数据库期末速成
数据库技术发展阶段
- 人工管理
- 文件系统
- 数据库系统
数据库的三级模式
- 内模式
一个数据库只有一个内模式 - 模式
也称概念模式或逻辑模式
对数据库中全部数据的逻辑结构和特征的描述(数据项的名字、类型、取值范围)
一个数据库只有一个模式
位于模式结构的中间层
与硬件无关,与具体的应用程序、开发工具及高级程序设计语言无关 - 外模式
数据库用户能够看见和使用的局部数据的逻辑结构和特征的描述
一个数据库可以有多个外模式,但是一个应用程序只能使用一个外模式
内模式-DBMS
模式-DBA
外模式-程序员
数据库-三级模式和两级映射
信息的三种世界
- 现实世界
- 信息世界(概念世界)
- 数据世界(机器世界)
概念模型
是现实世界的第一层抽象
在概念模型中,用于标识同一实体集中两个不同实体值的是关键字
常用的概念模型是实体-联系模型
基本概念
- 实体:一名学生,一名教师
- 属性:姓名,性别,年龄,大队
- 码:学号(唯一标识符)
- 实体型:学生(学号、姓名,性别,年龄,系。。。)(用实体名及其属性名集合来抽象刻画同类实体)
- 实体集:全体学生(同型实体的集合)
- 联系:教师实体与学社工实体之间存在教和学的联系,学生和课程之间存在选课联系
两个实体型之间的联系
- 一对一联系(1:1)
一个区队只有一个区队长
一个区队长旨在一个区队任职 - 一对多联系(1:M)
一个区队中有若干名学生,每个学生只属于一个区队 - 多对多联系(M:N)
- 一门课程同时又若干个学生选修
- 一个学生可以同时选修多门课程
E-R图
- 实体-矩形
- 属性-椭圆形表示,并用无向边将其与相应的实体连接起来
- 联系-棱形,用无向边把棱形框与有关实体连接起来,在无向边旁边著名联系的类型
- 联系的属性-椭圆形表示,若联系具有属性,也要用无向边联系起来
数据模型
组成:数据结构、数据操作、数据的完整性约束
三种数据模型:
层次模型(非关系模型)、网状模型(非关系模型)、关系模型
层次模型:
用树形结构表示各类实体以及实体间的联系(无法直接表示多对多)
网状模型:
用网状结构,容易描述多对多联系
关系模型:
用二维表格表示实体及实体间的关系
一个关系对应一张二维表
二位表中的一行代表一个元组
二维表中的列称为属性,给每一个属性起一个名称即属性名
属性值是属性的具体取值
属性的取值范围称为域
关键字或码(唯一标识元组的属性)
...(不详细描述了)
关系数据库
- 数据结构:关系
- 逻辑结构:二维表
在每一个关系中,必须满足:
每一列数据类型相同,每个属性必须是单值,关系的结构不能嵌套。
关系是动态的,随时间变化的
关系模式是对关系的描述,是静态的,相对稳定的
关系完整性
- 实体完整性:关系的主码中属性具有唯一性且不能取空值
- 参照完整性:学生关系中国每个元组的“专业号”属性只能取两类值:空值和非空值
- 用户定义的完整性规则。
数据库设计
概念数据库设计
逻辑结构设计
将E-R图转换为具体DBMS所支持的逻辑数据模型
- 一个实体转化为一个关系模式
- 一个联系转换为一个关系模式
1:1联系转换
可以转换成一独立关系模式
也可以与一段模式合并
1:N联系转换
课转成一独立模式
也可以与N端模式合并
M:N联系转换
必须产生一新的独立模式
关系规范化
符合某一种关系模式的集合
第一范式
关系R中所有的属性的原子即每列都是不可再分的数据项。
满足则记作R∈1NF
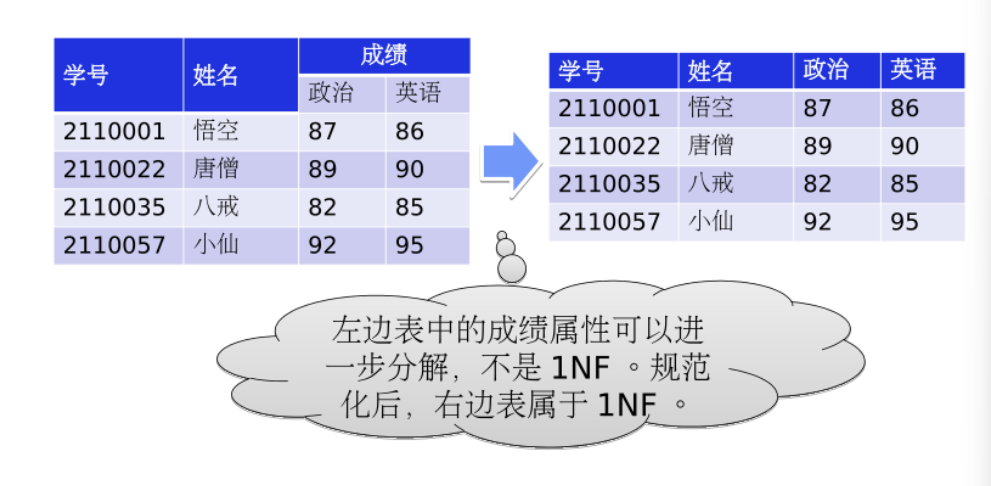
第二范式
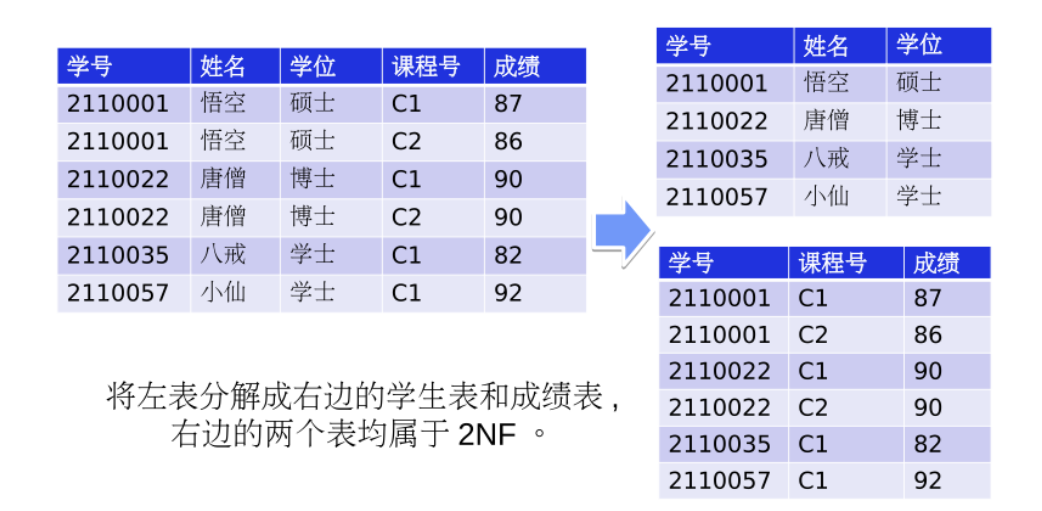
如果一个关系满足1NF,且除了主键意外的其他列,都完全依赖于该主键,而不是部分依赖
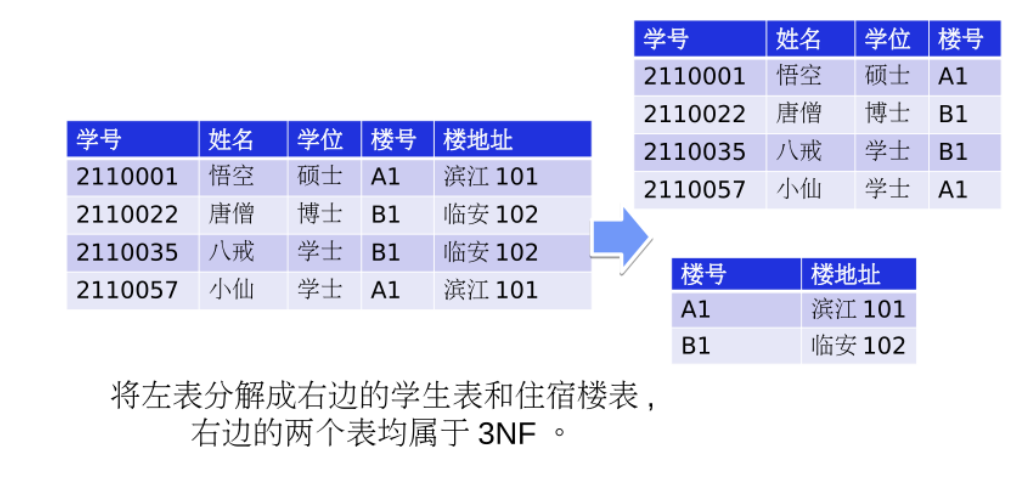
如图,主键为学号和课程号,表中存在函数依赖关系集:学号->姓名,学号->学位,(学号,课程号)->成绩,只有成绩完全依赖于主键,姓名和学位部分依赖于主键,因此不是2NF
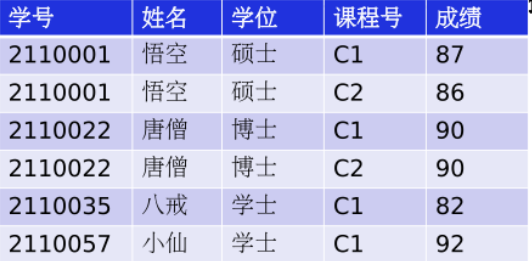
练习:
第三范式
如果一个关系R已经满足2NF,且没有一个非主键属性传递函数依赖于主键。满足则记作R∈3NF(即没有传递依赖)
传递依赖:如果关系中属性A->B,B->C,则A->C
学号->楼号,楼号->楼地址
存在传递依赖,不是3NF
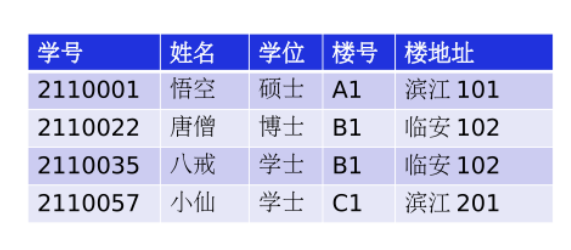
练习:
物理结构设计
表的操作
表的创建
use TeachDB
create table student;
(sno char(7) primary key,
sname varchar(8) not null,
ssex char(2),
sbirth date,
ssubunit varchar(20)
);
create table sc
(
sno char(7),
cno char(4),
score real,
primary key (sno,cno),
/*主码由两个属性构成,必须作为标记完整性进行定义*/
foreign key(sno) references student(sno),
/*标记完整性约束,sno是外码,被参照表是student*/
foreign key(cno references course(cno)
/*标记完整性约束,cno是外码,被参照表是course*/
)
表的修改
alter table student alter column sname varchar(10) not null;
删除学生表中的列
alter table student drop column sage;
添加表中的列
alter table student add cno char(4)
删除表
drop table course;
列约束和表约束
- primary key(主键)
- unique(唯一性)
- foreign key(外键)
- check(取值范围)
- default(默认值约束)
- NULL和NOT NULL(是否允许为空)
SQL删除约束
alter table table_name drop constraint constraint_name[,...n]
插入数据
insert [into] student(sno,sname,ssex) values('2210108','xiaoxiannv','女')
修改数据
update student set 性别 = '男' where sno = '2210108'
删除数据
delete student where sno = '2210108'
数据库查询(重点)
投影查询
select sno,sname from student;
select distinct specialty from student;
select * from student
select top 5 * from student
select top 50 percent * from student
select sno,sname,'年龄',year(getdate())-year(sbirthday) from student
select sno as 学号,姓名 = sname,year(getdate())-year(sbirthday) 年龄 from student
#以上是三种不同的列别名
选择查询
select * from student where specialty = '网安'
select sname,year(sbirthday) from student where year <2004;
#比较字符型的列,必须用单引号引起来
select * from sc where score between 80 and 90;
select sno,sname,specialty from student where specialty in ('网安','反恐')
#模糊查询
select sname,ssex from student where sname '杨%' #查询姓杨的同学
#查询姓名中第二个字为莫且全名为三个字的同学
select sname from student where sname like '_莫_'
#空值的查询
select sno,cno from SC where score IS (NOT) NULL
#多重查询
使用and和or来联结多个查询条件
聚合函数查询
count(*) 返回找到的函数
count(列名)
sum(列名)
avg(列名)
min(列名)
max(列名)
# 统计一列中不同值的个数
select count(distinct 列名) from SC
分组查询
#查询各专业又男女各多少人
select specialty,ssex,count(sno) 人数 from student group by specialty,ssex
#带having的条件的分组查询
select sno,count(cno) from sc
group by sno
having count(cno)>2
Where 作用于表,从中选择满足条件的行
Having 作用于组,从中筛选满足条件的组
Having 中条件使用聚合函数,Where中条件不能使用聚合函数
如果有group by子句,select子句列表只能是聚合函数和group by子句指定的列构成
查询结果排序
#查询所有“女”学生的学号、姓名和专业,并按学号升序排序
select sno,sname,specialty from student where ssex='女' order by ASC
#查询sc表中学生的成绩和学号,并按成绩(降序)排列,若成绩相同按学号(升序)排列
select sno,score from SC order by score DESC,sno ASC
连接查询
内连接
从两个笛卡尔积中,选出符合连接条件的元组
使用inner join运算符,并且使用on关键字指定连接
#查询每个学生的学号、姓名、课程号和成绩
select student.sno,student.sname,sc.score FROM student INNER JOIN sc
ON student.sno=sc.sno
#上式等于下面这条式子,个人觉得后者比较简单
select student.sno,student.sname,sc.score FROM student,sc WHERE student.sno=sc.sno
自连接
一张表的两个副本之间的连接
必须为表指定两个别名,使之在逻辑上成为两张表
select * from student a,student b
where a.sname = b.sname and a.sno<>b.sno
外连接
不仅要查询已经选课的学生情况,还要为选课的学生情况
左外连接 LEFT OUTER JOIN
右外连接 RIGHT OUTER JOIN
全外连接 FULL OUTER JOIN
#查询每个学生及其选修课程的成绩情况(含为选课的学生信息)
select student.*,sc.cno,sc.score FROM student LEFT JOIN sc ON student.sno=sc.sno
#查询每个学生及其选修课程的情况(含为选课的学生信息及为被选修的课程信息)
select course.*,student.sno,student.sname,sc.score FROM course FULL JOIN sc ON course.cno = sc.cno FULL JOIN student ON student.sno = sc.sno
我是这么理解的:左外连接就是左边这张表里的元素必须在结果中,右边的表有对应的就往里填,没有就为空。全外连接就是互相填充
交叉连接
不考,不写
子查询
select语句可以嵌套在其他语句中(比如select、insert、update、delete等)
无关子查询
在父查询之前执行,然后返回数据供父查询使用
select * from sc a where score < (select avg(score) from sc b)
#查询于“小仙女”在同一个专业学习的学生信息
法一:
select * from student
where specialty = (select specialty from student where sname = '小仙女')
法二:
select a.* from student a,student b where a.specialty = b.specialty and b.sname = '小仙女'
#子查询不能用order by子句
新知识:
#查询C001号课程成绩最高的学生学号
select sno from sc where cno = 'C001'
and score >= ALL(select score from sc where cno = 'C001')
或
select sno from sc where cno = 'C001'
and score = (select max(score)from sc where cno = 'C001')
相关子查询
- 比较子查询
#查询成绩比该课的平均成绩低的学生成绩信息
select * from sc a
where score<(select avg(score) from sc b where a.cno = b.cno)
- 带有exists的子查询
#查询没有选修C004号课程的学生姓名
select sname from student where not exists(select * from sc where sno = student.sno and cno = 'C004')
联合查询
并 UNION
select sno FROM sc WHERE cno = 'C001'
UNION
select sno FROM sc WHERE cno = 'C004'
交 INTERSECT
过
差 EXCEPT
过
视图与索引
视图:
- 从一个或几个基本表导出的表
- 只存放视图的定义,不存放数据
- 基表数据发生变化,从试图中查询出的数据也随之改变
视图创建
CREATE VIEW vi_sc
AS
select * FROM student.sno=sc.sno AND course.cno = sc.cno AND specialty = '网安'
视图修改
ALTER VIEW vi_count
AS
...
视图使用
select * from vi_count WHERE 课程名 = 'C语言'
使用视图修改基本表中的数据
INSERT INTO vi_boy(sno,sname,ssex,sage)
VALUES('2210108','y1y1','男','19');
可以发现,在boy表里是可以插入性别为女的数据的
需要在视图结尾加上WITH CHECK OPTION来加以约束
视图删除
DROP VIEW vi_boy
索引
->加快查询速度
索引创建
#给student表的姓名列的升序创建一个名为“index_name”的普通索引
create index idx_name ON student(sname)
create unique index idx_Scno
on SC(Sno ASC,Cno DESC)
索引查看
#查看表中的索引信息
EXEC sp_helpindex student
或者
EXEC sp_help student
索引删除
#删除student表中的index_sname索引
DROP INDEX student.index_name
存储过程
一组能完成特定功能的SQL语句集,存储在数据库中,经过第一次编译后再次调用不需要再编译
存储过程创建
CREATE PROCEDURE proc_getStuAvgScore
AS
select sno,avg(score) as 'avgscore' from sc GROUP BY sno
#创建课查询的存储过程
CREATE PROCEDURE proc_getStudent
@number char(7)
AS
select * from student WHERE sno = @number
存储过程的执行
EXECUTE proc_getStuAvgScore
#传参
EXECUTE proc_getStudent '1302001'
存储过程修改
ALTER PROCEDURE name
@sname varchar(20) = '小仙女'
AS
....
存储过程删除
DROP PROCEDURE proc_getStuByName
触发器
触发器创建
不能显示地被调用,而是在指定的表或视图中插入更改删除记录时被自动调用
#为student表创建一个简单触发器,
再插入和修改数据是,能自动提示信息
Create TRIGGER reminder ON student FOR INSERT,UPDATE AS print '你在插入或修改student的数据'
触发器修改
alter TRIGGER reminder ON student INSTEAD OF INSERT,UPDATE
AS print'你执行的添加或修改操作无效!'
触发器的禁止、启用
ALTER TABLE 表名
ENABLE|DISABLE TRIGGER 触发器名
触发器的删除
DROP TRIGGER 触发器名
基于C#.NET的数据库应用系统开发
过
祝:期末不挂科
本文来自博客园作者:P1ggy,转载请注明原文链接:https://www.cnblogs.com/y1y1/p/17951576
