数据结构4——并查集(入门)
一、问题引入
题意:首先在地图上给你若干个城镇,这些城镇都可以看作点,然后告诉你哪些对城镇之间是有道路直接相连的。最后要解决的是整幅图的连通性问题。比如随意给你两个点,让你判断它们是否连通,或者问你整幅图一共有几个连通分支,也就是被分成了几个互相独立的块。像畅通工程这题,问还需要修几条路,实质就是求有几个连通分支。如果是1个连通分支,说明整幅图上的点都连起来了,不用再修路了;如果是2个连通分支,则只要再修1条路,从两个分支中各选一个点,把它们连起来,那么所有的点都是连起来的了;如果是3个连通分支,则只要再修两条路……
说明:输入4 2 1 3 4 3。即一共有4个点,2条路。下面两行告诉你,1、3之间有条路,4、3之间有条路。那么整幅图就被分成了1-3-4和2两部分。只要再加一条路,把2和其他任意一个点连起来,畅通工程就实现了,那么这个这组数据的输出结果就是1。好了,现在编程实现这个功能吧,城镇有几百个,路有不知道多少条,而且可能有回路。 这可如何是好? 我以前也不会呀,自从用了并查集之后,嗨,效果还真好!
二、故事描述
并查集由一个整数型的数组和两个函数构成。数组pre[]记录了每个点的前导点是什么,函数find是查找,函数join是合并。
话说江湖上散落着各式各样的大侠,有上千个之多。他们没有什么正当职业,整天背着剑在外面走来走去,碰到和自己不是一路人的,就免不了要打一架。但大侠们有一个优点就是讲义气,绝对不打自己的朋友。而且他们信奉“朋友的朋友就是我的朋友”,只要是能通过朋友关系串联起来的,不管拐了多少个弯,都认为是自己人。这样一来,江湖上就形成了一个一个的群落,通过两两之间的朋友关系串联起来。而不在同一个群落的人,无论如何都无法通过朋友关系连起来,于是就可以放心往死了打。但是两个原本互不相识的人,如何判断是否属于一个朋友圈呢? 我们可以在每个朋友圈内推举出一个比较有名望的人,作为该圈子的代表人物,这样,每个圈子就可以这样命名“齐达内朋友之队”“罗纳尔多朋友之队”……两人只要互相对一下自己的队长是不是同一个人,就可以确定敌友关系了。 但是还有问题啊,大侠们只知道自己直接的朋友是谁,很多人压根就不认识队长,要判断自己的队长是谁,只能漫无目的的通过朋友的朋友关系问下去:“你是不是队长?你是不是队长?” 这样一来,队长面子上挂不住了,而且效率太低,还有可能陷入无限循环中。于是队长下令,重新组队。队内所有人实行分等级制度,形成树状结构,我队长就是根节点,下面分别是二级队员、三级队员。每个人只要记住自己的上级是谁就行了。遇到判断敌友的时候,只要一层层向上问,直到最高层,就可以在短时间内确定队长是谁了。由于我们关心的只是两个人之间是否连通,至于他们是如何连通的,以及每个圈子内部的结构是怎样的,甚至队长是谁,并不重要。所以我们可以放任队长随意重新组队,只要不搞错敌友关系就好了。于是,门派产生了。 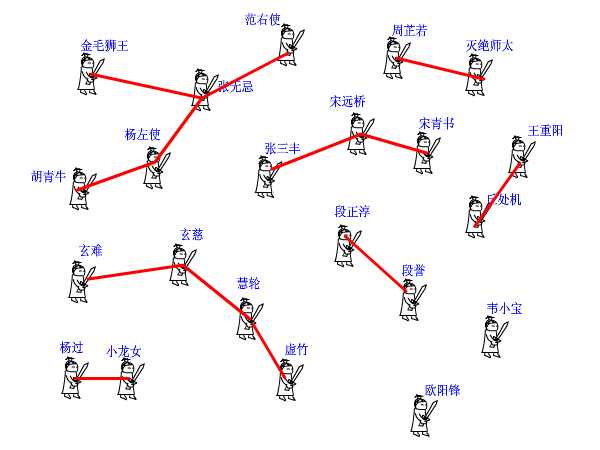
下面我们来看并查集的实现。 int pre[1000]; 这个数组,记录了每个大侠的上级是谁。大侠们从1或者0开始编号(依据题意而定),pre[15]=3就表示15号大侠的上级是3号大侠。如果一个人的上级就是他自己,那说明他就是掌门人了,查找到此为止。也有孤家寡人自成一派的,比如欧阳锋,那么他的上级就是他自己。每个人都只认自己的上级。比如胡青牛同学只知道自己的上级是杨左使。张无忌是谁?不认识!要想知道自己的掌门是谁,只能一级级查上去。 find这个函数就是找掌门用的,意义再清楚不过了(路径压缩算法先不论,后面再说)。
int find(int x) //查找x的掌门
{
int r=x; //委托 r 去找掌门
while(pre[r] != r) //如果r的上级不是r自己(也就是说找到的大侠他不是掌门 = =)
r = pre[r] ; // r 接着找他的上级,直到找到掌门为止。
return r ; //掌门驾到~~~
}
再来看看join函数,就是在两个点之间连一条线,这样一来,原先它们所在的两个板块的所有点就都可以互通了。这在图上很好办,画条线就行了。但我们现在是用并查集来描述武林中的状况的,一共只有一个pre[]数组,该如何实现呢? 还是举江湖的例子,假设现在武林中的形势如图所示。虚竹小和尚与周芷若MM是我非常喜欢的两个人物,他们的终极boss分别是玄慈方丈和灭绝师太,那明显就是两个阵营了。我不希望他们互相打架,就对他俩说:“你们两位拉拉勾,做好朋友吧。”他们看在我的面子上,同意了。这一同意可非同小可,整个少林和峨眉派的人就不能打架了。这么重大的变化,可如何实现呀,要改动多少地方?其实非常简单,我对玄慈方丈说:“大师,麻烦你把你的上级改为灭绝师太吧。这样一来,两派原先的所有人员的终极boss都是师太,那还打个球啊!反正我们关心的只是连通性,门派内部的结构不要紧的。”玄慈一听肯定火大了:“我靠,凭什么是我变成她手下呀,怎么不反过来?我抗议!”抗议无效,上天安排的,最大。反正谁加入谁效果是一样的,我就随手指定了一个。这段函数的意思很明白了吧?
void join(int x,int y) //我想让虚竹和周芷若做朋友
{
int fx=find(x), fy=find(y); //虚竹的老大是玄慈,芷若MM的老大是灭绝
if(fx != fy) //玄慈和灭绝显然不是同一个人
pre[fx]=fy; //方丈只好委委屈屈地当了师太的手下啦
}
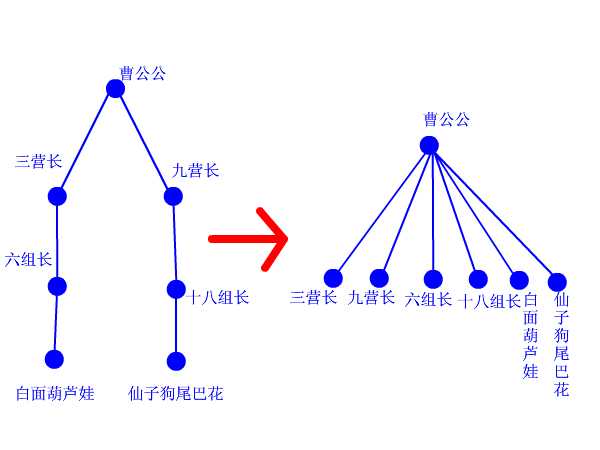
再来看看路径压缩算法。建立门派的过程是用join函数两个人两个人地连接起来的,谁当谁的手下完全随机。最后的树状结构会变成什么样,我也完全无法预计,一字长蛇阵也有可能。这样查找的效率就会比较低下。最理想的情况就是所有人的直接上级都是掌门,一共就两级结构,只要找一次就找到掌门了。哪怕不能完全做到,也最好尽量接近。这样就产生了路径压缩算法。 设想这样一个场景:两个互不相识的大侠碰面了,想知道能不能揍。 于是赶紧打电话问自己的上级:“你是不是掌门?” 上级说:“我不是呀,我的上级是谁谁谁,你问问他看看。” 一路问下去,原来两人的最终boss都是东厂曹公公。 “哎呀呀,原来是记己人,西礼西礼,在下三营六组白面葫芦娃!” “幸会幸会,在下九营十八组仙子狗尾巴花!” 两人高高兴兴地手拉手喝酒去了。 “等等等等,两位同学请留步,还有事情没完成呢!”我叫住他俩。 “哦,对了,还要做路径压缩。”两人醒悟。 白面葫芦娃打电话给他的上级六组长:“组长啊,我查过了,其习偶们的掌门是曹公公。不如偶们一起直接拜在曹公公手下吧,省得级别太低,以后查找掌门麻环。” “唔,有道理。” 白面葫芦娃接着打电话给刚才拜访过的三营长……仙子狗尾巴花也做了同样的事情。 这样,查询中所有涉及到的人物都聚集在曹公公的直接领导下。每次查询都做了优化处理,所以整个门派树的层数都会维持在比较低的水平上。路径压缩的代码,看得懂很好,看不懂也没关系,直接抄上用就行了。总之它所实现的功能就是这么个意思。
三、算法描述
关键特征:
①用集合中的某个元素来代表这个集合,该元素称为集合的代表元;
②一个集合内的所有元素组织成以代表元为根的树形结构;
③对于每一个元素 pre[x]指向x在树形结构上的父亲节点。如果x是根节点,则令pre[x] = x;
④对于查找操作,假设需要确定x所在的的集合,也就是确定集合的代表元。可以沿着pre[x]不断在树形结构中向上移动,直到到达根节点。
判断两个元素是否属于同一集合,只需要看他们的代表元是否相同即可。
路径压缩:
为了加快查找速度,查找时将x到根节点路径上的所有点的pre(上级)设为根节点,该优化方法称为压缩路径。使用该优化后,平均复杂度可视为Ackerman函数的反函数,实际应用中可粗略认为其是一个常数。
用途:
1、维护无向图的连通性。支持判断两个点是否在同一连通块内,和判断增加一条边是否会产生环。
2、用在求解最小生成树的Kruskal算法里。
一般来说,一个并查集对应三个操作:初始化+查找根结点函数+合并集合函数
【初始化】
包括对所有单个的数据建立一个单独的集合(即根据题目的意思自己建立的最多可能有的集合,为下面的合并查找操作提供操作对象)。
在每一个单个的集合里面,有三个东西。
①集合所代表的数据(这个初始值根据需要自己定义,不固定) ;
②这个集合的层次通常用rank表示(一般来说,初始化的工作之一就是将每一个集合里的rank置为1);
③这个集合的类别pre(其实就是一个指针,用来指示这个集合属于那一类,合并过后的集合,他们的pre指向的最终值一定是相同的) (有的简单题里面集合的数据就是这个集合的标号,也就是说只包含2和3,1省略了)。
初始化的时候,每一个集合的pre都是这个集合自己的标号。没有跟它同类的集合,那么这个集合的源头只能是自己了。
最简单的集合就只含有这三个东西了,当然,复杂的集合就是把3指针这一项添加内容,如PKU食物链那题,我们还可以添加enemy指针,表示这个物种集合的天敌集合;food指针,表示这个物种集合的食物集合。随着指针的增加,并查集操作起来也变得复杂,题目也就显得更难了。
数组表示法
设置很多相同大小的数组,如:
int pre[max]; //集合index的类别,或者用parent表示
int rank[max]; //集合index的层次,通常初始化为0
int data[max]; //集合index的数据类型
//初始化集合
void Make_pre(int i)
{
pre[i]=i; //一个集合的pre都是这个集合自己的标号。没有跟它同类的集合,那么这个集合的源头只能是自己了。
rank[i]=0;
}
【查找函数】
就是找到pre指针的源头,可以把函数命名为find_pre,如果集合的pre等于集合的编号(即还没有被合并或者没有同类),那么自然返回自身编号。 如果不同(即经过合并操作后指针指向了源头(合并后选出的rank高的集合))那么就可以调用递归函数,如下面的代码:
//查找集合i(一个元素是一个集合)的源头(递归实现)
int Find_pre(int i)
{
//如果集合i的父亲是自己,说明自己就是源头,返回自己的标号
if(pre[i]==i)
return pre[i];
//否则查找集合i的父亲的源头
return Find_pre(pre[i]);
}
【合并集合函数】
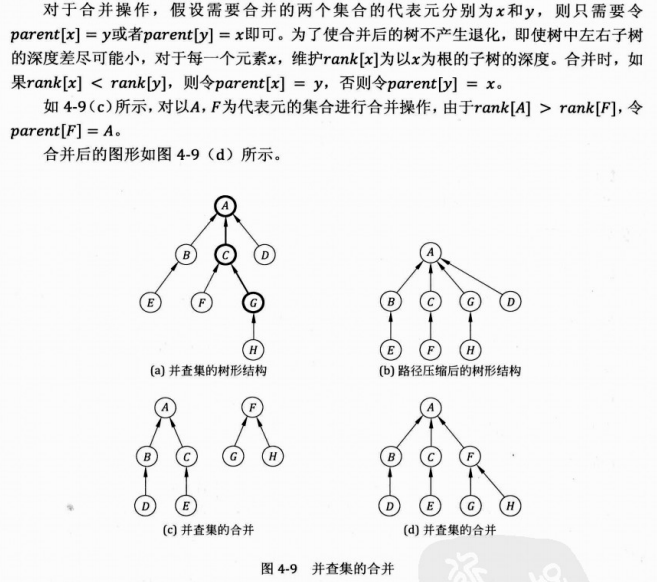
这就是所谓并查集的并了。至于怎么知道两个集合是可以合并的,那就是题目的条件了。先看代码:
void Union(int i,int j)
{
i=Find_pre(i);
j=Find_pre(j);
if(i==j) return ;
if(rank[i]>rank[j]) pre[j]=i;
else
{
if(rank[i]==rank[j]) rank[j]++;
pre[i]=j;
}
}
四、代码实现
#define N 105
int pre[N]; //每个结点
int rank[N]; //树的高度
//初始化
int init(int n) //对n个结点初始化
{
for(int i = 0; i < n; i++){
pre[i] = i; //每个结点的上级都是自己
rank[i] = 1; //每个结点构成的树的高度为1
}
}
int find_pre(int x) //查找结点x的根结点
{
if(pre[x] == x){ //递归出口:x的上级为x本身,即x为根结点
return x;
}
return find_pre(pre[x]); //递归查找
}
//改进查找算法:完成路径压缩,将x的上级直接变为根结点,那么树的高度就会大大降低
int find_pre(int x) //查找结点x的根结点
{
if(pre[x] == x){ //递归出口:x的上级为x本身,即x为根结点
return x;
}
return pre[x] = find_pre(pre[x]); //递归查找 此代码相当于 先找到根结点rootx,然后pre[x]=rootx
}
bool is_same(int x, int y) //判断两个结点是否连通
{
return find_pre(x) == find_pre(y); //判断两个结点的根结点(亦称代表元)是否相同
}
void unite(int x,int y)
{
int rootx, rooty;
rootx = find_pre(x);
rooty = find_pre(y);
if(rootx == rooty){
return ;
}
if(rank(rootx) > rank(rooty)){
pre[rooty] = rootx; //令y的根结点的上级为rootx
}
else{
if(rank(rootx) == rank(rooty)){
rank(rooty)++;
}
pre[rootx] = rooty;
}
}
后记:写到这里,并查集只是入了门,还有一些知识点在下篇文章——并查集(进阶)中讲解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号