- 模块的四种表现形式
1、使用python编写的py文件
2、编译后的共享库比如c或者是c++库
3、包下面带有__init__.py的一组py文件
4、python解释器下的py文件
- 为什么要使用模块
模块可以帮我们更好的管理功能代码,比如:函数
可以将项目拆分成一个个的功能,分别存放于不同的py文件
- 如何创建
鼠标右键创建py文件
-在py文件编写python代码
-在一个文件中,通过import关键字导入模块
-import 模块名
# 注意: import 模块时,模块不能加.py后缀
在使用模块阶段,需注意,谁是执行文件,谁是被导入文件(模块)
模块在首次导入时,就已经固定好了,当前文件查找的顺序是先从内存中查到的
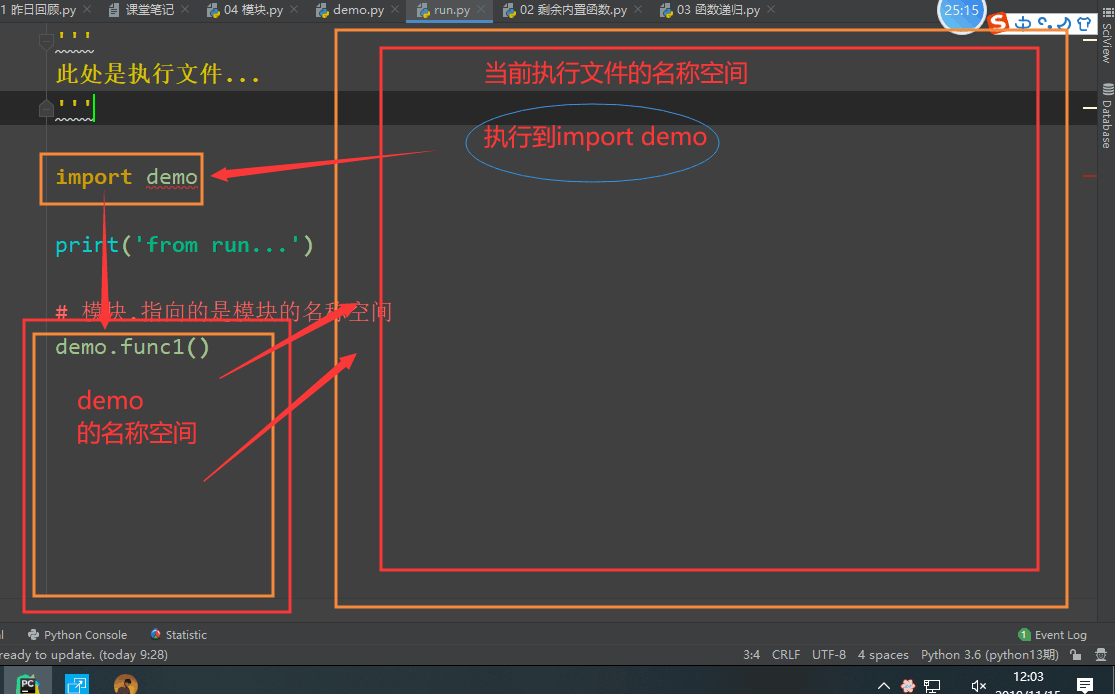
- 模块导入过程
1、会先执行当前执行文件,并产生执行文件中的名称空间
2、当执行到导入模块的代码时,被导入的模块会产生一个模块的名称空间
3、会将被导入模块的名称空间加载到内存中
- 给模块取别名
as
import 模块 as 模块的别名
- 模块导入的方式
-import 模块
-from 包\模块 import 模块\(函数名,变量名,类名)
- 项目的文件夹
- conf:
- 用于存放配置文件的文件夹
- core:
- 核心业务代码 .py
- interface:
- 接口, 接口内写获取数据前的逻辑代码,通过后才能获取数据
- db:
- 用于存放文件数据
- lib:
- 存放公共功能文件
- log:
- 用于存放日志文件,日志用于记录用户的操作记录
- bin:
- 里面存放启动文件 / - 启动文件
- readme.txt:
- 项目说明书, 用户告诉使用者项目的操作
Only you can control your future
You're not alone. You still have family,peopel who care for you and want to save you.
