kubernetes之监控Prometheus实战--邮件告警--微信告警(二)
kubernetes插件
上面是我们最常用的 grafana 当中的 dashboard 的功能的使用,然后我们也可以来进行一些其他的系统管理,比如添加用户,为用户添加权限等等,我们也可以安装一些其他插件,比如 grafana 就有一个专门针对 Kubernetes 集群监控的插件:grafana-kubernetes-app
要安装这个插件,需要到 grafana 的 Pod 里面去执行安装命令:
kubectl get pods -n kube-ops NAME READY STATUS RESTARTS AGE grafana-75f64c6759-gknxz 1/1 Running 0 1d node-exporter-48b6g 1/1 Running 0 7d node-exporter-4swrs 1/1 Running 0 7d node-exporter-4w2dd 1/1 Running 0 7d node-exporter-fcp9x 1/1 Running 0 7d prometheus-56b6d68c48-6xpvw 1/1 Running 0 7d [root@k8s-master ~]# kubectl exec -it grafana-75f64c6759-gknxz /bin/bash -n kube-ops grafana@grafana-75f64c6759-gknxz:/usr/share/grafana$ grafana-cli plugins install grafana-kubernetes-app installing grafana-kubernetes-app @ 1.0.1 from url: https://grafana.com/api/plugins/grafana-kubernetes-app/versions/1.0.1/download into: /var/lib/grafana/plugins ✔ Installed grafana-kubernetes-app successfully Restart grafana after installing plugins . <service grafana-server restart>
安装完成后需要重启 grafana 才会生效,我们这里直接删除 Pod,重建即可,然后回到 grafana 页面中,切换到 plugins 页面可以发现下面多了一个 Kubernetes 的插件,点击进来启用即可,然后点击Next up旁边的链接配置集群
这里我们可以添加一个新的 Kubernetes 集群,这里需要填写集群的访问地址:https://kubernetes.default,然后比较重要的是集群访问的证书,勾选上TLS Client Auth和With CA Cert这两项。

集群访问的证书文件,用我们访问集群的 kubectl 的配置文件中的证书信息(~/.kube/config)即可,其中属性certificate-authority-data、client-certificate-data、client-key-data就对应这 CA 证书、Client 证书、Client 私钥,不过 config 文件里面的内容是base64编码过后的,所以我们这里填写的时候要做base64解码。
配置完成后,可以直接点击Deploy(实际上前面的课程中我们都已经部署过相关的资源了),然后点击Save,就可以获取到集群的监控资源信息了。
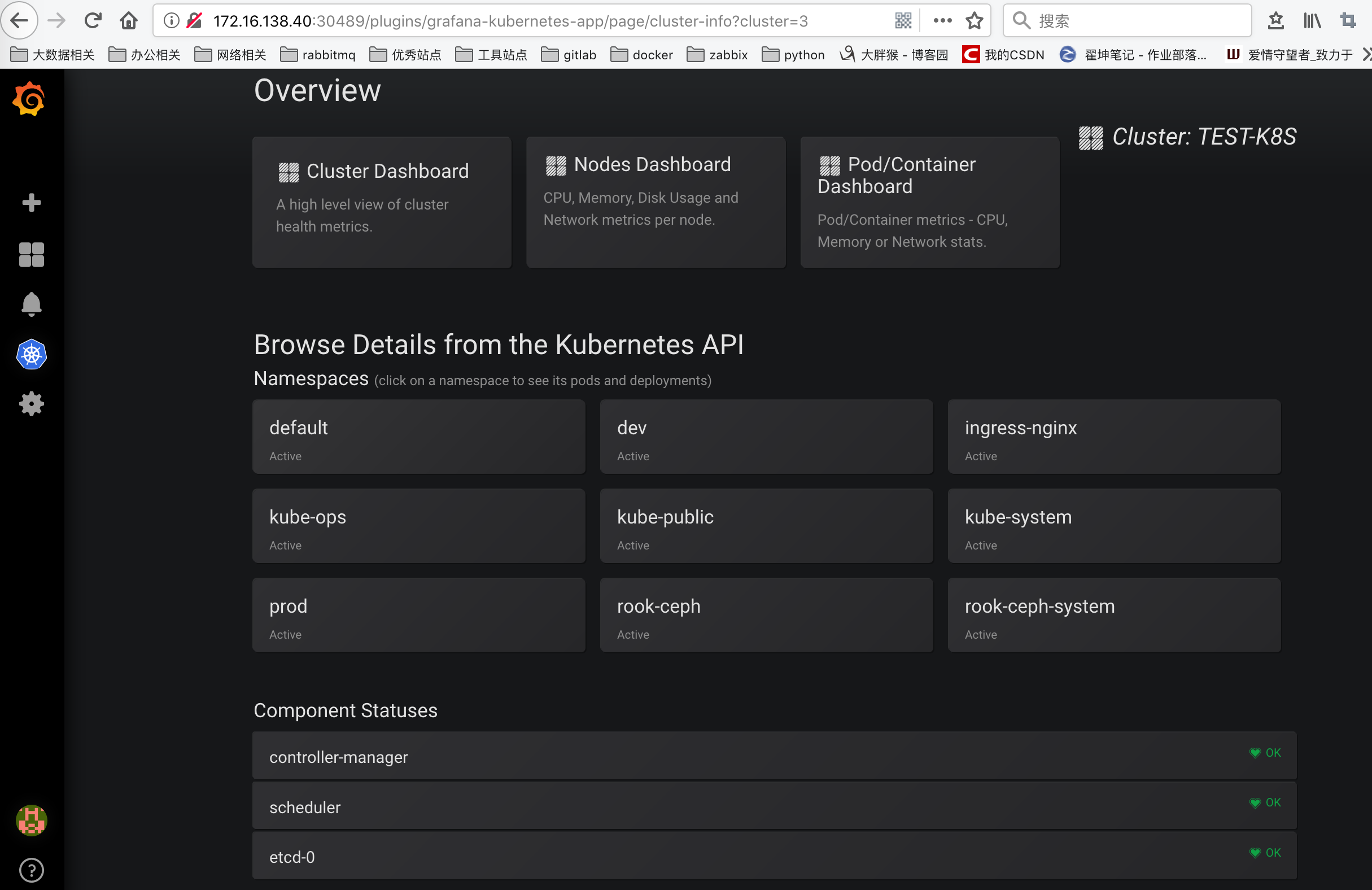
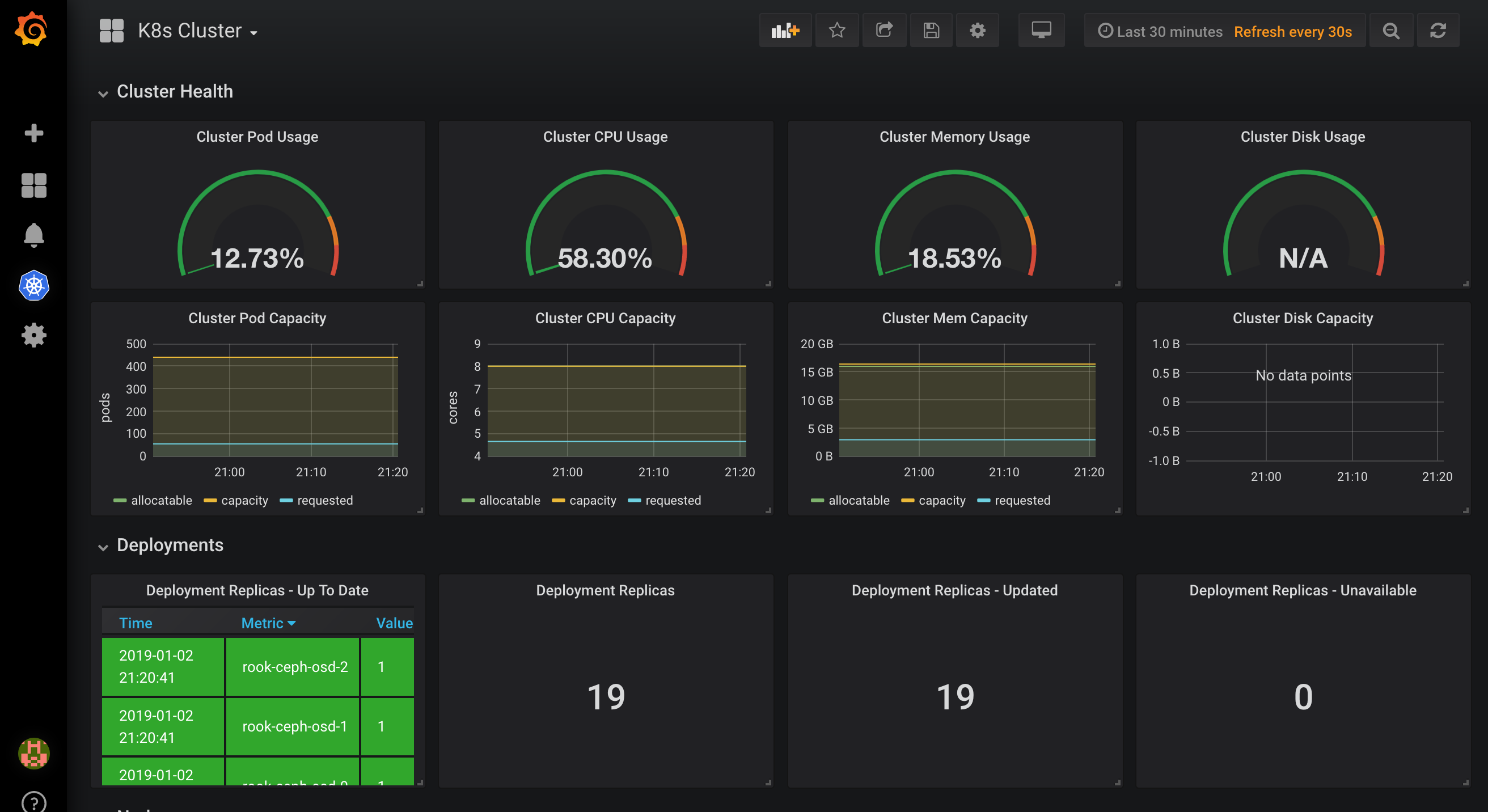
可以看到上面展示了整个集群的状态,可以查看上面的一些 Dashboard:
AlertManager
Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息进行去重,降噪,分组等,是一款前卫的告警通知系统。
安装
从官方文档https://prometheus.io/docs/alerting/configuration/中我们可以看到下载AlertManager二进制文件后,可以通过下面的命令运行:
$ ./alertmanager --config.file=simple.yml
其中-config.file参数是用来指定对应的配置文件的,由于我们这里同样要运行到 Kubernetes 集群中来,所以我们使用docker镜像的方式来安装,使用的镜像是:prom/alertmanager:v0.15.3
首先,指定配置文件,同样的,我们这里使用一个 ConfigMap 资源对象:(alertmanager-conf.yaml)
apiVersion: v1 kind: ConfigMap metadata: name: alert-config namespace: kube-ops data: config.yml: |- global: # 在没有报警的情况下声明为已解决的时间 resolve_timeout: 5m # 配置邮件发送信息 smtp_smarthost: 'smtp.qq.com:587' smtp_from: 'zhaikun1992@qq.com' smtp_auth_username: 'zhaikun1992@qq.com' smtp_auth_password: '**' #改成自己的密码 smtp_hello: 'qq.com' smtp_require_tls: false # 所有报警信息进入后的根路由,用来设置报警的分发策略 route: # 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面 group_by: ['alertname', 'cluster'] # 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。 group_wait: 30s # 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。 group_interval: 5m # 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们 repeat_interval: 5m # 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器 receiver: default # 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。 routes: - receiver: email group_wait: 10s match: team: node receivers: - name: 'default' email_configs: - to: 'zhai_kun@suixingpay.com' send_resolved: true - name: 'email' email_configs: - to: 'zhaikun1992@qq.com' send_resolved: true
这里有一个坑。如果我们邮件服务器使用的是25或者465端口的话,或报如下错误:
smtp.*****.com:465 fail to send mail alert due to 'does not advertise the STARTTLS extension
这里是一个BUG,可以参考
创建
$ kubectl create -f alertmanager-conf.yaml configmap "alert-config" created
然后配置 AlertManager 的容器,我们可以直接在之前的 Prometheus 的 Pod 中添加这个容器,对应的 YAML 资源声明如下:
- name: alertmanager image: prom/alertmanager:v0.15.3 imagePullPolicy: IfNotPresent args: - "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager/data" ports: - containerPort: 9093 name: http volumeMounts: - mountPath: "/etc/alertmanager" name: alertcfg resources: requests: cpu: 100m memory: 256Mi limits: cpu: 100m memory: 256Mi volumes: - name: alertcfg configMap: name: alert-config
这里我们将上面创建的 alert-config 这个 ConfigMap 资源对象以 Volume 的形式挂载到 /etc/alertmanager 目录下去,然后在启动参数中指定了配置文件--config.file=/etc/alertmanager/config.yml,然后我们可以来更新这个 Prometheus 的 Pod:
$ kubectl apply -f prome-deploy.yaml deployment.extensions "prometheus" configured
AlertManager 的容器启动起来后,我们还需要在 Prometheus 中配置下 AlertManager 的地址,让 Prometheus 能够访问到 AlertManager,在 Prometheus 的 ConfigMap 资源清单中添加如下配置:
alerting: alertmanagers: - static_configs: - targets: ["localhost:9093"]
更新这个资源对象后,稍等一小会儿,执行 reload 操作:
$ kubectl delete -f prome-cm.yaml configmap "prometheus-config" deleted $ kubectl create -f prome-cm.yaml configmap "prometheus-config" created kubectl get svc -n kube-ops NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE grafana NodePort 10.97.81.127 <none> 3000:30489/TCP 75d prometheus NodePort 10.111.210.47 <none> 9090:31990/TCP,9093:30250/TCP 77d $ curl -X POST "http://10.111.210.47:9090/-/reload"
报警规则
现在我们只是把AlertManager运行起来了。但是它并不知道要报什么警。因为没有任何地方告诉我们要报警,所以我们还需要配置一些报警规则来告诉我们对哪些数据进行报警。
警报规则允许你基于 Prometheus 表达式语言的表达式来定义报警报条件,并在触发警报时发送通知给外部的接收者。
同样在 Prometheus 的配置文件中添加如下报警规则配置:
rule_files:
- /etc/prometheus/rules.yml
其中rule_files就是用来指定报警规则的,这里我们同样将rules.yml文件用 ConfigMap 的形式挂载到/etc/prometheus目录下面即可:
apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: kube-ops data: prometheus.yml: | ... rules.yml: | groups: - name: test-rule rules: - alert: NodeMemoryUsage expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 20 for: 2m labels: team: node annotations: summary: "{{$labels.instance}}: High Memory usage detected" description: "{{$labels.instance}}: Memory usage is above 20% (current value is: {{ $value }}"
上面我们定义了一个名为NodeMemoryUsage的报警规则,其中:
for语句会使 Prometheus 服务等待指定的时间, 然后执行查询表达式。labels语句允许指定额外的标签列表,把它们附加在告警上。annotations语句指定了另一组标签,它们不被当做告警实例的身份标识,它们经常用于存储一些额外的信息,用于报警信息的展示之类的。
为了方便演示,我们将的表达式判断报警临界值设置为20,重新更新 ConfigMap 资源对象,由于我们在 Prometheus 的 Pod 中已经通过 Volume 的形式将 prometheus-config 这个一个 ConfigMap 对象挂载到了/etc/prometheus目录下面,所以更新后,该目录下面也会出现rules.yml文件,所以前面配置的rule_files路径也是正常的,更新完成后,重新执行reload操作,这个时候我们去 Prometheus 的 Dashboard 中切换到alerts路径下面就可以看到有报警配置规则的数据了:

因为我们配置了for等待时间,因为现在是PENDING状态。过两分钟后,我们会发现进入FIRING状态

我们可以看到页面中出现了我们刚刚定义的报警规则信息,而且报警信息中还有状态显示。一个报警信息在生命周期内有下面3种状态:
- inactive: 表示当前报警信息既不是firing状态也不是pending状态
- pending: 表示在设置的阈值时间范围内被激活了
- firing: 表示超过设置的阈值时间被激活了
我们这里的状态现在是firing就表示这个报警已经被激活了,我们这里的报警信息有一个team=node这样的标签,而最上面我们配置 alertmanager 的时候就有如下的路由配置信息了:
routes: - receiver: email group_wait: 10s match: team: node
所以我们这里的报警信息会被email这个接收器来进行报警,我们上面配置的是邮箱,所以正常来说这个时候我们会收到一封如下的报警邮件:
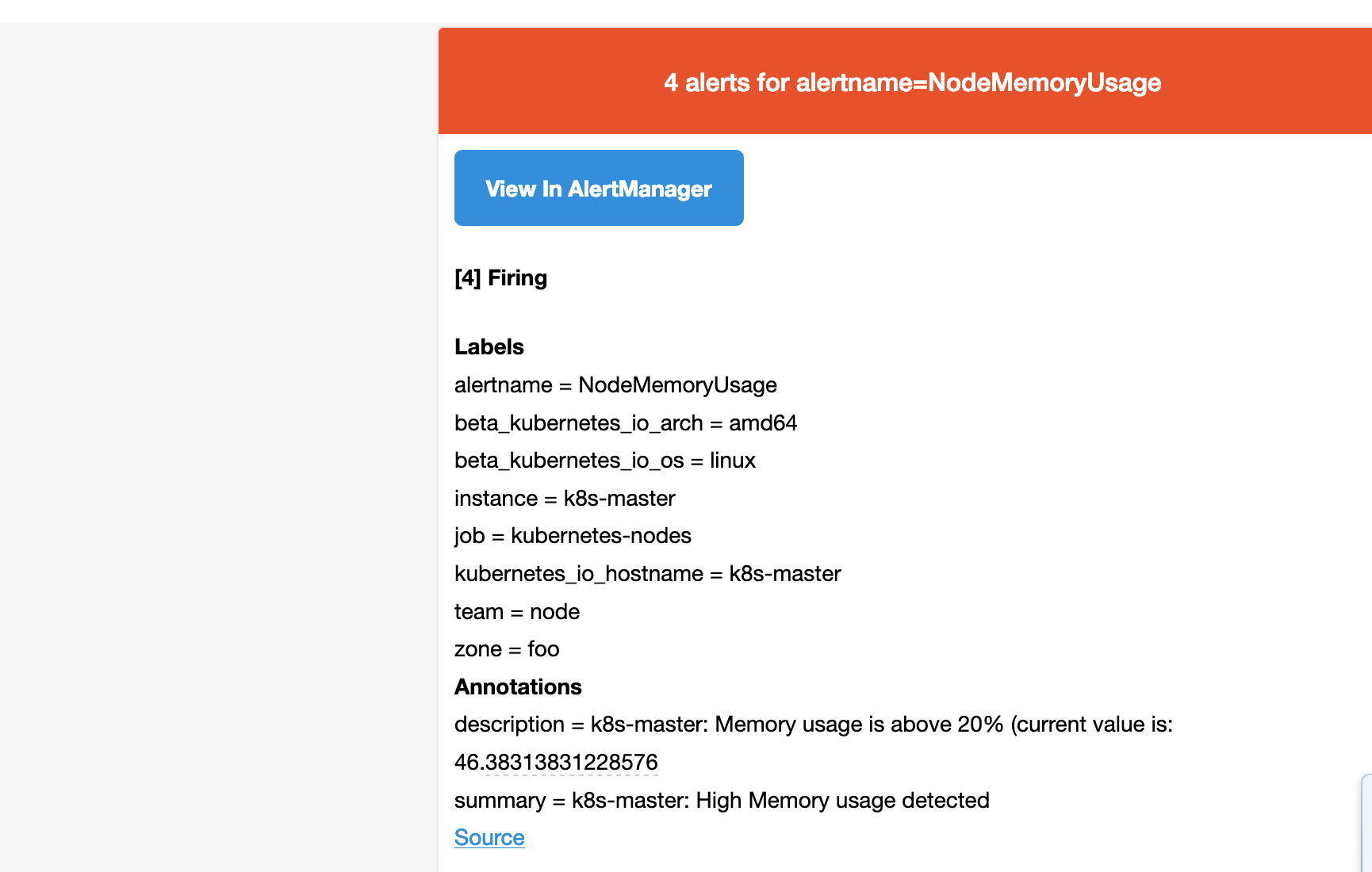
我们可以看到收到的邮件内容中包含一个View In AlertManager的链接,我们同样可以通过 NodePort 的形式去访问到 AlertManager 的 Dashboard 页面:
$ kubectl get svc -n kube-ops NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE grafana NodePort 10.97.81.127 <none> 3000:30489/TCP 75d prometheus NodePort 10.111.210.47 <none> 9090:31990/TCP,9093:30250/TCP 77d
通过任意节点IP:30250进行访问,我们就可以查看到 AlertManager 的 Dashboard 页面:

在这个页面中我们可以进行一些操作,比如过滤、分组等等,里面还有两个新的概念:Inhibition(抑制)和 Silences(静默)。
- Inhibition:如果某些其他警报已经触发了,则对于某些警报,Inhibition 是一个抑制通知的概念。例如:一个警报已经触发,它正在通知整个集群是不可达的时,Alertmanager 则可以配置成关心这个集群的其他警报无效。这可以防止与实际问题无关的数百或数千个触发警报的通知,Inhibition 需要通过上面的配置文件进行配置。
- Silences:静默是一个非常简单的方法,可以在给定时间内简单地忽略所有警报。Silences 基于 matchers配置,类似路由树。来到的警告将会被检查,判断它们是否和活跃的 Silences 相等或者正则表达式匹配。如果匹配成功,则不会将这些警报发送给接收者。
由于全局配置中我们配置的repeat_interval: 5m,所以正常来说,上面的测试报警如果一直满足报警条件(CPU使用率大于20%)的话,那么每5分钟我们就可以收到一条报警邮件。
现在我们添加一个 Silences,如下图所示,匹配 k8s-master 节点的内存报警:
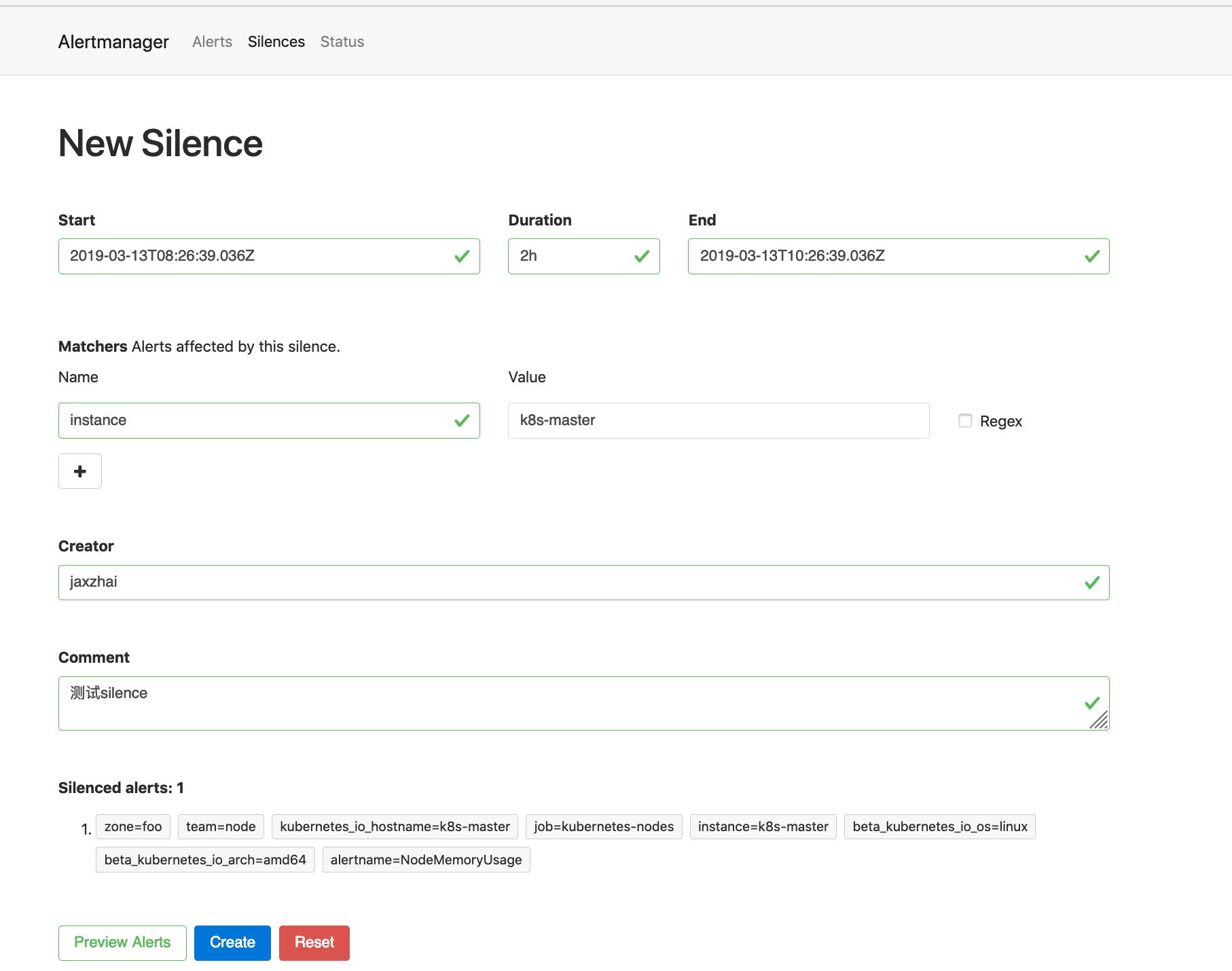
添加完成后,等下一次的报警信息触发后,我们可以看到报警信息里面已经没有了节点 k8s-master 的报警信息了(报警节点变成3个了):
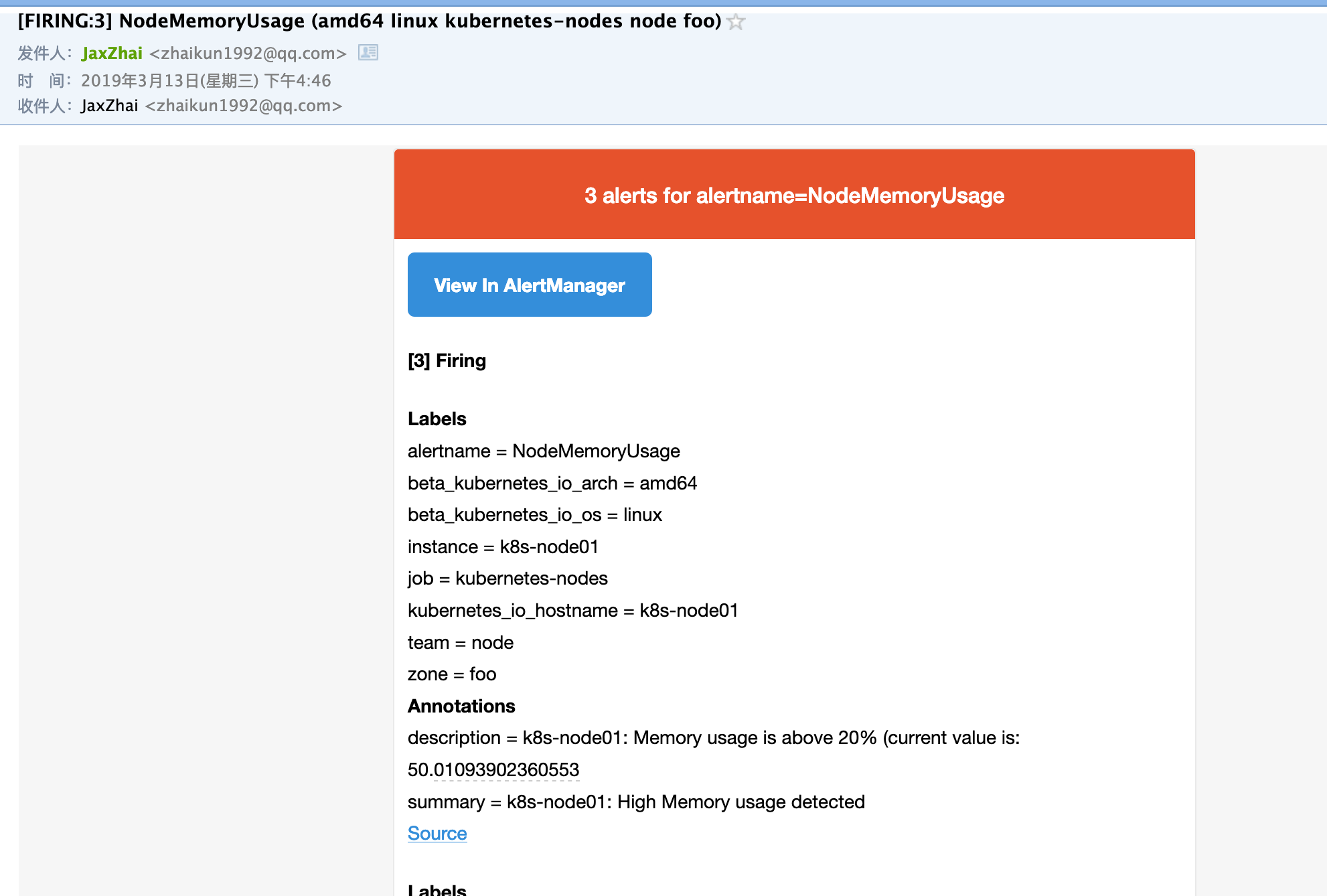
由于我们上面添加的 Silences 是有过期时间的,所以在这个时间段过后,k8s-master 的报警信息就会恢复了。
微信告警
1、登录企业微信,创建第三方应用,点击创建应用按钮 -> 填写应用信息:
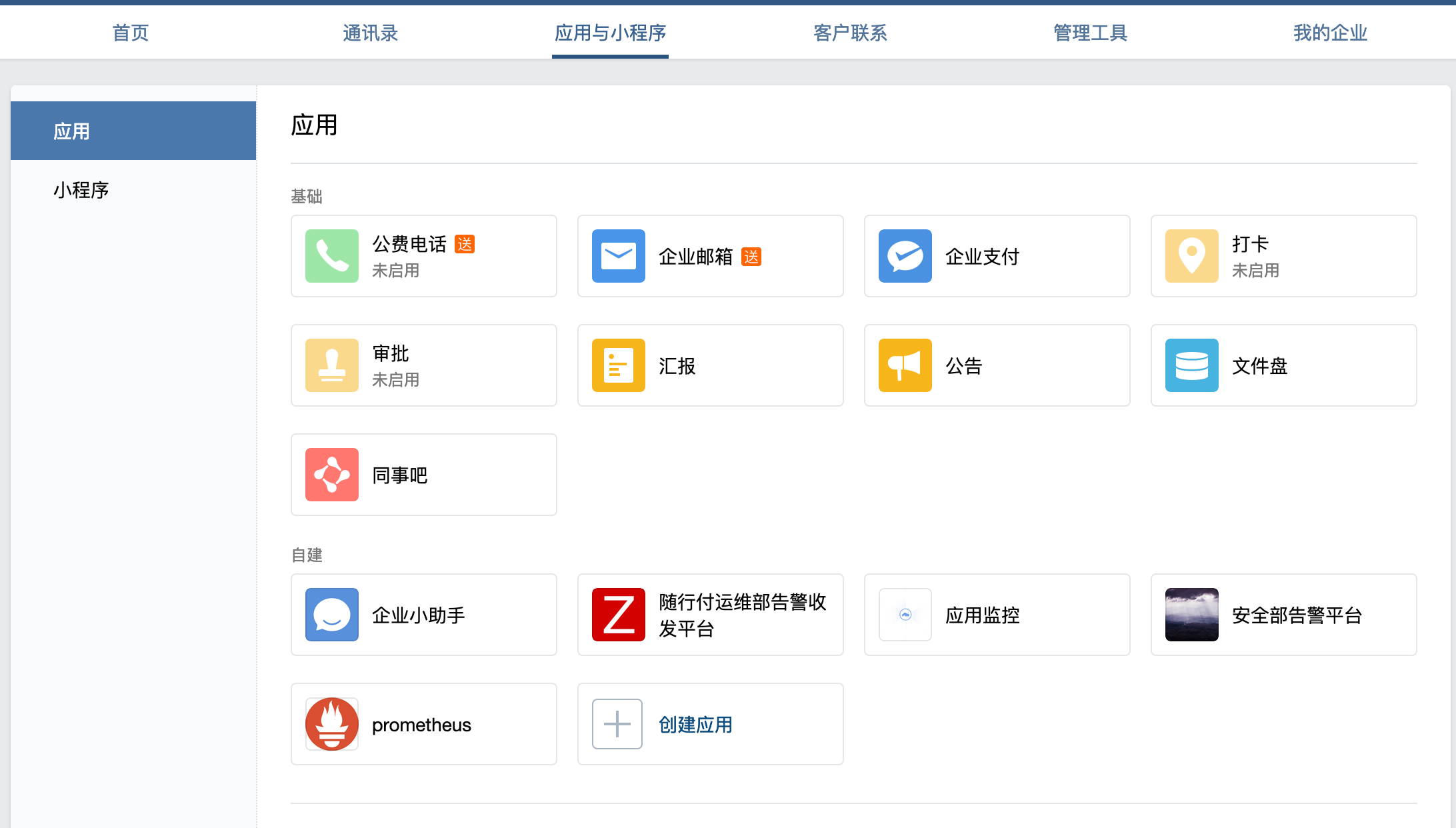
我们打开已经创建好的promethues应用。获取一下信息:

新增告警信息模板
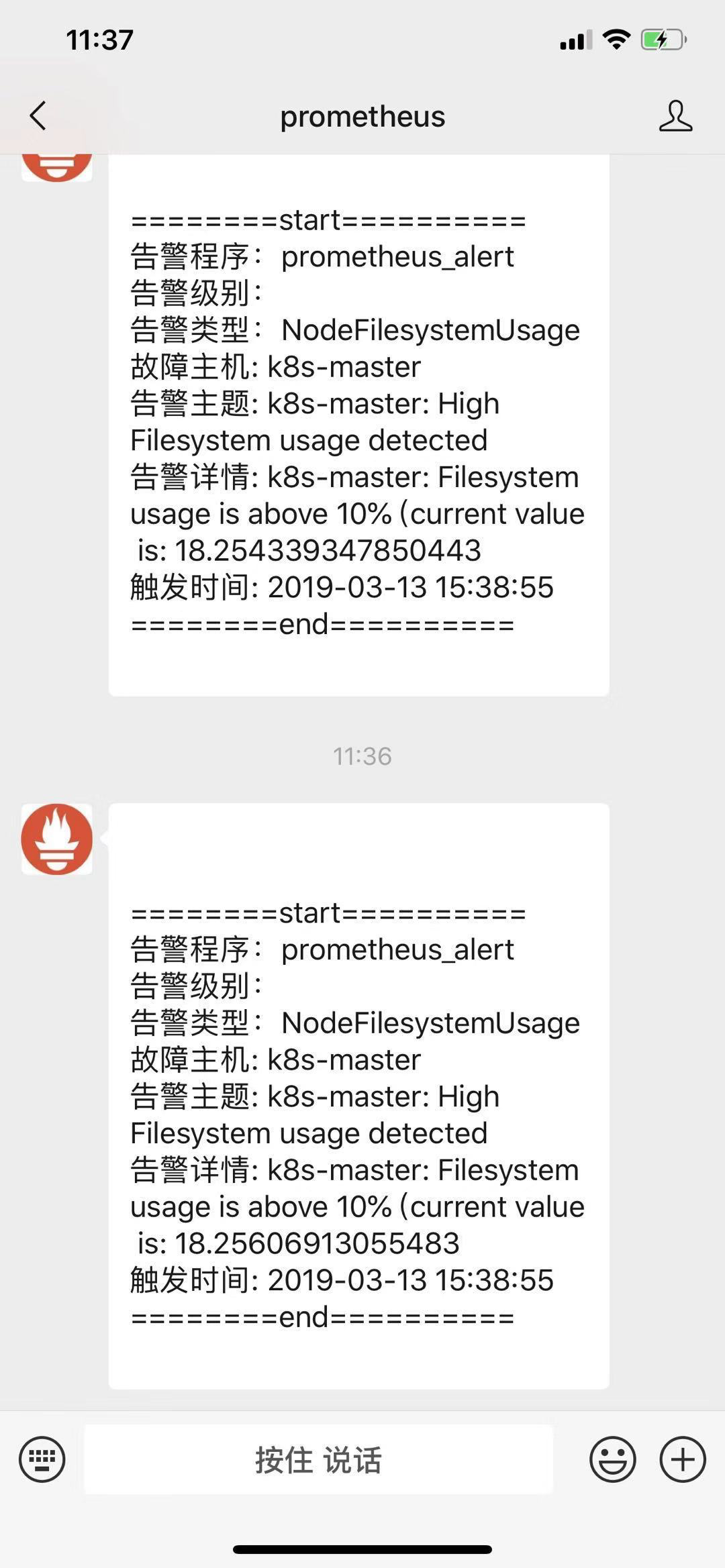
apiVersion: v1 kind: ConfigMap metadata: name: wechat-tmpl namespace: kube-ops data: wechat.tmpl: | {{ define "wechat.default.message" }} {{ range .Alerts }} ========start========== 告警程序: prometheus_alert 告警级别: {{ .Labels.severity }} 告警类型: {{ .Labels.alertname }} 故障主机: {{ .Labels.instance }} 告警主题: {{ .Annotations.summary }} 告警详情: {{ .Annotations.description }} 触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} ========end========== {{ end }} {{ end }}
把模板挂载到alertmanager 的pod中的/etc/alertmanager-tmpl
volumeMounts: ........ - mountPath: "/etc/alertmanager-tmpl" name: wechattmpl ........ volumes: ......... - name: wechattmpl configMap: name: wechat-tmpl
在rules.yml中添加一个新的告警信息。
- alert: NodeFilesystemUsage expr: (node_filesystem_size_bytes{device="rootfs"} - node_filesystem_free_bytes{device="rootfs"}) / node_filesystem_size_bytes{device="rootfs"} * 100 > 10 for: 2m labels: team: wechat annotations: summary: "{{$labels.instance}}: High Filesystem usage detected" description: "{{$labels.instance}}: Filesystem usage is above 10% (current value is: {{ $value }}"
alertmanager中默认支持微信告警通知。我们可以通过官网查看 我们的配置如下:
apiVersion: v1 kind: ConfigMap metadata: name: alert-config namespace: kube-ops data: config.yml: |- global: resolve_timeout: 5m smtp_smarthost: 'smtp.qq.com:587' smtp_from: 'zhaikun1992@qq.com' smtp_auth_username: 'zhaikun1992@qq.com' smtp_auth_password: 'jrmujtmydxtibaid' smtp_hello: 'qq.com' smtp_require_tls: true #指定wechar告警模板 templates: - "/etc/alertmanager-tmpl/wechat.tmpl" route: group_by: ['alertname', 'cluster', 'alertname_wechat'] group_wait: 30s group_interval: 5m repeat_interval: 5m receiver: default routes: - receiver: email group_wait: 10s match: team: node #配置微信的路由分组 - receiver: 'wechat' group_wait: 10s match: team: wechat receivers: - name: 'default' email_configs: - to: 'zhai_kun@suixingpay.com' send_resolved: true - name: 'email' email_configs: - to: 'zhaikun1992@qq.com' send_resolved: true #配置微信接收器 - name: 'wechat' wechat_configs: - corp_id: '***' to_party: '**' to_user: "***" agent_id: '***' api_secret: '****' send_resolved: true
wechat_configs 配置详情
send_resolved 告警解决是否通知,默认是falseapi_secret 创建微信上应用的Secret- api_url wechat的url。默认即可
- corp_id 企业微信---我的企业---最下面的企业ID
- message 告警消息模板:默认
template "wechat.default.message" - agent_id 创建微信上应用的agent_id
- to_user 接受消息的用户 所有用户可以使用 @all
- to_party 接受消息的部门
我们部署验证一下:
kubectl create -f alertmanager-cm.yaml kubectl create -f prome-server.yaml kubectl create -f prome-confmap.yaml kubectl create -f wechat-tmpl.yaml
稍等两分钟,我们的微信企业号会接收到告警信息。