理解java容器底层原理--手动实现HashMap
HashMap结构
HashMap的底层是数组+链表,百度百科找了张图:

先写个链表节点的类
package com.xzlf.collection2;
public class Node {
int hash;
Object key;
Object value;
Node next;
}
自定义一个HashMap,实现了put方法增加键值对,并解决了键重复的时候覆盖相应的节点
package com.xzlf.collection2;
/**
* 自定义一个hashMap
* 实现了put方法增加键值对,并解决了键重复的时候覆盖相应的节点
* @author xzlf
*
*/
public class MyHashMap {
private Node[] table;//位桶 .bucket array
private int size;//存放键值对的个数
public MyHashMap() {
table = new Node[16];//长度一般定义成2的整数次幂
}
public void put(Object key, Object value) {
Node newNode = new Node();
newNode.hash = myHash(key.hashCode(), table.length);
newNode.key = key;
newNode.value = value;
Node tmp = table[newNode.hash];
Node iterLast = null;//正在遍历的最后一个元素
boolean keyRepeat = false;
if(tmp == null) {
//此处数组元素为空,则直接将新节点放进去
table[newNode.hash] = newNode;
}else {
//此处数组元素不为空。则遍历对应链表。。
while(tmp != null) {
// 判断是否有重复的键
if(key.equals(tmp.key)) {
keyRepeat = true;
// 键重复,直接覆盖value其他的值(hash,key,next)保持不变。
tmp.value = value;
break;
}else {
iterLast = tmp;
tmp = tmp.next;
}
}
if(!keyRepeat) {
//key没有重复的情况,则添加到链表最后。
iterLast.next = newNode;
}
}
}
public static int myHash(int v, int length) {
// System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
我们在写个main() 方法测试一下:
目前还没有重写toString() 方法,我们先把计算位置的方法加一条打印语句,然后在最后的输出语句加上断点,用debug模式查看
public static int myHash(int v, int length) {
System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
public static void main(String[] args) {
MyHashMap map = new MyHashMap();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
System.out.println(map);
}
debug模式运行代码,控制台输出了元素存放位置:

我们看下10 4 14 位置对应的值是否对应上 aa bb cc

debug模式中可以看到添加的变量,说明数据添加进去了
我们还要测试下键重复和桶位在同一位置情况
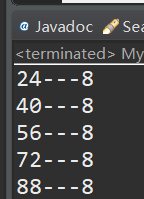
先用以下代码,找出在存放位置为索引8(可以自己定义)的键:
for (int i = 10; i < 100; i++) {
if (myHash(i,16) == 8) {
System.out.println(i + "---" + myHash(i, 16));//24, 40,56,72,88
}
}
找出来是24, 40,56,72,88:
用以下代码测试键重复,和存放位置一直情况:
public static void main(String[] args) {
MyHashMap map = new MyHashMap();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
map.put(10, "ssss");
map.put(24, "dd");
map.put(56, "ee");
map.put(72, "ff");
map.put(56, "java");
System.out.println(map);
}
还是用debug模式测试:

8和10的位置都是预期效果。接下来我们可以去重写toString方法,以方便我们查看结果。
版本二:重写toString()
package com.xzlf.collection2;
/**
* 自定义一个hashMap
* 实现toString方法,方便查看Map中的键值对信息
* @author xzlf
*
*/
public class MyHashMap2 {
private Node[] table;//位桶 .bucket array
private int size;//存放键值对的个数
public MyHashMap2() {
table = new Node[16];//长度一般定义成2的整数次幂
}
public void put(Object key, Object value) {
Node newNode = new Node();
newNode.hash = myHash(key.hashCode(), table.length);
newNode.key = key;
newNode.value = value;
Node tmp = table[newNode.hash];
Node iterLast = null;//正在遍历的最后一个元素
boolean keyRepeat = false;
if(tmp == null) {
//此处数组元素为空,则直接将新节点放进去
table[newNode.hash] = newNode;
}else {
//此处数组元素不为空。则遍历对应链表。。
while(tmp != null) {
// 判断是否有重复的键
if(key.equals(tmp.key)) {
keyRepeat = true;
// 键重复,直接覆盖value其他的值(hash,key,next)保持不变。
tmp.value = value;
break;
}else {
iterLast = tmp;
tmp = tmp.next;
}
}
if(!keyRepeat) {
//key没有重复的情况,则添加到链表最后。
iterLast.next = newNode;
}
}
}
public static int myHash(int v, int length) {
// System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("{");
// 遍历位桶数组
for (int i = 0; i < table.length; i++) {
Node tmp = table[i];
//遍历链表
while(tmp != null) {
sb.append(tmp.key + ":" + tmp.value + ",");
tmp = tmp.next;
}
}
sb.setCharAt(sb.length() - 1, '}');
return sb.toString();
}
public static void main(String[] args) {
MyHashMap2 map = new MyHashMap2();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
map.put(10, "ssss");
map.put(24, "dd");
map.put(56, "ee");
map.put(72, "ff");
map.put(56, "java");
System.out.println(map);
}
}
运行测试:
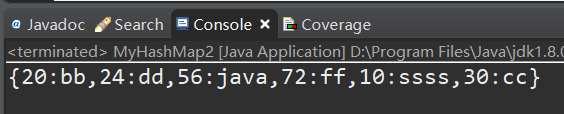
没有问题,继续添加get() 方法。
版本三:添加get方法
package com.xzlf.collection2;
/**
* 自定义一个hashMap
* 添加get方法
* @author xzlf
*
*/
public class MyHashMap3 {
private Node[] table;//位桶 .bucket array
private int size;//存放键值对的个数
public MyHashMap3() {
table = new Node[16];//长度一般定义成2的整数次幂
}
public void put(Object key, Object value) {
Node newNode = new Node();
newNode.hash = myHash(key.hashCode(), table.length);
newNode.key = key;
newNode.value = value;
Node tmp = table[newNode.hash];
Node iterLast = null;//正在遍历的最后一个元素
boolean keyRepeat = false;
if(tmp == null) {
//此处数组元素为空,则直接将新节点放进去
table[newNode.hash] = newNode;
}else {
//此处数组元素不为空。则遍历对应链表。。
while(tmp != null) {
// 判断是否有重复的键
if(key.equals(tmp.key)) {
keyRepeat = true;
// 键重复,直接覆盖value其他的值(hash,key,next)保持不变。
tmp.value = value;
break;
}else {
iterLast = tmp;
tmp = tmp.next;
}
}
if(!keyRepeat) {
//key没有重复的情况,则添加到链表最后。
iterLast.next = newNode;
}
}
}
public static int myHash(int v, int length) {
// System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("{");
// 遍历位桶数组
for (int i = 0; i < table.length; i++) {
Node tmp = table[i];
//遍历链表
while(tmp != null) {
sb.append(tmp.key + ":" + tmp.value + ",");
tmp = tmp.next;
}
}
sb.setCharAt(sb.length() - 1, '}');
return sb.toString();
}
public Object get(Object key) {
int hash = myHash(key.hashCode(), table.length);
Object value = null;
Node tmp = table[hash];
while(tmp != null) {
if(key.equals(tmp.key)) {//如果找到了,则返回对应的值
value = tmp.value;
break;
}else {
tmp = tmp.next;
}
}
return value;
}
public static void main(String[] args) {
MyHashMap3 map = new MyHashMap3();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
map.put(10, "ssss");
map.put(24, "dd");
map.put(56, "ee");
map.put(72, "ff");
map.put(56, "java");
System.out.println(map);
System.out.println(map.get(10));
System.out.println(map.get(30));
System.out.println(map.get(72));
System.out.println(map.get(78));
}
}
运行测试:

也没问题。
现在已经把hashMap的核心功能get put 实现了。
最后完善一下。
版本四:添加泛型,完善size计数
Node添加泛型:
package com.xzlf.collection2;
public class Node2<K, V> {
int hash;
K key;
V value;
Node2 next;
}
自定义hashmap添加泛型并完善size计数:
package com.xzlf.collection2;
/**
* 自定义一个hashMap
* 增加泛型,修复部分bug
* @author xzlf
*
*/
public class MyHashMap4<K, V> {
private Node2[] table;//位桶 .bucket array
private int size;//存放键值对的个数
public MyHashMap4() {
table = new Node2[16];//长度一般定义成2的整数次幂
}
public void put(K key, V value) {
Node2 newNode2 = new Node2();
newNode2.hash = myHash(key.hashCode(), table.length);
newNode2.key = key;
newNode2.value = value;
Node2 tmp = table[newNode2.hash];
Node2 iterLast = null;//正在遍历的最后一个元素
boolean keyRepeat = false;
if(tmp == null) {
//此处数组元素为空,则直接将新节点放进去
table[newNode2.hash] = newNode2;
size++;
}else {
//此处数组元素不为空。则遍历对应链表。。
while(tmp != null) {
// 判断是否有重复的键
if(key.equals(tmp.key)) {
keyRepeat = true;
// 键重复,直接覆盖value其他的值(hash,key,next)保持不变。
tmp.value = value;
break;
}else {
iterLast = tmp;
tmp = tmp.next;
}
}
if(!keyRepeat) {
//key没有重复的情况,则添加到链表最后。
iterLast.next = newNode2;
size++;
}
}
}
public static int myHash(int v, int length) {
// System.out.println(v&(length - 1));
return v&(length - 1);// 位运算把元素散列到各位位置
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("{");
// 遍历位桶数组
for (int i = 0; i < table.length; i++) {
Node2 tmp = table[i];
//遍历链表
while(tmp != null) {
sb.append(tmp.key + ":" + tmp.value + ",");
tmp = tmp.next;
}
}
sb.setCharAt(sb.length() - 1, '}');
return sb.toString();
}
public V get(K key) {
int hash = myHash(key.hashCode(), table.length);
V value = null;
Node2 tmp = table[hash];
while(tmp != null) {
if(key.equals(tmp.key)) {//如果找到了,则返回对应的值
value = (V) tmp.value;
break;
}else {
tmp = tmp.next;
}
}
return value;
}
public static void main(String[] args) {
MyHashMap4<Integer, String> map = new MyHashMap4<>();
map.put(10, "aa");
map.put(20, "bb");
map.put(30, "cc");
map.put(10, "ssss");
map.put(24, "dd");
map.put(56, "ee");
map.put(72, "ff");
map.put(56, "java");
System.out.println(map);
System.out.println(map.get(10));
System.out.println(map.get(30));
System.out.println(map.get(72));
System.out.println(map.get(78));
}
}
运行测试:

泛型完毕。
至于扩容和remove方法可以参考我的另外两篇:
理解java容器底层原理–手动实现ArryList
https://mp.csdn.net/console/editor/html/105032218
和
理解java容器底层原理–手动实现LinkedList
重视基础,才能走的更远。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号