
周测5
一、单选
1、下列关于栈的叙述正确的是()
A、栈是非线性结构
B、栈是一种树状结构
C、栈具有先进先出的特征
D、栈有后进先出的特征
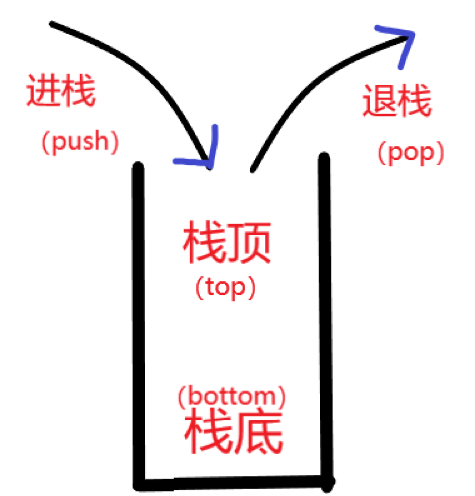
-
栈作为一种数据结构,是一种只能在一端进行插入和删除操作的特殊线性表。它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。
栈具有记忆作用,对栈的插入与删除操作中,不需要改变栈底指针。
允许进行插入和删除操作的一端称为栈顶(top),另一端为栈底(bottom);栈底固定,而栈顶浮动;栈中元素个数为零时称为空栈。插入一般称为进栈(push),删除则称为退栈(pop)。栈也称为先进后出表。
2、链表不具有的特点是()
A、不必事先估计存储空间
B、可随机访问任一元素
C、插入删除不需要移动元素
D、所需空间与线性表长度成正比
-
链表是用指针来指向元素的值,所有的操作都是通过移动指针来进行的,本身的元素不需要移动。
数据在内存中的地址(即物理地址)不一定连续,但是他们的逻辑地址是连续的。
插入或者删除时,改变的是指向数据的指针,其元素都是不变的。
对于单链表来说,只有指向链表头的头指针,所以不能随机访问表内元素,只能通过指针的移动。
链表的存储空间是不需要事先估计的,他不是线性的,所以可以随着结点的增加而随时增加存储空间。
3、线性表若采用链式存储结构时,要求内存中可用存储单元的地址()
A、必须是连续的
B、部分地址必须是连续的
C、一定是不连续的
D、连续不连续都可以
4、下列叙述中,错误的是()
A、数据的存储结构与数据处理的效率密切相关
B、数据的存储结构与数据处理的效率无关
C、数据的存储结构在计算机中所占的空间不一定是连续的
D、一种数据的逻辑结构可以有多种存储结构
-
数据结构的定义:
数据的逻辑结构:反映数据元素之间的关系的数据元素集合的表示。包括集合、线形结构、树形结构和图形结构四种。
数据的存储结构:在计算机存储空间中的存放形式称为数据的存储结构。常用的有顺序、链接、索引等存储结构。
5、下列数据结构中,按先进后出原则组织数据的是()
A、线性链表
B、栈
C、循环链表
D、顺序表
6、下列关于栈的叙述中正确的是()
A、在栈中只能插入数据
B、在栈中只能删除数据
C、栈是先进先出的线性表
D、栈是先进后出的线性表
7、下列关于队列的叙述中正确的是()
A、在队列中只能插入数据
B、在队列中只能删除数据
C、队列是先进先出的线性表
D、队列是先进后出的线性表
先进先出链表是在尾部插入头部删除,先进后出链表是在头部插入头部删除
8、下列叙述中,正确的是()
A、线性链表中的各元素在存储空间中的位置必须是连续的
B、线性链表中的表头元素存储在内存中一定在其他元素的前面
C、线性链表中的各元素在存储空间中的位置不一定是连续的,但在内存中表头元素一定存储在其他元素的前面
D、线性链表中的各元素在存储空间中的位置不一定是连续的,且在内存中各元素的存储顺序也是任意的
-
线性表有顺序表和链表两种存储结构。
顺序表:线性表的结点按逻辑次序依次存放在一组地址连续的存储单元里的方法。
链表:用一组任意的存储单元来存放线性表的结点,这组存储单元既可以是连续的,也可以是不连续的
9、单列集合的顶层接口是()
A.java.util.Map
B.java.util.Collection
C.java.util.List
D.java.util.Set

10、ArrayList类的底层数据结构是()
A、数组结构
B、链表结构
C、哈希表结构
D、红黑树结构
-
底层实现:
ArrayList/Vector:数组
LinkedList:双链表存储
Stack:后进先出的堆栈
Queue:先进先出的队列
HashSet/HashMap/HashTable/ConcurrentHashMap:数组+链表+红黑树
LinkedHashSet/LinkedHashMap:链表
TreeSet:底层基于TreeMap实现
TreeMap:红黑树数据结构
11、LinkedList类的特点是()
A、查询快
B、增删快
C、元素不重复
D、元素自然排序
-
(1)有序,可重复
(2)底层使用双链表存储,所以查找慢(LinkedList不能随机访问,从开头或结尾遍历列表),添加和删除快(前提是找到指定位置或者找到指定元素后,添加和删除的操作快)
12、关于迭代器说法错误的是()
A、迭代器是取出集合元素的方式
B、迭代器的hasNext()方法返回值是布尔类型
C、List集合有特有迭代器
D、next()方法将返回集合中的上一个元素 下一个元素
13、对于HashMap集合说法正确的是()
A、底层是数组结构
B、底层是链表结构
C、可以存储null值和null键
D、不可以存储null值和null键
-
- 1.底层实现1.7之前:数组+链表 1.8以后:数组+链表+红黑树
- 2.key不允许重复,如果key的值相同,后添加的数据会覆盖之前的数据
14、在()中,只要指出表中任何一个结点的位置,就可以从它出发依次访问到表中其他所有结点。
A、线性单链表
B、双向链表
C、线性链表
D、循环链表
15、以下数据结构属于非线性数据结构的是()
A、队列
B、线性表
C、二叉树
D、栈
-
线性的数据结构有:线性表、栈、队列、双端队列、数组和串
非线性数据结构包括:多维数组、集合、树、Hash
16、LocalDateTime类型的日期格式化字符串使用哪个类()
A、Date
B、Calendar
C、SimpleDateFormat
D、DateTimeFormatter
17、LocalDate表示的是()
A、日期和时间
B、时间
C、日期
D、都不是
18、两个BigDecimal对象相加使用什么?()
A、+
B、add
C、subtract
D、divide
19、Math.ceil(2.365)()
A、2
B、2.37
C、2.4
D、3
20、使用File创建文件是使用哪个方法?()
A、mkdir()
B、mkdirs()
C、createNewFile()
D、以上都不对
21、使用File判断是否为目录使用哪个方法()
A、isFile()
B、isDirectory()
C、exists()
D、以上都不对
二、多选
1、重写equals和hashCode后,下面关于这两个方法说法正确的是()
A、两个对象的hashCode值相同,那么他们调用equals()方法返回值一定为true
B、两个对象的hashCode值相同,那么他们调用equals()方法返回值可以为false
C、两个对象的equals()方法返回值为true,那么hashCode值可以不同
D、只要重写equals方法,原则上就要重写hashCode方法
HashCode相同再判断equals,equals可以为true,也可以为false;但equals相同HashCode一定相同
2、Java中的集合类包括ArrayList、LinkedList、HashMap等类,下列关于集合类
描述正确的是()
A、ArrayList和LinkedList均实现了List接口
B、ArrayList的查询速度比LinkedList快
C、添加和删除元素时,ArrayList的表现更佳
D、HashMap实现Map接口,它允许任何类型的键和值对象,并允许将null用作键或值
3、下面关于Collection 和 Collections的区别错误的是()
A、Collections是集合顶层接口
B、Collection是针对Collections集合操作的工具类
C、List、Set、Map都继承自Collection接口
D、Collections是针对Collection集合操作的工具类
三、判断
1、栈和队列通常采用的存储结构是链式存储和顺序存储
A、对
B、错
2、当线性表采用顺序存储结构实现存储时,其主要特点是逻辑结构中相邻的结点在存储结构中仍相邻。
A、对
B、错
3、两个对象的hashCode值相同,那么他们调用equals()方法返回值必须为true
A、对
B、错
4、Vector是非线程安全的
A、对
B、错
多线程安全的
5、ArrayList底层是链表结构
A、对
B、错
数组结构
6、InputStreamReader是字节流通向字符流的桥梁,它使用指定的charset读取字节并将其解码为字符
A、对
B、错
7、? extends Number : 表示泛型必须是Number子类
A、对
B、错
Number或Number子类
8、流按照类型分为字节流和字符流
A、对
B、错
9、字节流继承inputStream和OutputStream,字符流继承自Reader和Writer
A、对
B、错
10、File类型中定义了mkdirs方法来创建多层目录
A、对
B、错
四、简答
1、编写一段程序完成文件的复制功能(使用FileOutputStream和FileInputStream)
public class TestFileCopy {
public static void main(String[] args) {
//定义FileInputStream类型变量
FileInputStream fis = null;
//定义FileOutputStream类型变量
FileOutputStream fos = null;
try {
//实例化FileInputStream文件输入流
fis = new FileInputStream("data.txt");
//实例化FileOutputStream文件输出流
fos = new FileOutputStream("data_copy.txt");
//定义byte数组存储读取的数据
byte[] bytes = new byte[1024];
int len = 0;
//循环读取数据到byte数组中
while ((len = fis.read(bytes)) != -1) {
//把byte数组中的数据写入到输出流文件中
fos.write(bytes, 0, len);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}2、将集合变量list中的重复元素去掉,保证如下list集合中添加顺序不变,不能使用循环遍历操作
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("b");
list.add("c");
list.add("b");
list.add("b");
list.add("b");
list.add("c");
list.add("c");
list.add("d");
list.add("c");
list.add("c");
list.add("c");
list.add("d");
list.add("d");
list.add("d");
list.add("d");
list.add("d");
单独定义方法去除重复,方法定义public void getSingle(ArrayList list);不能修改变方法的名称返回值和参数
public void getSingle(ArrayList<String> list) {
//1,创建一个LinkedHashSet集合
LinkedHashSet<String> lhs = new LinkedHashSet<>();
//2,将List集合中所以的元素添加到LinkedHashSet集合中
lhs.addAll(list);
//3,将List集合中的元素清除
list.clear();
//4,将LinkedHashSet集合中元素添加到List集合中
list.addAll(lhs);
}

