


MySql重新学习笔记
本地环境:centos7.6+mysql8.0版本,navicat for mysql客户端
centOs7.6安装 mysql-8.0.27博客参考;navicat客户端破解提供博客参考【十分感谢博主】;
https://www.cnblogs.com/kimit/p/15474718.html
https://www.cnblogs.com/zpy1993-09/p/14929860.html
mysql基础认知:
各版本:
3.26--5.2版本
正宗后代
– Centos5、6中默认有5.1版本
– Centos7中默认是MariaDB
5.4--5.7 ,8.0版本
– 借鉴社区好的贡献,进一步开发的版本
– 主流版本:5.5 5.6 5.7
MySQL Cluster 6.0 版本&更高
– 类似于Oracle RAC,硬件要求高。
– 一般各大网站没有人用
mysql产品线(派生产品)
派生版本有Drizzle、MariaDB、Percona Server及OurDelta等。
=============================================================
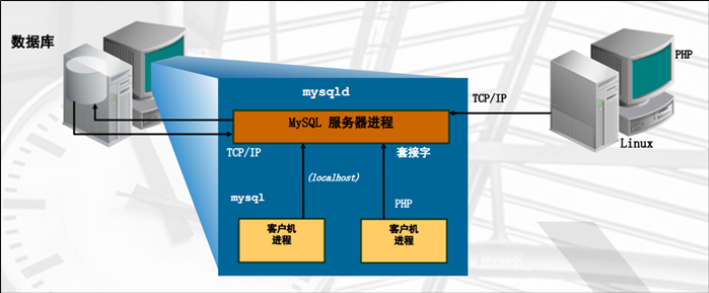
mysql服务结构
c/s模式,服务端与客户端两部分组成
服务端程序 mysqld
客户端程序 mysql自带客户端(mysql、mysqladmin、mysqldump等)
第三方客户端 API接口(php-mysql)
=============================================================
mysql连接方式
TCP/IP 连接 网络连接串(通过用户名 密码 IP 端口进行连接)
mysql -uroot -psbt123456 -h 127.0.0.1 -P 3306
socket 连接 网络套接字(用户名 密码 socket文件)
mysql -uroot -psbt123456 -S /var/lib/mysql/mysql.sock
=============================================================
MySQL在启动过程
启动后台守护进程,并生成工作线程
预分配内存结构供MySQL处理数据使用
实例就是MySQL的后台进程+线程+预分配的内存结构
Mysqld服务的构成
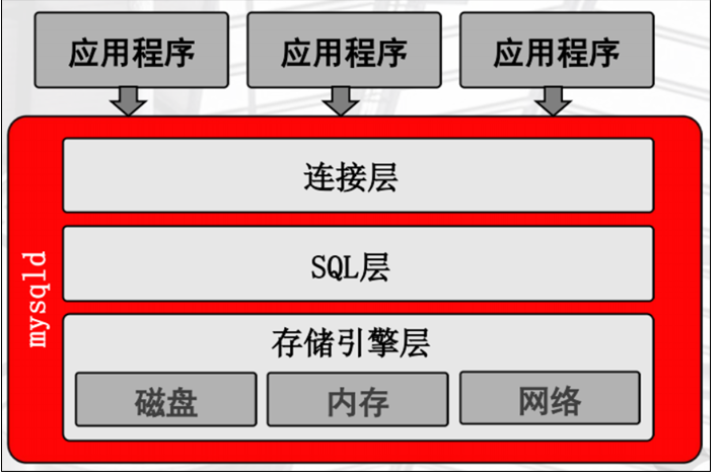
连接层
通讯协议为:tcp/ip 或 socket
连接线程 为连接的数量
用户验证 为通过用户名 密码验证进行通讯协议
sql层
sql即结构化的查询语句(数据库内部逻辑语言)sql92 sql99
DDL 数据库定义语言
DCL 数据库控制语言
DML 数据库操作语言
DQL 数据查询语言
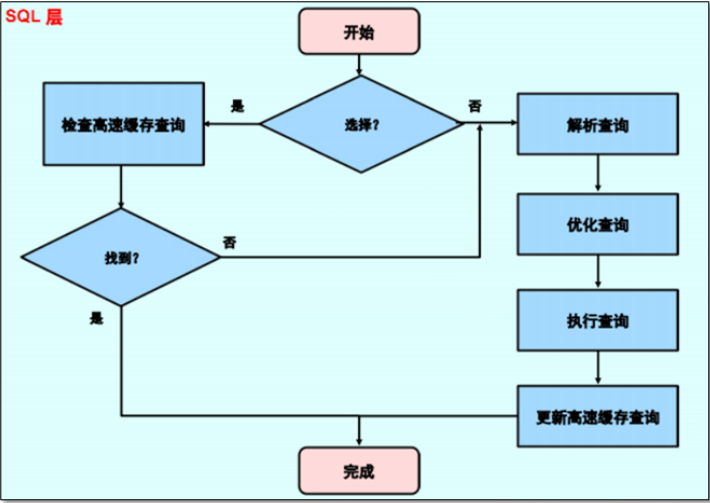
1、判断语法、语句、语义
判断语句类型
2、数据库不能直接响应sql语句
必须明确的知道数据在哪个磁盘
3、数据库对象授权情况判断
授权失败不继续
4、解析(解析器)
将sql语句解析成执行计划,运行执行计划,生成找数据的方式
5、优化 (优化器)
运行执行计划
5.6之后 基于代价的算法,从执行计划中选择代价最小的交给"执行器"
6、"执行器"
运行执行计划
最终生产如何去磁盘找数据方式
7、将取数据的方式,交由下层(存储引擎层)进行处理
8、最终将取出的数据抽象成管理员或用户能看懂的方式(表),展现在用户面前
9、查询缓存: 缓存之前查询的数据。
假如我们查询的表是一个经常有变动的表,查询缓存不要设置太大
=============================
存储引擎层
由上层决定存储方式
存储引擎是充当不同表类型的处理程序的服务器组件。
存储引擎层功能:
存数据、取数据
数据的不同存储方式
不同的管理方式:
事务(增、删、改)
备份恢复
高级功能(高可用的架构、读写分离架构)
依赖于存储引擎的功能
存储引擎是充当不同表类型的处理程序的服务器组件。
存储引擎用于:
存储数据、检索数据、通过索引查找数据
存储介质、 事务功能、 锁定、备份和恢复、优化
特殊功能:
全文搜索、引用完整性、空间数据处理
双层处理,上层包括SQL解析器和优化器、下层包含一组存储引擎
SQL 层不依赖于存储引擎:引擎不影响SQL处理
=================
mysql 的逻辑构成(数据库内部结构)
逻辑构成是为了用户能够读懂数据出现的,让你更好的理解数据。
管理数据的一种方式。
对象:
库中包含表,在linux中以目录表示
表中有列结构与行记录,在linux中以多个文件表示
行记录
列结构
切换库
mysql> use mysql;
查看表
mysql> show tables;
查看列的信息(记录)
mysql> desc user;
======================
mysql的存储方式
程序文件随数据目录一起存储在安装目录下。
执行管理程序和实用程序时将创建可执行文件和日志文件。
使用磁盘空间的是数据目录。
服务器日志文件和状态文件:
包含服务器处理的语句的信息。
日志用于进行故障排除、监视、复制和恢复。
InnoDB 日志文件:(适用于所有数据库)驻留在数据目录级别。
InnoDB 系统表空间:包含数据字典、撤消日志和缓冲区。
每个数据库在数据目录下具有单一目录(无论在数据库中创建何种类型的表)。
数据库目录存储以下内容:
数据文件:
存储引擎的数据文件。包含元数据或索引信息,具体取决使用的存储引擎。
格式文件 (.frm):
包含每个表和/或视图结构的说明,位于数据库目录中。
触发器:
与某个表关联并在该表发生特定事件时激活的命名数据库对象。
数据目录的位置取决于配置、操作系统、安装包和分发。典型位置是 /var/lib/mysql。
MySQL 在磁盘上存储系统数据库 (mysql)。
mysql 包含诸如用户、特权、插件、帮助列表、事件、时区实现和存储例程之类的信息。
========
MySQL体系结构小结
sql 优化理念
解析器 : 执行计划 数据库执行sql的一种方式
优化器 : 知道基本规则,直接影响将来选择哪个执行计划
查询缓存 : 生产环境中,一般会用redis memcached 来代替
逻辑结构
库 就是一个目录,为了存放多张表
表 在相应的库中,用多个文件来表示
myisam表 3个文件:(.myd数据文件 .myi索引文件 frm表 结构定义文件)
innodb: 2个或者一个,共享表空间(ibdata1 基表 元数据)、独立表空间(5.6以后默认的表存储方式)
如何使用磁盘
多个库多个目录,目录下存放了多个表的存储文件
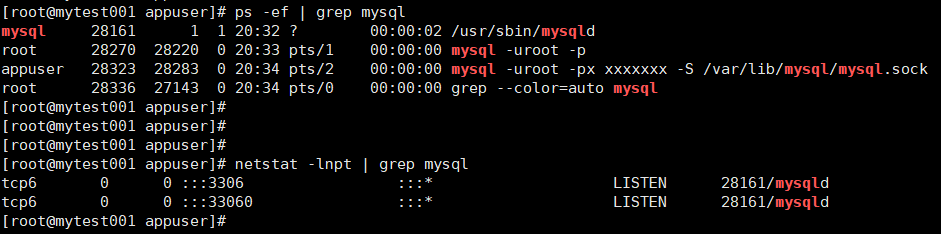
查看进程 查看端口号:可以看到服务端进程mysqld【用户mysql】;两个客户端连接进程【用户root和appuser】;使用端口是3306;
数据库的启动流程
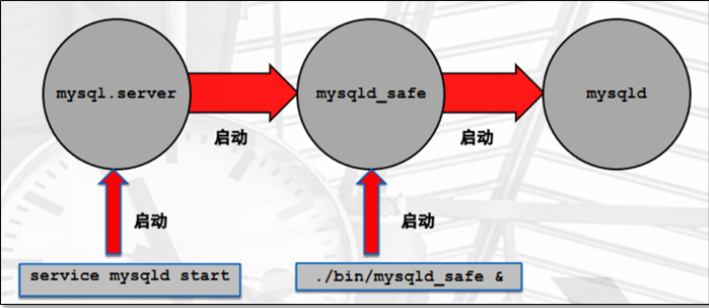
可以看出mysql.server文件与mysqld_safe文件都是脚本文件,最后都调用mysqld二进制文件进行启动。
注意:我当前的环境中没有安装mysqld_safe守护,此处留白,后研究:
my.cnf 配置文件说明
功能 :
1、影响到服务器进程的启动
2、影响到客户端程序
配置my.cnf
使用不同的"标签"去明确指定影响哪部分功能
服务器端
[server]
[mysqld] -----> 一般设置此项
[mysqld_safe]
客户端
[client] ----> 为了方便设置此项
[mysql]
[mysqladmin]
[mysqldump]
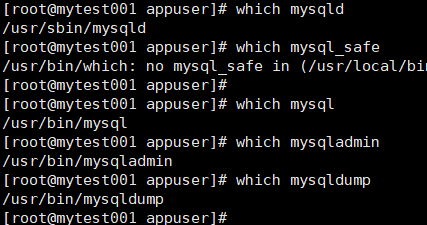
关键配置
1.配置文件的位置
MySQL配置文件
/etc/my.cnf 或者 /etc/my.cnf.d/server.cnf 【测试环境:/etc/my.cnf】
- 在哪里保存你的数据
几个关键的文件:
.pid文件,记录了进程id 【测试环境:/etc/my.cnf:[pid-file=/var/run/mysqld/mysqld.pid]】
.sock文件,是内部通信使用的socket接口,比3306快 【测试环境:/etc/my.cnf:[socket=/var/lib/mysql/mysql.sock]】
.log文件,日志文件 【测试环境:/etc/my.cnf:[log-error=/var/log/mysqld.log]】
安装目录:basedir 【测试环境:/usr/local/mysql】
数据目录:datadir 【测试环境:/etc/my.cnf:[datadir=/var/lib/mysql]】
例如下例:
[mysqld]
user=mysql
port=3306
socket=/data/3306/mysql.sock,#这里指定了一个特别的连接
basedir=/usr/local/mysql
datadir=/data/3306/data
[client]
port=3306
socket=/data/3306/mysql.sock,在客户端也要声明它,命令行要用到
注意:我当前的环境中没有复杂业务,此处后研究:
- 查询缓存要不要开
写入频繁的数据库,不要开查询缓存
query_cache_size
Query_cache里的数据又怎么处理呢?首先要把Query_cache和该表相关的语句全部置为失效,然后在写入更新。
那么如果Query_cache非常大,该表的查询结构又比较多,查询语句失效也慢,一个更新或是Insert就会很慢,
这样看到的就是Update或是Insert怎么这么慢了。所以在数据库写入量或是更新量也比较大的系统,该参数不适合分配过大。
而且在高并发,写入量大的系统,建议把该功能禁掉。
query_cache_limit
指定单个查询能够使用的缓冲区大小,缺省为1M
query_cache_min_res_unit
默认是4KB,设置值大对大数据查询有好处,但如果你的查询都是小数据查询,就容易造成内存碎片和浪费
说明:禁掉查询缓存的方法就是直接注释掉查询缓存的配置,如#query_cache_size=1M, 这样就可以了
- 其他需要开的缓存
读缓存,线程缓存,排序缓存
sort_buffer_size=2M
connection级参数。太大将导致在连接数增高时,内存不足。
max_allowed_packet=32M
网络传输中一次消息传输量的最大值。系统默认值 为1MB,最大值是1GB,必须设置1024的倍数。
join_buffer_size=2M
和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享
tmp_table_size=256M
默认大小是 32M。GROUP BY 多不多的问题
max_heap_table_size=256M
key_buffer_size=2048M
索引的缓冲区大小,对于内存在4GB左右的服务器来说,该参数可设置为256MB或384MB。
read_buffer_size=1M
read_rnd_buffer_size=16M
进行排序查询时,MySql会首先扫描一遍该缓冲,以避免磁盘搜索
bulk_insert_buffer_size=64M
批量插入数据缓存大小,可以有效提高插入效率,默认为8M
Innodb缓存
innodb_buffer_pool_size=2048M
只需要用Innodb的话则可以设置它高达 70-80% 的可用内存。一些应用于 key_buffer 的规则有 ——如果你的数据量不大,并且不会暴增,那么无需把innodb_buffer_pool_size 设置的太大了。
配置文件的读取过程
/etc/my.cnf --> /etc/mysql/my.cnf --> $MYSQL_HOME/my.cnf --> defaults-extra-file=/tmp/clsn.txt --> ~/.my.cnf
mysql多实例配置
MySQL多实例就是同时开启多个不同的服务端口(如:3306/3308)同时运行多个进程,通过不同的socket监听不同的服务端口来提供服务。
多实例共用一套MySQL安装程序,使用不同的my.cnf(也可以相同)配置文件、启动程序(也可以相同)和数据文件。
在提供服务时,多实例MySQL在逻辑上看来是各自独立的,他们根据配置文件对应设定值,获得服务器响应数量的资源。
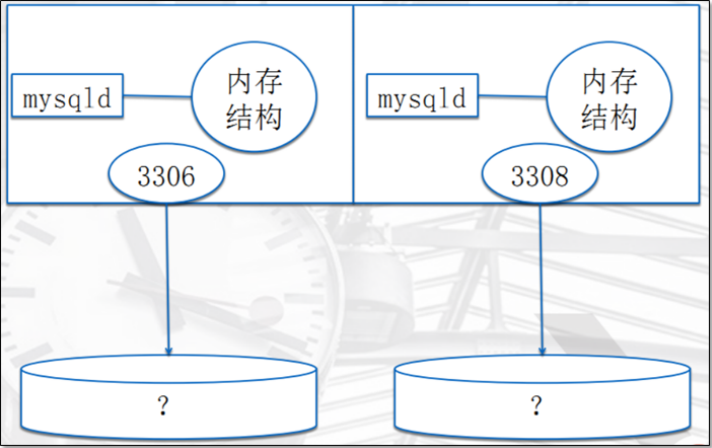
MySQL多实例的作用与问题
有效利用服务器资源,且可以实现资源的逻辑隔离;
节约服务器资源,当公司资金紧张,但是数据库又需要各自尽量独立地提供服务,而且,需要主从复制等技术时,多实例就再好不过了
弊端,比如,会存在资源互相抢占的问题。
当某个数据库实例并发很高或者有SQL慢查询时,整个实例会消耗大量的系统CPU、磁盘I/O等资源,导致服务器上的其他数据库实例提供服务的质量一起下降。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构