
7-1 图的字典表示
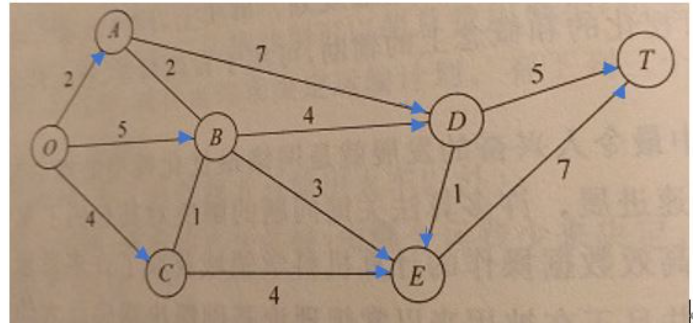
有向图的字典表示。输入多行字符串,每行表示一个顶点和该顶点相连的边及长度,输出顶点数,边数,边的总长度。比如上图0点表示:
{'O':{'A':2,'B':5,'C':4}}。用eval函数处理输入,eval函数具体用法见第六章内置函数。
输入格式:
第一行表示输入的行数
下面每行输入表示一个顶点和该顶点相连的边及长度的字符串
输出格式:
在一行中输出顶点数,边数,边的总长度
输入样例:
在这里给出一组输入。例如:
4
{'a':{'b':10,'c':6}}
{'b':{'c':2,'d':7}}
{'c':{'d':10}}
{'d':{}}
输出样例:
在这里给出相应的输出。例如:
4 5 35
pointnum=int(input()) edgesum=0 edgenum=0 for i in range(pointnum): dictlist=eval(input()) for j in dictlist: dict=dictlist[j] for k in dict: edgenum=edgenum+1 edgesum=edgesum+dict[k] break print(pointnum,edgenum,edgesum)
7-2 jmu-python-逆序输出
输入一行字符串,然后对其进行如下处理。
输入格式:
字符串中的元素以空格或者多个空格分隔。
输出格式:
逆序输出字符串中的所有元素。
然后输出原列表。
然后逆序输出原列表每个元素,中间以1个空格分隔。注意:最后一个元素后面不能有空格。
输入样例:
a b c e f gh
输出样例:
ghfecba
['a', 'b', 'c', 'e', 'f', 'gh']
gh f e c b a
str=input()
list=[]
for s in str.split():
list.append(s)
print("".join(list[::-1]))
print(list)
print(" ".join(list[::-1]))
7-3 jmu-python-班级人员信息统计
输入a,b班的名单,并进行如下统计。
输入格式:
第1行::a班名单,一串字符串,每个字符代表一个学生,无空格,可能有重复字符。
第2行::b班名单,一串字符串,每个学生名称以1个或多个空格分隔,可能有重复学生。
第3行::参加acm竞赛的学生,一串字符串,每个学生名称以1个或多个空格分隔。
第4行:参加英语竞赛的学生,一串字符串,每个学生名称以1个或多个空格分隔。
第5行:转学的人(只有1个人)。
输出格式
特别注意:输出人员名单的时候需调用sorted函数,如集合为x,则print(sorted(x))
输出两个班级的所有人员数量
输出两个班级中既没有参加ACM,也没有参加English的名单和数量
输出所有参加竞赛的人员的名单和数量
输出既参加了ACM,又参加了英语竞赛的所有人员及数量
输出参加了ACM,未参加英语竞赛的所有人员名单
输出参加英语竞赛,未参加ACM的所有人员名单
输出参加只参加ACM或只参加英语竞赛的人员名单
最后一行:一个同学要转学,首先需要判断该学生在哪个班级,然后更新该班级名单,并输出。如果没有在任何一班级,什么也不做。
输入样例:
abcdefghijab
1 2 3 4 5 6 7 8 9 10
1 2 3 a b c
1 5 10 a d e f
a
输出样例:
Total: 20
Not in race: ['4', '6', '7', '8', '9', 'g', 'h', 'i', 'j'], num: 9
All racers: ['1', '10', '2', '3', '5', 'a', 'b', 'c', 'd', 'e', 'f'], num: 11
ACM + English: ['1', 'a'], num: 2
Only ACM: ['2', '3', 'b', 'c']
Only English: ['10', '5', 'd', 'e', 'f']
ACM Or English: ['10', '2', '3', '5', 'b', 'c', 'd', 'e', 'f']
['b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']a = input()
seta = set(a)
b = input()
setb = set(b.split())
acm = input()
setacm = set(acm.split())
english = input()
setenglish = set(english.split())
zhuanxue = input()
Total = seta.union(setb)
race = setacm.union(setenglish)
Notinrace = Total.difference(race)
ACMplusEnglish = setacm.intersection(setenglish)
OnlyACM = setacm.difference(setenglish)
OnlyEnglish = setenglish.difference(setacm)
ACMOrEnglish = setacm.symmetric_difference(setenglish)
print("Total:",len(seta.union(setb)))
print("Not in race:",sorted(Notinrace),end=", ")
print("num:",len(Notinrace))
print("All racers:",sorted(race),end=", ")
print("num:",len(race))
print("ACM + English:",sorted(ACMplusEnglish),end=", ")
print("num:",len(ACMplusEnglish))
print("Only ACM:",sorted(OnlyACM))
print("Only English:",sorted(OnlyEnglish))
print("ACM Or English:",sorted(ACMOrEnglish))
if zhuanxue in seta:
seta.remove(zhuanxue)
print(sorted(seta))
elif zhuanxue in setb:
setb.remove(zhuanxue)
print(sorted(setb))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号