Java 语言特性【四】——其他
引言
前面按照重要级别说了一下,看下导图中其余部分:
动态代理与反射
动态代理与反射是 Java 语言的特色,需要掌握动态代理与反射的使用场景,例如在 ORM 框架中会大量使用代理类。而 RPC 调用时会使用到反射机制调用实现类方法。
反射(一)之初探反射
反射(二)之反射机制
反射(三)之通过反射获取构造方法, 成员变量, 成员方法
反射(四)之反射在开发中的适用场景及利弊
反射(五)之动态代理的作用
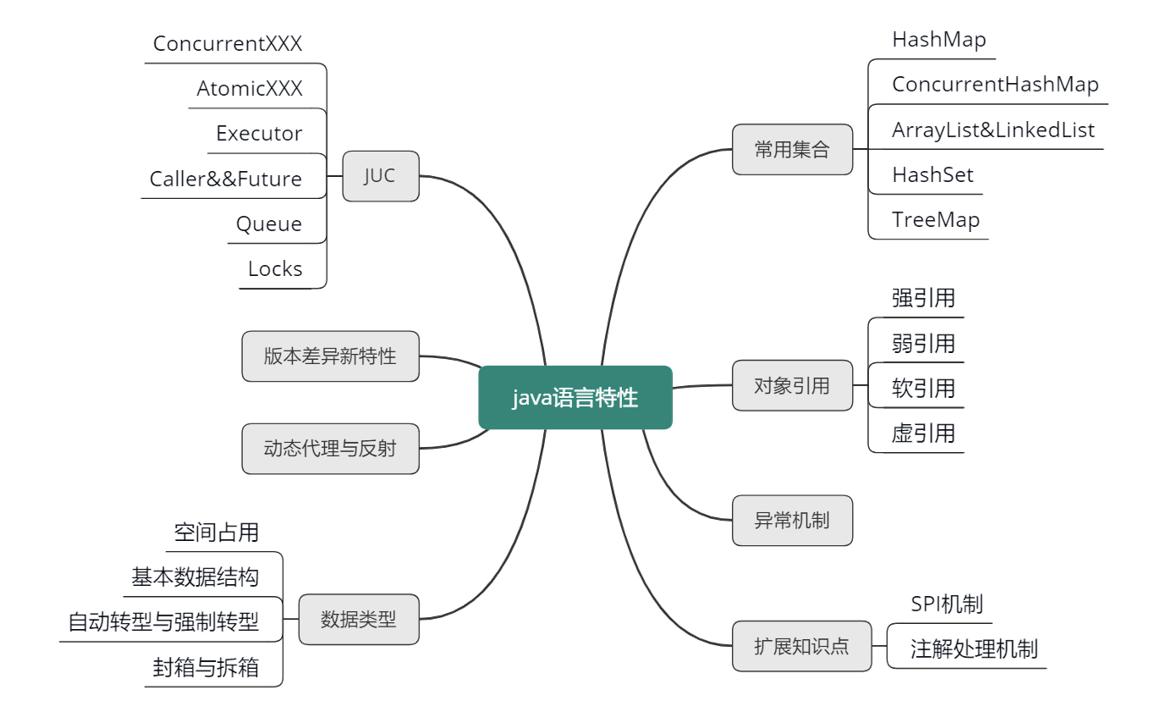
数据类型
Java 基础数据类型也常常会在面试中被问到,例如各种数据类型占用多大的内存空间、数据类型的自动转型与强制转型、基础数据类型与 wrapper 数据类型的自动装箱与拆箱等。
基本数据类型
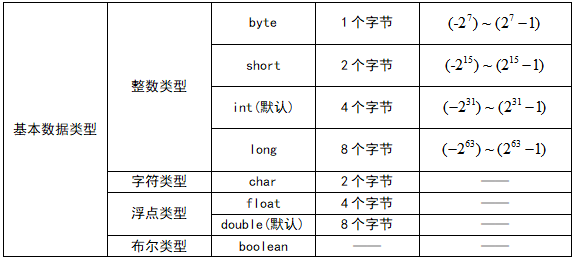
基本类型的类型转换
表述范围小的数值或变量直接赋给表数范围大的变量时,系统会进行自动类型转换,否则需要强制转换。
1、自动类型转换
示例:
package com.xgcd.basic; public class AutoConversion { public static void main(String[] args) { int a = 6; float f = a; System.out.println(f);// 6.0 byte b = 9; // char c = b;// 报错,byte类型不能自动转换为char类型 double d = b; System.out.println(d);// 9.0 } }
2、强制类型转换
强制类型转换可能会引起数据丢失。
基本类型对应包装类及自动装箱、拆箱
boolean 对应 Boolean、byte 对应 Byte、short 对应 Short、int 对应 Integer、long 对应 Long、char 对应 Character、float 对应 Float、double 对应 Double,除了 int 和 char 外,都是将首字母大写……
除此之外,8个包装类都提供了一个 parseXxx(String str) 静态方法用于将字符串转换成基本类型。基本类型变量和包装类对象之间的转换其实没这么繁琐,从 jdk1.5 后就变得简单了,jdk1.5提供了自动装箱 (Autoboxing) 和自动拆箱 (AutoUnboxing) 功能。
所谓自动装箱就是可以把一个基本类型变量直接赋给对应的包装类变量或者赋给 Object 变量。
自动拆箱与之相反,允许直接把包装对象直接赋给一个对应的基本类型变量。注意都是对应的,万不能驴唇不对马嘴,如:Integer 试图拆箱成 boolean 类型变量就不能行。
示例:
package com.xgcd.basic; public class AutoConversion { public static void main(String[] args) { // 基本类型变量直接赋给包装类对象 Integer inObj = 5; // 基本类型变量直接赋给Object对象 Object boolObj = true; // 直接把一个Integer对象赋给int类型的变量 int it = inObj; if (boolObj instanceof Boolean) { // 先把Object对象强转为Boolean类型,再赋给boolean变量 boolean b = (Boolean) boolObj; System.out.println(b);// true } } }
总之就是对应类型的相互赋值就可以了。但有一点需要注意,包装类的比较。
虽然包装类型的变量是引用数据类型,但包装类的实例可以与数值类型的值进行比较,这种比较时直接取出包装类实例所包装的数值来进行比较的。如:
Integer a = new Integer(6); System.out.println(a > 5.0);// true
两个包装类的实例比较的情况比较复杂,因为包装类的实例实际上是引用类型,只有两个包装类引用指向同一个对象时,才会返回true。如:
System.out.println(new Integer(2) == new Integer(2));// false
但自jdk1.5后,出现了自动装箱,这种情况可能会出现些特殊情况。如:
Integer ina = 2; Integer inb = 2; System.out.println(ina == inb);// true Integer biga = 128; Integer bigb = 128; System.out.println(biga == bigb);// false
同样是两个int类型的数值自动装箱成Integer实例后,两个2自动装箱后就相等,两个128自动装箱后不相等是为什么呢?这与java的Integer类的设计有关,查看java.lang.Integer类的源代码:
private static class IntegerCache { static final int low = -128; static final int high; static final Integer cache[]; static { // high value may be configured by property int h = 127; String integerCacheHighPropValue = sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high"); if (integerCacheHighPropValue != null) { try { int i = parseInt(integerCacheHighPropValue); i = Math.max(i, 127); // Maximum array size is Integer.MAX_VALUE h = Math.min(i, Integer.MAX_VALUE - (-low) -1); } catch( NumberFormatException nfe) { // If the property cannot be parsed into an int, ignore it. } } high = h; cache = new Integer[(high - low) + 1]; int j = low; for(int k = 0; k < cache.length; k++) cache[k] = new Integer(j++); // range [-128, 127] must be interned (JLS7 5.1.7) assert IntegerCache.high >= 127; } private IntegerCache() {} }
系统把一个-128~127之间的整数自动装箱成Integer实例,并放入了一个名为cache的数组中缓存起来。如果以后把一个-128~127之间的整数自动装箱成一个Integer实例时,实际上是直接指向对应的数组元素,因此-128~127之间的同一个整数自动装箱成Integer实例时,永远都是引用cache数组的同一个数组元素,所以他们全部相等。但每次把一个不在-128~127范围内的整数自动装箱成Integer实例时,系统总是重新创建一个Integer实例,所以出现程序运行结果false。通过缓存从而提高程序的运行性能。
此外,包装类还可以实现基本类型变量和字符串之间的转换。
字符串和基本类型的值转换
字符串类型的值转换为基本类型的值有两种方式。
- 利用包装类提供的 parseXxx(String str) 静态方法。
- 利用包装类提供的 Xxx(String str) 构造器。
String 类提供了多个重载 valueOf() 方法,用于将基本类型变量转换成字符串。代码就略了。
补充
1.为什么存在这两种类型呢?
在Java语言中,new一个对象存储在堆里,通过栈中的引用来使用这些对象;但是对于经常用到的一系列类型如int,如果用new将其存储在堆里就不是很有效——特别是简单的小的变量。所以就出现了基本类型,同C++一样,Java采用了相似的做法,对于这些类型不是用new关键字来创建,而是直接将变量的值存储在栈中,因此更加高效。
2.有了基本类型为什么还要有包装类型呢?
我们知道Java是一个面相对象的编程语言,基本类型并不具有对象的性质,为了让基本类型也具有对象的特征,就出现了包装类型(如我们在使用集合类型Collection时就一定要使用包装类型而非基本类型),它相当于将基本类型“包装起来”,使得它具有了对象的性质,并且为其添加了属性和方法,丰富了基本类型的操作。
另外,当需要往ArrayList,HashMap中放东西时,像int,double这种基本类型是放不进去的,因为容器都是装object的,这是就需要这些基本类型的包装器类了(事实上由于自动装箱,list中add元素是可以的,但是remove元素就不同了,因为删除元素时不会自动装箱)。
// 为什么需要包装类 ArrayList<Object> list = new ArrayList<>(); int number1 = 11; boolean add = list.add(number1); System.out.println("add:" + add); Object remove = list.remove(number1);// remove不会自动装箱,而是把number1当作索引了; 正确做法是remove(Integer.valueOf(number1)),再次执行remove即为true System.out.println(remove); 输出结果: add:true Exception in thread "main" java.lang.IndexOutOfBoundsException: Index: 11, Size: 1 at java.util.ArrayList.rangeCheck(ArrayList.java:657) at java.util.ArrayList.remove(ArrayList.java:496) at com.xgcd.basic.AutoConversion.main(AutoConversion.java:36)
3.二者相互转换:
1、int转Integer
1. int i = 0;
2. Integer ii = new Integer(i);
2、Integer转int
1. Integer ii = new Integer(0);
2. int i = ii.intValue();
4.二者的区别:
1. 声明方式不同:
基本类型不使用new关键字,而包装类型需要使用new关键字来在堆中分配存储空间;
2. 存储方式及位置不同:
基本类型是直接将变量值存储在栈中,而包装类型是将对象放在堆中,然后通过引用来使用;
3. 初始值不同:
基本类型的初始值如int为0,boolean为false,而包装类型的初始值为null;
4. 使用方式不同:
基本类型直接赋值直接使用就好,而包装类型在集合如Collection、Map时会使用到。
对象引用
Java 对对象的引用分为强引用、软引用、弱引用、虚引用四种,这些引用在 GC 时的处理策略不同,强引用不会被 GC 回收;软引用内存空间不足时会被 GC 回收;弱引用则在每次 GC 时被回收;虚引用必须和引用队列联合使用,主要用于跟踪一个对象被垃圾回收的过程。
异常机制
Java 的异常处理机制就是 try-catch-finally 机制,需要知道异常时在 try catch 中的处理流程;需要了解 Error 和 Exception 的区别。
除非在 try 块、catch 块中调用了退出虚拟机的方法,否则不管在 try、catch 中执行怎样的代码,出现怎样的情况,异常处理的 finally 块总会被执行。可使用 exit 退出虚拟机:
System.exit(1);
Java 异常分为两大类:Checked 异常和 Runtime 异常(运行时异常)。对于 Checked 异常处理方式有两种:try catch 或 throw。也可以自行抛出异常:
if (false) { throw new RuntimeException("宁试图抢劫银行,已被便衣枪毙"); }
这里 throw Exception 和 throw RuntimeException 效果一样,自行抛出 Runtime 异常比自行抛出 Checked 异常的灵活性更好。同样抛出 Checked 异常则可以让编译器提醒程序员必须处理该异常(该抛出抛出,该捕获捕获)。
自定义异常
自定义异常都应该继承 Exception 基类,如果希望自定义 Runtime 异常,则应该继承 RuntimeException 基类。第一异常类时通常需要提供两个构造器:一个是无参构造器,另一个是带一个字符串参数的构造器,这个字符串将作为该异常对象的描述信息(也就是异常对象的 getMessage() 方法的返回值)。
示例:
/** * 自定义异常类 */ public class MyException extends Exception { //异常信息 private String message; //构造函数 public MyException(String message){ super(message); this.message = message; } //获取异常信息,由于构造函数调用了super(message),不用重写此方法 //public String getMessage(){ // return message; //} }
在需要抛异常的地方 throw new MyException("自定义异常提示信息xxx"); 测试异常:
/** * 测试异常 */ public class TestException { @org.junit.Test public void test(){ UseMyException ex = new UseMyException("admin","123"); try{ ex.throwException("1234"); }catch (MyException me){ System.out.println("MyException:"+me.getMessage()); } } }
异常链
对于正式的企业及应用而言,原始异常是不可能直接抛给用户的,一来他们不需要看原始异常信息,二来也不符合代码安全规范。通常我们会把原始异常信息隐藏起来,仅向上提供必要的异常提示信息,这样既可以保证底层异常不会扩散到表现层,又可以避免向上暴露太多的实现细节,完全符合面向对象的封装原则。
这种把捕获一个异常然后接着抛出另一个异常,并把原始异常信息保存下来是一种典型的链式处理(责任链模式),也被称为“异常链”。如:
try { // 实现结算工资的业务逻辑 ... } catch (SQLException sqle) { // 把原始异常记录下来,留给管理员 ... // 下面异常中的message就是对用户的提示 throw new SalException("访问底层数据库出现异常"); } catch (Exception e) { // 把原始异常记录下来,留给管理员 ... // 下面异常中的message就是对用户的提示 throw new SalException("系统出现未知异常"); }
这种 catch 和 throw 结合使用的情况在企业级应用中非常有用。
与上面不同的是,下面加粗的代码创建 SalException 对象时,传入了一个 Exception 对象,而不是传入一个String 对象,这就需要 SalException 类有相应的构造器。自JDK1.4后,Throwable 基类就已经有了一个可以接收 Exception 参数的方法,就是下面定义的 SalException 类。
创建这个 SalException 业务异常类后,就可以用他来封装原始异常,从而实现对异常的链式处理。
public calSal() throws SalException { try { // 实现结算工资的业务逻辑 ... } catch (SQLException sqle) { // 把原始异常记录下来,留给管理员 ... // 下面异常中的message就是对用户的提示 throw new SalException(sqle); } catch (Exception e) { // 把原始异常记录下来,留给管理员 ... // 下面异常中的message就是对用户的提示 throw new SalException(e); } } public class SalException extends Exception{ public SQLException(){} public SalException(String msg){ super(msg); } // 创建一个可以接收throwable 参数的构造器 public SalException(Throwable t){ super(t); } }
Error 和 Exception 的区别
1、从概念角度分析:
Error:程序无法处理的系统错误,编译器不做检查;
Exception:程序可以处理的异常,捕获后可能恢复;
总结:前者是程序无法处理的错误,后者是可以处理的异常。
2、从责任角度分析:
Error:属于JVM需要负担的责任;
Exception:
RuntimeException(非受检异常)是程序应该负担的责任;
Checked Exception (受检异常)可检查异常时Java编译器应该负担的责任。
3、常见Error和Exception
RuntimeException:
1、NullPropagation:空指针异常;
2、ClassCastException:类型强制转换异常
3、IllegalArgumentException:传递非法参数异常
4、IndexOutOfBoundsException:下标越界异常
5、NumberFormatException:数字格式异常
非RuntimeException:
1、ClassNotFoundException:找不到指定class的异常
2、IOException:IO操作异常
Error:
1、NoClassDefFoundError:找不到class定义的异常
2、StackOverflowError:深递归导致栈被耗尽而抛出的异常
3、OutOfMemoryError:内存溢出异常
此外,还需要注意几点
不要过度使用异常
- 把异常额普通错误混淆在一起,不再编写任何错误处理代码,而是以简单地抛出异常来代替所有的错误处理。
- 使用异常处理来代替流程控制。
- 其实就是要让程序变得更加健壮。
不要使用过于庞大的try块
当 try 块过于庞大时,业务过于复杂,会造成出现异常的可能性大大增加,从而导致分析异常原因的难度也大大增加,而且难免在 try 块后紧跟大量的 catch 块才可以针对不同的异常提供不同的处理逻辑。同一个 try 块后紧跟大量的 catch 块则需要分析他们之间的逻辑关系,反而增加了编程复杂度。
正确的做法是,把大块的 try 块分割成多个可能出现异常的程序段落,并把他们放在单独的try 块中,从而分别捕获并处理异常。
不要忽略捕获到的异常
catch 块整个为空或者仅仅打印出错信息都是不妥的。建议:
- 处理异常
- 重新抛出异常
- 在合适的层处理异常
扩展知识点
最后 Java 的注解机制和 SPI 扩展机制可以作为扩展点适当了解。
可参考:
注解机制及其原理
深入理解SPI机制
作者:习惯沉淀
如果文中有误或对本文有不同的见解,欢迎在评论区留言。
如果觉得文章对你有帮助,请点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
扫码关注一线码农的学习见闻与思考。
回复"大数据","微服务","架构师","面试总结",获取更多学习资源!
