

| 作业要求 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
|---|---|
| 作业目标 | 用python代码实现论文查重、学会用性能分析、单元测试、异常处理说明、记录PSP表格 |
| GitHub链接 | https://github.com/sunshyys/lunwenchachong |
调用的模块及接口:
jieba:
jieba库是优秀的中文分词第三方库。它的分词原理是利用一个中文词库,确定汉字之间的关联概率,汉字间概率大的组成词组,形成分词结果
gensim:
Gensim是在做自然语言处理时较为经常用到的一个工具库,主要用来以无监督的方式从原始的非结构化文本当中来学习到文本隐藏层的主题向量表达。
re:
re 模块(Regular Expression 正则表达式)提供各种正则表达式的匹配操作,在文本解析、复杂字符串分析和信息提取时是一个非常有用的工具
os:
os库是Python标准库,包含几百个函数,常用路径操作、进程管理、环境参数等几类。os.path子库以path为入口,用于操作和处理文件路径。
cProfile:
测试程序性能的模块
各函数如下:
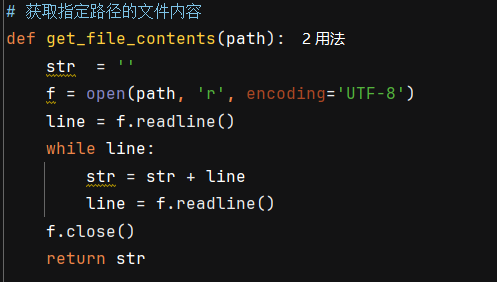
get_file_contents:
获取指定路径的函数内容,代码如下:
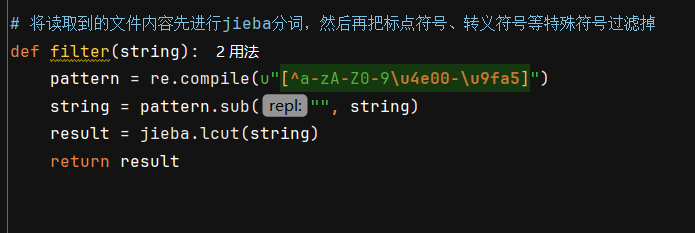
filter:
将读取到的文件内容先进行jieba分词,然后再把标点符号、转义符号等特殊符号过滤掉,代码如下:
convert_corpus:
忽略掉文本的语法和语序等要素,将其仅仅看作是若干个词汇的集合,代码如下:

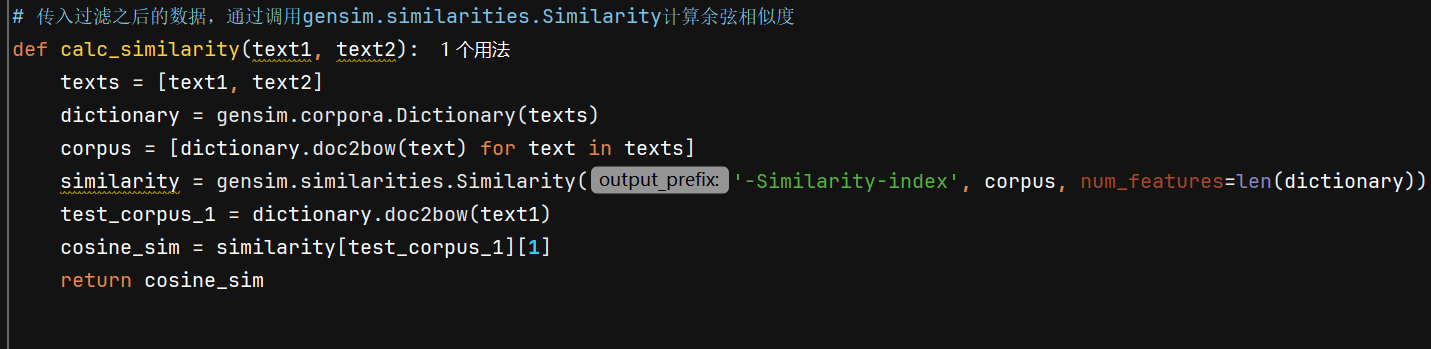
calc_similarity:
传入过滤之后的数据,通过调用gensim.similarities.Similarity计算余弦相似度,代码如下:
代码实现如下:
点击查看代码
# coding:gbk
import os
import re
import cProfile
import gensim
import jieba
jieba.setLogLevel(jieba.logging.INFO)
# 获取指定路径的文件内容
def get_file_contents(path):
str = ''
f = open(path, 'r', encoding='UTF-8')
line = f.readline()
while line:
str = str + line
line = f.readline()
f.close()
return str
# 将读取到的文件内容先进行jieba分词,然后再把标点符号、转义符号等特殊符号过滤掉
def filter(string):
pattern = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]")
string = pattern.sub("", string)
result = jieba.lcut(string)
return result
# 忽略掉文本的语法和语序等要素,将其仅仅看作是若干个词汇的集合
def convert_corpus(text1, text2):
texts = [text1, text2]
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
return corpus
# 传入过滤之后的数据,通过调用gensim.similarities.Similarity计算余弦相似度
def calc_similarity(text1, text2):
texts = [text1, text2]
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))
test_corpus_1 = dictionary.doc2bow(text1)
cosine_sim = similarity[test_corpus_1][1]
return cosine_sim
if __name__ == '__main__':
print("请输入原论文路径:")
path1 = input()
print("请输入要查重的论文路径:")
path2 = input()
if not os.path.exists(path1) :
print("论文原文文件不存在!")
exit()
if not os.path.exists(path2):
print("抄袭版论文文件不存在!")
exit()
save_path = "C:\\Users\Administrator\PycharmProjects\\rjgc\save.txt" #输出结果绝对路径
str1 = get_file_contents(path1)
str2 = get_file_contents(path2)
text1 = filter(str1)
text2 = filter(str2)
similarity = calc_similarity(text1, text2)
print("文章相似度: %.2f"%similarity)
cProfile.run("get_file_contents(path1)")
cProfile.run("get_file_contents(path2)")
cProfile.run("filter(str1)")
cProfile.run("filter(str2)")
cProfile.run("convert_corpus(text1,text2)")
cProfile.run("calc_similarity(text1,text2)")
#将相似度结果写入指定文件
f = open(save_path, 'w', encoding="utf-8")
f.write("python"+" "+"main.py"+" "+path1+" "+path2+" "+"文章相似度: %.2f"%similarity)
f.close()
测试结果如下:
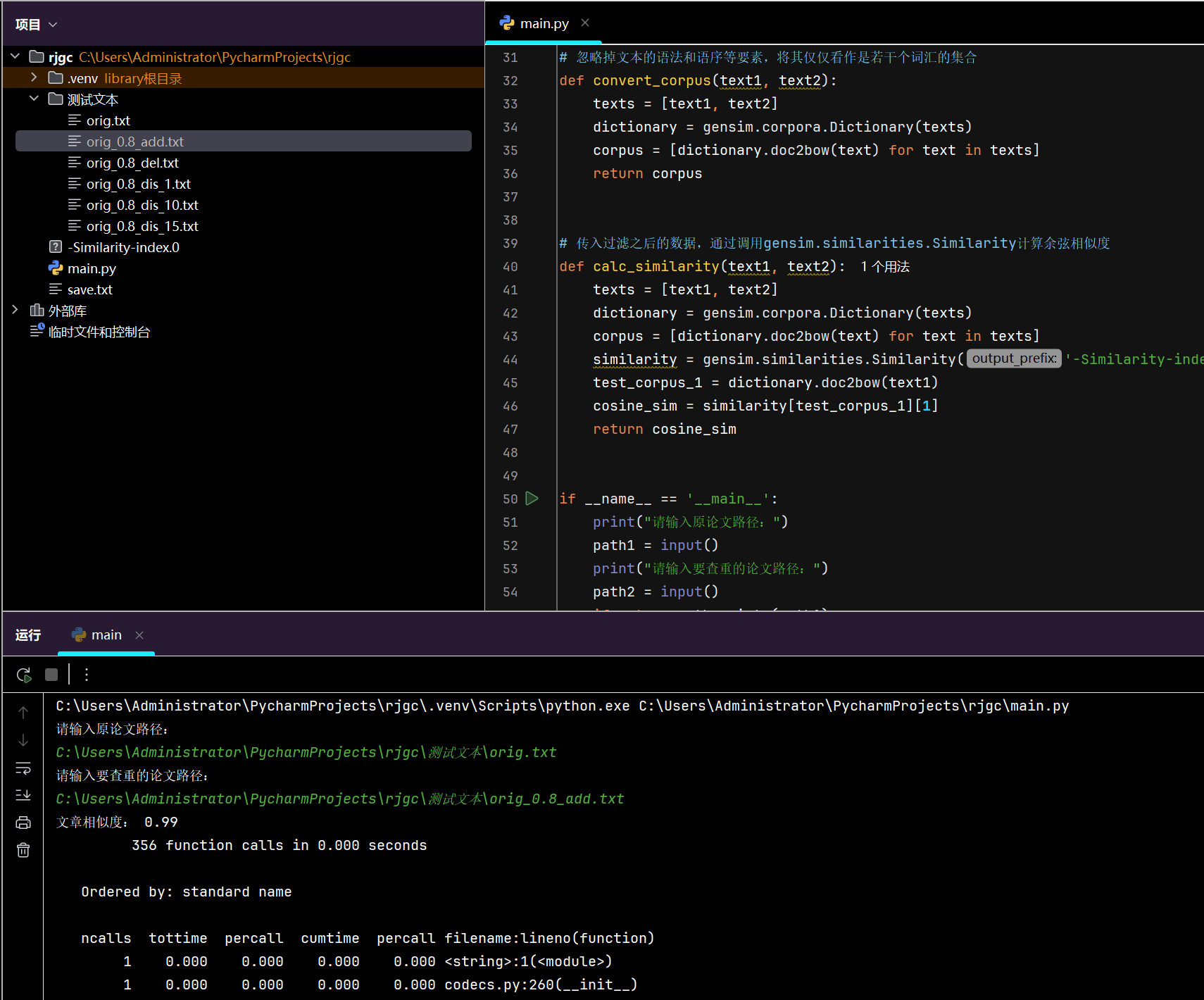

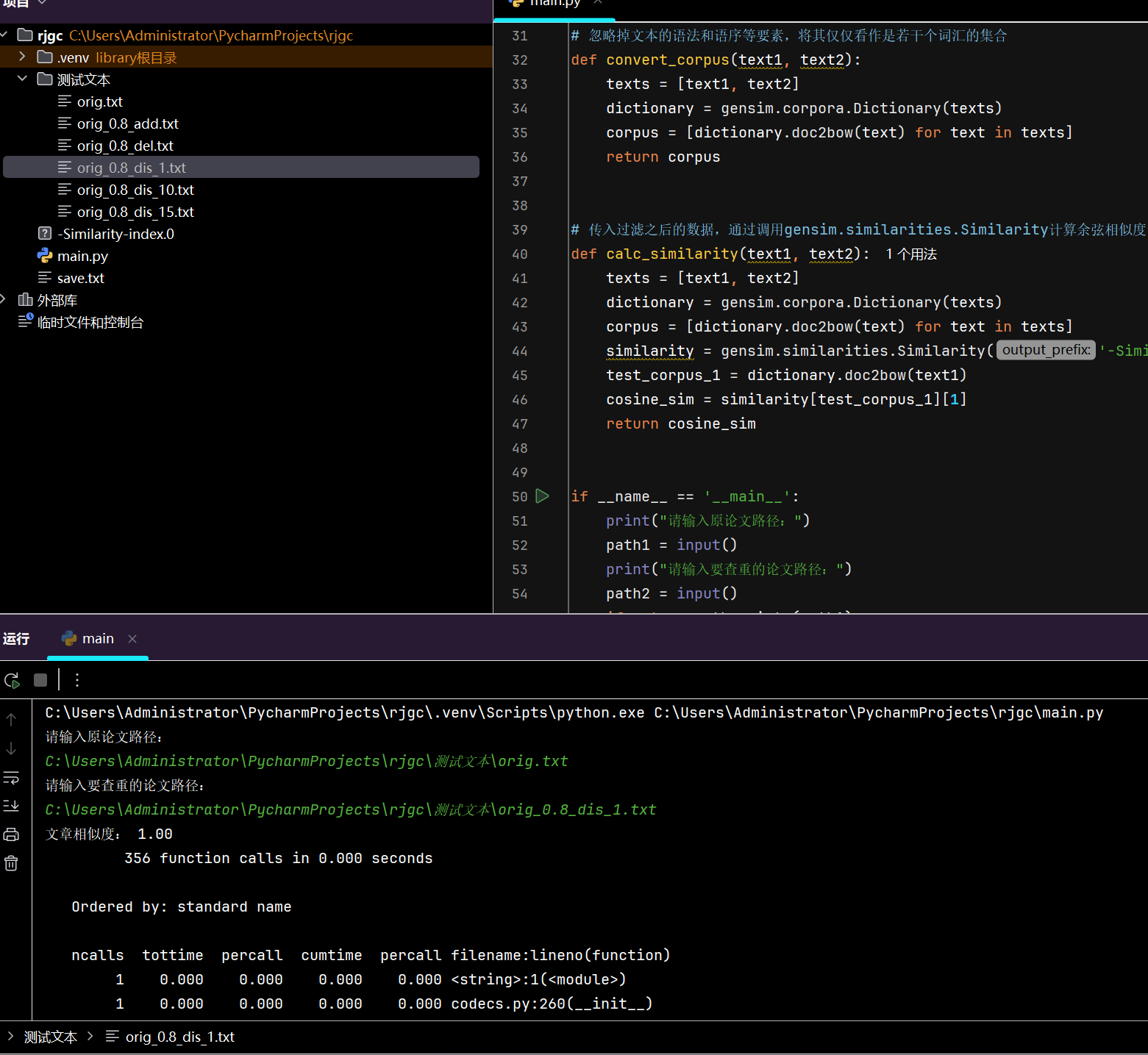
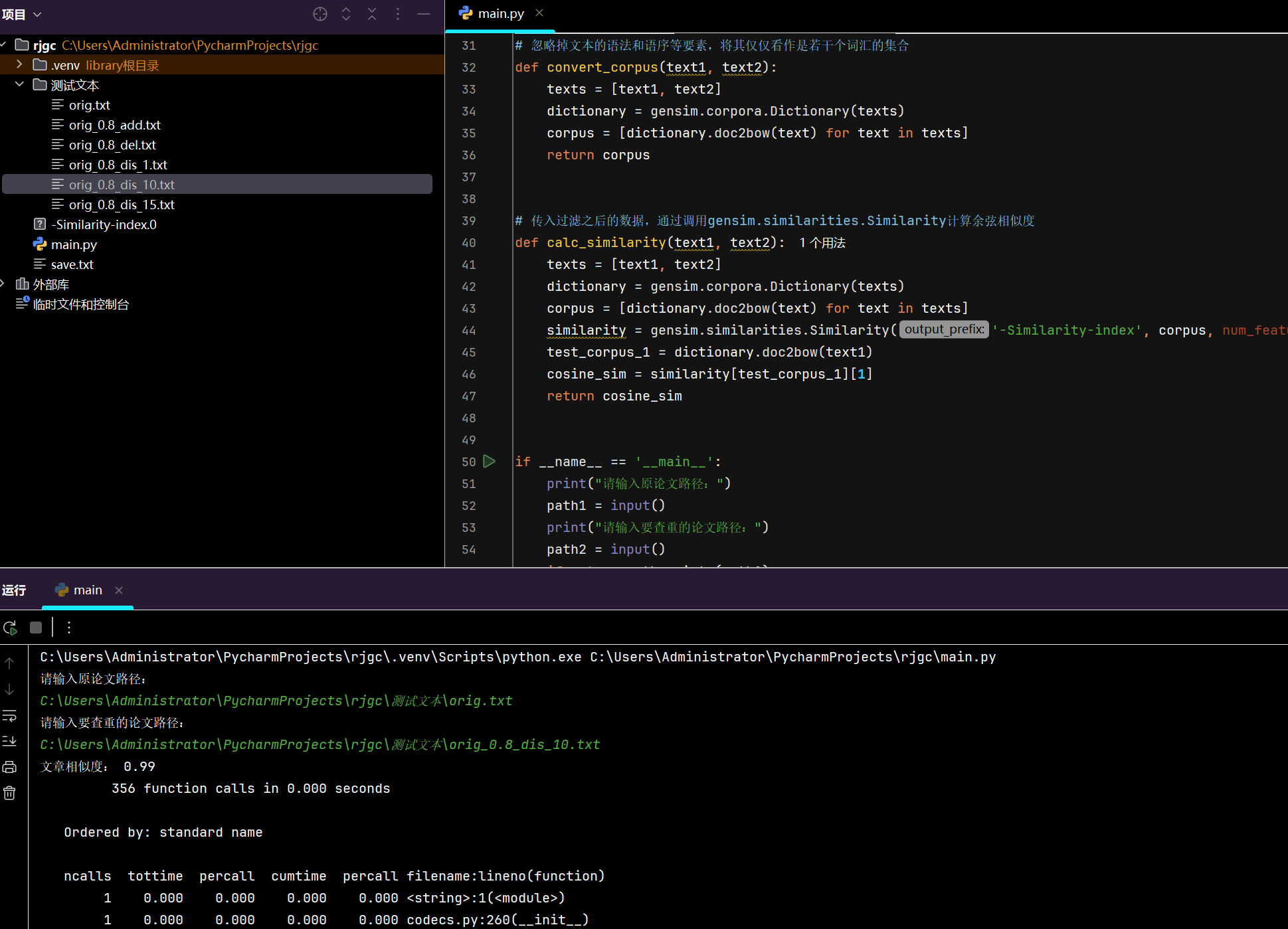
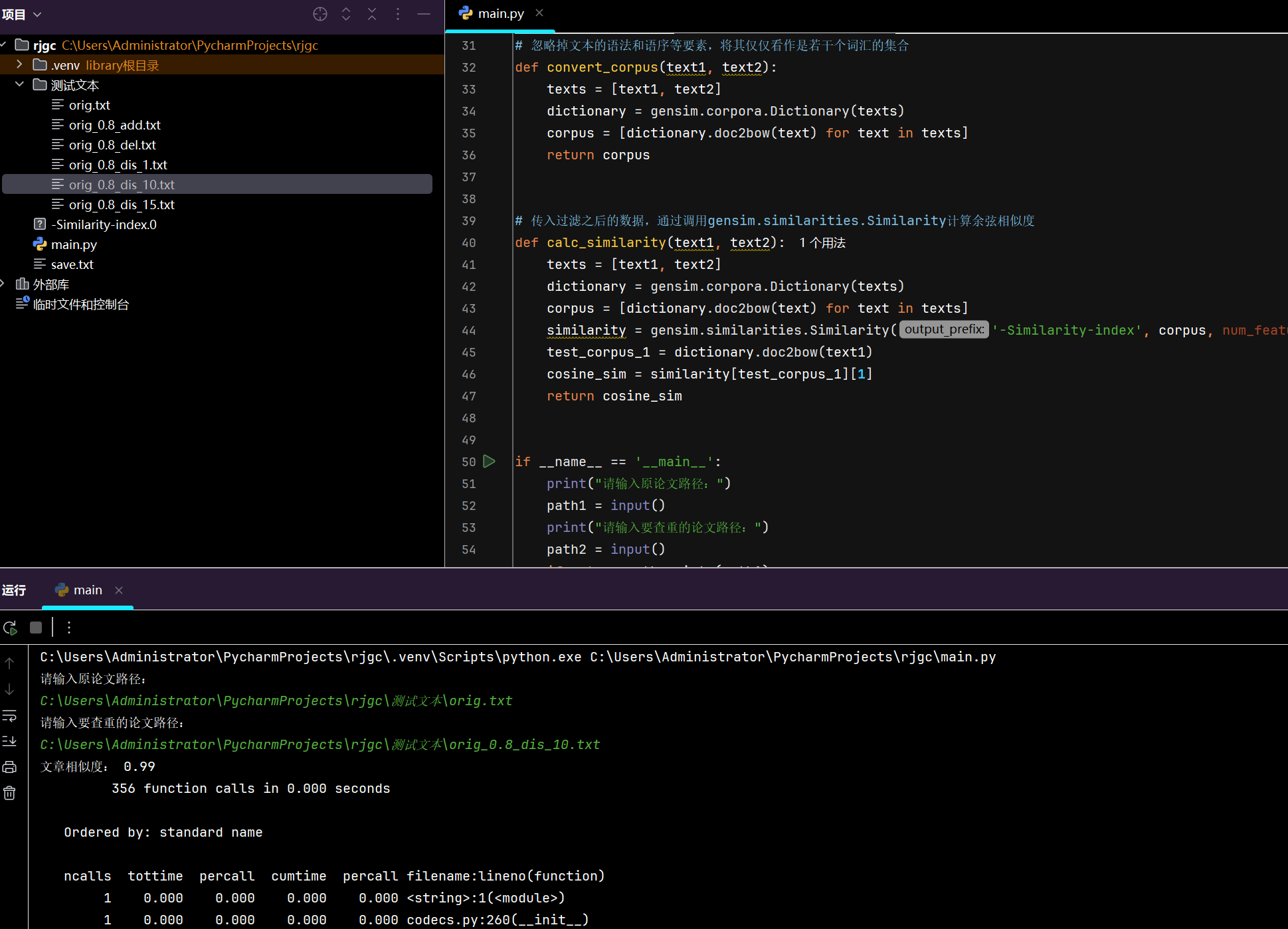
单元测试:
为了方便单元测试,主函数修改如下:
点击查看代码
if __name__ == '__main__':
print("请输入原论文路径:")
path1 = input()
print("请输入要查重的论文路径:")
path2 = input()
if not os.path.exists(path1) :
print("论文原文文件不存在!")
exit()
if not os.path.exists(path2):
print("抄袭版论文文件不存在!")
exit()
save_path = "C:\\Users\Administrator\PycharmProjects\\rjgc\save.txt" #输出结果绝对路径
str1 = get_file_contents(path1)
str2 = get_file_contents(path2)
text1 = filter(str1)
text2 = filter(str2)
similarity = calc_similarity(text1, text2)
print("文章相似度: %.2f"%similarity)
cProfile.run("get_file_contents(path1)")
cProfile.run("get_file_contents(path2)")
cProfile.run("filter(str1)")
cProfile.run("filter(str2)")
cProfile.run("convert_corpus(text1,text2)")
cProfile.run("calc_similarity(text1,text2)")
#将相似度结果写入指定文件
f = open(save_path, 'w', encoding="utf-8")
f.write("python"+" "+"main.py"+" "+path1+" "+path2+" "+"文章相似度: %.2f"%similarity)
f.close()
错误测试:
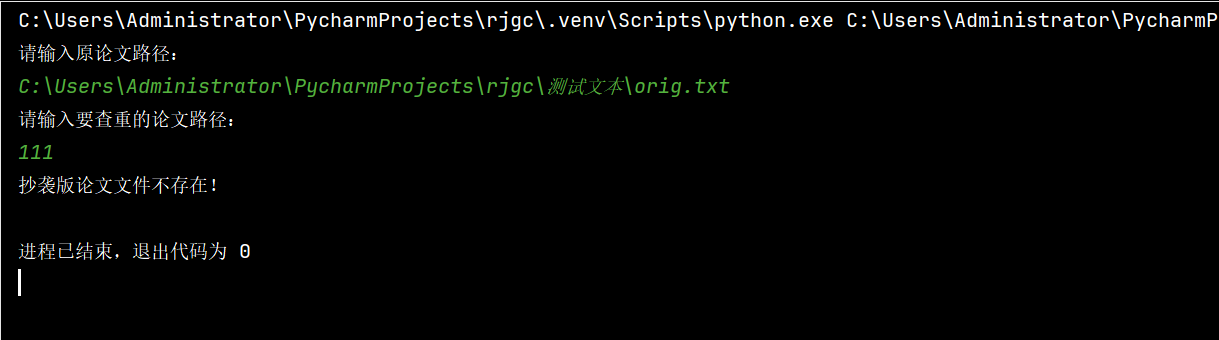
耗费时间如下:
点击查看代码
356 function calls in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 codecs.py:260(__init__)
1 0.000 0.000 0.000 0.000 codecs.py:309(__init__)
6 0.000 0.000 0.000 0.000 codecs.py:319(decode)
6 0.000 0.000 0.000 0.000 codecs.py:331(getstate)
1 0.000 0.000 0.000 0.000 main.py:12(get_file_contents)
6 0.000 0.000 0.000 0.000 {built-in method _codecs.utf_8_decode}
1 0.000 0.000 0.000 0.000 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {built-in method io.open}
1 0.000 0.000 0.000 0.000 {method 'close' of '_io.TextIOWrapper' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
330 0.000 0.000 0.000 0.000 {method 'readline' of '_io.TextIOWrapper' objects}
244 function calls in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 codecs.py:260(__init__)
1 0.000 0.000 0.000 0.000 codecs.py:309(__init__)
6 0.000 0.000 0.000 0.000 codecs.py:319(decode)
6 0.000 0.000 0.000 0.000 codecs.py:331(getstate)
1 0.000 0.000 0.000 0.000 main.py:12(get_file_contents)
6 0.000 0.000 0.000 0.000 {built-in method _codecs.utf_8_decode}
1 0.000 0.000 0.000 0.000 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {built-in method io.open}
1 0.000 0.000 0.000 0.000 {method 'close' of '_io.TextIOWrapper' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
218 0.000 0.000 0.000 0.000 {method 'readline' of '_io.TextIOWrapper' objects}
135930 function calls in 0.043 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.043 0.043 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 __init__.py:168(check_initialized)
1 0.002 0.002 0.013 0.013 __init__.py:172(calc)
20169 0.006 0.000 0.009 0.000 __init__.py:177(<genexpr>)
1 0.007 0.007 0.008 0.008 __init__.py:180(get_DAG)
5402 0.003 0.000 0.042 0.000 __init__.py:249(__cut_DAG)
5402 0.001 0.000 0.043 0.000 __init__.py:289(cut)
1 0.000 0.000 0.043 0.043 __init__.py:356(lcut)
760 0.006 0.000 0.013 0.000 __init__.py:37(viterbi)
7080 0.003 0.000 0.004 0.000 __init__.py:49(<listcomp>)
2280 0.000 0.000 0.000 0.000 __init__.py:54(<genexpr>)
3033 0.002 0.000 0.015 0.000 __init__.py:59(__cut)
3033 0.002 0.000 0.018 0.000 __init__.py:85(cut)
761 0.000 0.000 0.000 0.000 _compat.py:76(strdecode)
1 0.000 0.000 0.043 0.043 main.py:24(filter)
1 0.000 0.000 0.000 0.000 re.py:232(compile)
1 0.000 0.000 0.000 0.000 re.py:271(_compile)
1 0.000 0.000 0.043 0.043 {built-in method builtins.exec}
762 0.000 0.000 0.000 0.000 {built-in method builtins.isinstance}
4477 0.000 0.000 0.000 0.000 {built-in method builtins.len}
16324 0.003 0.000 0.012 0.000 {built-in method builtins.max}
11686 0.001 0.000 0.001 0.000 {built-in method math.log}
13455 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
36733 0.004 0.000 0.004 0.000 {method 'get' of 'dict' objects}
2281 0.001 0.000 0.001 0.000 {method 'match' of 're.Pattern' objects}
2281 0.001 0.000 0.001 0.000 {method 'split' of 're.Pattern' objects}
1 0.000 0.000 0.000 0.000 {method 'sub' of 're.Pattern' objects}
194385 function calls in 0.060 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.060 0.060 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 __init__.py:168(check_initialized)
1 0.010 0.010 0.019 0.019 __init__.py:172(calc)
18786 0.004 0.000 0.007 0.000 __init__.py:177(<genexpr>)
1 0.006 0.006 0.006 0.006 __init__.py:180(get_DAG)
5908 0.003 0.000 0.059 0.000 __init__.py:249(__cut_DAG)
5908 0.001 0.000 0.059 0.000 __init__.py:289(cut)
1 0.000 0.000 0.060 0.060 __init__.py:356(lcut)
879 0.012 0.000 0.026 0.000 __init__.py:37(viterbi)
17832 0.007 0.000 0.008 0.000 __init__.py:49(<listcomp>)
2637 0.000 0.000 0.000 0.000 __init__.py:54(<genexpr>)
5148 0.002 0.000 0.028 0.000 __init__.py:59(__cut)
5148 0.002 0.000 0.031 0.000 __init__.py:85(cut)
880 0.000 0.000 0.000 0.000 _compat.py:76(strdecode)
1 0.000 0.000 0.060 0.060 main.py:24(filter)
1 0.000 0.000 0.000 0.000 re.py:232(compile)
1 0.000 0.000 0.000 0.000 re.py:271(_compile)
1 0.000 0.000 0.060 0.060 {built-in method builtins.exec}
881 0.000 0.000 0.000 0.000 {built-in method builtins.isinstance}
4635 0.000 0.000 0.000 0.000 {built-in method builtins.len}
27195 0.004 0.000 0.011 0.000 {built-in method builtins.max}
10303 0.001 0.000 0.001 0.000 {built-in method math.log}
14760 0.001 0.000 0.001 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
68198 0.006 0.000 0.006 0.000 {method 'get' of 'dict' objects}
2638 0.001 0.000 0.001 0.000 {method 'match' of 're.Pattern' objects}
2638 0.000 0.000 0.000 0.000 {method 'split' of 're.Pattern' objects}
1 0.000 0.000 0.000 0.000 {method 'sub' of 're.Pattern' objects}
37260 function calls (37255 primitive calls) in 0.009 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.009 0.009 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 __init__.py:1356(debug)
2 0.000 0.000 0.000 0.000 __init__.py:1368(info)
1 0.000 0.000 0.000 0.000 __init__.py:1429(log)
4 0.000 0.000 0.000 0.000 __init__.py:1614(isEnabledFor)
3/1 0.000 0.000 0.000 0.000 copy.py:132(deepcopy)
2 0.000 0.000 0.000 0.000 copy.py:190(_deepcopy_atomic)
1 0.000 0.000 0.000 0.000 copy.py:236(_deepcopy_dict)
1 0.000 0.000 0.000 0.000 copy.py:252(_keep_alive)
3 0.000 0.000 0.000 0.000 dictionary.py:133(__len__)
1 0.000 0.000 0.000 0.000 dictionary.py:144(__str__)
1 0.000 0.000 0.006 0.006 dictionary.py:169(add_documents)
4 0.004 0.001 0.009 0.002 dictionary.py:208(doc2bow)
3111 0.000 0.000 0.000 0.000 dictionary.py:250(<genexpr>)
4 0.001 0.000 0.001 0.000 dictionary.py:256(<dictcomp>)
1 0.000 0.000 0.006 0.006 dictionary.py:43(__init__)
1 0.000 0.000 0.009 0.009 main.py:32(convert_corpus)
1 0.000 0.000 0.003 0.003 main.py:35(<listcomp>)
1 0.000 0.000 0.000 0.000 platform.py:1334(platform)
1 0.000 0.000 0.000 0.000 utils.py:399(add_lifecycle_event)
1 0.000 0.000 0.009 0.009 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {built-in method builtins.hasattr}
6 0.000 0.000 0.000 0.000 {built-in method builtins.id}
22621 0.001 0.000 0.001 0.000 {built-in method builtins.isinstance}
3117/3114 0.000 0.000 0.000 0.000 {built-in method builtins.len}
6 0.003 0.000 0.003 0.000 {built-in method builtins.sorted}
2 0.000 0.000 0.000 0.000 {built-in method builtins.sum}
1 0.000 0.000 0.000 0.000 {built-in method now}
1 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
8341 0.000 0.000 0.000 0.000 {method 'get' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'isoformat' of 'datetime.datetime' objects}
13 0.000 0.000 0.000 0.000 {method 'items' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'keys' of 'dict' objects}
2 0.000 0.000 0.000 0.000 {method 'values' of 'dict' objects}
50867 function calls (50848 primitive calls) in 0.017 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 <__array_function__ internals>:2(atleast_1d)
1 0.000 0.000 0.000 0.000 <__array_function__ internals>:2(concatenate)
1 0.000 0.000 0.000 0.000 <__array_function__ internals>:2(dot)
1 0.000 0.000 0.000 0.000 <__array_function__ internals>:2(hstack)
1 0.000 0.000 0.017 0.017 <string>:1(<module>)
8 0.000 0.000 0.000 0.000 __init__.py:1356(debug)
8 0.000 0.000 0.000 0.000 __init__.py:1368(info)
3 0.000 0.000 0.000 0.000 __init__.py:1429(log)
1 0.000 0.000 0.000 0.000 __init__.py:145(_DType_reduce)
19 0.000 0.000 0.000 0.000 __init__.py:1614(isEnabledFor)
7 0.000 0.000 0.000 0.000 base.py:1205(isspmatrix)
2 0.000 0.000 0.000 0.000 compression.py:26(get_supported_compression_types)
4 0.000 0.000 0.000 0.000 compression.py:34(get_supported_extensions)
1 0.000 0.000 0.000 0.000 contextlib.py:107(__enter__)
1 0.000 0.000 0.000 0.000 contextlib.py:116(__exit__)
1 0.000 0.000 0.000 0.000 contextlib.py:237(helper)
1 0.000 0.000 0.000 0.000 contextlib.py:81(__init__)
16/3 0.000 0.000 0.000 0.000 copy.py:132(deepcopy)
11 0.000 0.000 0.000 0.000 copy.py:190(_deepcopy_atomic)
1 0.000 0.000 0.000 0.000 copy.py:210(_deepcopy_list)
3 0.000 0.000 0.000 0.000 copy.py:236(_deepcopy_dict)
4 0.000 0.000 0.000 0.000 copy.py:252(_keep_alive)
1 0.000 0.000 0.000 0.000 copy.py:268(_reconstruct)
2 0.000 0.000 0.000 0.000 copy.py:273(<genexpr>)
4 0.000 0.000 0.000 0.000 dictionary.py:133(__len__)
1 0.000 0.000 0.000 0.000 dictionary.py:144(__str__)
1 0.000 0.000 0.006 0.006 dictionary.py:169(add_documents)
5 0.005 0.001 0.010 0.002 dictionary.py:208(doc2bow)
3111 0.000 0.000 0.000 0.000 dictionary.py:250(<genexpr>)
5 0.001 0.000 0.001 0.000 dictionary.py:256(<dictcomp>)
1 0.000 0.000 0.006 0.006 dictionary.py:43(__init__)
1 0.000 0.000 0.004 0.004 docsim.py:101(__init__)
4 0.000 0.000 0.000 0.000 docsim.py:119(fullname)
2 0.000 0.000 0.004 0.002 docsim.py:152(get_index)
1 0.000 0.000 0.001 0.001 docsim.py:189(__getitem__)
1 0.000 0.000 0.001 0.001 docsim.py:214(query_shard)
1 0.000 0.000 0.001 0.001 docsim.py:304(__init__)
1 0.000 0.000 0.001 0.001 docsim.py:366(add_documents)
1 0.000 0.000 0.000 0.000 docsim.py:417(shardid2filename)
1 0.000 0.000 0.004 0.004 docsim.py:436(close_shard)
1 0.000 0.000 0.000 0.000 docsim.py:479(query_shards)
1 0.000 0.000 0.006 0.006 docsim.py:504(__getitem__)
1 0.000 0.000 0.000 0.000 docsim.py:777(__init__)
1 0.000 0.000 0.000 0.000 docsim.py:835(__len__)
1 0.000 0.000 0.001 0.001 docsim.py:838(get_similarities)
2 0.000 0.000 0.000 0.000 genericpath.py:121(_splitext)
1 0.000 0.000 0.001 0.001 interfaces.py:305(__getitem__)
2 0.000 0.000 0.000 0.000 local_file.py:38(extract_local_path)
1 0.000 0.000 0.017 0.017 main.py:40(calc_similarity)
1 0.000 0.000 0.003 0.003 main.py:43(<listcomp>)
1 0.000 0.000 0.000 0.000 matutils.py:223(ismatrix)
3 0.001 0.000 0.002 0.001 matutils.py:370(sparse2full)
5955 0.001 0.000 0.001 0.000 matutils.py:394(<genexpr>)
1 0.000 0.000 0.000 0.000 matutils.py:647(ret_normalized_vec)
1 0.000 0.000 0.000 0.000 matutils.py:664(<listcomp>)
3 0.000 0.000 0.001 0.000 matutils.py:696(unitvec)
1786 0.000 0.000 0.000 0.000 matutils.py:781(<genexpr>)
1 0.000 0.000 0.000 0.000 multiarray.py:148(concatenate)
1 0.000 0.000 0.000 0.000 multiarray.py:736(dot)
9 0.000 0.000 0.000 0.000 ntpath.py:122(splitdrive)
1 0.000 0.000 0.000 0.000 ntpath.py:178(split)
2 0.000 0.000 0.000 0.000 ntpath.py:201(splitext)
2 0.000 0.000 0.000 0.000 ntpath.py:287(expanduser)
1 0.000 0.000 0.000 0.000 ntpath.py:34(_get_bothseps)
4 0.000 0.000 0.000 0.000 ntpath.py:75(join)
4 0.000 0.000 0.000 0.000 numerictypes.py:284(issubclass_)
2 0.000 0.000 0.000 0.000 numerictypes.py:358(issubdtype)
2 0.000 0.000 0.000 0.000 parse.py:109(_coerce_args)
2 0.000 0.000 0.000 0.000 parse.py:412(urlsplit)
2 0.000 0.000 0.000 0.000 parse.py:98(_noop)
3 0.000 0.000 0.000 0.000 platform.py:1334(platform)
1 0.000 0.000 0.000 0.000 shape_base.py:19(_atleast_1d_dispatcher)
1 0.000 0.000 0.000 0.000 shape_base.py:207(_arrays_for_stack_dispatcher)
1 0.000 0.000 0.000 0.000 shape_base.py:218(_vhstack_dispatcher)
1 0.000 0.000 0.000 0.000 shape_base.py:23(atleast_1d)
1 0.000 0.000 0.000 0.000 shape_base.py:285(hstack)
2 0.000 0.000 0.004 0.002 smart_open_lib.py:100(open)
2 0.000 0.000 0.004 0.002 smart_open_lib.py:308(_shortcut_open)
2 0.000 0.000 0.000 0.000 smart_open_lib.py:50(_sniff_scheme)
1 0.000 0.000 0.000 0.000 utils.py:1429(pickle)
1 0.000 0.000 0.004 0.004 utils.py:1446(unpickle)
2 0.000 0.000 0.000 0.000 utils.py:1545(ignore_deprecation_warning)
3 0.000 0.000 0.000 0.000 utils.py:399(add_lifecycle_event)
1 0.000 0.000 0.004 0.004 utils.py:453(load)
1 0.000 0.000 0.000 0.000 utils.py:491(_load_specials)
2 0.000 0.000 0.000 0.000 utils.py:558(_adapt_by_suffix)
1 0.000 0.000 0.000 0.000 utils.py:576(_smart_save)
1 0.000 0.000 0.000 0.000 utils.py:620(_save_specials)
1 0.000 0.000 0.001 0.001 utils.py:724(save)
2 0.000 0.000 0.000 0.000 utils.py:905(is_corpus)
1 0.000 0.000 0.000 0.000 warnings.py:130(filterwarnings)
1 0.000 0.000 0.000 0.000 warnings.py:181(_add_filter)
1 0.000 0.000 0.000 0.000 warnings.py:453(__init__)
1 0.000 0.000 0.000 0.000 warnings.py:474(__enter__)
1 0.000 0.000 0.000 0.000 warnings.py:493(__exit__)
2 0.000 0.000 0.000 0.000 {built-in method _pickle.dump}
1 0.000 0.000 0.000 0.000 {built-in method _pickle.load}
3 0.000 0.000 0.000 0.000 {built-in method _warnings._filters_mutated}
1 0.000 0.000 0.017 0.017 {built-in method builtins.exec}
7 0.000 0.000 0.000 0.000 {built-in method builtins.getattr}
16 0.000 0.000 0.000 0.000 {built-in method builtins.hasattr}
28 0.000 0.000 0.000 0.000 {built-in method builtins.id}
28080 0.001 0.000 0.001 0.000 {built-in method builtins.isinstance}
8 0.000 0.000 0.000 0.000 {built-in method builtins.issubclass}
5 0.000 0.000 0.000 0.000 {built-in method builtins.iter}
3144/3140 0.000 0.000 0.000 0.000 {built-in method builtins.len}
2 0.000 0.000 0.000 0.000 {built-in method builtins.locals}
2 0.000 0.000 0.000 0.000 {built-in method builtins.max}
7 0.000 0.000 0.000 0.000 {built-in method builtins.next}
11 0.004 0.000 0.004 0.000 {built-in method builtins.sorted}
3 0.000 0.000 0.000 0.000 {built-in method builtins.sum}
2 0.004 0.002 0.004 0.002 {built-in method io.open}
1 0.000 0.000 0.000 0.000 {built-in method math.sqrt}
3 0.000 0.000 0.000 0.000 {built-in method now}
18 0.000 0.000 0.000 0.000 {built-in method nt.fspath}
2 0.000 0.000 0.000 0.000 {built-in method nt.getpid}
1 0.000 0.000 0.000 0.000 {built-in method numpy.asanyarray}
1 0.000 0.000 0.000 0.000 {built-in method numpy.asarray}
4/2 0.000 0.000 0.000 0.000 {built-in method numpy.core._multiarray_umath.implement_array_function}
1 0.000 0.000 0.000 0.000 {built-in method numpy.empty}
3 0.000 0.000 0.000 0.000 {built-in method numpy.zeros}
1 0.000 0.000 0.000 0.000 {method '__reduce_ex__' of 'object' objects}
8 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
2 0.000 0.000 0.000 0.000 {method 'astype' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
5 0.000 0.000 0.000 0.000 {method 'endswith' of 'str' objects}
8372 0.000 0.000 0.000 0.000 {method 'get' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'insert' of 'list' objects}
3 0.000 0.000 0.000 0.000 {method 'isoformat' of 'datetime.datetime' objects}
21 0.000 0.000 0.000 0.000 {method 'items' of 'dict' objects}
5 0.000 0.000 0.000 0.000 {method 'keys' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'remove' of 'list' objects}
5 0.000 0.000 0.000 0.000 {method 'replace' of 'str' objects}
6 0.000 0.000 0.000 0.000 {method 'rfind' of 'str' objects}
1 0.000 0.000 0.000 0.000 {method 'rstrip' of 'str' objects}
4 0.000 0.000 0.000 0.000 {method 'startswith' of 'str' objects}
5 0.000 0.000 0.000 0.000 {method 'values' of 'dict' objects}
PSP表格如下:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 150 | 180 |
| Estimate | 估计这个任务需要多少时间 | 250 | 300 |
| Development | 开发 | 300 | 320 |
| Analysis | 需求分析 (包括学习新技术) | 100 | 100 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 30 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| Design | 具体设计 | 140 | 150 |
| Coding | 具体编码 | 30 | 50 |
| Code Review | 代码复审 | 20 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 10 | 30 |
| Reporting | 报告 | 100 | 200 |
| Test Repor | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 5 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 5 | 20 |
| 合计 | 1220 | 1470 |

