第2讲——处理数据
一、学习新知识
我们记录一个信息,往往关注3个基本属性:信息将存储在哪里,要存储什么值,存储何种类型的信息。
例如,我今天的幸运数字是7,我想用程序记录下来:
int luck_ynum = 7;
这段代码告诉程序,它正在存储整数,并使用名称lucky_num来表示该整数的值(这里为7)。
实际上,程序将找到一块能够存储整数的内存,将该内存标记为lucky_num,并将7复制到该内存单元中;然后你可在程序中使用lucky_num来访问该内存单元,使用&运算符检索lucky_num的内存地址。
我知道整数类型不能存下太大的数,而且不同C++整型使用不同的内存量来存储整数。使用的内存量越大,可以表示的整数值范围也越大。有的类型(符号类型)可表示正值和负值,而有的类型(无符号类型)不能表示负值。
宽度:描述存储整数时使用的内存量。使用的内存越多,则越宽。
C++的基本整型(按宽度递增的顺序排列)分别是char、short、int、long long
我们知道,计算机内存由一些叫做位(bit)的单元组成,其中1字节=8位(即1B = 8bit)
C++的short、int、long long类型通过使用不同数目的位来存储值,例如,16位的int取值范围为-32768~32767 。
【程序1】
#include <iostream>
#include <climits> //包含了关于整型限制的信息
using namespace std;
int main()
{
int n_int = INT_MAX; //int的最大取值
long long n_long = LLONG_MAX;
cout<<"int is "<<sizeof(int)<<" bytes."<<endl;
cout<<"int's maxinum value is "<<n_int<<endl;
cout<<"long long's maxinum value is "<<n_long<<endl;
return 0;
}
程序运行结果是:
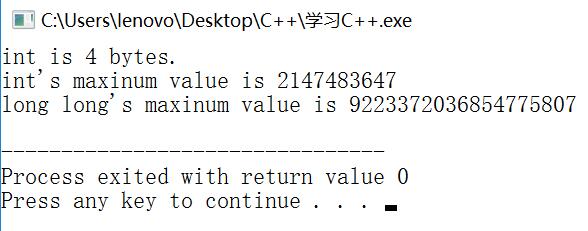
sizeof运算符返回类型或变量的长度,单位为字节。
“字节”的含义依赖于实现,因为在不同的系统中,int可能为16位,也可能为32位。
【头文件climits】
头文件climits定义了符号常量来表示类型的限制。
如符号常量:CHAR_BIT,CHAR_MAX,CHAR_MIN,INT_MAX,INT_MIN分别表示char的位数、char的最大/值以及int的最大/小值。
【符号常量——预处理器方式】
climits文件中的符号常量INT_MAX与“#define INT_MAX 32767”用法类似。
我们知道,在C++编译过程中,首先将源代码传递给预处理器。在这里,#define和#include一样,也是一个预处理器编译指令。
#define——预处理器编译指令
该编译指令告诉预处理器:在程序中查找INT_MAX,并将所有的INT_MAX都替换为32767.修改后的程序将在完成这些替换后被编译。
【整型字面值】
C++能够以三种不同的计数方式来书写整数:基数为10、基数为8、基数为16。
【程序2】
#include <iostream>
using namespace std;
int main()
{
int ten = 42;
int eight = 042; //4x8+2x1 = 34
int sixteen = 0x42; //4x16+2x1 = 66
cout<<"ten = "<<ten<<" (42 in decimal)"<<endl;
cout<<"eight = "<<eight<<" (042 in octal)"<<endl;
cout<<"sixteen = "<<sixteen<<" (0x42 in hex)"<<endl;
return 0;
}
cout将以十进制显示整数。
下面来看最后一个整型:char类型。char类型专为存储字符(如字母和数字)而设计的。
编程语言通过使用字母的数值编码来存储字母,故而char是另一种整型,它足够长,能够表示计算机系统中的所有基本符号(所有的字母、数字、标点符号等)。因为许多系统支持的字符都不超过128个,因此用一个字节就可以表示所有的符号。
我们最常用的符号集是ASCII字符集。字符集中的字符用数值编码(ASCII码)表示(如字符A的编码为65)。
【程序3】
#include <iostream>
using namespace std;
int main()
{
char ch;
cout<<"Enter a character: ";
cin>>ch;
cout<<"Hola!Thank you for the "<<ch<<" character."<<endl;
return 0;
}
注意,若我们输入的是字符'A',那么变量ch中存的值为65,然而程序将打印A,这是因为cin和cout帮我们完成了转换工作。
输入时,cin将键盘输入的A转换为65;输出时,cout将值65转换为所显示的字符A。
cin和cout的行为都是由变量类型引导的。
如果我们非要将字符的数值打印出来呢??
【程序4】
#include <iostream>
using namespace std;
int main()
{
char ch = 'A';
int i = ch;
cout<<"The ASCII code for "<<ch<<" is "<<i<<endl;
return 0;
}
此外,介绍一个函数:cout.put(),该函数显示一个字符。
【程序5】
#include <iostream>
using namespace std;
int main()
{
char ch = 'A';
cout.put(ch); //输出A
cout.put('!'); //输出!
return 0;
}
很尴尬,在这要讲解这个函数。
函数cout.put()是一个重要的C++OOP概念——成员函数——的第一个例子。类定义了如何表示和控制数据。成员函数归类所有,描述了操纵类数据的方法。例如类ostream有一个put()成员函数,用来输出字符。只能通过类的特定对象(例如这里的cout对象)来使用成员函数。要通过对象(如cout)使用成员函数,必须用句点将对象名和函数名称连接起来。句点被称为成员运算符。cout.put()的意思是,通过类对象cout来使用函数put()。
现在,我们只要知道:cout.put()成员函数提供了另一种显示字符的方法,可以替代<<运算符。
【const限定符】
处理符号常量的另一种方法:使用const限定符
如:const int N = 100;
注意,常量N被初始化后,其值就被固定了,编译器将不允许再修改该常量的值。
好处:明确指定类型;可以使用C++的作用域规则将定义限定在特定的函数或文件中;可以将const用于更复杂的类型(如数组、结构)。
【浮点数】
学习完C++整型,我们就来到浮点类型喽!!!
浮点数能够表示带小数部分的数字,它们提供的值范围也更大。如果数字很大,无法表示为long类型,则可以使用浮点类型来表示。
来一段比较官方的讲解:
计算机将带小数部分的数字分为两部分存储,一部分表示值,另一部分用于对值进行放大或缩小。下面打个比方,对于数字34.1245和34124.5,它们除了小数点的位置不同外,其他都是相同的。可以把第一个数表示为0.341245(基准值)和100(缩放因子),而将第二个数表示为0.341245(基准值相同)和10000(缩放因子更大)。缩放因子的作用是移动小数点的位置,术语浮点因此而得名。C++内部表示浮点数的方法与此相同,只不过它基于的是二进制数,因此缩放因子是2的幂,不是10的幂。我们不必了解内部表示。
官方腔调结束。。。
我们只要知道:浮点数能表示小数值、非常大和非常小的值。它们的内部表示方法与整数有天壤之别。
C++的两种书写浮点数的方式:第一种是使用常用的标准小数点表示法(如12.34,0.00023,8.0),第二种是使用E表示法(如7E5,2.52e+8,8.33E-4,9.11e-31)
C++有3种浮点类型:float、double和long double。这些类型是按它们可以表示的有效数位和允许的指数最小范围来描述的。有效位是数字中有意义的位(例如,加利福尼亚的Shasta山脉的高度为14179英尺,该数字使用了5个有效位,如果写成14000英尺,那么有效位就为2位)。
由上面我们知道了float和double类型及它们表示数字时在精度方面的差异(即有效位数)。
【程序6】
#include <iostream>
using namespace std;
int main()
{
cout.setf(ios_base::fixed, ios_base::floatfield); //使输出使用定点表示法
float tub = 10.0/3.0; //初始化为3.3333333333……
double mint = 10.0/3.0; //初始化为3.3333333333……
const float million = 1.0e6;
cout<<"tub = "<<tub<<endl; //输出3.333333
cout<<"a million tubs = "<<million*tub<<endl; //输出3333333.250000 而不是3333333.333333 更不是3333333.25
cout<<"ten million tubs = "<<10*million*tub<<endl; //输出33333332.000000 而不是33333332
cout<<"mint = "<<mint<<endl; //输出3.333333
cout<<"a million mints = "<<million*mint<<endl; //输出3333333.333333
return 0;
}
程序输出为:
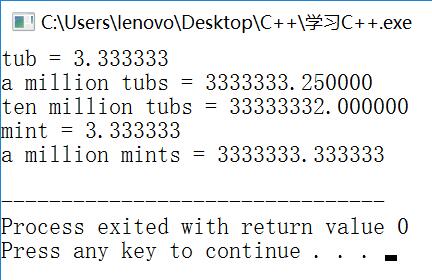
cout会删除结尾的0(例如,将3333333.250000显示为3333333.25),调用cout.setf()将覆盖这种行为。因为cout打印6位小数,于是tub和mint都是精确的,但当程序将每个数乘以一百万后,tub在第7个3之后就与正确的值有了误差,那么我就知道了float至少有6位有效位,而mint显示了13个3,这是因为double至少有15位有效位。所以,float的精度限制是比double的精度限制低的。
cout.setf()函数是ostream中的方法,这种调用迫使输出使用定点表示法,以便更好地了解精度,它防止程序将较大的值切换为E表示法,并使程序显示到小数点后6位。参数ios_base::fixed和ios_base::floatfield是通过包含iostream来提供的常量。
【强制类型转换】
强制类型转换不会修改apple变量本身,而是创建一个新的、指定类型的值,可以在表达式中使用这个值。
第一种方法
int apple;
(long)apple; //形式一
long(apple); //形式二
cout<<int('Q');
第二种方法
int apple; static_cast<long>(apple);
第一种方法来自C语言,我们认为它有过多的可能性而极其危险,而运算符static_cast<>比传统强制类型转换更严格。
【auto声明】
作用:使编译器能够根据初始值的类型推断变量的类型。
auto n = 100; //n是int因为100是int auto x = 1.5; //x是double vector<double> scores; auto it = scores.begin(); //it是迭代器
二、温故而知新
1. 语句“char grade = 65”与语句“char grade = 'A'”是否等价?
这两条语句并不真正等价,虽然对于某些系统来说,它们是等效的。最重要的是,只有在使用ASCII码的系统上,第一条语句才将得分设置为字母A,而第二条语句还可用于使用其他编码的系统。其次,65是一个int常量,而'A'是一个char常量。
【请用至少两种方法找出编码88表示的字符】


//way 1 char c = 88; cout<<c<<endl; //way 2 cout<<(char)88<<endl; //way 3 cout<<char(88)<<endl; //way 4 cout.put(char(88));
2. 假设x1和x2是两个double变量,您要将它们作为整数相加,再将结果赋给一个整型变量。请编写一条完成这项任务的C++语句。如果要将他们作为double值相加并转换为int呢?
//下面的代码用于完成第一个任务 int pos = (int)x1 + (int)x2; int pos = int(x1) + int(x2); //要将它们作为double类型相加,再进行转换,可采取下述方式之一: int pos = (int)(x1+x2); int pos = int(x1+x2);
3. 将long值赋给float变量会导致舍入误差,将long值赋给double变量呢?将long long值赋给double变量呢?
这个问题的答案取决于这两个类型的长度。如果long为4个字节,则没有损失。因为最大的long值将是20亿,即有10位数。由于double提供了至少13位有效数字,因而不需要进行任何舍入。long long类型可提供19位有效数字,超过了double保证的13位有效数字。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号