
hive on spark 踩坑记录
最近一直在弄hive on spark,明明选的spark 2.3.0和hive 3.0.0是兼容的,不知道为啥就是成功不了,今天终于解决了!
坑一:spark java.lang.NoClassDefFoundError: org/apache/spark/SparkConf
参考解决:https://blog.csdn.net/pingyufeng/article/details/126193929
解决方式
cp $SPARK_HOME/jars/scala-library-2.12.10.jar $HIVE_HOME/lib
cp $SPARK_HOME/jars/spark-core_2.12-3.1.2.jar $HIVE_HOME/lib
cp $SPARK_HOME/jars/spark-network-common_2.12-3.1.2.jar $HIVE_HOME/lib
坑二:
java.lang.IllegalAccessError: tried to access method com.google.common.base.Stopwatch.<init>()V from class org.apache.hadoop.mapreduce.lib.input.FileInputFormat at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:262) at org.apache.hadoop.hive.shims.Hadoop23Shims$1.listStatus(Hadoop23Shims.java:134) at org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat.getSplits(CombineFileInputFormat.java:217) at org.apache.hadoop.mapred.lib.CombineFileInputFormat.getSplits(CombineFileInputFormat.java:75) at org.apache.hadoop.hive.shims.HadoopShimsSecure$CombineFileInputFormatShim.getSplits(HadoopShimsSecure.java:321) at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getCombineSplits(CombineHiveInputFormat.java:444) at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getSplits(CombineHiveInputFormat.java:564) at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:200) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:253) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:251) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.rdd.RDD.partitions(RDD.scala:251) at org.apache.spark.rdd.RDD.getNumPartitions(RDD.scala:267) at org.apache.spark.api.java.JavaRDDLike$class.getNumPartitions(JavaRDDLike.scala:65) at org.apache.spark.api.java.AbstractJavaRDDLike.getNumPartitions(JavaRDDLike.scala:45) at org.apache.hadoop.hive.ql.exec.spark.SparkPlanGenerator.generateMapInput(SparkPlanGenerator.java:215) at org.apache.hadoop.hive.ql.exec.spark.SparkPlanGenerator.generateParentTran(SparkPlanGenerator.java:142) at org.apache.hadoop.hive.ql.exec.spark.SparkPlanGenerator.generate(SparkPlanGenerator.java:114) at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient$JobStatusJob.call(RemoteHiveSparkClient.java:359) at org.apache.hive.spark.client.RemoteDriver$JobWrapper.call(RemoteDriver.java:378) at org.apache.hive.spark.client.RemoteDriver$JobWrapper.call(RemoteDriver.java:343) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed during runtime. Please check stacktrace for the root cause.
图片为证
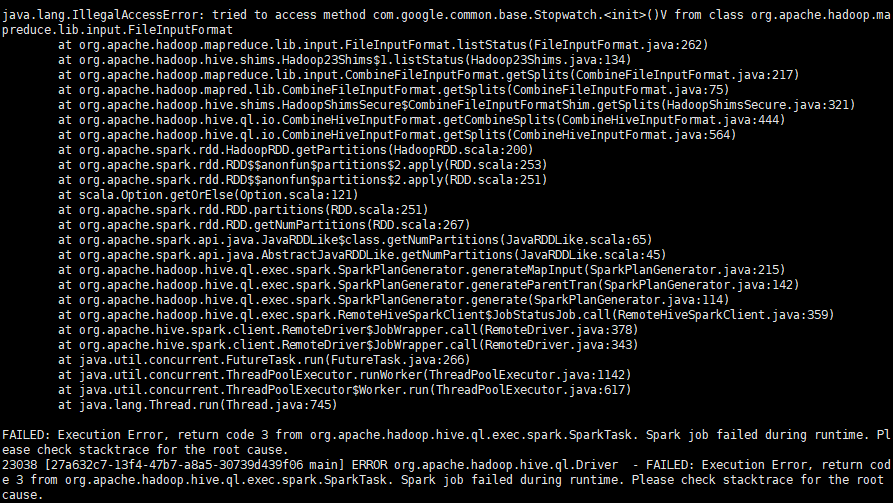
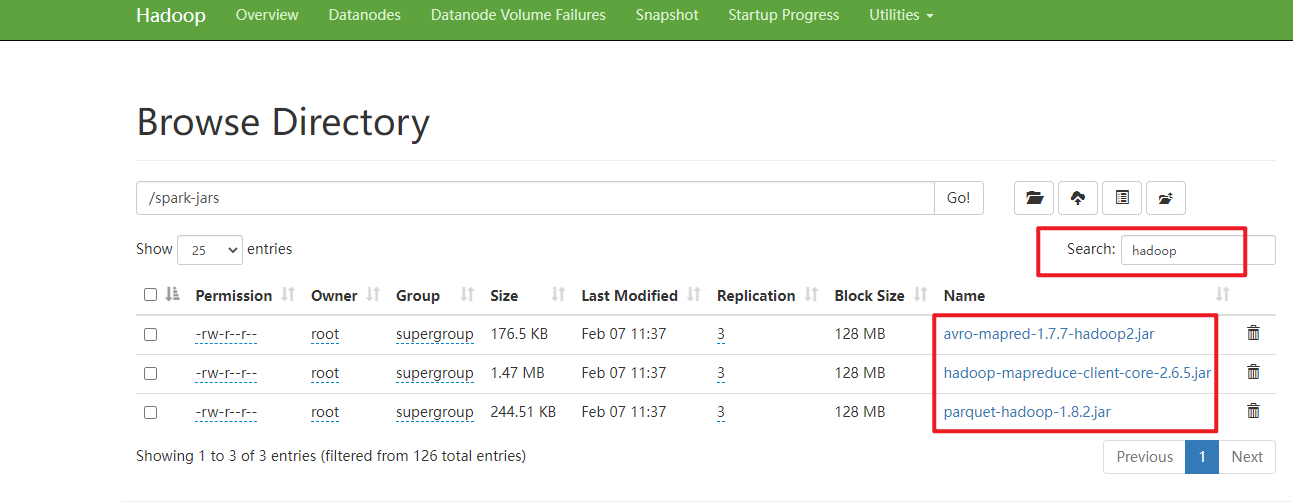
参考解决:https://www.cnblogs.com/ylcoder/p/6285041.html
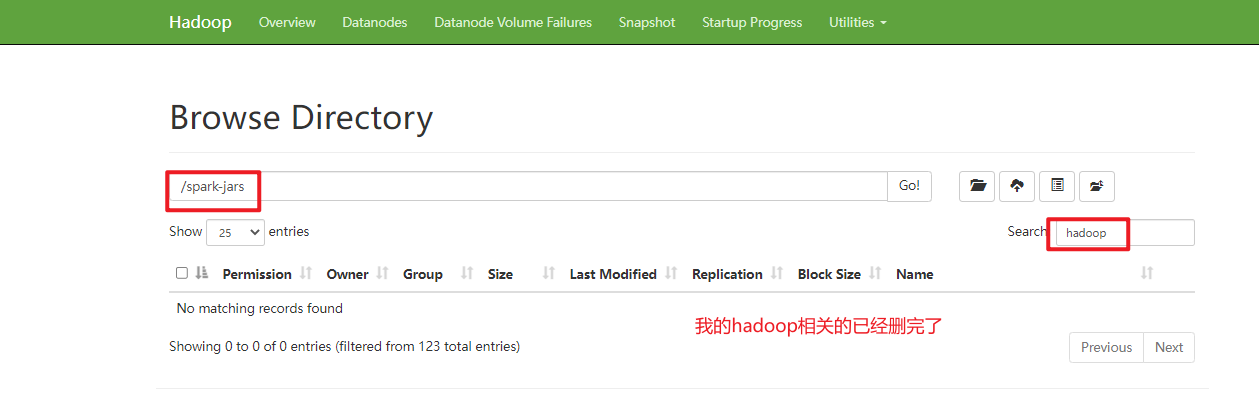
解决方式:删除上传到hdfs上的spark-jars(我的文件夹名)中hadoop相关的jar包
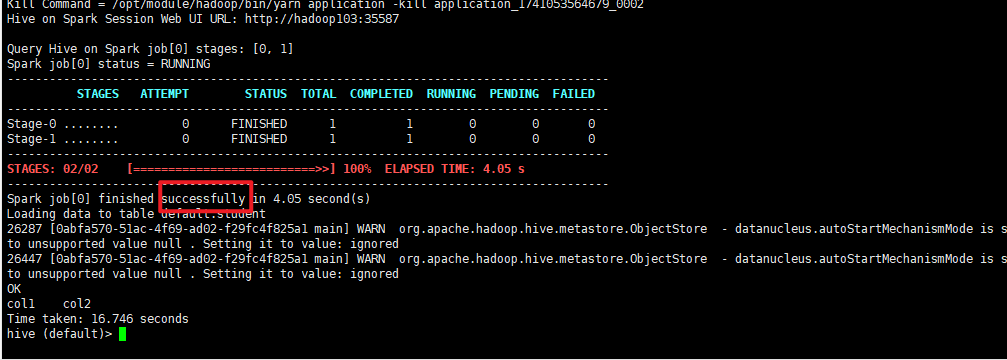
最后,hive执行的成功截图!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号