

教你如何通俗易懂的了解深度学习知识
首先,深度学习网上的资料很多,但大部分都不大适合初学者学习,我个人入门看的是台湾学者李宏毅制作的一个300页PPT --《一天搞懂深度学习》,接下来将对PPT里面的内容进行一些通俗化的描述。另附上该PPT的百度网盘链接:https://pan.baidu.com/s/1b7RVLF8HgqTOE0suFCt_uw 密码:os0w。希望对大家有帮助。
所谓深度学习,其中含有多个隐层的神经网络。深度学习需要有一定的数学知识,需要采用深入浅出的方式,才不会让初学者有畏难情绪。我认为要了解深度学习,首先要捡起来之前遗忘的关于导数,偏导数,以及各类函数的概念。我们知道,深度学习就是用神经网络来解决一些线性不可分的问题,其中神经网络主要有三个部分:定义模型函数->判断模型函数好坏->选择一个最好的函数,神经网络之所以叫神经网络是因为它的作用过程很像神经单元。以下是神经元结构。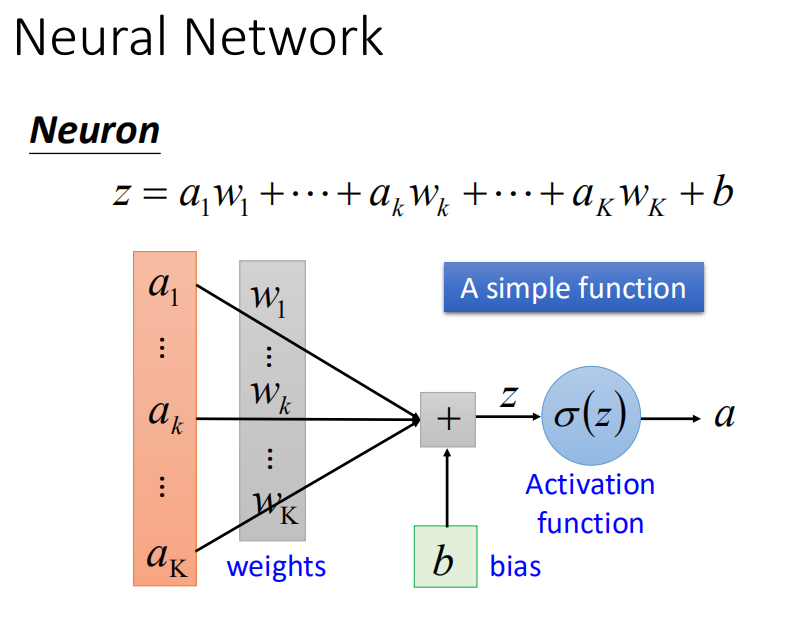
有图可见,各种神经元的连接方式不同,会延伸出不同的神经网络,例如全部向前连接的神经网络,上层每一个神经元都与下层每一个神经元进行相连。其中我们判断模型函数的损失,最关键的就是要定义模型的损失函数,当我们确定了模型的损失函数,那么我们的目标就是最小化这个损失。进一步的说,选择最好的模型参数过程也变成求最小化损失函数的参数过程。接下来我们将选择最好的模型参数,这个部分通常采用梯度下降法来进行选择。但是梯度下降法无法保证全局最优,常常会陷入局部最优的情况。这取决于我们初始点的选择,深度学习中的梯度下降法又叫做向后传播算法,向后传播算法其实本质是利用深度学习梯度下降算法不断进行更新神经网络中不同神经元权重的一个过程。
深度学习,包括了输入层,输出层和隐层。
输入层,就是大部分人对某件事物有各种各样的需求,每一种需求所占的比重是不同的,这就是权重的不同,这些不同的因素就构成了输入层的参数。
隐层,类似于具体到某一个人的身上,他对这些需求,结合自己的意愿,进行磨合,将比重进行修改,成为最适合他的需求比重。磨合的过程就是不断学习和修正的过程。
输出层,就是输出的结果,隐层中权重的更改,最后适合与否的结果在输出层中输出。
深度学习,既要防止欠拟合,也要防止过拟合。欠拟合就是训练的个数不够,所得到的函数不一定就是最优的函数,欠拟合固然不好,但是过拟合更不可取,过拟合,顾名思义,就是训练集的样本个数太多,训练集的效果很好,但是测试集的效果不行。
深度学习是一个不断磨合的过程,刚开始定位的标准参数,然后进行不断的修正,改变其中一些节点的权重,我们假设,深度学习就是在给学生上课,我们需要对他们进行不断的训练,出题目,然后给他们正确答案,以后在遇到类似的题目,他们就会解得出来,这就是类似于神经网络求解权重的过程。
深度学习的参数越多,显而易见,模型的训练效果会越好,有理论证明单隐层具有足够的神经元的话,可以实现任何函数,但实际上在单隐层中,随着节点单元的数量增多,其准确率上升速率较慢,甚至有的不升反降。因而相比单隐层的训练方法,深度学习的表达方式更加简洁明了。构建深度神经网络有利于模块化的训练过程,这样我们可以利用较少的训练数据来达到我们想要的效果。

