
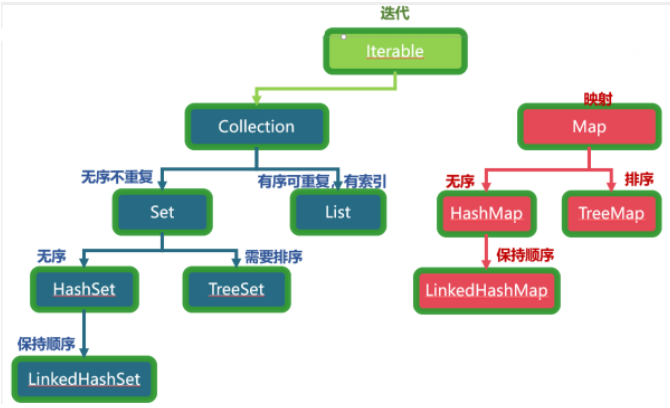
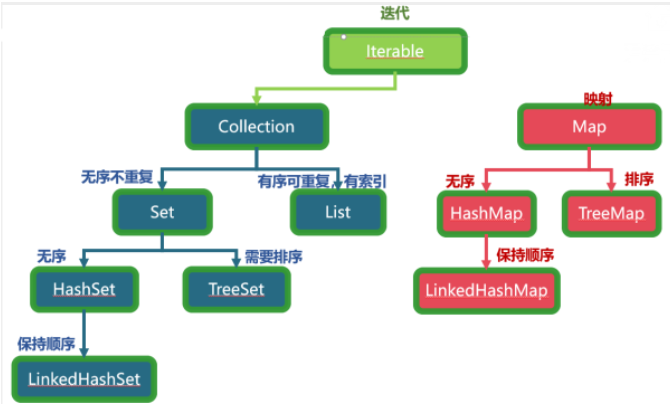
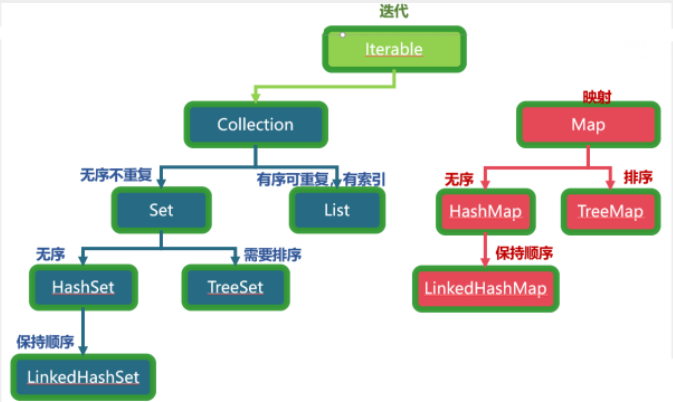
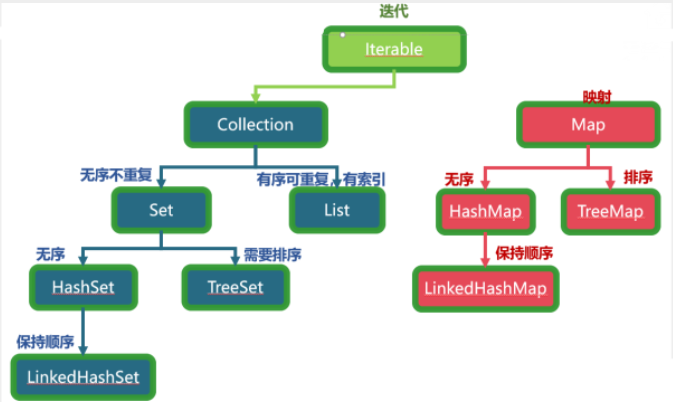
Collection集合
1.集合类介绍
-
为什么出现集合类:
面向对象语言对事物的体现都是以对象的形式,所以为了方便对多个对象的操作,就对对象进行存储,集合就是存储对象最常用的一种方式
-
数组和集合类同是容器,有何不同:
-
数组长度是固定的;集合长度是可变的。
-
数组中可以存储基本数据类型和引用数据类型,集合只能存储对象。
-
数组中存储数据类型是单一的,集合中可以存储任意类型的对象。
-
-
集合类的特点
集合只用于存储对象,集合长度是可变的,集合可以存储不同类型的对象。
2.Collection接口

2.1 Collection接口是最基本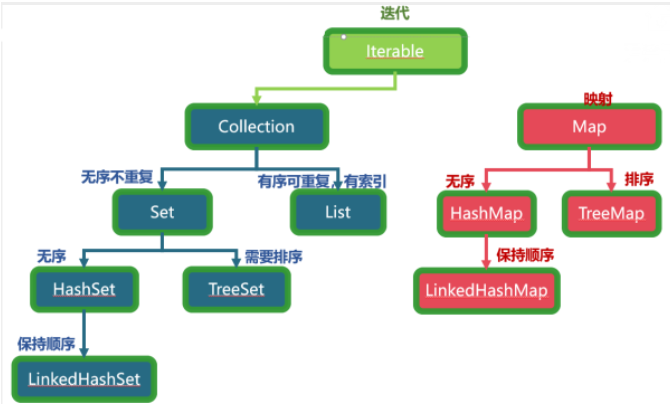 的集合接口
的集合接口
-
Collection接口不提供直接的实现,JavaSDK提供的类都是继承自Collection的“子接口”如List和Set。
-
Collection所代表的是一种规则,它所包含的元素都必须遵循一条或者多条规则。
-
Collection接口为集合提供一些统一的访问接口(泛型接口),覆盖了向集合中添加元素、删除元素以及协助对集合进行遍历访问的相关方法


2.2 Collection的遍历
-
使用增强型for遍历
-
使用增强型for循环进行Collection遍历的一般形式
for(元素类型 循环变量名 : Collection对象){ 对循环变量进行处理 }增强型 for 循环对数组的遍历一样,循环自动将 Collection 中的每个元素赋值给循环变量,在循环中针对该循环变量进行处理则就保证了对 Collection 中所有的元素进行逐一处理
-
-
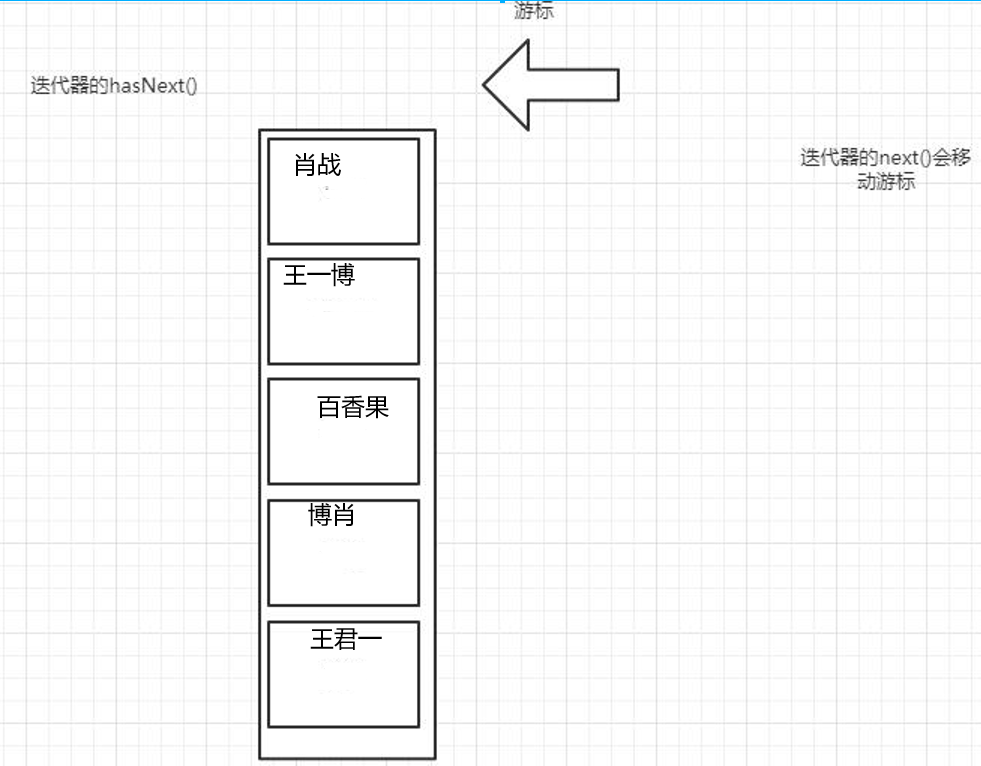
使用迭代器遍历
因为Collection中有iterator方法,所以每一个子类集合对象都具备迭代器
Iterator 变量名 = Collection对象.iterator(); while(变量名.hasNext()){ System.out.println(变量名.next()); }
3.List接口
3.1 List接口为Collection子接口。
-
List所代表的是有序的Collection
-
它用某种特定的插入顺序来维护元素顺序,同时可以根据元素的整数索引(在列表中的位置,和数组相似,从0开始,到元素个数-1)访问元素,并检索列表中的元素

-
List由于列表有序并存在索引,因此除了增强for循环进行遍历外,还可以使用普通的for循环进行遍历
2.2 List的常见实现类
3.2.1 List接口实现类-ArrayList
-
构造方法:

-
特点:
2.查找快,添加和删除慢(数组根据索引查找时间复杂度O(1),添加和删除ArrayList需要扩缩容)
3.创建ArrayList对象, 如果使用无参构造,创建的是空列表, 在添加第一个元素的时候,容量才初始化为10
4.存储数据当快溢出时,就会进行扩容操作,ArrayList的默认扩容扩展后数组大小为:原数组长度+(原数组长度>>1)
5.可添加重复元素,有序
6.ArrayList是一个非线程安全的列表
查看代码
import java.util.ArrayList; import java.util.Iterator; import java.util.List; public class ArrayListTest { public static void main(String[] args) { //接口编程 //构造方法一:给定容量 //List<String> list=new ArrayList(20); //无参构造方法,容量是空的,当添加一个元素时,容量是10 System.out.println("---list.size()---"); List<String> list = new ArrayList(); System.out.println(list.size());/**输出:0*/ System.out.println("---list.add()---"); //add往尾部添加元素 list.add("肖战"); list.add("王一博"); list.add("百香果"); System.out.println(list.size());/**输出:3*/ System.out.println("---list.get()---"); System.out.println(list.get(1));/**输出:王一博*/ System.out.println("---list.contains(\"百香果\")---");//转义\" System.out.println(list.contains("百香果"));/**输出:true*/ System.out.println("---list.set(1,\"博肖\")---"); list.set(1, "博肖"); System.out.println(list.get(1));/**输出:博肖*/ System.out.println("---指定位置插入---"); list.add(1, "王君一");//指定位置添加插入元素 System.out.println(list.get(1));/**输出:王君一*/ System.out.println(list.size());/**输出:4*/ System.out.println("---for i遍历---"); for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); } System.out.println("---remove---"); //按照对象删除,返回值是Boolean值 //System.out.println(list.remove("pq"));/*true*/ //按照索引删除,返回值是删除对象 System.out.println(list.remove(1));/**输出:王君一*/ System.out.println("---增强for循环遍历---"); //增强for本质是iterator迭代器,增强for是语法糖 for (String s : list) { System.out.println(s); } List<String> list1 = new ArrayList<>(); list1.add("啵比"); list1.add("赞比"); list.addAll(list1); System.out.println("---迭代器遍历---"); //获取迭代器 Iterator<String> iterator = list.iterator(); //iterator.hasNext(),返回Boolean值,判断是否有下一个元素 int i = 1;//游标 while (iterator.hasNext()) { //获取下一个元素,要迭代器遍历,一定要调用next方法,保证游标移动,如果游标不移动iterator.next()永远是true System.out.println(iterator.next()); System.out.println(i); if (i == 10) { break; } i++; } System.out.println("---list.subList(1,3)----"); //fromIndex(包括)和toIndex(不包括)索引之间的数据 List<String> list3 = list.subList(1, 3);//左闭右开 for (String s : list3) { System.out.println(s); } System.out.println("---遍历过程中删除---"); /*增加for循环不能边遍历边删除 异常:java.util.ConcurrentModificationException for (String s:list) { System.out.println(s); list.remove(s); }*/ /*从前往后删除 System.out.println("删前:"+list.size()); int size=list.size(); for (int j = 0; j < size; j++) { System.out.println(list.get(0)); list.remove(0); } System.out.println("删后:"+list.size()); */ //从后往前删除 System.out.println("删前:" + list.size()); for (int j = list.size() - 1; j >= 0; j--) { System.out.println(list.get(j)); list.remove(j); } System.out.println("删后:" + list.size()); System.out.println("---迭代器删除---"); //边遍历边删除推荐用迭代器,只要动游标就可删除 System.out.println("删前:" + list1.size()); Iterator<String> iterator1 = list1.iterator(); while (iterator1.hasNext()) { String next = iterator1.next(); System.out.println(next); iterator1.remove(); } System.out.println("删后:" + list1.size()); } }
-



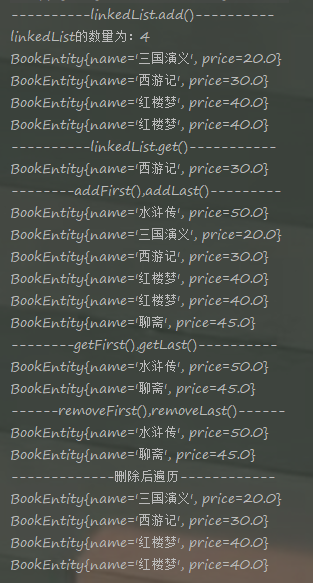
3.2.2 LinkedList
-
LinkedList类位置java.util.包,它是List下面的类。找头和尾非常快,效率高,查询少

-
构造方法

-
特点
(1)有序,可重复
(2)底层使用双链表存储,所以查找慢(LinkedList不能随机访问,从开头或结尾遍历列表),添加和删除快
(3)LinkedList也是非同步的
-
案例
查看代码
public class BookEntity { private String name; private double price; public BookEntity(String name, double price) { this.name = name; this.price = price; } public String getName() {return name; } public void setName(String name) {this.name = name;} public double getPrice() {return price;} public void setPrice(double price) {this.price = price;} @Override public String toString() { return "BookEntity{" + "name='" + name + '\'' + ", price=" + price + '}'; } } import com.BookEntity; import java.util.LinkedList; public class LinkedListTest { public static void main(String[] args) { LinkedList<BookEntity> linkedList = new LinkedList<>(); BookEntity be1 = new BookEntity("三国演义", 20); BookEntity be2 = new BookEntity("西游记", 30); BookEntity be3 = new BookEntity("红楼梦", 40); BookEntity be4 = be3; System.out.println("----------linkedList.add()----------"); linkedList.add(be1); linkedList.add(be2); linkedList.add(be3); linkedList.add(be4);//添加重复元素,List可添加 System.out.println("linkedList的数量为:" + linkedList.size()); for (BookEntity be : linkedList) { System.out.println(be); } System.out.println("----------linkedList.get()-----------"); System.out.println(linkedList.get(1)); System.out.println("--------addFirst(),addLast()---------"); BookEntity be5 = new BookEntity("水浒传", 50); BookEntity be6 = new BookEntity("聊斋", 45); linkedList.addFirst(be5); linkedList.addLast(be6); for (BookEntity be : linkedList) { System.out.println(be); } System.out.println("--------getFirst(),getLast()----------"); System.out.println(linkedList.getFirst()); System.out.println(linkedList.getLast()); System.out.println("------removeFirst(),removeLast()------"); System.out.println(linkedList.removeFirst());//返回删除的元素 System.out.println(linkedList.removeLast()); System.out.println("-------------删除后遍历------------"); for (BookEntity be : linkedList) { System.out.println(be); } } }
3.2.3 Vector
-
Vector类位置java.util.Vector
-
Interface Enumeration<E>是接口

-
1.Vector与ArrayList相似,操作几乎一样,但是Vector是同步的。所以说Vector是使用数组实现的线程安全的列表;
2.Vector在进行默认规则扩容时,新数组的长度=原始数组长度*2,也可以指定扩容长度;
3.创建对象的时候初始化长度为10。
-
案例
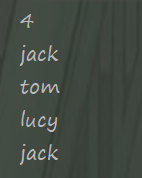
import java.util.Enumeration; import java.util.Vector; public class VectorTest { public static void main(String[] args) { Vector<String> vector = new Vector<>(); vector.add("jack"); vector.add("tom"); vector.add("lucy"); vector.add("jack"); System.out.println(vector.size()); //获取Enumeration接口对象 Enumeration<String> elements = vector.elements(); while (elements.hasMoreElements()) { String s = elements.nextElement(); System.out.println(s); } } }
-
说出ArrayList与Vector的区别?
相同点:ArrayList与Vector的底层都是由数组实现的。
不同点:1、ArrayList不同步,线程相对不安全,效率相对高;Vector同步的,线程相对安全,效率相对较低。
2、ArrayList是JDK1.2出现的。Vector是jdk1.0的时候出现的。
3、扩容方式:ArrayList扩容方式:原来数组长度1.5倍
Vector扩容方式: 默认是原来数组长度的2倍
4、实现方法不同
3.2.4 Stack
-
Stack继承自Vector,实现一个后进先出(先进后出)的堆栈
-
Stack提供5个额外的方法使得Vector得以被当作堆栈使用。
基本的push和pop 方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置
-
Stack刚创建后是空栈
-
案例
查看代码
import java.util.Iterator; import java.util.Stack; public class StackTest { public static void main(String[] args) { Stack<Integer> stack = new Stack<>(); stack.add(85); //入栈 stack.push(95);//添加 stack.push(105); System.out.println("----获取栈顶元素---"); Integer stackUpElement = stack.peek(); System.out.println(stackUpElement);/*输出:105*/ System.out.println("-----遍历栈-----"); Iterator<Integer> iterator = stack.iterator(); while (iterator.hasNext()) { Integer next = iterator.next(); System.out.println(next); }/*输出:85 95 105*/ System.out.println("---少栈顶元素---"); //出栈,stack中少一个元素,少栈顶元素 Integer pop = stack.pop(); System.out.println(pop);/*输出:105*/ System.out.println("---出栈---"); Iterator<Integer> iterator1 = stack.iterator(); while (iterator1.hasNext()) { Integer next = iterator1.next(); System.out.println(next); }/*输出:85 95*/ } }

3.2.5 Queue
-
队列是一种先进先出的数据结构,元素在队列末尾添加,在队列头部删除。Queue接口扩展自Collection,并提供插入、提取、检验等操作
-
接口Deque,是一个扩展自Queue的双端队列,它支持在两端插入和删除元素,因为LinkedList类实现了Deque接口,所以通常我们可以使用LinkedList来创建一个队列。PriorityQueue类实现了一个优先队列,优先队列中元素被赋予优先级,拥有高优先级的先被删除
查看代码
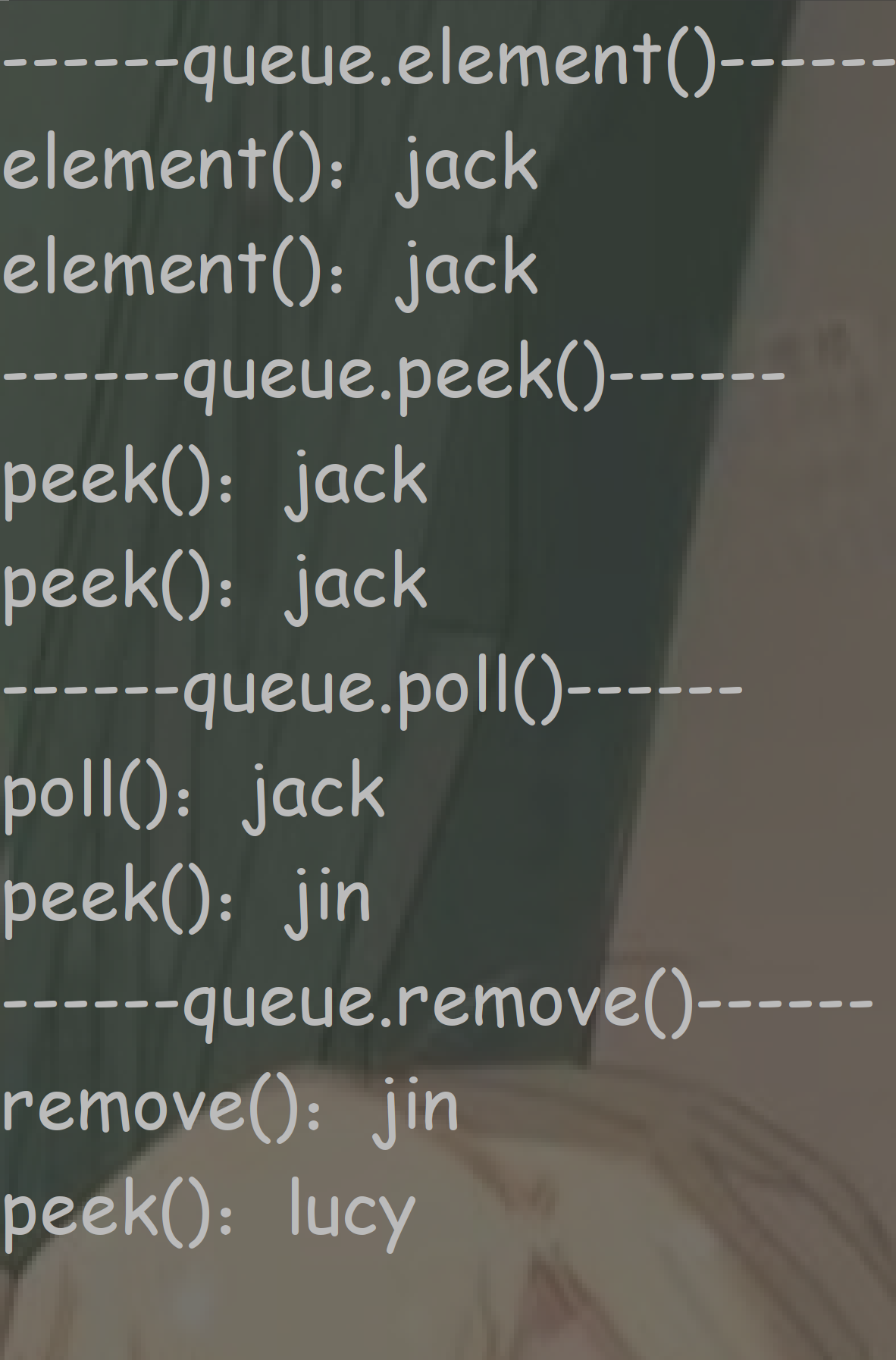
import java.util.LinkedList; import java.util.Queue; public class QueueTest { public static void main(String[] args) { //Deque extends Queue LinkedList实现了Deque接口 Queue<String> queue = new LinkedList<>(); queue.add("jack");//入队 queue.add("jin"); queue.add("lucy"); System.out.println("------queue.element()------"); //查看队头元素,并不删除队头元素 System.out.println("element():" + queue.element()); System.out.println("element():" + queue.element()); System.out.println("------queue.peek()------"); //查看队头元素,并不删除队头元素 System.out.println("peek():" + queue.peek()); System.out.println("peek():" + queue.peek()); System.out.println("------queue.poll()------"); //poll 削除队头元素,返回削除队头元素 System.out.println("poll():" + queue.poll()); //peek查看 System.out.println("peek():" + queue.peek()); System.out.println("------queue.remove()------"); //remove 删除队头元素,返回删除队头元素 System.out.println("remove():" + queue.remove()); //peek查看 System.out.println("peek():" + queue.peek()); } }
4.Set接口
-
Set接口位置java.util.Set
-
特点:一个不包含重复元素的 collection
-
Set接口方法与Collection方法一致。
-
Set接口中常用的子类:
-
HashSet:底层调用HashMap中的方法,集合元素唯一,不保证迭代顺序,线程不安全(不同步),存取速度快。
-
TreeSet:元素不重复,能按照指定顺序排列。存储的对象必须实现Comparable接口。线程不安全(不同步)。
-
LinkedHashSet: 哈希表和链表实现了Set接口,元素唯一,保证迭代顺序。
-
4.1 Set的常见实现类
4.1.1 EnumSet
-
EnumSet:是枚举的专用Set。所有的元素都是枚举类型
4.1.2 HashSet
-
常用方法:
-
boolean add(E e) 将指定的元素添加到此集合(如果尚未存在)。
-
void clear() 从此集合中删除所有元素。
-
boolean contains(Object o) 如果此集合包含指定的元素,则返回 true 。
-
boolean remove(Object o) 如果存在,则从该集合中删除指定的元素。
-
int size() 返回此集合中的元素个数。
-
-
HashSet特点:
-
HashSet:无序不重复,无索引
-
默认不重复的是虚地址,要想内容不重复,就重写hashcode和equals方法。
-
底层是HashMap实现,HashMap底层是由数组+链表+红黑树实现
-
HashSet堪称查询速度最快的集合,因为其内部是以HashCode来实现的。它内部元素的顺序是由哈希码来决定的,所以它不保证set的迭代顺序;特别是它不保证该顺序恒久不变
-
无索引,无法使用for循环来遍历,可以使用增强for循环和迭代器来循环
-
造成存泄露的原因:HashSet的remove方法也依赖于哈希值进行待删除节点定位,如果由于集合元素内容被修改而导致hashCode方法的返回值发生变更,那么,remove方法就无法定位到原来的对象,导致删除不成功,从而导致内存泄露。
-
-
HashSet<一>:
查看代码
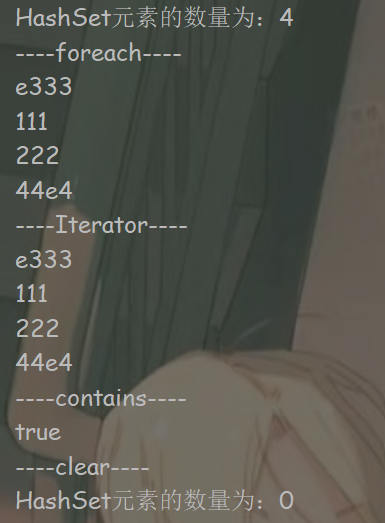
import java.util.HashSet; import java.util.Iterator; import java.util.Set; public class HashSetTest { public static void main(String[] args) { Set<String> set = new HashSet<>(); set.add("111"); set.add("222"); set.add("e333"); set.add("44e4"); set.add("222"); //HashSet去重 System.out.println("HashSet元素的数量为:" + set.size()); System.out.println("----foreach----"); //添加顺序与遍历元素顺序不一定一致 for (String s : set) { System.out.println(s); } System.out.println("----Iterator----"); Iterator<String> iterable = set.iterator(); while (iterable.hasNext()) { System.out.println(iterable.next()); } System.out.println("----contains----"); boolean bl = set.contains("e333"); System.out.println(bl); System.out.println("----clear----"); set.clear(); //清空 System.out.println("HashSet元素的数量为:" + set.size()); } }
- HashSet<二>:
查看代码
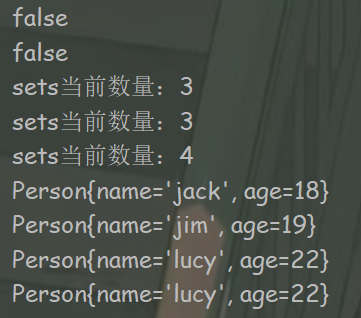
import java.util.HashSet; import java.util.Set; public class HashSetTest2 { public static void main(String[] args) { Set<Person> sets = new HashSet<>(); Person p1 = new Person("jack", 18); Person p2 = new Person("jim", 19); Person p3 = new Person("lucy", 20); System.out.println(p1 == p2);//false //p1==p2比较的是什么?比较的是地址值, //equals()比较两个对象是否相等,equals是Object的方法, //也就是说任何对象都有这个方法,我们就重写equals来符合业务需求 System.out.println(p1.equals(p2));//false /**HashSet为什么优先选择HashCode比较然后再equals? * 因为HashCode计算和比较效率高于equals比较*/ /**HashSet怎么判断两个Person是不是同一个, * 首先判断Person对象的HashCode是否相等, * 如果不相等就认为不是同一个对象, * 如果Hashcode相等,再次判断equals是否返回true, * 如果返回true就认为是同一个对象,返货false就认为不是同一个对象*/ //重写HashCode和equals规则: // equals相等Hashcode相同,HashCode相同equals不一定相等(eg:hashCode相同,equals不等) sets.add(p1); sets.add(p2); sets.add(p3); System.out.println("sets当前数量:" + sets.size()); //修改P3的age p3.setAge(22);//删不掉 sets.remove(p3); System.out.println("sets当前数量:" + sets.size()); //再次添加p3,还能添加成功 sets.add(p3); System.out.println("sets当前数量:" + sets.size()); for (Person person : sets) { System.out.println(person); } } } import java.util.Objects; public class Person { private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; } /** * 重写hashcode规则 * * @return */ @Override public int hashCode() { return name.hashCode() + age; } // @Override // public int hashCode() { // return Objects.hash(name, age); // } }
- HashSet<三>:
查看代码
public class Student { private String no; private String name; private int age; public Student(String no, String name, int age) { this.no = no; this.name = name; this.age = age; } public String getNo() { return no; } // public void setNo(String no) { // this.no = no; // } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Student{" + "no='" + no + '\'' + ", name='" + name + '\'' + ", age=" + age + '}'; } //如果业务上有要求:如果两个学生的学号相同就认为是同一个学生, //在业务判断中,用equals判断对象是否相等 @Override public boolean equals(Object o) { Student otherStu = (Student) o; if (this.getNo() == null || otherStu.getNo() == null) { return false; } return this.getNo().equals(otherStu.getNo()); } //重写HashCode,适应HashSet和HashMap // equals相等HashCode必须相同时,HashCOde相同equlas不一定相等 @Override public int hashCode() { //只有相同的学号字符串,HashCode也相同 //不同字符串HashCode也有可能相同,不影响,因为HashSet和HashMap,盘算HashCode相等之后还有判断equals return this.getNo().hashCode(); } } import java.util.HashSet; import java.util.Set; public class StudentHashSet { public static void main(String[] args) { Student s1 = new Student("001", "jack", 20); Student s2 = new Student("002", "tom", 30); Student s3 = new Student("003", "bxx", 40); //在业务看来s1和s5相等 Student s5 = new Student("003", "lucy", 40); Student s4 = s1; //没有业务要求,s1,s2,s3是三个不相等的对象(s1,s2,s3内存地址不相等) Set<Student> sets = new HashSet<>(); //HashSet怎么判断s1,s2,s3是不相等的三个对象? //1、判断HashCode是否相等 //2、如果HashCode相同,就判断equals是否相等 s1.setAge(80); s2.setAge(90); s3.setAge(100); // s1.setNo("004");//在业务上已经发生改变,s1不再是原来的学生了,再次删除不掉,是符合业务需求的 System.out.println(s1.hashCode());//没修改年龄前的HashCode:460141958 System.out.println(s2.hashCode());//没修改年龄前的HashCode:1163157884 System.out.println(s3.hashCode());//没修改年龄前的HashCode:1956725890 System.out.println(s4.equals(s1));//true sets.add(s1); sets.add(s2); sets.add(s3); sets.add(s4);//去重 sets.add(s5); System.out.println("数量:" + sets.size()); sets.remove(s1); System.out.println("数量:" + sets.size()); //如果业务上有要求:如果两个学生的学号相同就认为是同一个学生, } }
4.1.3 LinkedHashSet
-
LinkedHashSet继承自HashSet,它主要是用链表实现来扩展HashSet类,HashSet中条目是没有顺序的,但是在LinkedHashSet中元素既可以按照它们插入的顺序排序,也可以按它们最后一次被访问的顺序排序
-
保持Set中元素的插入顺序或者访问顺序,就使用LinkedHashSet
-
案例
查看代码
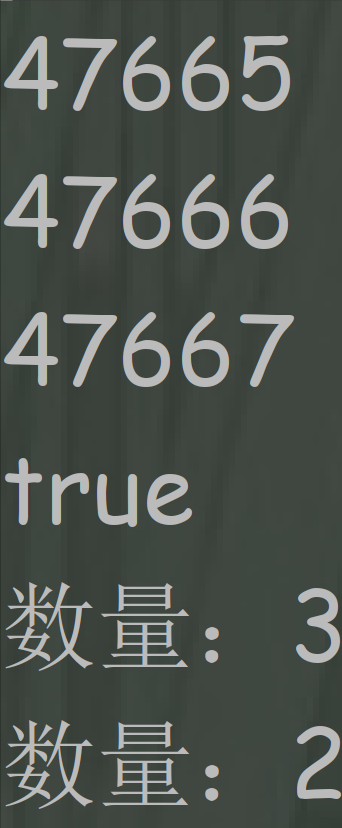
import java.util.ArrayList; import java.util.LinkedHashSet; import java.util.List; public class LinkedHashSetTest { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("a"); list.add("a"); list.add("b"); list.add("b"); list.add("c"); list.add("c"); list.add("d"); list.add("c"); list.add("d"); //要求list去重,又要保证顺序 LinkedHashSet<String> lhs = new LinkedHashSet(); lhs.addAll(list); for (String s : lhs) { System.out.println(s); } } }
![]()
4.1.4 TreeSet
-
TreeSet特点:无序不重复,但是排序。 线程不安全(不同步)。底层基于TreeMap实现。
-
使用元素的自然顺序(字典顺序)进行排序:
-
存储非自定义对象(必须本身已经实现Comparable的接口),默认进行排序。
-
存储自定义对象(需要实现Comparable接口,重写compareTo方法)进行排序。
-
接口Comparable<T>
-

-
使用比较器进行排序:
可以使用外部比较器Comparator,灵活为类定义多种比较器,此时类本身不需要实现Comparable接口;

查看代码
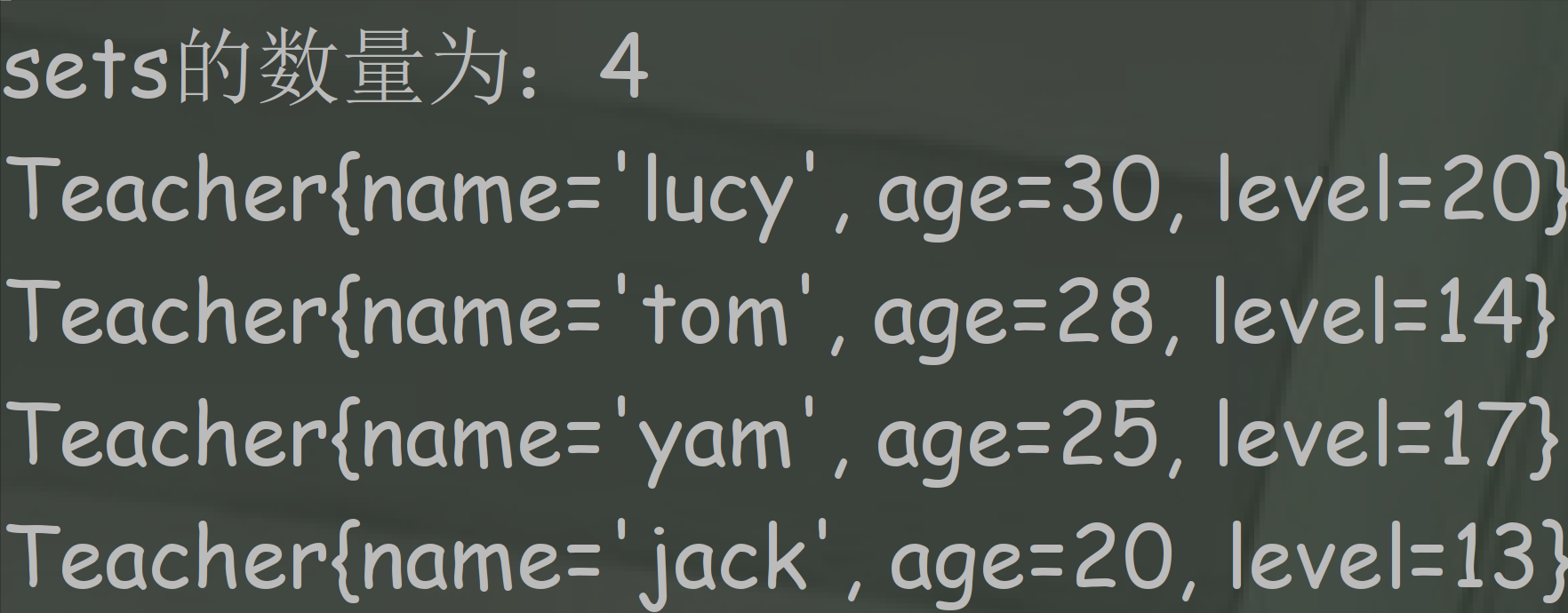
public class Teacher implements Comparable<Teacher> { private String name; private int age; private int level; public Teacher(String name, int age, int level) { this.name = name; this.age = age; this.level = level; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public int getLevel() { return level; } public void setLevel(int level) { this.level = level; } @Override public String toString() { return "Teacher{" + "name='" + name + '\'' + ", age=" + age + ", level=" + level + '}'; } /** * 比较两个对象大小(通过年龄比大小) * * @param o * @return 大于0:当前对象大于传入对象o;小于0:当前对象小于传入对象o;等于0:当前对象等于传入对象o */ @Override public int compareTo(Teacher o) { //return this.age-o.age;//由小到大排序 return o.age - this.age;//由大到小排序 //this表示新添加的元素 //例如:第一个添加的元素是Jack,第二个是Tom //this指的是Tom,o指的是Jack //结果-3,表示Tom<Jack } } import java.util.Set; import java.util.TreeSet; public class TreeSetTest { public static void main(String[] args) { //创建对象Teacher Teacher t1 = new Teacher("jack", 20, 13); Teacher t2 = new Teacher("tom", 28, 14); Teacher t3 = new Teacher("lucy", 30, 20); Teacher t4 = new Teacher("yam", 25, 17); //创建TreeSet对象 //元素对象哪个大哪个小,取决于Comparable接口CompareTo方法的返回值 Set<Teacher> sets = new TreeSet<>(); sets.add(t1); sets.add(t2); sets.add(t3); sets.add(t4); System.out.println("sets的数量为:" + sets.size()); for (Teacher t : sets) { System.out.println(t); } } }
5.Map接口
-
Map是由一系列键值对组成的集合,提供了key到Value的映射。同时它也没有继承 Collection。
-
Map是一个key对应一个value,所以它不能存在相同的 key 值,当然value值可以相同
-
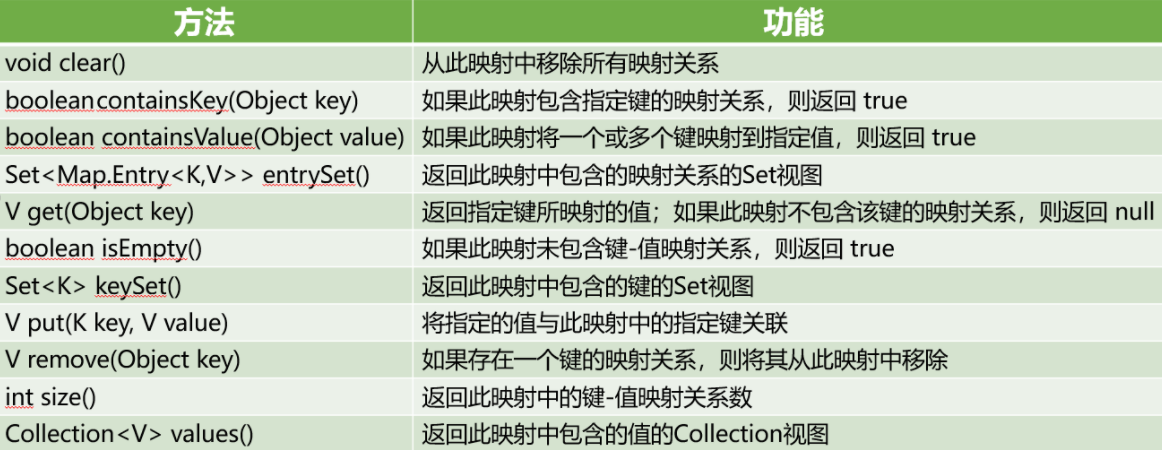
Map接口提供了重要的针对键、值进行操作的接口方法
5.1 HashMap
-
特点:
-
1.底层实现1.7之前:数组+链表 1.8以后:数组+链表+红黑树
-
2.key不允许重复,如果key的值相同,后添加的数据会覆盖之前的数据
-
3.HashMap是非线程安全的,允许存放null键,null值。
-
查看代码
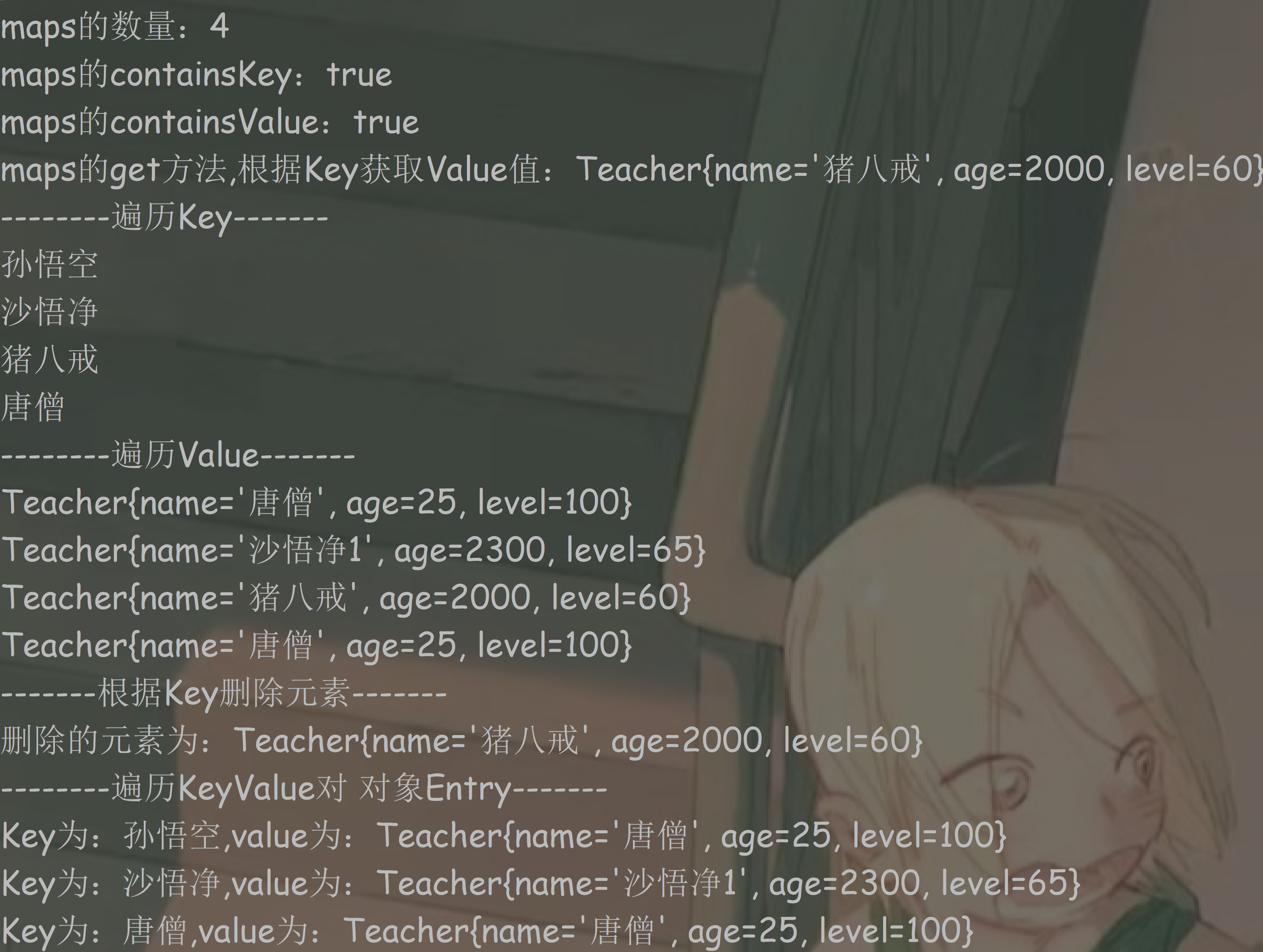
import java.util.Collection; import java.util.HashMap; import java.util.Map; import java.util.Set; public class HashMapTest { public static void main(String[] args) { Map<String, Teacher> maps = new HashMap<>();//创建HashMap对象 //创建Teacher对象 Teacher t1 = new Teacher("唐僧", 25, 100); Teacher t2 = new Teacher("孙悟空", 3000, 80); Teacher t3 = new Teacher("猪八戒", 2000, 60); Teacher t4 = new Teacher("沙悟净", 2000, 50); Teacher t5 = new Teacher("沙悟净1", 2300, 65); //Teacher添加到HashMap中 maps.put("唐僧", t1); maps.put("孙悟空", t2); maps.put("孙悟空", t1);//value重复,t1替换t2,后赋值的覆盖前面的 maps.put("猪八戒", t3); maps.put("沙悟净", t4); maps.put("沙悟净", t5);//key重复,t5替换t4,后赋值的覆盖前面的 System.out.println("maps的数量:" + maps.size()); System.out.println("maps的containsKey:" + maps.containsKey("孙悟空")); System.out.println("maps的containsValue:" + maps.containsValue(t3)); Teacher t0 = maps.get("猪八戒"); System.out.println("maps的get方法,根据Key获取Value值:" + t0); System.out.println("--------遍历Key-------"); Set<String> keys = maps.keySet(); for (String key : keys) { System.out.println(key); } System.out.println("--------遍历Value-------"); Collection<Teacher> value = maps.values(); for (Teacher t : value) { System.out.println(t); } System.out.println("-------根据Key删除元素-------"); Teacher remove = maps.remove("猪八戒"); System.out.println("删除的元素为:" + remove); System.out.println("--------遍历KeyValue对 对象Entry-------"); Set<Map.Entry<String, Teacher>> entries = maps.entrySet(); for (Map.Entry<String, Teacher> entry : entries) { Object key = entry.getKey(); Teacher value1 = entry.getValue(); System.out.println("Key为:" + key + ",value为:" + value1); } } }
-
数据结构:
java1.7 HashMap结构
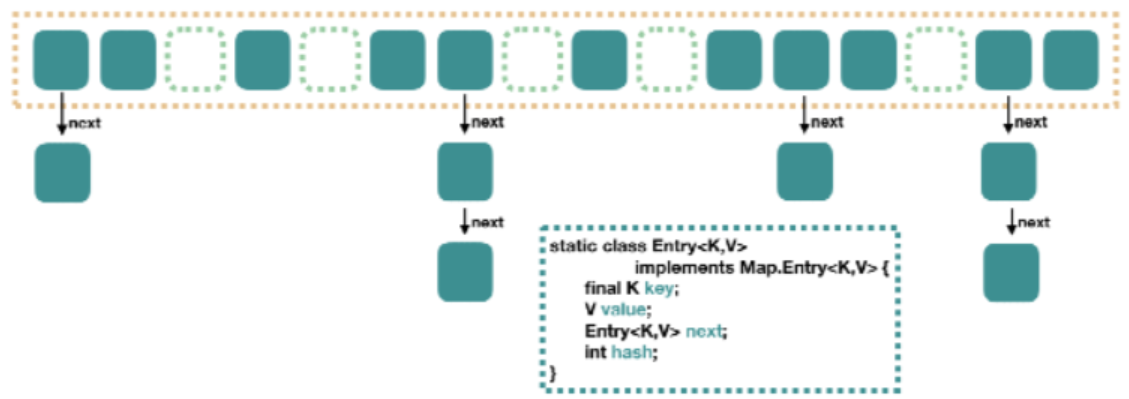
大方向上,HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。上图中,每个绿色
的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next
-
capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
-
loadFactor:负载因子,默认为 0.75。
-
threshold:扩容的阈值,等于 capacity * loadFactor
-
-
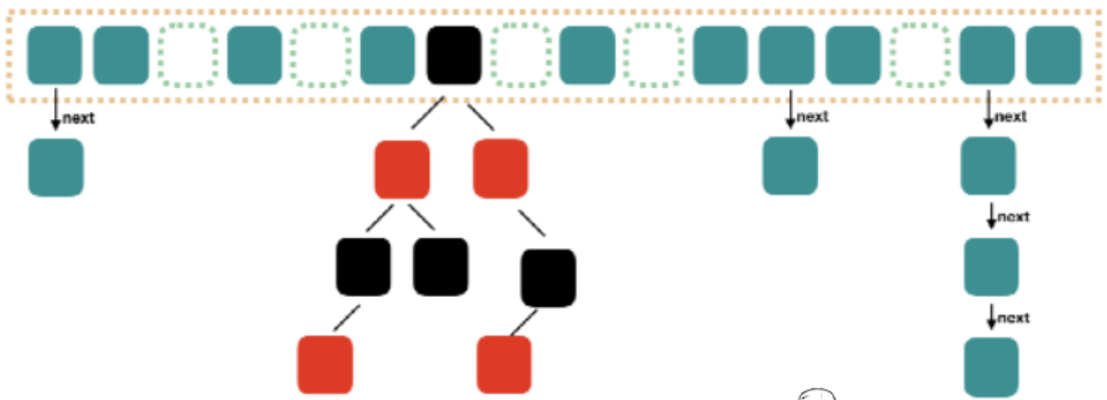
java1.8 HashMap结构:
Java1.8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑 树 组成。
根据 Java1.7 HashMap 的介绍,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。为了降低这部分的开销,在 Java1.8 中,当链表中的元素超过了 8 个以后, 会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
-
如何判断key是否相同:第一步计算key的hashcode是否想相同,如果不同,就认为key不相同,如果相同进行第二步判断,判断key的equals是否为true,如果为false就是认为key不相同,如果为true就认为key相同
-
所以我们重写hashcode和equals的原则,hashcode相同,equals不一定相等,但是equals相等,hashcode必须相同
5.2 HashTable
-
Hashtable,它的操作接口和HashMap相同。
-
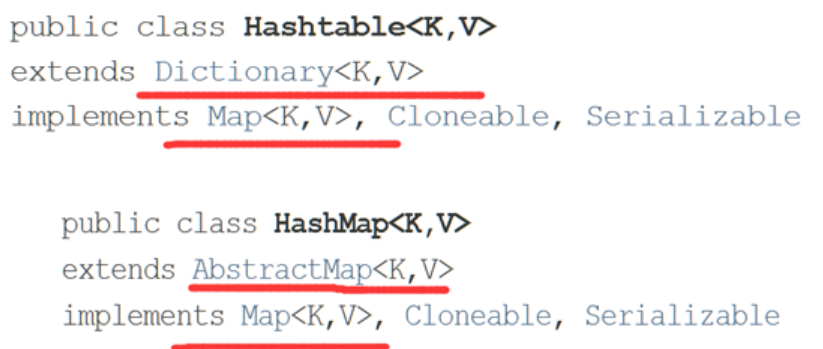
HashMap和HashTable的区别在于:
-
Hashtable是线程安全的,而HashMap是非线程安全的
-
Hashtable不允许空的键值对,而HashMap可以
-
Hashtable与HashMap都实现Map接口,但二个类的继承的父类不是同一个
-
-
HashTable底层实现:数组+链表+红黑树
-
案例
查看代码
import java.util.Collection; import java.util.HashMap; import java.util.Hashtable; import java.util.Map; public class HashTableTest { public static void main(String[] args) { Hashtable<String, Integer> hashTable = new Hashtable<>(); // hashTable.put(null,1);//运行报错,java.lang.NullPointerException,key不能是null // hashTable.put("a",null);//运行报错,java.lang.NullPointerException,value不能是null // hashTable.put(null,null);//运行报错,java.lang.NullPointerException HashMap<String, Integer> hashmap = new HashMap<>(); hashmap.put(null, 1);//key可以为null hashmap.put("jack", null);//value也可以为null hashmap.put(null, null); for (Map.Entry<String, Integer> entry : hashmap.entrySet() ) { System.out.println(entry); } } }

5.3 ConcurrentHashMap
-
特点:ConcurrentHashMap是线程安全并且高效的HashMap
-
常用方法:同HashMap
-
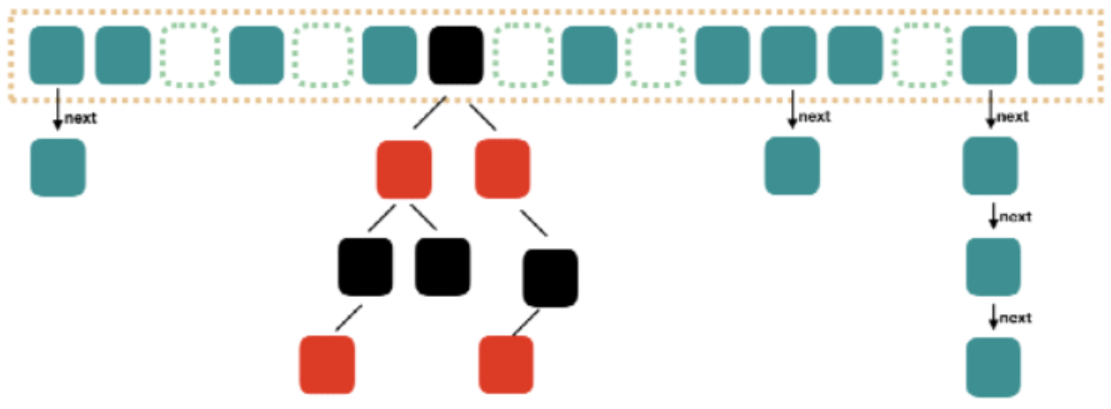
数据结构:JDK8 数组+链表+红黑树,数组的结构可能是链表,也可能是红黑树,红黑树是为了提高查找效率。采用CAS+Synchronized保证线程安全。CAS表示原子操作,例如:i++不是原子操作。Synchronized:表示锁,多线程能够保证只有一个线程操作。
-
ConcurrentHashMap比HashTable效率要高
-
案例:
查看代码
import java.util.Map; import java.util.Set; import java.util.concurrent.ConcurrentHashMap; public class ConcurrentHashMapTest { public static void main(String[] args) { ConcurrentHashMap<String, Integer> concurrentHashMap = new ConcurrentHashMap<>(); // concurrentHashMap.put(null,1);//key不能为null concurrentHashMap.put("jack", 20); // concurrentHashMap.put("lucy",null);//value不能为null System.out.println("数量为:" + concurrentHashMap.size()); Set<Map.Entry<String, Integer>> entries = concurrentHashMap.entrySet(); for (Map.Entry<String, Integer> en : entries) { System.out.println(en); } } }

5.4 LinkedHashMap
-
LinkedHashMap继承自HashMap,它主要是用链表实现来扩展HashMap类,HashMap中条目是没有顺序的,但是在LinkedHashMap中元素既可以按照它们插入的顺序排序,也可以按它们最后一次被访问的顺序排序
-
保持Map中元素的插入顺序或者访问顺序,就使用LinkedHashMap
-
案例
查看代码
import java.security.Key; import java.util.Iterator; import java.util.LinkedHashMap; import java.util.Set; public class LinkedHashMapTest { public static void main(String[] args) { LinkedHashMap<String, Integer> linkedHashMap = new LinkedHashMap<>(); linkedHashMap.put("jack", 20); linkedHashMap.put("tom", 23); linkedHashMap.put("lucy", 22); linkedHashMap.put("wan", 25); System.out.println("数量为:" + linkedHashMap.size()); Set<String> keys = linkedHashMap.keySet(); Iterator<String> it = keys.iterator(); while (it.hasNext()) { String key = it.next(); Integer value = linkedHashMap.get(key); System.out.println("key=" + keys + ",value=" + value); } } }
5.5 TreeMap
-
TreeMap特点: 可以对Map集合中的元素进行排序。
-
1.TreeMap基于红黑树数据结构的实现
-
2.键可以使用Comparable或Comparator接口, 重写compareTo方法来排序。
-
3.自定义的类必须实现接口和重写方法,否则抛异
-
4.Key值不允许重复,如果重复会把原有的value值覆盖。
-
-
使用元素的自然顺序(字典顺序)进行排序:
-
对象(本身具有比较功能的元素)进行排序。
-
自定义对象(本身没有比较功能的素)进行排序(要进行比较那就让元素具有比较功能,
那就要实现Comparable这个接口里compareTo的方法)
-
-
使用比较器进行排序:
-
定义一个类实现Comparator接口,覆盖compare方法,将类对象作为参数传递给TreeSet集合的构造方法
-
查看代码
import java.util.Map; import java.util.Set; import java.util.TreeMap; import java.util.TreeSet; public class TreeMapTest { public static void main(String[] args) { Product p1 = new Product("苹果", 20); Product p2 = new Product("香蕉", 30); Product p3 = new Product("巧克力", 50); //创建外部比较器 ProductComparator comparator = new ProductComparator(); //new TreeMap传入外部比较器对象 TreeMap<Product, String> treeMap = new TreeMap<>(comparator); treeMap.put(p1, "我是苹果"); treeMap.put(p2, "我是香蕉"); treeMap.put(p3, "我是巧克力"); Set<Map.Entry<Product, String>> entries = treeMap.entrySet(); for (Map.Entry<Product, String> en : entries) { System.out.println(en); } System.out.println("------------------------"); TreeSet<Product> treeSet = new TreeSet<>(comparator); treeSet.add(p1); treeSet.add(p2); treeSet.add(p3); for (Product p : treeSet) { System.out.println(p); } } }


