负采样(召回paper reading)
负采样的必要性?
可以不用但没有必要;通常而言能显著提高计算效率,理论和实验能证明效果有保证,调整采样策略甚至能更好
1、是否需要负样本?(无负样本)
- 可以通过batch norm,regularization term避免模型坍塌,如byol, Knowledge Graph Embedding Without Negative Sampling
2、是否需要采样?(全量样本)
- 如果效率问题可被高度优化,全量计算所有样例:Efficient Heterogeneous Collaborative Filtering without Negative Sampling for Recommendation
3、采样下如何预估概率?
- 正交分解采样空间: 层次softmax
- 采样空间来逼近全空间:
- NCE估计目标分布,简化为NEG (简化为识别正样本与噪声的二分类)
- Sampled Softmax (抽样候选集做归一项的近似, 变种为info nce)
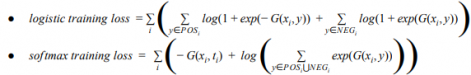
其中G(x,y) = sim(x,y) - log q(y|x) 也就是去samle selection bias(ssb)的logits
Notes on Noise Contrastive Estimation and Negative Sampling
负样本构成?
召回任务下以serving时的样本全空间随机采样为主,辅以负样本挖掘,后者与任务强相关,各显神通
- 以aribnb为例 Real-time Personalization using Embeddings for Search Ranking at Airbnb
- 随机采样 + 同城/owner拒绝作为强负样本
- 以pinsage为例 Graph Convolutional Neural Networks for Web-Scale Recommender Systems
- 随机采样 + Personal PageRank分数低(随机游走的重复次数,rank 2000-5000)作为强负样本
- 以ebr为例 Embedding-based Retrieval in Facebook Search
- 随机采样 + 难样本挖掘
- 正样本:click v.s. impression v.s. both 均等有效
- 负样本: random v.s. non-click impression 后者显著差 因为样本分布偏差,实际上hard negative也是部分相关的
- non-click impression 无论是补充正样本,负样本都没有明显效果
- 以ATA为例:

负样本采样策略?
没有显著好的策略,主要看建模目的,可以融合多种策略进行生成,通常而言提高数量,去除偏差效果不会变差
1. uniform采样:训练前准备好负样本
- 随机负采样:随机从负例候选集中选择一个作为负例
- 流行度采样:\(p_n(v) \propto deg(v)^{\alpha}\)(可以是负值,如音乐场景)
2. in batch采样:batch内的所有样本作为彼此的负样本去做batch softmax
- 由于全空间分布与用户行为分布有bias,因此重在去除ssb,见 Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations
3. cross batch采样: 缓存前几个batch的embedding和采样概率,用作补充当前batch的负样本
- 重在保证效率的情况下提高采样规模 Cross-Batch Negative Sampling for Training Two-Tower Recommenders
4. 其他
- 生成式采样:生成器充当采样器生成样例以混淆判别器,而判别器需要判断给定的样例是正例还是生成的样例。A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models
- 图结构采样:根据图结构导出正负样本例。如pinsage根据游走序列导出page rank分作为负样本筛选标准。
- 业务信息采样:借助样本强化side info建模,如位置,类目,不同阶段的交互等,如pv not click, click not purchase
负样本质量?
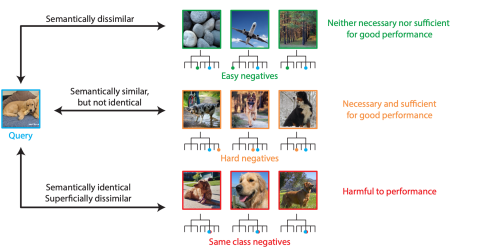
Hard Negative
-
必要性:分析表明非常少的负样本(5%的强负样本)直接决定了模型效果好坏,95%的简单负样本是不必要且不充分的,0.1%的超难负样本是有害的 Are all negatives created equal in contrastive instance discrimination?
-
策略:圈选候选分布的子集,逐渐逼近真实分布
- Online : 训练过程中动态枚举选择离src/pos 最近的样本作为强负样本
- Offline: 人为分层样本,如相关性分层,位置分层,模型预测排序分层
-
以airbnb为例

-
以ebr为例
- online: 同batch内与正样本最相似的其他正样本作为难负样本。(不够难)
- offline: 取预测rank 101-500的样本作为超难负样本。(迭代训练)
- 只用hard < 只用simple < 混合 , 因为预测空间是混合难度的。
-
以ATA为例:

- 样本组合:随机打散?累计训练?
Debias
- SSB:
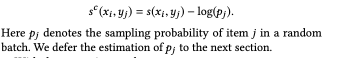
- False Negative: 强负例是可能未来正样本, 来自于ssb,怎么过滤?Simplify and Robustify Negative Sampling for Implicit Collaborative Filtering
- 人为设定:不是选择得分最高的负例,而是考虑对应的正样本分数,选择得分不超过正样本的难度适中的负例来缓解伪负例问题
- 启发式:统计学的角度观测到数据集中的伪负例在训练过程中方差较小,而强负例具有较高的方差。
负样本数量?
-
理论上样本数量越多信息量越多\(I(x^{+},c) \ge log(K+1)-\mathcal{L}_K\),但是label是隐式的,K太大会导致noise太多,即存在伪负例。
-
静态数量:基本呈现先增后降的趋势,无论是绝对数量还是混合比例都是经验性方法
-
以cross batch为例:
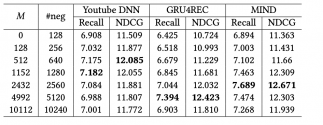
-
以EBR为例:
- 每个正样本最好是2个难负样本, 简单:困难= 100:1
-
以ATA为例:

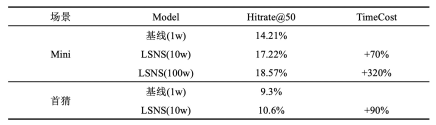
-
-
动态数量
- 标签越置信或越不置信,所需要的负样本数量均以多为宜(对抗噪声、逼近真实分布)Rethinking InfoNCE: How Many Negative Samples Do You Need?
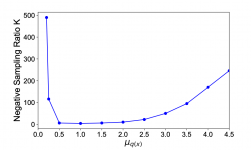
- 模型开始及结束阶段,负样本数量均以少为宜。(正样本指引学习、持续优化简单负样本造成overfitting)
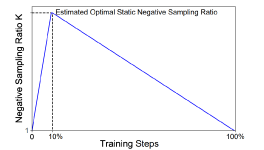
- 标签越置信或越不置信,所需要的负样本数量均以多为宜(对抗噪声、逼近真实分布)Rethinking InfoNCE: How Many Negative Samples Do You Need?
Appendix
https://github.com/RUCAIBox/Negative-Sampling-Paper
https://zhuanlan.zhihu.com/p/451214173
https://mp.weixin.qq.com/s/kcR4l_VKEXgGGsTEM71DNA

 浙公网安备 33010602011771号
浙公网安备 33010602011771号