

寒假研学作业
1.寒假研学作业
import requests
from bs4 import BeautifulSoup
import re
import openpyxl
import sqlite3
class DoubanTop250:
def __init__(self):
self.headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0"}
self.base_url = "https://movie.douban.com/top250"
def fetch_content(self, url):#获得网页内容
response = requests.get(url, headers=self.headers)
if response.status_code == 200:#爬取成功
return response.text
else:
return None
def parse_content(self, html):#解析内容
soup = BeautifulSoup(html, 'html.parser')
movie_list = []
movies = soup.find_all('div', class_='item')
for movie in movies:
#电影名称
title = movie.find('span', class_='title').get_text()#得到不含标签的文本内容
#电影引言
quote = movie.find('span', class_='inq').get_text() if movie.find('span', class_='inq') else ''
participants = movie.find('p', class_='').get_text().strip()
#电影导演
director_stars_participants = re.split(r'\s+/|\xa0\xa0\xa0', participants)#正则表达式,导演与主演之间有三个空格
director_participants = director_stars_participants[0].split(':')#把“导演”和人名分开
director = director_participants[1].strip() if len(director_participants) > 1 else '未知'#只要人名
#电影主演
stars_participants = director_stars_participants[1].split(':') if len(director_stars_participants) > 1 else ['未知']#把“主演”和人名分开
stars = stars_participants[1] if len(stars_participants) > 1 else '未知'#把人名存储进stars
#电影评分
rating = movie.find('span', class_='rating_num').get_text()
movie_list.append([title, quote, director, stars, rating])
next_page = soup.find('span', class_='next').find('a')
next_page_url = self.base_url + "?start=" + next_page['href'].split('=')[1] if next_page else None
return movie_list, next_page_url
def save_to_excel(self, movies):#存入excel表格中
wb = openpyxl.Workbook()#工作簿
sheet = wb.active#获取第一张工作表
sheet.title = '豆瓣电影Top250'
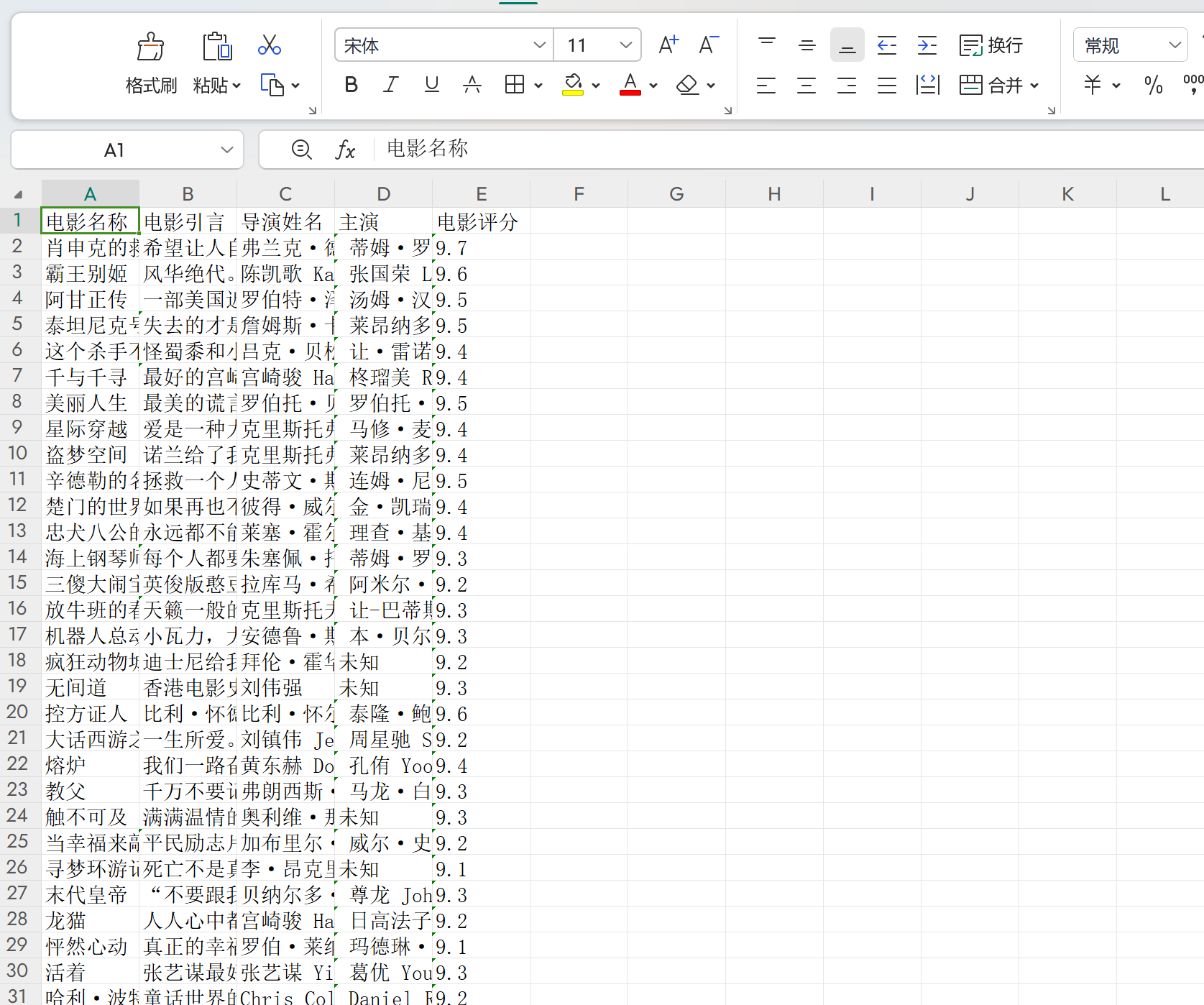
sheet.append(['电影名称', '电影引言', '导演姓名', '主演', '电影评分'])
for movie in movies:
sheet.append(movie)#输入数据
wb.save('Douban_Movie_Top250.xlsx')
def run(self):#通过循环得到每一页的数据
self.create_database()#创建数据库和表
movies = []#存储电影的信息
next_page_url = self.base_url
while next_page_url:#当下一页不为空,继续循环
html = self.fetch_content(next_page_url)
page_movies, next_page_url = self.parse_content(html)
movies.extend(page_movies)
#extend将一个列表全部元素添加到一个列表中
self.save_to_excel(movies)#调用写入excel文件
self.save(movies)#存储数据到数据库
self.close()#关闭
def create_database(self):
self.connection = sqlite3.connect('douban_movie_top250.db')#连接创建数据库
self.cursor = self.connection.cursor()#创建游标
#创建表
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS movies(
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT,
quote TEXT,
director TEXT,
stars TEXT,
rating TEXT
)
''')#内容都用TEXT存储,id是每一行的标识符
#不存在movies时创建新表
self.connection.commit()#提交
def save(self, movies):#存储数据库
for movie in movies:
self.cursor.execute('''
INSERT INTO movies(title,quote,director,stars,rating)
VALUES(?,?,?,?,?)
''', movie)#?作为占位符,INSERT指明插入数据
self.connection.commit()#确保数据插入成功
def close(self):#关闭数据库
self.connection.close()
result = DoubanTop250()
result.run()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!