
01_日志采集框架Flume简介及其运行机制
离线辅助系统概览:
1.概述:
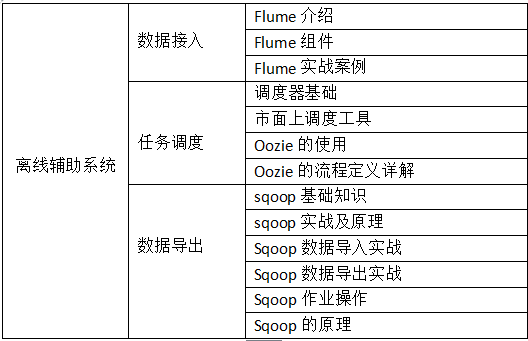
在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集、结果数据导出、
任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中都有便捷的开源框架,如图所示:
1.1 Flume介绍:
Flume是一个分布式、可靠、高可用的海量日志采集、聚合和传输的系统。
Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS、hbase、hive、kafka等众多外
部存储系统中
一般的采集需求,通过对flume的简单配置即可实现
Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景。
1.2 Flume运行机制:
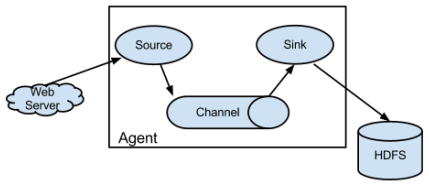
1. Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成
2. 每一个agent相当于一个数据传递员,内部有三个组件:
a) Source:采集源,用于跟数据源对接,以获取数据;
b) Sink:下沉采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据
c) Channel:angent内部的数据传输通道,用于从source将数据传递到sink
3. Source 到 Channel 到 Sink之间传递数据的形式是Event事件;Event事件是一个数据流单元;
1.3 Flume采集系统结构图:
1.简单结构:单个agent采集数据
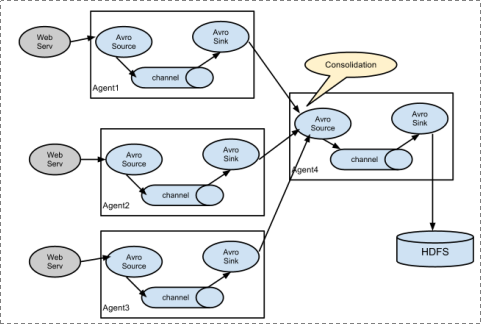
2.复杂结构:多个agent采集数据
你情我愿,我们就在一起!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号