Kubernetes之POD
什么是Pod
Pod是可以创建和管理Kubernetes计算的最小可部署单元。一个Pod代表着集群中运行的一个进程。
Pod就像是豌豆荚一样,它由一个或者多个容器组成(例如Docker容器),它们共享容器存储、网络和容器运行配置项。Pod中的容器总是被同时调度,有共同的运行环境。你可以把单个Pod想象成是运行独立应用的“逻辑主机”——其中运行着一个或者多个紧密耦合的应用容器——在有容器之前,这些应用都是运行在几个相同的物理机或者虚拟机上。
尽管kubernetes支持多种容器运行时,但是Docker依然是最常用的运行时环境,我们可以使用Docker的术语和规则来定义Pod。
Pod中共享的环境包括Linux的namespace,cgroup和其他可能的隔绝环境,这一点跟Docker容器一致。在Pod的环境中,每个容器中可能还有更小的子隔离环境。
Pod中的容器共享IP地址和端口号,它们之间可以通过localhost互相发现。它们之间可以通过进程间通信,例如SystemV信号或者POSIX共享内存。不同Pod之间的容器具有不同的IP地址,不能直接通过IPC通信。
Pod中的容器也有访问共享volume的权限,这些volume会被定义成pod的一部分并挂载到应用容器的文件系统中。
就像每个应用容器,pod被认为是临时实体。在Pod的生命周期中,pod被创建后,被分配一个唯一的ID(UID),调度到节点上,并一致维持期望的状态直到被终结(根据重启策略)或者被删除。如果node死掉了,分配到了这个node上的pod,在经过一个超时时间后会被重新调度到其他node节点上。一个给定的pod(如UID定义的)不会被“重新调度”到新的节点上,而是被一个同样的pod取代,如果期望的话甚至可以是相同的名字,但是会有一个新的UID(查看replication controller获取详情)。
Pod中如何管理多个容器
Pod中可以同时运行多个进程(作为容器运行)协同工作。同一个Pod中的容器会自动的分配到同一个 node 上。同一个Pod中的容器共享资源、网络环境和依赖,它们总是被同时调度。
注意在一个Pod中同时运行多个容器是一种比较高级的用法。只有当你的容器需要紧密配合协作的时候才考虑用这种模式。例如,你有一个容器作为web服务器运行,需要用到共享的volume,有另一个“sidecar”容器来从远端获取资源更新这些文件。如图

Pod中可以共享两种资源
- 网络 每个Pod都会被分配一个唯一的IP地址。Pod中的所有容器共享网络空间,包括IP地址和端口。Pod内部的容器可以使用
localhost互相通信。Pod中的容器与外界通信时,必须分配共享网络资源(例如使用宿主机的端口映射)。 - 存储 可以Pod指定多个共享的Volume。Pod中的所有容器都可以访问共享的volume。Volume也可以用来持久化Pod中的存储资源,以防容器重启后文件丢失。
使用Pod
我通常把pod分为两类:
- 自主式Pod 这种Pod本身是不能自我修复的,当Pod被创建后(不论是由你直接创建还是被其他Controller),都会被Kuberentes调度到集群的Node上。直到Pod的进程终止、被删掉、因为缺少资源而被驱逐、或者Node故障之前这个Pod都会一直保持在那个Node上。Pod不会自愈。如果Pod运行的Node故障,或者是调度器本身故障,这个Pod就会被删除。同样的,如果Pod所在Node缺少资源或者Pod处于维护状态,Pod也会被驱逐。
- 控制器管理的Pod Kubernetes使用更高级的称为Controller的抽象层,来管理Pod实例。Controller可以创建和管理多个Pod,提供副本管理、滚动升级和集群级别的自愈能力。例如,如果一个Node故障,Controller就能自动将该节点上的Pod调度到其他健康的Node上。虽然可以直接使用Pod,但是在Kubernetes中通常是使用Controller来管理Pod的。

上图所示是Pod的组成示意图,我们看到每个Pod都有一个特殊的被称为“根容器”的Pause 容器。 Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器,每个Pod还包含一个或者多个紧密相关的用户业务容器。
Pod的终止
因为Pod作为在集群的节点上运行的进程,所以在不再需要的时候能够优雅的终止掉是十分必要的(比起使用发送KILL信号这种暴力的方式)。用户需要能够放松删除请求,并且知道它们何时会被终止,是否被正确的删除。用户想终止程序时发送删除pod的请求,在pod可以被强制删除前会有一个宽限期,会发送一个TERM请求到每个容器的主进程。一旦超时,将向主进程发送KILL信号并从API server中删除。如果kubelet或者container manager在等待进程终止的过程中重启,在重启后仍然会重试完整的宽限期。
示例流程如下:
- 用户发送删除pod的命令,默认宽限期是30秒;
- 在Pod超过该宽限期后API server就会更新Pod的状态为“dead”;
- 在客户端命令行上显示的Pod状态为“terminating”;
- 跟第三步同时,当kubelet发现pod被标记为“terminating”状态时,开始停止pod进程:1 如果在pod中定义了preStop hook,在停止pod前会被调用。如果在宽限期过后,preStop hook依然在运行,第二步会再增加2秒的宽限期;2 向Pod中的进程发送TERM信号;
- 跟第三步同时,该Pod将从该service的端点列表中删除,不再是replication controller的一部分。关闭的慢的pod将继续处理load balancer转发的流量;
- 过了宽限期后,将向Pod中依然运行的进程发送SIGKILL信号而杀掉进程。
- Kublete会在API server中完成Pod的的删除,通过将优雅周期设置为0(立即删除)。Pod在API中消失,并且在客户端也不可见。
删除宽限期默认是30秒。 kubectl delete命令支持 --grace-period=<seconds> 选项,允许用户设置自己的宽限期。如果设置为0将强制删除pod。在kubectl>=1.5版本的命令中,你必须同时使用 --force 和 --grace-period=0 来强制删除pod。
Pause 容器
在接触Kubernetes的初期,便知道集群搭建需要下载一个gcr.io/google_containers/pause-amd64:3.0镜像,然后每次启动一个容器,都会伴随一个pause容器的启动。
但这个pause容器的功能是什么,它是如何做出来的,以及为何都伴随容器启动等等。这些问题一直在我心里,如今有缘学习相关内容。
189fbd12e903 rancher/rancher-agent:v2.0.6 "run.sh -- share-r..." 10 days ago Exited (0) 10 days ago share-mnt [root@k8s-master ~]# docker ps -a | grep pause-amd64 f30cc4df0eff rancher/pause-amd64:3.1 "/pause" 4 days ago Up 4 days k8s_POD_confserver-bdf79c8cb-xxf82_confserver_f92c3ecc-a11b-11e8-a1c4-005056936694_0 af651c01f1e4 rancher/pause-amd64:3.1 "/pause" 5 days ago Up 5 days k8s_POD_jenkins-5cf89c84f6-h4hs6_jenkins_954201e0-a057-11e8-a1c4-005056936694_0 7ab1920551ca rancher/pause-amd64:3.1 "/pause" 10 days ago Up 10 days k8s_POD_nfs-provisioner-2cjpp_nfs-provisioner_a24395b7-9c42-11e8-a1c4-005056936694_0 4f89f1c2e83b rancher/pause-amd64:3.1 "/pause" 10 days ago Up 10 days k8s_POD_cattle-node-agent-s8s75_cattle-system_a2443a27-9c42-11e8-a1c4-005056936694_0 74ff9a7eb776 rancher/pause-amd64:3.1 "/pause" 10 days ago Up 10 days k8s_POD_nginx-ingress-controller-gl7k6_ingress-nginx_a239056d-9c42-11e8-a1c4-005056936694_0 76a3177f05ec rancher/pause-amd64:3.1 "/pause" 10 days ago Up 10 days k8s_POD_calico-node-7vzlj_kube-system_a2391472-9c42-11e8-a1c4-005056936694_0
kubernetes中的pause容器主要为每个业务容器提供以下功能:
- 在pod中担任Linux命名空间共享的基础;
- 启用pid命名空间,开启init进程。
Pod 的生命周期
Pod phase
Pod 的 status 在信息保存在 Podstatus 中定义,其中有一个 phase 字段。
Pod 的相位(phase)是 Pod 在其生命周期中的简单宏观概述。该阶段并不是对容器或 Pod 的综合汇总,也不是为了做为综合状态机。
Pod 相位的数量和含义是严格指定的。除了本文档中列举的状态外,不应该再假定 Pod 有其他的 phase 值。
下面是 phase 可能的值:
| 值 | 描述 |
| Pending | Pod已被Kubernetes系统接受,但尚未创建一个或多个Container图像。这包括计划之前的时间以及通过网络下载图像所花费的时间,这可能需要一段时间 |
| Running | Pod已绑定到节点,并且已创建所有Container。至少有一个Container仍在运行,或者正在启动或重新启动 |
| Succeeded | Pod中的所有容器都已成功终止,并且不会重新启动 |
| Failed | Pod中的所有容器都已终止,并且至少有一个Container已终止失败。也就是说,Container要么退出非零状态,要么被系统终止 |
| Unknown | 由于某种原因,无法获得Pod的状态,这通常是由于与Pod的主机通信时出错 |
下图是Pod的生命周期示意图,从图中可以看到Pod状态的变化。
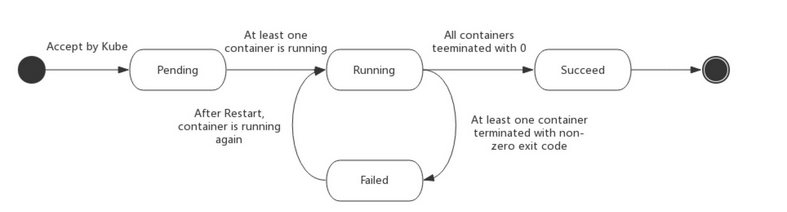
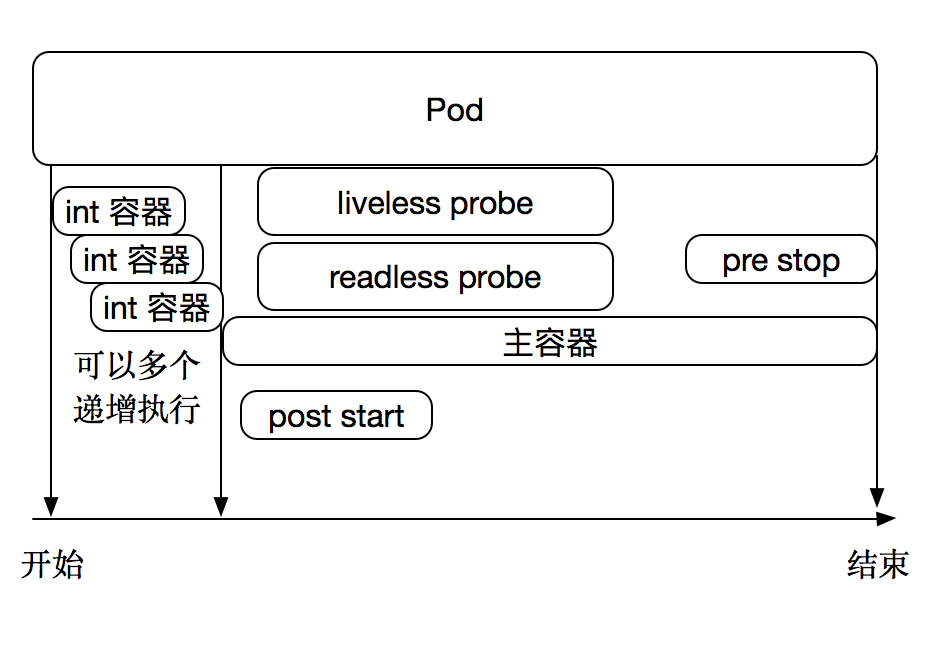
在pod生命周期中可以做的一些事情。主容器启动前可以完成初始化容器,初始化容器可以有多个,他们是串行执行的,执行完成后就推出了,在主程序刚刚启动的时候可以指定一个post start 主程序启动开始后执行一些操作,在主程序结束前可以指定一个 pre stop 表示主程序结束前执行的一些操作。在程序启动后可以做两类检测 liveness probe 和 readness probe。如下图:
POD的重启策略
restartPolicy:
- Always 默认策略
- OnFailure 只有状态错误的时候重启(正常退出不会重启)
- Never 重来不重启
Pod条件
Pod有一个PodStatus,它有一个PodConditions 数组, Pod已经或没有通过它。PodCondition数组的每个元素都有六个可能的字段:
-
该
lastProbeTime字段提供上次探测Pod条件的时间戳。 - 该
lastTransitionTime字段提供Pod最后从一个状态转换到另一个状态的时间戳 - 该
message字段是人类可读的消息,指示有关转换的详细信息 - 该
reason字段是该条件最后一次转换的唯一,单字,CamelCase原因 - 该
status字段是一个字符串,可能的值为“True”,“False”和“Unknown” - 该
type字段是一个包含以下可能值的字符串:PodScheduled:Pod已被安排到一个节点;- Read: Pod能够提供请求,应该添加到所有匹配服务的负载平衡池中;
Initialized:所有init容器都已成功启动;- U
nschedulable:调度程序现在无法调度Pod,例如由于缺少资源或其他限制 - C
ontainersReady:Pod中的所有容器都已准备就绪
容器探针
探针是由 Kubelet 对容器执行的定期诊断。要执行诊断,kubelet 调用由容器实现的 Handler。有三种类型的处理程序:
- ExecAction:在Container内执行指定的命令。如果命令以状态代码0退出,则认为诊断成功
- TCPSocketAction:对指定端口上的Container的IP地址执行TCP检查。如果端口打开,则诊断被认为是成功的
- HTTPGetAction:对指定端口和路径上的Container的IP地址执行HTTP Get请求。如果响应的状态代码大于或等于200且小于400,则认为诊断成功。
每个探针都有三个结果之一:
- 成功:Container通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不应采取任何措施。
kubelet可以选择在运行容器上执行两种探测并对其做出反应:
livenessProbe:指示Container是否正在运行。如果存活探测失败,则kubelet会杀死Container,并且Container将受其重启策略的约束。如果Container未提供存活探测,则默认状态为Success。readinessProbe:指示Container是否已准备好为服务请求。如果就绪探测失败,则端点控制器会从与Pod匹配的所有服务的端点中删除Pod的IP地址。初始延迟之前的默认就绪状态是Failure。如果Container未提供就绪状态探测,则默认状态为Success。
什么时候应该使用livenessProbe或readinessProbe探针?
如果您的Container中的进程在遇到问题或变得不健康时自行崩溃,则不一定需要存活探测器; kubelet将根据Pod的restartPolicy自动执行正确的操作。
如果您希望在容器探测失败时杀死并重新启动,则指定存活探测,并指定restartPolicy为Always或OnFailure。
如果您只想在探测成功时开始向Pod发送流量,请指定就绪探测。在这种情况下,就绪探针可能与存活探测相同,但spec中就绪探针的存在意味着Pod将在不接收任何流量的情况下启动,并且仅在探针探测成功后才开始接收流量。
如果Container需要在启动期间处理大型数据,配置文件或迁移,请指定就绪探针。
如果您希望Container能够自行维护,您可以指定一个就绪探针,该探针检查特定于就绪的端点,该端点与活动探针不同。
请注意,如果您只想在Pod被删除时排除请求,则不一定需要就绪探测; 在删除Pod时,无论是否存在就绪探针,Pod都会自动将其置于未完成状态。当等待 Pod 中的容器停止时,Pod 仍处于未完成状态。
livenessProbe详解
kubectl explain pod.spec.containers.livenessProbe
- exec command 的方式探测 例如 ps 一个进程
- failureThreshold 探测几次失败 才算失败 默认是连续三次
- periodSeconds 每次的多长时间探测一次 默认10s
- timeoutSeconds 探测超市的秒数 默认1s
- initialDelaySeconds 初始化延迟探测,第一次探测的时候,因为主程序未必启动完成
- tcpSocket 检测端口的探测
- httpGet http请求探测
案例
apiVersion: v1 kind: Pod metadata: name: liveness-exec-pod namespace: default labels: name: myapp spec: containers: - name: livess-exec image: busybox:latest imagePullPolicy: IfNotPresent command: ["/bin/sh","-c","touch /tmp/test; sleep 30; rm -f /tmp/test; sleep 3600"] livenessProbe: exec: command: ["test","-e","/tmp/test"] initialDelaySeconds: 1 periodSeconds: 3
看一下描述信息
$ kubectl describe pods liveness-exec-pod ...... Command: /bin/sh -c touch /tmp/test; sleep 30; rm -f /tmp/test; sleep 3600 State: Running Started: Thu, 23 Aug 2018 11:09:28 -0400 Last State: Terminated Reason: Error Exit Code: 137 Started: Thu, 23 Aug 2018 11:08:22 -0400 Finished: Thu, 23 Aug 2018 11:09:28 -0400 Ready: True Restart Count: 1 重启次数一次(会叠加) Liveness: exec [test -e /tmp/test] delay=1s timeout=1s period=3s #success=1 #failure=3 失败3次 Environment: <none> ..... $ kubectl get pods NAME READY STATUS RESTARTS AGE jdk-94bcfc779-fs2cl 1/1 Running 0 9d liveness-exec-pod 1/1 Running 3 (重启三次了) 4m
httpGet 案例
apiVersion: v1 kind: Pod metadata: name: liveness-httpget-pod namespace: default labels: name: myapp spec: containers: - name: livess-httpget image: ikubernetes/myapp:v1 ports: - name: http containerPort: 80 imagePullPolicy: IfNotPresent livenessProbe: httpGet: port: http path: /index.html initialDelaySeconds: 1 periodSeconds: 3
readinessProbe详解
kubectl explain pod.spec.containers.readinessProbe
- exec command 的方式探测 例如 ps 一个进程
- failureThreshold 探测几次失败 才算失败 默认是连续三次
- periodSeconds 每次的多长时间探测一次 默认10s
- timeoutSeconds 探测超市的秒数 默认1s
- initialDelaySeconds 初始化延迟探测,第一次探测的时候,因为主程序未必启动完成
- tcpSocket 检测端口的探测
- httpGet http请求探测
案例
apiVersion: v1 kind: Pod metadata: name: readiness-httpget-pod namespace: default labels: name: myapp spec: containers: - name: readiness-httpget image: ikubernetes/myapp:v1 ports: - name: http containerPort: 80 imagePullPolicy: IfNotPresent readinessProbe: httpGet: port: http path: /index.html initialDelaySeconds: 1 periodSeconds: 3
详情
Name: readiness-httpget-pod Namespace: default Node: rancher-node/172.16.138.170 Start Time: Sun, 26 Aug 2018 10:13:03 -0400 Labels: name=myapp Annotations: cni.projectcalico.org/podIP=10.42.0.194/32 kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"labels":{"name":"myapp"},"name":"readiness-httpget-pod","namece":"default"},"spec":{"c... Status: Running IP: 10.42.0.194 Controllers: <none> Containers: readiness-httpget: Container ID: docker://7eacd3604aa53352e9d744a33b527a35b6a4e21e5a47b26c5d1e6ead7f045c3f Image: ikubernetes/myapp:v1 Image ID: docker-pullable://ikubernetes/myapp@sha256:9c3dc30b5219788b2b8a4b065f548b922a34479577befb54b03330999d30d513 Port: 80/TCP State: Running Started: Sun, 26 Aug 2018 10:13:09 -0400 Ready: True Restart Count: 0 Readiness: http-get http://:http/index.html delay=1s timeout=1s period=3s #success=1 #failure=3 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-ws5gd (ro) Conditions: Type Status Initialized True Ready True PodScheduled True Volumes:
.....
lifecycle详解
极少数会用到
kubectl explain pod.spec.containers.lifecycle
- postStart 启动后执行
- preStop 终止前执行
同样是有三种类型
- exec command 的方式 例如 初始化环境
- httpGet http方式
- tcpSocket TCP port 的方式
案例
apiVersion: v1 kind: Pod metadata: name: lifecycle-poststart namespace: default labels: name: myapp tier: appfront spec: containers: - name: lifecycle-poststart-pod image: nginx imagePullPolicy: IfNotPresent lifecycle: postStart: exec: command: ["/bin/sh","-c","echo Home+Page >> /usr/share/message"] preStop: exec: command: ["/usr/sbin/nginx","-s","quit"]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号