灭绝树学习小记
灭绝树学习小记
Tags:图论
一、概述
听这名字特别酷对吧
不像一个Noip滚粗选手能学的东西
所以只能当一个搬运工了
orzlitble:https://blog.csdn.net/litble/article/details/83019578
灭绝树和支配树应该是一种东西
用于\(O((n+m)logn)\)或者\(O((n+m)\alpha)\)求解一类如下问题:
在一张捕食图上(从捕食者向被捕食者有连边),若某生物的所有食物都灭绝了,则该生物灭绝。
灭绝树便是此图的一种生成树,使得满足灭绝树上某点灭绝,该点子树内所有点都灭绝
二、实现方式
把图分成以下几种情况考虑
树
本身就是自己的灭绝树
DAG
- [ZJOI2012]灾难
- [Codeforces757F]Team Rocket Rises Again
分以下几步
- 求出DAG的拓扑序
- 照拓扑序,从出度为0的点开始,某点的灭绝树上父亲就是该点在DAG上的所有出点 在灭绝树上的LCA
- 如果没有出度,连向一个虚拟点0方便计算
找LCA用倍增实现即可
一般有向图
例题:HDU4694 Important Sisters:求一般图每个点支配树上的祖先编号之和
\(orz\ Tarjan\)
首先把原图\(dfs\)一遍,求出\(dfn\)序
半支配点
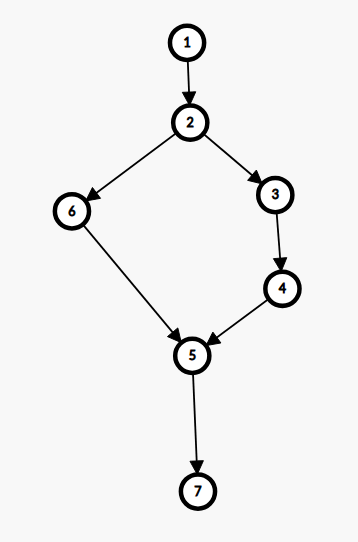
官方定义:\(semi[x]=min\{v |\)有路径\(v->v0->v1...->v_k->x\)使得\(dfn[v_i]>dfn[x]\)对\(1<=i<=k\)成立\(\}\),\(min\)指\(dfn\)最小
通俗一点:从\(semi[x]\)到\(x\)的路径,掐头去尾,都走的\(dfn\)大于\(x\)的点
画个图大概就是如下,\(dfn[]=\{0,1,2,3,4,5,7,6\}\),\(2->6->5\)掐头去尾的\(dfn\)都大于\(dfn[5]\)
重要性质:
以下祖先关系均指\(dfs\)树的祖先关系
- 1.不在\(dfs\)树上的边一定是由\(dfn\)大的点指向\(dfn\)小的点
- 2.\(semi[x]\)一定是\(x\)的祖先
- 3.在\(dfs\)树上从\(semi[x]\)向\(x\)连边,删掉其他边,灭绝关系不变
性感地理解就是:\(semi[x]\)到\(x\)的路径相当于是在\(dfs\)树外有一条路,且\(semi[x]\)是离根最近的那个点,从\(semi[x]\)都走不到\(x\)了,那其他的点更走不到了
由此可以得出一种做法,求出\(semi\)后转DAG的做法,复杂度\(O(nlogn)\)
求半支配点
十分的巧妙
按照\(dfn\)序从大到小做,对于\(x\),枚举\(R\)存在\(R->x\)这条边
for(int w=n;w>=2;w--)
{
int x=id[w],res=n;
for(int i=rA.head[x];i;i=rA.a[i].next)
{
int R=rA.a[i].to;//反图
if(!dfn[R]) continue;//有可能root不能走到y
if(dfn[R]<dfn[x]) res=min(res,dfn[R]);
else find(R),res=min(res,dfn[semi[mn[R]]]);
}
//anc[x]表示x在dfs树上的父亲
semi[x]=id[res];fa[x]=anc[x];B.link(semi[x],x);
}
其中\(find(R)\)表示路径压缩的带权并查集,维护\(R\)到其已经被搜过的祖先的 \(dfn\)的最小值\(mn[R]\),用\(semi[mn[R]]\)去更新\(semi[x]\)
然后例题就得到了一种\(O(nlog)\)的做法
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<queue>
#include<vector>
#include<cstring>
#define pb push_back
using namespace std;
const int N=1e5+10;
int n,m,ans[N],dfn[N],id[N],tot,dep[N];
int anc[N],fa[N],semi[N],mn[N],in[N],ff[20][N];
int q[N],top;
queue<int> Q;
vector<int> E[N];
struct Map
{
struct edge {int next,to;}a[N<<1];
int head[N],cnt;
void reset()
{
cnt=0;memset(head,0,sizeof(head));
}
void link(int x,int y) {a[++cnt]=(edge){head[x],y};head[x]=cnt;}
}A,rA,B,C;
void reset()
{
A.reset();rA.reset();B.reset();C.reset();
tot=top=0;
for(int i=1;i<=n;i++)
{
dfn[i]=id[i]=ans[i]=in[i]=anc[i]=dep[i]=0;
fa[i]=mn[i]=semi[i]=i;
E[i].clear();
for(int j=0;j<=18;j++) ff[j][i]=0;
}
}
void dfs(int x,int fr)
{
dfn[x]=++tot;id[tot]=x;
anc[x]=fr;B.link(fr,x);
for(int i=A.head[x];i;i=A.a[i].next)
if(!dfn[A.a[i].to]) dfs(A.a[i].to,x);
}
void dfscalc(int x,int fr)
{
ans[x]=x+ans[fr];
for(int i=C.head[x];i;i=C.a[i].next)
dfscalc(C.a[i].to,x);
}
int find(int x)
{
if(x==fa[x]) return x;
int tt=fa[x];fa[x]=find(fa[x]);
if(dfn[semi[mn[tt]]]<dfn[semi[mn[x]]]) mn[x]=mn[tt];
return fa[x];
}
int LCA(int x,int y)
{
if(dep[x]<dep[y]) swap(x,y);
int d=dep[x]-dep[y];
for(int i=18;i>=0;i--) if(d&(1<<i)) x=ff[i][x];
for(int i=18;i>=0;i--)
if(ff[i][x]^ff[i][y])
x=ff[i][x],y=ff[i][y];
return x==y?x:ff[0][x];
}
void Work()
{
dfs(n,0);
for(int w=n;w>=2;w--)
{
int x=id[w],res=n;
if(!x) continue;
for(int i=rA.head[x];i;i=rA.a[i].next)
{
int R=rA.a[i].to;
if(!dfn[R]) continue;
if(dfn[R]<dfn[x]) res=min(res,dfn[R]);
else find(R),res=min(res,dfn[semi[mn[R]]]);
}
semi[x]=id[res];fa[x]=anc[x];B.link(semi[x],x);
}
for(int x=1;x<=n;x++)
for(int i=B.head[x];i;i=B.a[i].next)
in[B.a[i].to]++,E[B.a[i].to].pb(x);
for(int x=1;x<=n;x++) if(!in[x]) Q.push(x);
while(!Q.empty())
{
int x=Q.front();Q.pop();q[++top]=x;
for(int i=B.head[x];i;i=B.a[i].next)
if(!--in[B.a[i].to]) Q.push(B.a[i].to);
}
for(int i=1;i<=top;i++)
{
int x=q[i],f=0,l=E[x].size();
if(l) f=E[x][0];
for(int j=1;j<l;j++) f=LCA(f,E[x][j]);
ff[0][x]=f;dep[x]=dep[f]+1;C.link(f,x);
for(int p=1;p<=18;p++) ff[p][x]=ff[p-1][ff[p-1][x]];
}
ans[0]=0;dfscalc(n,0);
}
int main()
{
while(scanf("%d%d",&n,&m)!=EOF)
{
reset();
for(int i=1,x,y;i<=m;i++)
scanf("%d%d",&x,&y),A.link(x,y),rA.link(y,x);
Work();
for(int i=1;i<n;i++) printf("%d ",ans[i]);
printf("%d\n",ans[n]);
}
return 0;
}
更高效的做法
性质
\(idom[x]\)表示\(x\)的支配点(灭绝树/支配树上的父亲)
- 若x是y的祖先,则要么\(x\)是\(idom[y]\)的祖先,要么\(idom[y]\)是\(idom[x]\)的祖先
可以这样性感地理解:如果\(x\)是祖先,那么\(x\)的食物来源(指向\(x\)的边)就少,相对来说灭绝掉\(x\)更容易,那么\(idom[x]\)会相应地靠近\(x\),同理\(y\)什么都吃所以夸张地说就是要把草给灭绝了\(y\)才会灭绝
然后看不懂了。。真的不可理解了。。而且发现上边一般图的做法我并不一定理解到位 丢个链接甩锅吧 https://www.cnblogs.com/fenghaoran/p/dominator_tree.html 应该很少会有这种毒瘤玩意,记得$O(nlogn)$的做法就好了,毕竟路径压缩并查集是可以被卡成$O(nlogn)$的:http://www.cnblogs.com/meowww/p/6475952.html

