
URL的编码和解码
URL的编码和解码
参考:阮一峰--关于URL编码
1 为什么要URL编码
- 在因特网上传送URL,只能采用ASCII字符集
也就是说URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号,即
只有字母和数字[0-9a-zA-Z]、一些特殊符号$-_.+!*'()[不包括双引号]、以及某些保留字(空格转换为+),才可以不经过编码直接用于URL
这意味着 如果URL中有汉字,就必须编码后使用。 但是麻烦的是 标准的国际组织并没有规定具体的编码方法,而是交给应用程序(浏览器)自己决定。 这导致"URL编码"成为了一个混乱的领域。
如果包含中文,其实会自动编码的,比如Chrome和火狐,"文"和"章"的utf-8编码分别是"E6 96 87"和"E7 AB A0" ,下图所示的"%e6%96%87%e7%ab%a0"就是按照顺序,在每个字节前加上%而得到的:
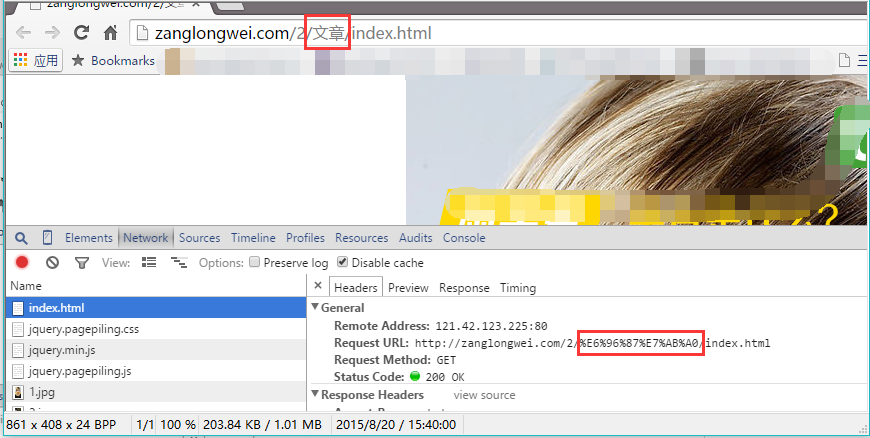
但是不同的浏览器可能会有不同的编码方式,不要将编码交给浏览器。应该用JS在前端对URL编码,这样就实现了统一
- 如果key=value这种传参方式中,value中包含
?``=或者&等符号,url的解析会变得很困难 - 不同的操作系统、浏览器、不同的网页字符集(charset)有不同的默认编码方式,要有一个统一格式来发送url,参考文章中举了4个例子(很有读的必要)!
2 如何编码
URL编码通常也被称为百分号编码(percent-encoding),是因为它的编码方式非常简单:
使用%加上两位的字符——0123456789ABCDEF——代表一个字节的十六进制形式。URL编码要做的,就是将每一个非安全的ASCII字符都被替换为“%xx”格式,
对于非ASCII字符,RFC文档建议使用utf-8对其进行编码得到相应的字节,然后对每个字节执行百分号编码。
如"中文"使用UTF-8字符集得到的字节为0xE4 0xB8 0xAD 0xE6 0x96 0x87,经过Url编码之后得到"%E4%B8%AD%E6%96%87"。
一些常见的特殊字符换成相应的十六进制的值:
+ %20
/ %2F
? %3F
% %25
# %23
& %26
2.1 JS的三种编码函数
上面说了编码方式的混乱,那么如何统一呢?
**使用Javascript先对URL编码,或者将可以在后台编码的参数编码后再发送给前端使用。然后再向服务器提交,不要给浏览器插手的机会,这样就能保证客户端只用一种编码方法向服务器发出请求 **
escape
js中编码出生最早的一个,不提倡使用,真正作用是:
返回一个字符的Unicode编码值,为的是方便他们能在所有计算机上可读,规则:
所有空格、标点以及其他非ASCII字符都用%xx编码替换; 例如空格返回的是%20 字符值大于255的字符以%uxxxx格式储存
encodeURI函数(推荐使用)
这个函数才是javascript中真正用来对URL编码的函数
它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号"; / ? : @ & = + $ , #",也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。
需要注意的是,它不对单引号'编码
它对应的解码函数是decodeURI()。
规则就是我上面第二部分所说的,采用utf-8编码。比如:
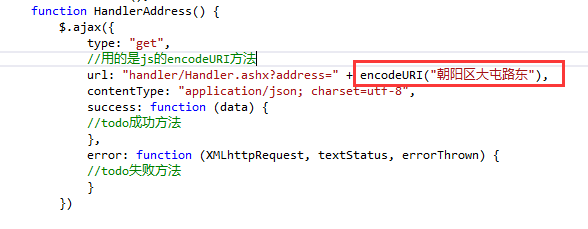
encodeURIComponent函数(推荐使用)
与encodeURI()的区别是,它用于对URL的组成部分进行个别编码,而不用于对整个URL进行编码。
因此,"; / ? : @ & = + $ , #",这些在encodeURI()中不被编码的符号,在encodeURIComponent()中统统会被编码,具体的编码规则是和encodeURI函数是一样的
它对应的解码函数是decodeURIComponent()。
实验:
利用chrome的开发者工具:

可以看到第一种,对需要url编码的部分用encodeURIComponent函数,其他部分不编码符合要求,即
对需要编码的参数用encodeURIComponent函数最推荐
2.2 我们的问题
遇到的问题:
get请求的路径参数filePath为:/image/5cf4adbe16ad4fc18ab2259cb86bb14d.png,
在相应的控制器Controller中:
@RequestMapping(path = "/admin/{filePath}")
那么这个请求就变成了:
http://localhost/admin//image/5cf4adbe16ad4fc18ab2259cb86bb14d.png
由于服务器无法解析上面的url,导致400 bad request错误
2.3 Java的URLEncoder.encode("需要编码的参数","UTF-8")
比较JS的encodeURIComponent函数和Java的URLEncoder.encode("需要编码的参数","UTF-8")函数:
对//中国/images/head_tripletown.png//!@#$%^&*()进行URL编码:
//JS的encodeURIComponent函数
javascript:encodeURIComponent("//中国/images/head_tripletown.png//!@#$%^&*()")
"%2F%2F%E4%B8%AD%E5%9B%BD%2Fimages%2Fhead_tripletown.png%2F%2F!%40%23%24%25%5E%26*()"
//Java的URLEncoder.encode("需要编码的参数","UTF-8")函数
URLEncoder.encode("//中国/images/head_tripletown.png//!@#$%^&*()","UTF-8")
%2f%2f%e4%b8%ad%e5%9b%bd%2fimages%2fhead_tripletown.png%2f%2f!%40%23%24%25%5e%26*()
可以看到一模一样,因此:
使用Javascript先对URL编码,或者将可以在后台编码的参数编码后再发送给前端使用。
3 为什么两次编码
首先看例子,原始请求:
http://localhost/admin/image/filePath//images/head_tripletown.png/200/200
其中,Controller中的映射文件:
@RequestMapping(path = "/admin/image/filePath/{filePath}/{width}/{height}")
对filePath参数一次编码后,发起URL请求:
请求为:http://localhost/admin/image/filePath/%2fimages%2fhead_tripletown.png/200/200
在拦截器加断点:
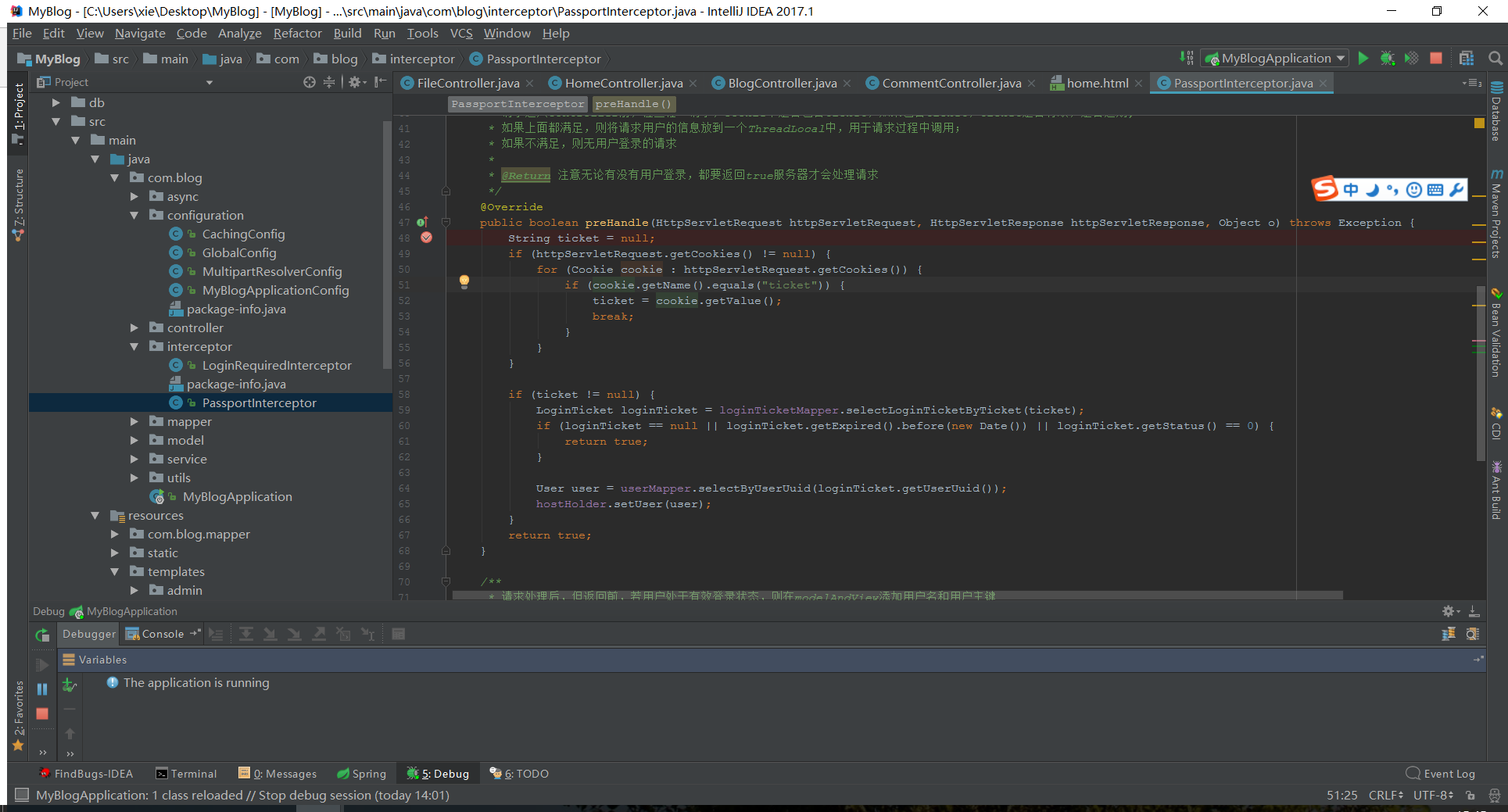
毫无反应。。。所以应该在拦截器工作前就对URL进行了解码
对filePath参数两次编码后,发起URL请求:
请求为:http://localhost/admin/image/filePath/%252fimages%252fhead_tripletown.png/200/200
在拦截器加断点:
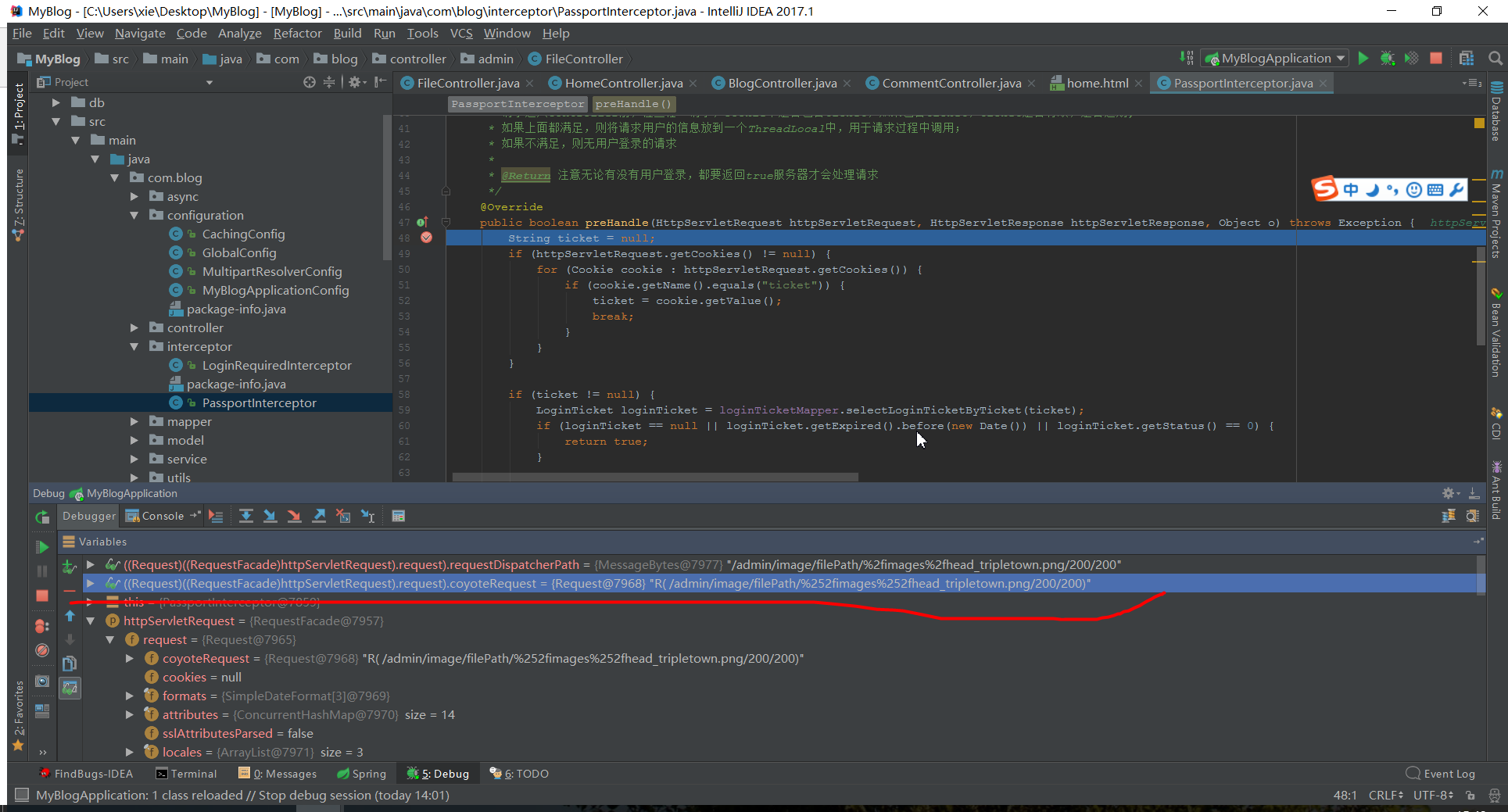
一次解码之前:
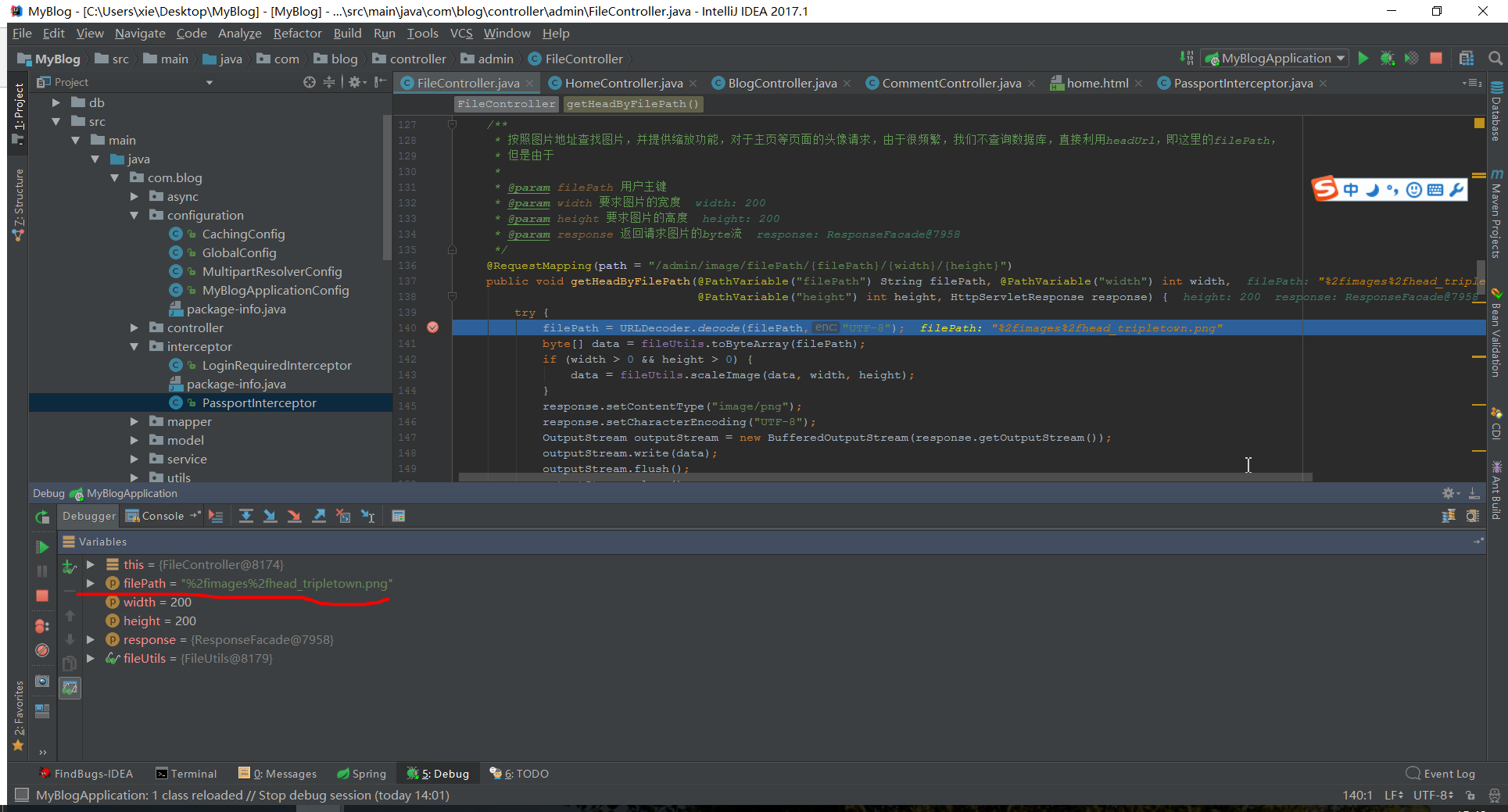
一次解码之后:
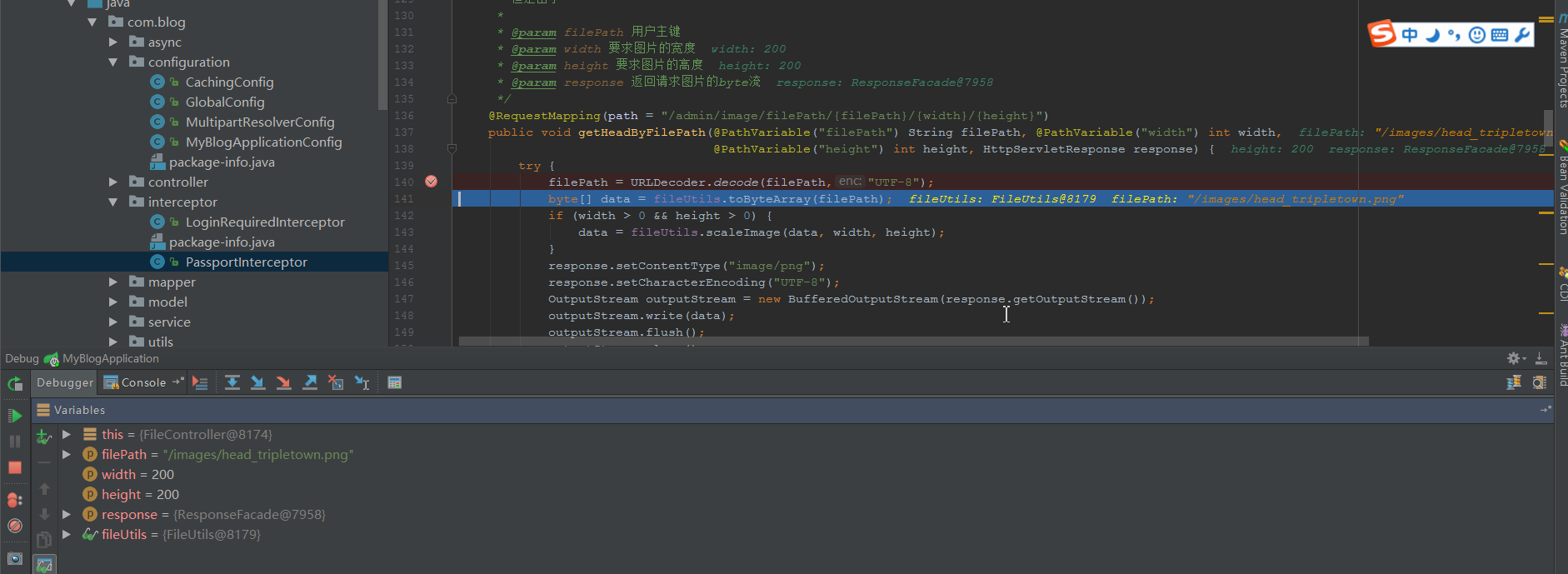
获得了正常回应:
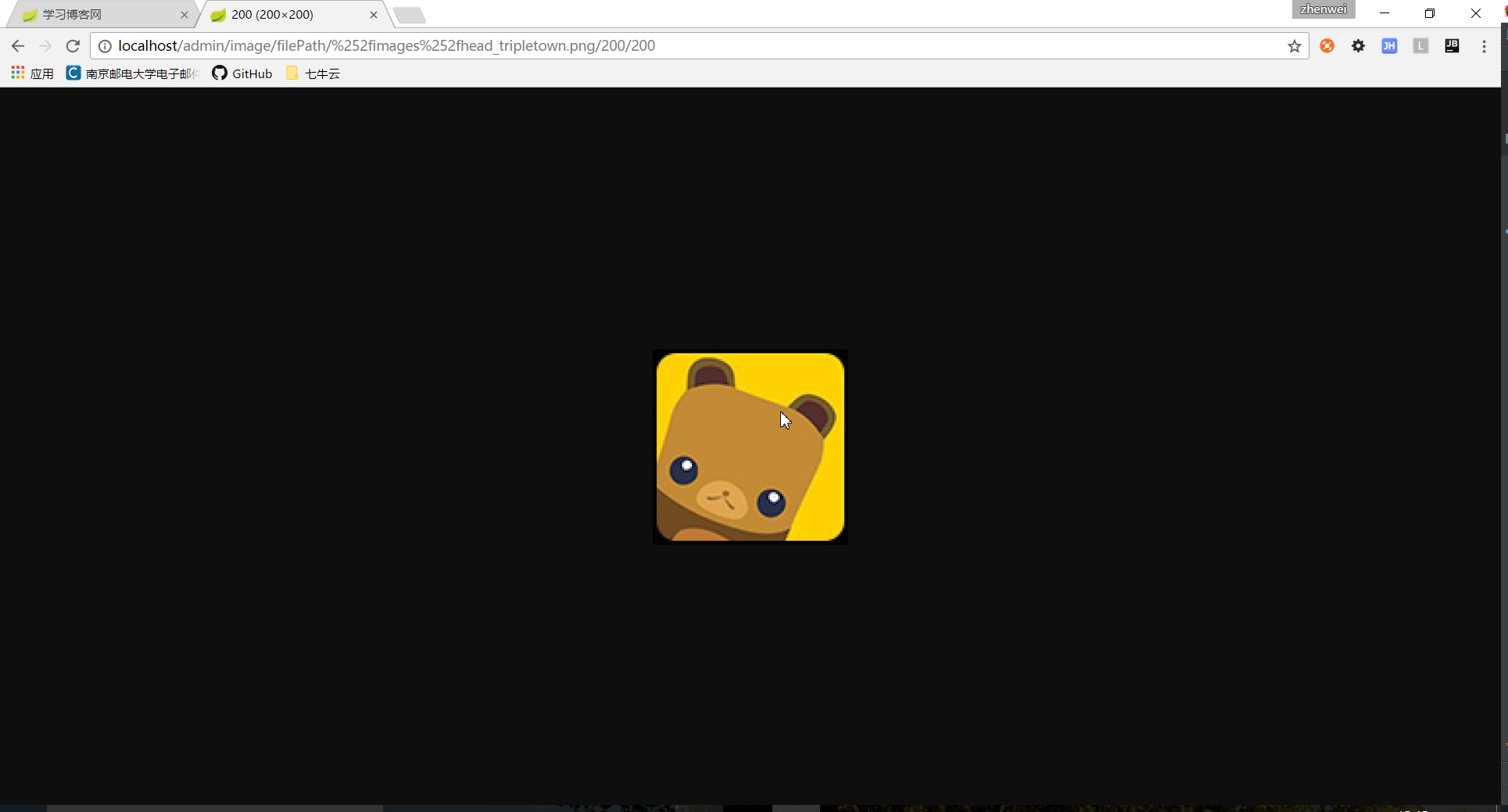
两次编码的原因:
- 一般的原因:解决服务器解码后乱码问题
如果只进行一次encodeURI,得到的是UTF-8形式的URL,服务器端通过request.getParameter()解码查询参数(通常是iso-8859-1)就会得到乱码。
如果进行两次encodeURI,第一次编码得到的是UTF-8形式的URL,第二次编码得到的依然是UTF-8形式的URL,但是在效果上相当于首先进行了一次UTF-8编码(此时已经全部转换为ASCII字符),再进行了一次iso-8859-1编码,因为对英文字符来说UTF-8编码和ISO-8859-1编码的效果相同。在服务器端,首先通过request.getParameter()自动进行第一次解码(可能是gb2312,gbk,utf-8,iso-8859-1等字符集,对结果无影响)得到ascii字符,然后再使用UTF-8进行第二次解码,通常使用java.net.URLDecoder("","UTF-8")方法。
两次编码两次解码的过程为:
UTF-8编码->UTF-8(iso-8859-1)编码->iso-8859-1解码->UTF-8解码,编码和解码的过程是对称的,所以不会出现乱码。
- 我们的原因:解决400 bad request错误
由于我们发送的请求为:
http://localhost/admin/image/filePath/%2fimages%2fhead_tripletown.png/200/200
服务器端首先进行一次解码,变为:
http://localhost/admin/image/filePath//images/head_tripletown.png/200/200
在dispatcherservlet(前端控制器,用来查询映射文件,转发请求和转发回应)中查询映射文件,发现没有匹配的RequestMapping,就会报400 bad request错误
如果两次编码:
http://localhost/admin/image/filePath/%252fimages%252fhead_tripletown.png/200/200
服务器端首先进行一次解码,变为:
http://localhost/admin/image/filePath/%2fimages%2fhead_tripletown.png/200/200
查询映射文件可以正常转发,在接收请求后在手动进行一次解码。
4 扩展
什么是application/x-www-form-urlencoded
它是一种编码类型。当URL地址里包含非西欧字符的字符串时,系统会将这些字符转换成application/x-www-form-urlencoded字符串。表单里提交时也是如此,当包含非西欧字符的字符串时,系统也会将这些字符转换成application/x-www-form-urlencoded字符串,然后在服务器端自动解码。FORM元素的enctype属性指定了表单数据向服务器提交时所采用的编码类型,默认的缺省值是“application/x-www-form-urlencoded。
然而,在向服务器发送大量的文本、包含大量非ASCII字符的文本或二进制数据时这种编码方式效率很低。这个时候我们就要使用另一种编码类型“multipart/form-data”,比如在我们在做上传的时候,表单的enctype属性一般会设置成“multipart/form-data”。 Browser端<form>表单的ENCTYPE属性值为multipart/form-data,它告诉我们传输的数据要用到多媒体传输协议,由于多媒体传输的都是大量的数据,所以规定上传文件必须是post方法,<input>的type属性必须是file。

