【网络排查】 挥手:Nginx日志报connection reset by peer是怎么回事?
我们经常看到Nginx 的日志里面,可能就有 connection reset by peer 这种报错。“连接被对端 reset(重置)”,这个字面上的意思是看明白了。但是,心里不免发毛:
- 这个 reset 会影响我们的业务吗,这次事务到底有没有成功呢?
- 这个 reset 发生在具体什么阶段,属于 TCP 的正常断连吗?
- 我们要怎么做才能避免这种 reset 呢?
先,你需要理解下 connection reset by peer 的含义。熟悉 TCP 的话,你应该会想到这大概是对端(peer)回复了 TCP RST(也就是这里的 reset),终止了一次 TCP 连接。其实,这也是我们做网络排查的第一个要点:把应用层的信息,“翻译”成传输层和网络层的信息。
这里我说的“应用层信息”,可能是以下这些:
- 应用层日志,包括成功日志、报错日志,等等;
- 应用层性能数据,比如 RPS(每秒请求数),transaction time(处理时间)等;
- 应用层载荷,比如 HTTP 请求和响应的 header、body 等。
而“传输层 / 网络层信息”,可能是以下种种:
- 传输层:TCP 序列号(Sequence Number)、确认号(Acknowledge Number)、MSS、接收窗口(Receive Window)、拥塞窗口(Congestion Window)、时延(Latency)、重复确认(DupAck)、选择性确认(Selective Ack)、重传(Retransmission)、丢包(Packet loss)等。
- 网络层:IP 的 TTL、MTU、跳数(hops)、路由表等。
可见,这两大类(应用 vs 网络)信息的视角和度量标准完全不同,所以几乎没办法直接挂钩。而这,也就造成了问题排查方面的两大鸿沟。
- 应用现象跟网络现象之间的鸿沟:你可能看得懂应用层的日志,但是不知道网络上具体发生了什么。
- 工具提示跟协议理解之间的鸿沟:你看得懂 Wireshark、tcpdump 这类工具的输出信息的含义,但就是无法真正地把它们跟你对协议的理解对应起来
你需要具备把两大鸿沟填平的能力,有了这个能力,你也就有了能把两大类信息(应用信息和网络信息)联通起来的“翻译”的能力。这正是网络排查的核心能力。
案例 1:connection reset by peer?
大致应用日志是这样的:
这里我们理解一下应用日志相关信息:
- recv() failed:这里的 recv() 是一个系统调用,也就是 Linux 网络编程接口。它的作用呢,看字面就很容易理解,就是用来接收数据的。我们可以直接 man recv,看到这个系统调用的详细信息,也包括它的各种异常状态码。
- 104:这个数字也是跟系统调用有关的,它就是 recv() 调用出现异常时的一个状态码,这是操作系统给出的。在 Linux 系统里,104 对应的是 ECONNRESET,也正是一个 TCP 连接被 RST 报文异常关闭的情况。
- upstream:在 Nginx 等反向代理软件的术语里,upstream 是指后端的服务器。也就是说,客户端把请求发到 Nginx,Nginx 会把请求转发到 upstream,等后者回复 HTTP 响应后,Nginx 把这个响应回复给客户端。注意,这里的“客户端 <->Nginx”和“Nginx<->upstream”是两条独立的 TCP 连接,也就是下图这样:

这里我们要找到 TCP RST 报文,所以使用下面的过滤条件:
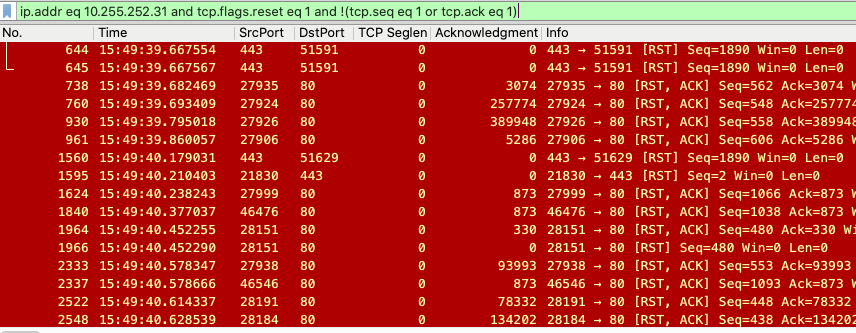
为了找到它们,我们需要再增加一些明确的搜索条件。还记得我提到过的两大鸿沟吗?一个是应用现象跟网络现象之间的鸿沟,一个是工具提示跟协议理解之间的鸿沟。现在为了跨越第一个鸿沟,我们需要把搜索条件落实具体,针对当前案例来说,就是基于以下条件寻找数据包:
- 既然这些网络报文跟应用层的事务有直接关系,那么报文中应该就包含了请求相关的数据,比如字符串、数值等。当然,这个前提是数据本身没有做过特定的编码,否则的话,报文中的二进制数据,跟应用层解码后看到的数据就会完全不同。
- 这些报文的发送时间,应该跟日志的时间是吻合的。
对于条件 1,我们可以利用 Nginx 日志中的 URL 等信息;对于条件 2,我们就要利用日志的时间。其实,在开头部分展示的 Nginx 日志中,就有明确的时间(2015/12/01 15:49:48),虽然只是精确到秒,但很多时候已经足以帮助我们进一步缩小范围了。
那么,在 Wireshark 中搜索“特定时间段内的报文”,又要如何做到呢?这就是我要介绍给你的又一个搜索技巧:使用 frame.time 过滤器。比如下面这样:
这就可以帮助我们定位到跟上面 Nginx 日志中,第一条日志的时间匹配的报文了。为了方便你理解,我直接把这条日志复制到这里给你参考:
我们再结合前面的搜索条件,就得到了下面这个更加精确的过滤条件:
这次我们终于非常成功地锁定到只有 3 个 RST 报文了:

我们先来看看,11393 号报文所属的流是什么情况?
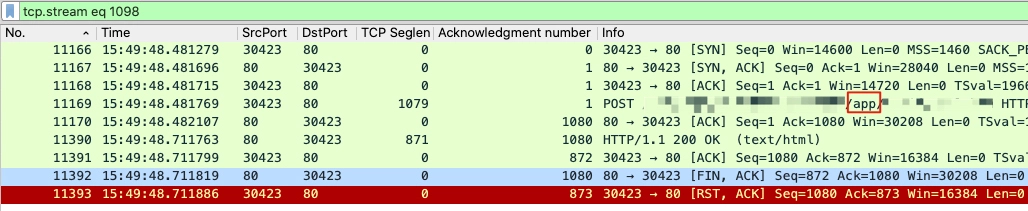
原来,11448 跟 11450 是在同一个流里面的。现在清楚了,3 个 RST,分别属于 2 个 HTTP 事务。
你再仔细对比一下两个图中的红框部分,是不是不一样?它们分别是对应了一个 URL 里带“weixin”字符串的请求,和一个 URL 里带“app”字符串的请求。那么,在这个时间点(15:49:48)对应的日志是关于哪一个 URL 的呢?
你只要往右拖动一下鼠标,就能看到 POST URL 里的“weixin”字符串了。而包号 11448 和 11450 这两个 RST 所在的 TCP 流的请求,也是带“weixin”字符串的,所以它们就是匹配上面这条日志的 RST!如果你还没有完全理解,我这里帮你小结一下,为什么我们可以确定这个 TCP 流就是对应这条日志的,主要三点原因:
- 时间吻合;
- RST 行为吻合;
- URL 路径吻合。
根据HTTP过程和数据包情况可以是一下过程

也就是说,握手和 HTTP POST 请求和响应都正常,但是客户端在对 HTTP 200 这个响应做了 ACK 后,随即发送了 RST+ACK,而正是这个行为破坏了正常的 TCP 四次挥手。也正是
这个 RST,导致服务端 Nginx 的 recv() 调用收到了 ECONNRESET 报错,从而进入了 Nginx 日志,成为一条 connection reset by peer。
这个对应用产生了什么影响呢?对于服务端来说,表面上至少是记录了一次报错日志。但是有意思的是,这个 POST 还是成功了,已经被正常处理完了,要不然 Nginx 也不会回复 HTTP 200。
对于客户端呢?还不好说,因为我们并没有客户端的日志,也不排除客户端认为这次是失败,可能会有重试等等。
我们把这个结论告诉给了客户,他们悬着的心稍稍放下了:至少 POST 的数据都被服务端处理了。当然,他们还需要查找客户端代码的问题,把这个不正常的 RST 行为给修复掉,但是至少已经不用担心数据是否完整、事务是否正常了。
我们现在就可以回答了:
- 这个 reset 是否影响业务,还要继续查客户端应用,但服务端事务是成功被处理了。
- 这个 reset 发生在事务处理完成后,但不属于 TCP 正常断连,还需要继续查客户端代码问题。
- 要避免这种 reset,需要客户端代码进行修复。
一个 FIN 就完成了 TCP 挥手?
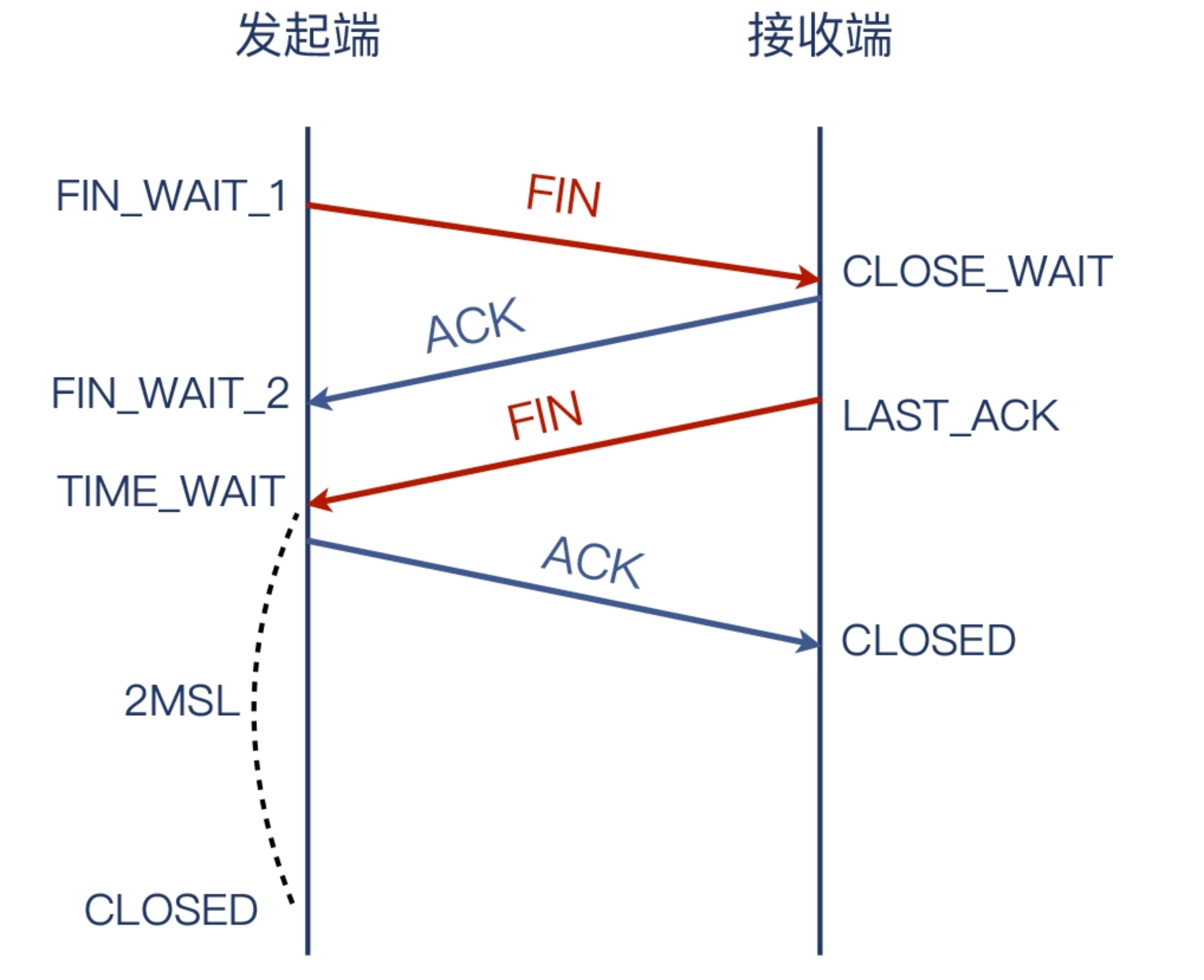
我在图上没有用“客户端”和“服务端”这种名称,而是叫“发起端”和“接收端”。这是因为,TCP 的挥手是任意一端都可以主动发起的。也就是说,挥手的发起权并不固定给客户端或者服务端。这跟 TCP 握手不同:握手是客户端发起的。或者换个说法:发起握手的就是客户端。在握手阶段,角色分工十分明确。
可是有一次,一个客户向我报告这么一个奇怪的现象:他们偶然发现,他们的应用在 TCP 关闭阶段,只有一个 FIN,而不是两个 FIN。这好像不符合常理啊。我也觉得有意思,就一起看了他们这个抓包文件:

确实奇怪,真的只有一个 FIN。这两端的操作系统竟然能容忍这种事情发生?TCP 里一个报文可以搭另一个报文的顺风车(Piggybacking),以提高 TCP 传输的运载效率。所以,TCP 挥手倒不是一定要四个报文,Piggybacking 后,就可能是 3 个报文了。看起来就类似三次挥手。
那这次的案例,我们在 Wireshark 中看到了后两个报文,即接收端回复的 FIN+ACK 和发起端的最后一个 ACK。那么,第一个 FIN 在哪里呢?从 Wireshark 的截图中,确实看不出来。当然,从 Wireshark 的图里,我们甚至可以认为,这次连接是服务端发起的,它发送了 FIN+ACK,而客户端只回复了一个 ACK,这条连接就结束了。这样的解读更加诡异,却也符合 Wireshark 的展示。

但是,Wireshark 的主界面还有个特点,就是当它的 Information 列展示的是应用层信息时,这个报文的 TCP 层面的控制信息就不显示了。所以,上面的 POST 请求报文,其 Information 列就是 POST 方法加上具体的 URL。它的 TCP 信息,包括序列号、确认号、标志位等,都需要到详情里面去找。我们先选中这个 POST 报文,然后到界面中间的 TCP 详情部分去看看:
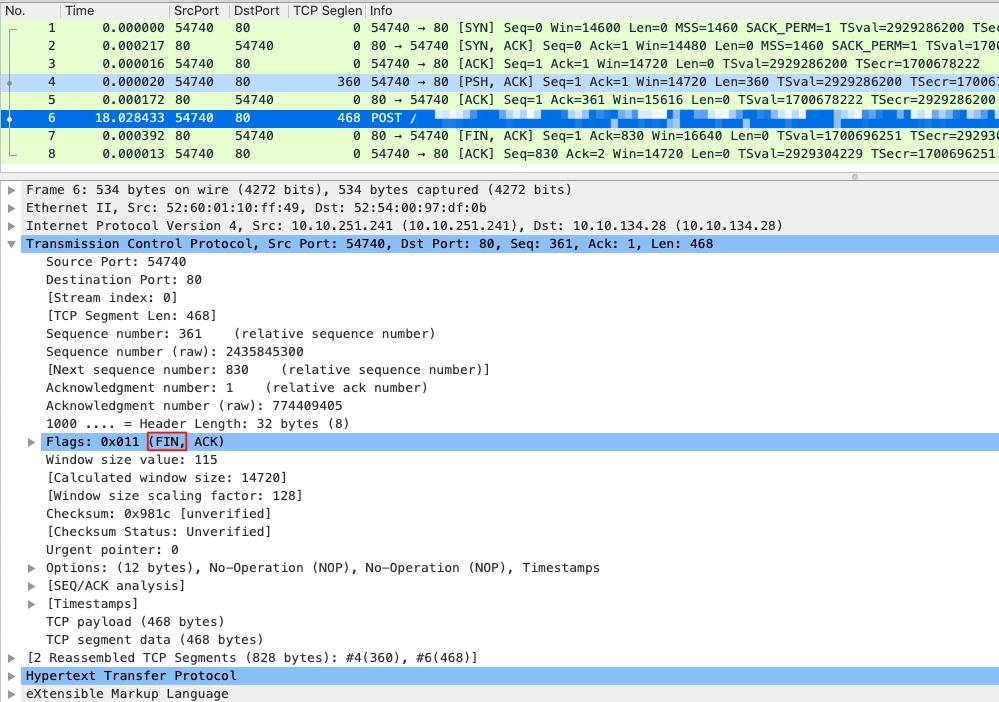
原来,第一个 FIN 控制报文,并没有像常规的那样单独出现,而是合并(Piggybacking)在 POST 报文里!所以,整个挥手过程,其实依然十分标准,完全遵循了协议规范。仅仅是因为 Wireshark 的显示问题,带来了一场小小的误会。虽然还有一个“为什么没有 HTTP 响应报文”的问题,但是 TCP 挥手方面的问题,已经得到了合理的解释了。
__EOF__

本文链接:https://www.cnblogs.com/xzkzzz/p/16005034.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类
2019-03-14 kubernetes之监控Prometheus实战--邮件告警--微信告警(二)