
1.Lucene简介
1.Lucene简介
Lucene是一个基于Java的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能
Lucene是开源项目,它是可扩展,高性能的库用于索引和搜索几乎任何类型的文本, Lucene库提供了所需的任何搜索应用程
序的核心业务。索引和搜索
实际上lucene的功能很单一,说到底,就是你给它若干个字符串,然后它为你提供一个全文搜索服务,告诉你你要搜索的关键
词出现在哪里
2.Lucene的特点
倒排索引 压缩算法 二元搜索
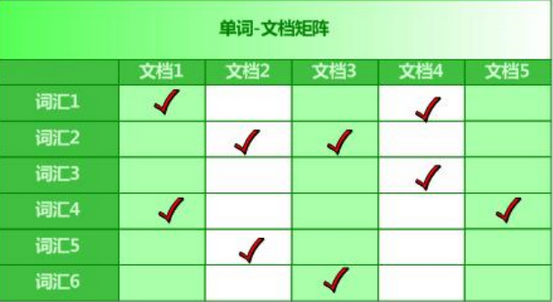
1.1.倒排索引 :
根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确
定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(invertedindex)
例如:单词——文档矩阵(将属性值放在前面作为索引)
3.Lucene的工作方式
lucene提供的服务实际包含两部分:一入一出。所谓入是写入,即将你提供的源(本质是字符串)写入索引或者将其从索引中删
除;所谓出是读出,即向用户提供全文搜索服务,让用户可以通过关键词定位源
写入流程 :源字符串首先经过analyzer处理,包括:分词,分成一个个单词;去除stopword(可选)。 将源中需要的信息加入
Document的各个Field中,并把需要索引的Field索引起来,把需要存储的Field存储起来。 将索引写入存储器,存储器可以是内存或磁盘
读出流程 :用户提供搜索关键词,经过analyzer处理。 对处理后的关键词搜索索引找出对应的Document。 用户根据需要从找到的
Document中提取需要的Field。
document 用户提供的源是一条条记录,它们可以是文本文件、字符串或者数据库表的一条记录等等。一条记录经过索引之后,就
是以一个Document的形式存储在索引文件中的。用户进行搜索,也是以Document列表的形式返回。
field 一个Document可以包含多个信息域,例如一篇文章可以包含“标题”、“正文”、“最后修改时间”等信息域,这些信息域就是通过
Field在Document中存储的。 Field有两个属性可选:存储和索引。通过存储属性你可以控制是否对这个Field进行存储;通过索引属性你
可以控制是否对该Field进行索引。这看起来似乎有些废话,事实上对这两个属性的正确组合很重要
4.使用Lucene建立倒排索引文件
导入lucene 相关jar包,调用相关java API生成索引


 浙公网安备 33010602011771号
浙公网安备 33010602011771号