

吴恩达学习笔记3(multiple gradient descent)
2023-03-01 17:12:27 星期三
使用梯度下降法处理多元线性回归
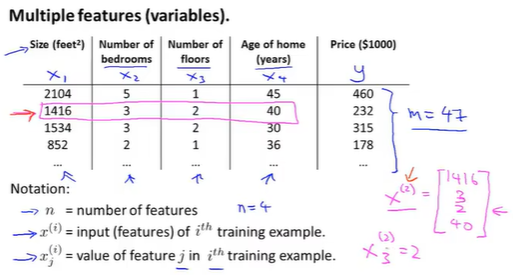
多元输入变量(multiple features)
假设函数
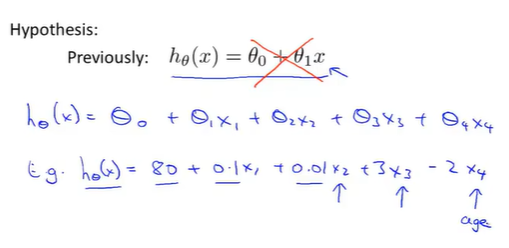
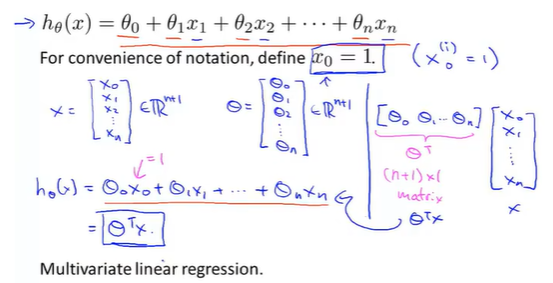
多元线性回归(multivariate linear regression)
将线性组合转换成矩阵乘法计算
问题描述

有n+1个特征量的gradient descent

特征缩放(feature scaling)
保证多个特征在相似范围内,这样梯度下降法能够更快的收敛
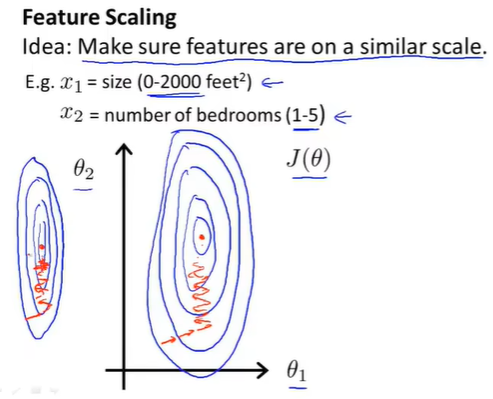
此时代价函数J的等值线图是椭圆形,梯度下降要来回波动,最终才收敛到最小值。
采用特征缩放
- 除以最大值
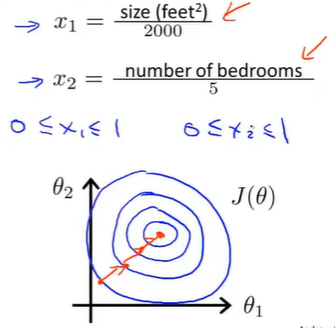
此时代价函数J的等值线偏移会变得没那么严重,此时梯度下降法是一条直线,收敛速度更快
注:
采用特征缩放时,特征取值约束到-1到+1范围内,不必严格规定,大概范围就行。

- 均值归一化

其中
梯度下降算法技巧
-
学习率(learning rate)

调试以及确保梯度下降算法正确工作的小技巧
学习率如何选
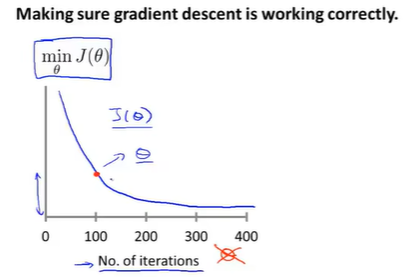
横坐标: 梯度下降算法的迭代100次
纵坐标:梯度下降算法相应100次得到的
表示梯度下降的每步迭代后,代价函数的值,如果梯度下降算法正常工作,每一步迭代后的
代价函数不继续下降==>梯度下降算法差不多已经收敛
自动收敛测试

如果
此时判断函数
不收敛情况

学习率较大
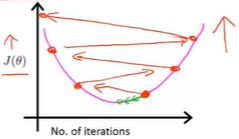
如果
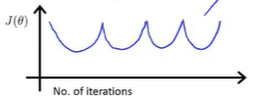
此时同样是
学习率
学习率
总结

对于大数据样本,加速收敛就是刚开始选择大学习率,随着迭代选择小学习率。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具