

XML解析的深度解读
一、XML是什么?有什么用?
XML是指可扩展标记语言(eXtensible MarkupLanguage),它是一种标记语言。它被设计的宗旨是描述数据(XML),而非显示数据(HTML)。
目前遵循的是W3C组织于2000年发布的XML1.0规范
应用场景:
1、描述数据
2、作为配置文件存在
二、XML的基本语法
1、文档声明:很重要
在编写XML文档时,需要先使用文档声明来声明XML文档。且必须出现在文档的第一行。
作用:告知解析器,我是一个XML文档。
最简单的声明语法:
<?xml version="1.0"?> 中间不要加空格,后面加?号
当我们写好的一个xml文件写入内存的时候会转换为二进制保存,这个时候会查码表,记事本保存的时候是gbk,而保存的时候默认查码表时用的是utf-8,
这个时候我们就可以用encoding属性:默认是UTF-8 <?xml version="1.0" encoding="GBK"?>,这样就可以解决乱码等问题。
standlone属性:该xml文件是否独立存在。
2、元素(标签)
XML语法非常严格。不能够省略结束标签。
一个XML文档必须有且仅有一个根标签
XML中不会忽略主体内容中出现的空格和换行
元素(标签)的名称可以包含字母、数字、减号、下划线和英文句点,但必须遵守下面的一些规范:
l 严格区分大小写;<P> <p>
l 只能以字母或下划线开头;abc _abc
l 不能以xml(或XML、Xml等)开头----W3C保留日后使用;
l 名称字符之间不能有空格或制表符;ab
l 名称字符之间不能使用冒号; (有特殊用途)
3、元素的属性
属性值一定要用引号(单引号或双引号)引起来
元素中属性不允许重复
4、注释
XML中的注释语法为:<!--这是注释-->
XML声明之前不能有注释 不允许第一行写注释(不同于java)
5、CDATA区
Character Data:字符数据。
语法:
<![CDATA[
内容
]]>
作用:
被CDATA包围的内容,都是普通的文本字符串。
6、特殊字符
特殊字符 替代符号
& &
< <
> >
" "
' &apos
7、处理指令(PI:ProcessingInstruction)(了解)
XML声明就是一种处理指令
处理指令:<?指令名称 属性?>
- <?xml version="1.0" encoding="GBK"?>
- <?xml-stylesheet type="text/css" href="main.css"?>
- <world>
- <chinese>中国</chinese>
- <america>美国</america>
- <japan>小日本</japan>
- </world>
三、XML的约束
XML可以自定义。如果作为配置文件。
格式良好的XML文档:遵循XML语法的。
有效的XML文档:遵守约束的XML文档。
有效的XML文档必定是格式良好的,但良好的不一定是有效的。
1、DTD约束:(能看懂DTD即可)
a、DTD(Document Type Definition):文档类型定义
作用:约束XML的书写规范
注意:dtd可以写在单独的文件中,扩展名是dtd,且必须使用UTF-8编码进行保存。
b、XML文档中如何导入DTD约束文档(XML外部)
l dtd文档在本地:
<!DOCTYPE 根元素 SYSTEM "dtd文件的路径">
l dtd文档在网络上:
<!DOCTYPE 根元素 PUBLIC "dtd名称" "DTD文档的URL链接地址">
c、了解:也可以把DTD的内容直接写在XML文档内部。
写在XML文档内部,dtd没有编码要求。(了解)
- <?xml version="1.0" encoding="GBK"?>
- <!DOCTYPE 书架 [
- <!ELEMENT 书架 (书+)>
- <!ELEMENT 书 (书名,作者,售价)>
- <!ELEMENT 书名 (#PCDATA)>
- <!ELEMENT 作者 (#PCDATA)>
- <!ELEMENT 售价 (#PCDATA)>
- <!ATTLIST 书
- ISBN ID #REQUIRED
- COMMENT CDATA #IMPLIED
- 出版社 CDATA "指令汇公司"
- >
- <!ENTITY copyright "指令汇公司">
- ]>
- <书架>
- <书 ISBN="a" COMMENT="ddd" 出版社="指令汇公司">
- <书名>Java就业培训教程</书名>
- <作者>©right;</作者>
- <售价>39.00元</售价>
- </书>
- <书 ISBN="b">
- <书名>JavaScript网页开发</书名>
- <作者>张孝祥</作者>
- <售价>28.00元</售价>
- </书>
- </书架>
练习:
- <?xml version="1.0" encoding="GBK"?>
- <!DOCTYPE TVSCHEDULE [
- <!ELEMENT TVSCHEDULE (CHANNEL+)>
- <!ELEMENT CHANNEL (BANNER,DAY+)>
- <!ELEMENT BANNER (#PCDATA)>
- <!ELEMENT DAY (DATE,(HOLIDAY|PROGRAMSLOT+)+)>
- <!ELEMENT HOLIDAY (#PCDATA)>
- <!ELEMENT DATE (#PCDATA)>
- <!ELEMENT PROGRAMSLOT (TIME,TITLE,DESCRIPTION?)>
- <!ELEMENT TIME (#PCDATA)>
- <!ELEMENT TITLE (#PCDATA)>
- <!ELEMENT DESCRIPTION (#PCDATA)>
- <!ATTLIST TVSCHEDULE NAME CDATA #REQUIRED>
- <!ATTLIST CHANNEL CHAN CDATA #REQUIRED>
- <!ATTLIST PROGRAMSLOT VTR CDATA #IMPLIED>
- <!ATTLIST TITLE RATING CDATA #IMPLIED>
- <!ATTLIST TITLE LANGUAGE CDATA #IMPLIED>
- ]>
- <TVSCHEDULE NAME="NN">
- <CHANNEL CHAN="CC">
- <BANNER>AAA</BANNER>
- <DAY>
- <DATE>2015</DATE>
- <PROGRAMSLOT>
- <TIME>ee</TIME>
- <TITLE>bb</TITLE>
- <DESCRIPTION>cc</DESCRIPTION>
- </PROGRAMSLOT>
- </DAY>
- </CHANNEL>
- </TVSCHEDULE>
2、Schema约束(新,有替换DTD的趋势)
四、利用Java代码解析XML文档
1、解析方式
l DOM:Document Object Model,文档对象模型。这种方式是W3C推荐的处理XML的一种标准方式。
缺点:必须读取整个XML文档,才能构建DOM模型,如果XML文档过大,造成资源的浪费。
优点:适合对XML中的数据进行操作(CRUD)。
l SAX:Simple API for XML。这种方式不是官方标准,属于开源社区XML-DEV,几乎所有的XML解析器都支持它。
2、解析工具
JAXP:
DOM或SAX方式进行解析XML。API在JDK之中。
Dom4J:(推荐)
是开源组织推出的解析开发包。(牛,大家都在用,包括SUN公司的一些技术的实现都在用)
五、JAXP进行DOM方式解析XML基本练习
1、JAXP简介:
开发包:(JDK中)
DOM:W3C。org.w3c.dom.* DOM规范。(接口/抽象类)
SAX:开源组织。org.xml.sax.* SAX规范。(接口/抽象类)
JAXP:javax.xml.*
2、利用JAXP进行DOM方式解析
- //JAXP进行DOM方式解析的基本操作
- public class JaxpDemo1 {
- public static void main(String[] args) throws Exception {
- //得到解析器
- DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
- DocumentBuilder builder = factory.newDocumentBuilder();
- //通过解析器就可以得到代表整个内存中XML的Document对象
- Document document = builder.parse("src/book.xml");
- test8(document);
- }
- // 1、得到某个具体的节点内容: 刘丰
- private static void test1(Document document){
- NodeList nl = document.getElementsByTagName("作者");
- Node authorNode = nl.item(0);
- System.out.println(authorNode.getTextContent());
- }
- // 2、遍历所有元素节点:打印元素的名称
- private static void test2(Node node){
- //确定node的类型
- //方式一
- // if(node.getNodeType()==Node.ELEMENT_NODE){
- // //是元素
- // }
- //方式二
- if(node instanceof Element){
- //是元素
- Element e = (Element)node;
- System.out.println(e.getNodeName());//打印元素名称
- }
- //判断有没有子节点
- NodeList nl = node.getChildNodes();
- for(int i=0;i<nl.getLength();i++){
- Node n = nl.item(i);
- test2(n);
- }
- }
- // 3、修改某个元素节点的主体内容:<售价>39.00元</售价>--->10元
- private static void test3(Document document) throws Exception{
- //得到售价
- Node priceNode = document.getElementsByTagName("售价").item(0);
- priceNode.setTextContent("10元");
- //更新XML文件
- TransformerFactory tf = TransformerFactory.newInstance();
- Transformer t = tf.newTransformer();
- //构建输入源:
- Source source = new DOMSource(document);
- //构建目标:
- Result result = new StreamResult("src/book.xml");
- t.transform(source, result);
- }
- // 4、向指定元素节点中增加子元素节点:第一本书添加子元素 <出版社>黑马程序员</出版社>
- private static void test4(Document document) throws Exception{
- //创建:<出版社>黑马程序员</出版社>
- Element e = document.createElement("出版社");
- e.setTextContent("黑马程序员");
- //得到书,把新节点挂上去
- Node bookNode = document.getElementsByTagName("书").item(0);
- bookNode.appendChild(e);
- //更新XML文件
- TransformerFactory tf = TransformerFactory.newInstance();
- Transformer t = tf.newTransformer();
- //构建输入源:
- Source source = new DOMSource(document);
- //构建目标:
- Result result = new StreamResult("src/book.xml");
- t.transform(source, result);
- }
- // 5、向指定元素节点上增加同级元素节点:第一本书<售价>前面添加<批发价>30</批发价>
- private static void test5(Document document) throws Exception{
- //创建新节点
- Element e = document.createElement("批发价");
- e.setTextContent("30元");
- //找到<售价>
- Node priceNode = document.getElementsByTagName("售价").item(0);
- //父标签:调用insertBefore(新节点,参考节点);
- Node bookNode = priceNode.getParentNode();
- bookNode.insertBefore(e, priceNode);
- //更新XML文件
- TransformerFactory tf = TransformerFactory.newInstance();
- Transformer t = tf.newTransformer();
- //构建输入源:
- Source source = new DOMSource(document);
- //构建目标:
- Result result = new StreamResult("src/book.xml");
- t.transform(source, result);
- }
- // 6、删除指定元素节点:删除批发价
- private static void test6(Document document) throws Exception{
- Node priceNode = document.getElementsByTagName("批发价").item(0);
- priceNode.getParentNode().removeChild(priceNode);
- //更新XML文件
- TransformerFactory tf = TransformerFactory.newInstance();
- Transformer t = tf.newTransformer();
- //构建输入源:
- Source source = new DOMSource(document);
- //构建目标:
- Result result = new StreamResult("src/book.xml");
- t.transform(source, result);
- }
- // 7、操作XML文件属性:书籍添加一个属性:ISBN=“ABC”
- private static void test7(Document document) throws Exception{
- Node bookNode = document.getElementsByTagName("书").item(0);
- if(bookNode instanceof Element){
- Element e = (Element)bookNode;
- e.setAttribute("ISBN", "ABC");
- }
- //更新XML文件
- TransformerFactory tf = TransformerFactory.newInstance();
- Transformer t = tf.newTransformer();
- //构建输入源:
- Source source = new DOMSource(document);
- //构建目标:
- Result result = new StreamResult("src/book.xml");
- t.transform(source, result);
- }
- // 8、操作XML文件属性:获取ISBN=“ABC”
- private static void test8(Document document) throws Exception{
- Node bookNode = document.getElementsByTagName("书").item(0);
- if(bookNode instanceof Element){
- Element e = (Element)bookNode;
- System.out.println(e.getAttribute("ISBN"));
- }
- }
- }
3、DOM小案例
a、建立xml文件
- <?xml version="1.0" encoding="UTF-8" standalone="no"?><exam>
- <student examid="222" idcard="111">
- <name>刘丰</name>
- <location>湖北</location>
- <grade>100</grade>
- </student>
- <student examid="dsf" idcard="2342"><name>dsf</name><location>435</location><grade>654.0</grade></student></exam>
b、代码要精细。要分层。
DAO:com.zhilinghui.dao
VIEW:com.zhilinghui.view
JavaBean:com.zhilinghui.domain(领域)
c、设计JavaBean
- public class Student {
- private String idcard;
- private String examid;
- private String name;
- private String location;
- private float grade;
- public Student(){}
- public Student(String idcard, String examid, String name, String location,
- float grade) {
- super();
- this.idcard = idcard;
- this.examid = examid;
- this.name = name;
- this.location = location;
- this.grade = grade;
- }
- public String getIdcard() {
- return idcard;
- }
- public void setIdcard(String idcard) {
- this.idcard = idcard;
- }
- public String getExamid() {
- return examid;
- }
- public void setExamid(String examid) {
- this.examid = examid;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public String getLocation() {
- return location;
- }
- public void setLocation(String location) {
- this.location = location;
- }
- public float getGrade() {
- return grade;
- }
- public void setGrade(float grade) {
- this.grade = grade;
- }
- @Override
- public String toString() {
- return "Student [idcard=" + idcard + ", examid=" + examid + ", name="
- + name + ", location=" + location + ", grade=" + grade + "]";
- }
- }
d、开发DAO
数据访问对象
- public class StudentDao {
- /**
- * 保存学生信息到XML文件中
- * @param student 封装要保存的信息
- * @return 成功返回true,否则false
- * @throws Exception
- */
- public boolean save(Student student) throws Exception{
- if(student==null)
- throw new IllegalArgumentException("学生参数不能为null");
- boolean result = false;
- /*
- * <student idcard="111" examid="222">
- <name>刘丰</name>
- <location>湖北</location>
- <grade>100</grade>
- </student>
- */
- //得到Document
- Document document = JaxpUtil.getDocument();
- //创建一个student元素:设置属性
- Element studentE = document.createElement("student");//<student></student>
- studentE.setAttribute("idcard", student.getIdcard());
- studentE.setAttribute("examid", student.getExamid());//<student idcard="111" examid="222"></student>
- //创建name,location,grade元素,挂到student上
- Element nameE = document.createElement("name");
- nameE.setTextContent(student.getName());//<name>刘丰</name>
- Element locationE = document.createElement("location");
- locationE.setTextContent(student.getLocation());//<location>湖北</location>
- Element gradeE = document.createElement("grade");
- gradeE.setTextContent(student.getGrade()+"");//<grade>100</grade>
- studentE.appendChild(nameE);
- studentE.appendChild(locationE);
- studentE.appendChild(gradeE);
- //把student挂接到exam上
- Node examNode = document.getElementsByTagName("exam").item(0);
- examNode.appendChild(studentE);
- //写到xml中
- JaxpUtil.wirte2xml(document);
- //更改result的取值为true
- result = true;
- return result;
- }
- /**
- * 根据姓名删除信息
- * @param name
- * @return 成功返回true,否则false
- */
- public boolean delete(String name){
- boolean result = false;
- try {
- Document document = JaxpUtil.getDocument();
- //得到所有的name元素
- NodeList nl = document.getElementsByTagName("name");
- //遍历:比对文本内容是否和参数一样
- for(int i=0;i<nl.getLength();i++){
- if(nl.item(i).getTextContent().equals(name)){
- //如果找到了一样的:爷爷干掉爸爸
- nl.item(i).getParentNode().getParentNode().removeChild(nl.item(i).getParentNode());
- //写回xml
- JaxpUtil.wirte2xml(document);
- break;
- }
- }
- result = true;
- } catch (Exception e) {
- throw new RuntimeException(e);//异常转译
- }
- return result;
- }
- /**
- * 根据准考证号查询学生信息
- * @param examid
- * @return 没有返回null
- */
- public Student findByExamId(String examid){
- Student student = null;
- try {
- Document document = JaxpUtil.getDocument();
- //得到所有的student元素
- NodeList nl = document.getElementsByTagName("student");
- //遍历:比对examid属性
- for(int i=0;i<nl.getLength();i++){
- Element e = (Element) nl.item(i);
- if(e.getAttribute("examid").equals(examid)){
- // 找到了:创建student对象,并设置相应的值
- student = new Student();
- student.setIdcard(e.getAttribute("idcard"));
- student.setExamid(examid);
- student.setName(e.getElementsByTagName("name").item(0).getTextContent());
- student.setLocation(e.getElementsByTagName("location").item(0).getTextContent());
- student.setGrade(Float.parseFloat(e.getElementsByTagName("grade").item(0).getTextContent()));
- break;
- }
- }
- } catch (Exception e) {
- throw new RuntimeException(e);//异常转译
- }
- return student;
- }
- }
e、测试DAO的功能
- public class StudentDaoTest {
- public static void main(String[] args) {
- StudentDao dao = new StudentDao();
- // Student student = new Student();
- // student.setIdcard("333");
- //
- // dao.save(student);
- // Student s = dao.findByExamId("444");
- // System.out.println(s);
- System.out.println(dao.delete("阿娇"));
- }
- }
f、开发界面
- ublic class Main {
- public static void main(String[] args) throws Exception {
- StudentDao dao = new StudentDao();
- System.out.println("a、添加用户\tb、查询成绩\tc、删除用户");
- System.out.println("请输入操作类型:");
- BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
- String op = br.readLine();//读取用户输入的a|b|c
- if("a".equals(op)){
- //添加
- System.out.println("请输入学生姓名:");
- String name = br.readLine();
- System.out.println("请输入学生准考证号:");
- String examid = br.readLine();
- System.out.println("请输入学生身份证号:");
- String idcard = br.readLine();
- System.out.println("请输入学生所在地:");
- String location = br.readLine();
- System.out.println("请输入学生成绩:");
- String grade = br.readLine();
- //封装数据
- Student student = new Student(idcard, examid, name, location, Float.parseFloat(grade));
- //调用dao
- boolean b = dao.save(student);
- if(b){
- System.out.println("------添加成功------");
- }else{
- System.out.println("------服务器忙------");
- }
- }else if("b".equals(op)){
- //查询
- System.out.println("请输入学生准考证号:");
- String examid = br.readLine();
- Student s = dao.findByExamId(examid);
- if(s==null)
- System.out.println("------查无此人------");
- else
- System.out.println(s);
- }else if("c".equals(op)){
- //删除
- System.out.println("请输入要删除的学生姓名:");
- String name = br.readLine();
- boolean b = dao.delete(name);
- if(b){
- System.out.println("------删除成功------");
- }else{
- System.out.println("------服务器忙------");
- }
- }else{
- System.out.println("你傻呀,输错了");
- }
- }
- }
sax解析原理
在使用 DOM 解析 XML 文档时,需要读取整个 XML 文档,在内存中构架代表整个 DOM 树的Doucment对象,从而再对XML文档进行操作。此种情况下,如果 XML 文档特别大,就会消耗计算机的大量内存,并且容易导致内存溢出。
SAX解析允许在读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才会文档进行操作。
SAX采用事件处理的方式解析XML文件,利用 SAX 解析 XML 文档,涉及两个部分:解析器和事件处理器: 解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以指定解析器去解析某个XML文档。 解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的xml文件内容作为方法的参数传递给事件处理器。 事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到sax解析器解析到的数据,从而可以决定如何对数据进行处理
基本解析操作
//1解析器
SAXParser parse = SAXParserFactory.newInstance().newSAXParser();
//2获取xml读取器
XMLReader reader = parse.getXMLReader();
//3注册内容处理器
reader.setContentHandler(new ContentHandler1());
//4读取xml文档
reader.parse("src/book.xml");
封装读取书
封装到BOOK.java
public class sax3 {
//封装读取书
public static void main(String[] args) throws Exception {
SAXParser parse=SAXParserFactory.newInstance().newSAXParser();
XMLReader reader=parse.getXMLReader();
final List<Book> books=new ArrayList<Book>();
reader.setContentHandler(new DefaultHandler(){
private Book b=null;
private String currentTagName=null;
public void startElement(String uri, String localName,
String qName, Attributes attributes) throws SAXException {
if("书".equals(qName)){
b=new Book();
}
currentTagName=qName;
}
public void endElement(String uri, String localName, String qName)
throws SAXException {
if("书".equals(qName)){
books.add(b);
b=null;
}
currentTagName=null;
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
if("书名".equals(currentTagName)){
b.setName(new String(ch,start,length));
}
if("作者".equals(currentTagName)){
b.setAuthor(new String(ch,start,length));
}
if("售价".equals(currentTagName)){
b.setPrice(new String(ch,start,length));
}
}
});
reader.parse("src/book.xml");
for(Book book:books)
System.out.println(book);
}
}
dom4j解析原理
Dom4j是一个简单、灵活的开放源代码的库。Dom4j是由早期开发JDOM的人分离出来而后独立开发的。与JDOM不同的是,dom4j使用接口和抽象基类,虽然Dom4j的API相对要复杂一些,但它提供了比JDOM更好的灵活性。 Dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件采用的Dom4j,例如Hibernate,包括sun公司自己的JAXM也用了Dom4j。 使用Dom4j开发,需下载dom4j相应的jar文件。
1、基本练习 a、拷贝jar包: 把dom4j-1.6.1.jar加入到你的classpath中 b、基本操作
// 1、得到某个具体的节点内容:jinpingmei
@Test
public void test1() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read("src/book.xml");
//首先要得到根元素
Element root = document.getRootElement();
List<Element> bookElements = root.elements();
// Element bookName = (Element) bookElements.get(0).elements().get(0);
// System.out.println(bookName.getText());
System.out.println(bookElements.get(0).elementText("书名"));
}
// 2、遍历所有元素节点:名称
@Test
public void test2()throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read("src/book.xml");
//首先要得到根元素
Element root = document.getRootElement();
treeWalk(root);
}
public void treeWalk(Element rootElement){//递归
System.out.println(rootElement.getName());
int nodeCount = rootElement.nodeCount();//子节点的数量
for(int i=0;i<nodeCount;i++){
Node node = rootElement.node(i);//得到一个子节点
if(node instanceof Element){
treeWalk((Element)node);
}
}
}
// 3、修改某个元素节点的主体内容:<售价>10元---20
@Test
public void test3()throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read("src/book.xml");
//首先要得到根元素
Element root = document.getRootElement();
//得售价
Element priceElement = root.element("书").element("售价");
priceElement.setText("21元");
//写回XML文档
// OutputFormat format = OutputFormat.createCompactFormat();//去除空格回车换行,适合运行期间
OutputFormat format = OutputFormat.createPrettyPrint();//漂亮的格式 默认编码是UTF-8
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"), format);
writer.write(document);
writer.close();
}
// 4、向指定元素节点中增加子元素节点:<出版社>黑马程序员
@Test
public void test4()throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read("src/book.xml");
//首先要得到根元素
Element root = document.getRootElement();
//得售价
Element bookElement = root.element("书");
//创建新元素
Element publisherElement = DocumentHelper.createElement("出版社");
publisherElement.setText("黑马程序员");
bookElement.add(publisherElement);
//写回XML文档
// OutputFormat format = OutputFormat.createCompactFormat();//去除空格回车换行,适合运行期间
OutputFormat format = OutputFormat.createPrettyPrint();//漂亮的格式 默认编码是UTF-8
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"), format);
writer.write(document);
writer.close();
}
// 5、向指定元素节点上增加同级元素节点:<售价>21元 添加<批发价>
@Test
public void test5()throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read("src/book.xml");
//首先要得到根元素
Element root = document.getRootElement();
//得售价
Element bookElement = root.element("书");
//创建新元素
Element priceElement = DocumentHelper.createElement("批发价");
priceElement.setText("30元");
List<Element> bookChildren = bookElement.elements();//得到书的子元素
bookChildren.add(2, priceElement);
//写回XML文档
// OutputFormat format = OutputFormat.createCompactFormat();//去除空格回车换行,适合运行期间
OutputFormat format = OutputFormat.createPrettyPrint();//漂亮的格式 默认编码是UTF-8
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"), format);
writer.write(document);
writer.close();
}
// 6、删除指定元素节点:批发价
@Test
public void test6()throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read("src/book.xml");
//首先要得到根元素
Element root = document.getRootElement();
Element priceElement = root.element("书").element("批发价");
priceElement.getParent().remove(priceElement);
//写回XML文档
// OutputFormat format = OutputFormat.createCompactFormat();//去除空格回车换行,适合运行期间
OutputFormat format = OutputFormat.createPrettyPrint();//漂亮的格式 默认编码是UTF-8
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"), format);
writer.write(document);
writer.close();
}
// 7、操作XML文件属性
@Test
public void test7()throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read("src/book.xml");
//首先要得到根元素
Element root = document.getRootElement();
Element book = root.element("书");
System.out.println(book.attributeValue("ISBN"));
}
@Test
public void test8()throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read("src/book.xml");
//首先要得到根元素
Element root = document.getRootElement();
Element book = root.element("书");
book.addAttribute("A", "B");
//写回XML文档
// OutputFormat format = OutputFormat.createCompactFormat();//去除空格回车换行,适合运行期间
OutputFormat format = OutputFormat.createPrettyPrint();//漂亮的格式 默认编码是UTF-8
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"), format);
writer.write(document);
writer.close();
}
Xpath
XPath是一个努力为XSL转换XSLT和XPointer [ ] [ ]之间共享一个共同的XPointer功能语法和语义的结果。它的主要目的是解决一个XML XML文档部分[ ]。为了支持这一功能,还提供用于处理字符串的基本设施、数字和布尔值。XPath使用一个紧凑的、非XML语法方便使用在uri和XML属性值的XPath。XPath操作基于XML文档的逻辑结构,而不是其表面的语法。Xpath的名字来自其使用的符号在URL路径通过一个XML文档的层次结构导航。 除了用于定位,XPath还设计有一个真子集,可用于匹配(测试一个节点是否符合一个模式);使用XPath进行XSLT。
XPath模型的XML文档的节点树。有不同类型的节点,包括元素节点、属性节点和文本节点。XPath定义了一个方法来计算每个节点类型字符串值。某些类型的节点也有名字。XPath完全支持XML命名空间的XML名称] [。因此,一个节点的名称被建模为一个地方的部分和一个可能的空命名空间URI;这就是所谓的扩展名。在[ 5数据模型]中详细描述了数据模型。
@Test//Xpath
public void test11() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read("src/book.xml");
Node n = document.selectSingleNode("//书[1]/书名");
System.out.println(n.getText());
}
@Test//Xpath:第一本书的ISBN的值
public void test12() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read("src/book.xml");
Node n = document.selectSingleNode("//书[1]");
System.out.println(n.valueOf("@ISBN"));
}
xml约束之schema
XML Schema 也是一种用于定义和描述 XML 文档结构与内容的模式语言,其出现是为了克服 DTD 的局限性
XML Schema 文件自身就是一个XML文件,但它的扩展名通常为.xsd。支持名称空间。 一个XML Schema文档通常称之为模式文档(约束文档),遵循这个文档书写的xml文件称之为实例文档。
和XML文件一样,一个XML Schema文档也必须有一个根结点,但这个根结点的名称为schema。
编写了一个XML Schema约束文档后,通常需要把这个文件中声明的元素绑定到一个URI地址上,在XML Schema技术中有一个专业术语来描述这个过程,即把XML Schema文档声明的元素绑定到一个名称空间上,以后XML文件就可以通过这个URI(即名称空间)来告诉解析引擎,xml文档中编写的元素来自哪里,被谁约束。
学习目标:不需要我们编写xsd 重点:根据xsd编写出xml文档。 难点:在xml中引入xsd约束
基本操作步骤:
a、根据xsd文件,找到根元素
<?xml version="1.0" encoding="UTF-8"?>
<书架>
</书架>
b、根元素来在哪个名称空间 使用xmlns关键字来声明名称空间。
<?xml version="1.0" encoding="UTF-8"?>
<tf:书架 xmlns:tf="http://www.zhilinghui.com">
</tf:书架>
c、名称空间和哪个xsd文件对应
<?xml version="1.0" encoding="UTF-8"?>
<tf:书架 xmlns:tf="http://www.zhilinghui.com"
schemaLocation="http://www.zhilinghui.com book.xsd">
</tf:书架>
d、schemaLocation来自一个标准的名称空间:固定写法
<?xml version="1.0" encoding="UTF-8"?>
<tf:书架 xmlns:tf="http://www.zhilinghui.com"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.zhilinghui.com book.xsd">
</tf:书架>
==============================================================================================================================
DOM4J的另一种深度解读:
DOM4J
与利用DOM、SAX、JAXP机制来解析xml相比,DOM4J 表现更优秀,具有性能优异、功能强大和极端易用使用的特点,只要懂得DOM基本概念,就可以通过dom4j的api文档来解析xml。dom4j是一套开源的api。实际项目中,往往选择dom4j来作为解析xml的利器。
先来看看dom4j中对应XML的DOM树建立的继承关系
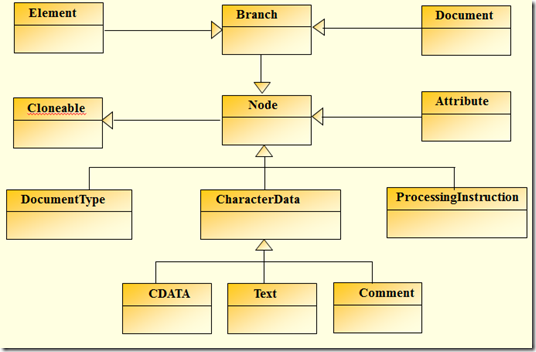
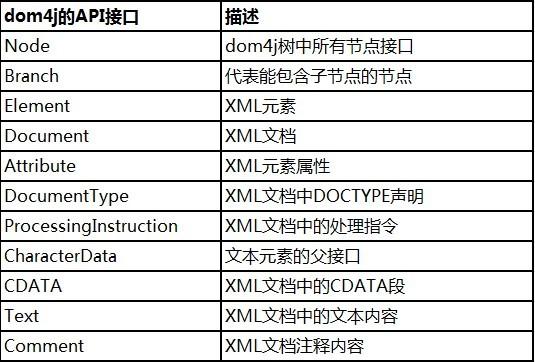
针对于XML标准定义,对应于图2-1列出的内容,dom4j提供了以下实现:
同时,dom4j的NodeType枚举实现了XML规范中定义的node类型。如此可以在遍历xml文档的时候通过常量来判断节点类型了。
常用API
class org.dom4j.io.SAXReader
- read 提供多种读取xml文件的方式,返回一个Domcument对象
interface org.dom4j.Document
- iterator 使用此法获取node
- getRootElement 获取根节点
interface org.dom4j.Node
- getName 获取node名字,例如获取根节点名称为bookstore
- getNodeType 获取node类型常量值,例如获取到bookstore类型为1——Element
- getNodeTypeName 获取node类型名称,例如获取到的bookstore类型名称为Element
interface org.dom4j.Element
- attributes 返回该元素的属性列表
- attributeValue 根据传入的属性名获取属性值
- elementIterator 返回包含子元素的迭代器
- elements 返回包含子元素的列表
interface org.dom4j.Attribute
- getName 获取属性名
- getValue 获取属性值
interface org.dom4j.Text
- getText 获取Text节点值
interface org.dom4j.CDATA
- getText 获取CDATA Section值
interface org.dom4j.Comment
- getText 获取注释
实例一:

1 //先加入dom4j.jar包
2 import java.util.HashMap;
3 import java.util.Iterator;
4 import java.util.Map;
5
6 import org.dom4j.Document;
7 import org.dom4j.DocumentException;
8 import org.dom4j.DocumentHelper;
9 import org.dom4j.Element;
10
11 /**
12 * @Title: TestDom4j.java
13 * @Package
14 * @Description: 解析xml字符串
15 * @author 无处不在
16 * @date 2012-11-20 下午05:14:05
17 * @version V1.0
18 */
19 public class TestDom4j {
20
21 public void readStringXml(String xml) {
22 Document doc = null;
23 try {
24
25 // 读取并解析XML文档
26 // SAXReader就是一个管道,用一个流的方式,把xml文件读出来
27 //
28 // SAXReader reader = new SAXReader(); //User.hbm.xml表示你要解析的xml文档
29 // Document document = reader.read(new File("User.hbm.xml"));
30 // 下面的是通过解析xml字符串的
31 doc = DocumentHelper.parseText(xml); // 将字符串转为XML
32
33 Element rootElt = doc.getRootElement(); // 获取根节点
34 System.out.println("根节点:" + rootElt.getName()); // 拿到根节点的名称
35
36 Iterator iter = rootElt.elementIterator("head"); // 获取根节点下的子节点head
37
38 // 遍历head节点
39 while (iter.hasNext()) {
40
41 Element recordEle = (Element) iter.next();
42 String title = recordEle.elementTextTrim("title"); // 拿到head节点下的子节点title值
43 System.out.println("title:" + title);
44
45 Iterator iters = recordEle.elementIterator("script"); // 获取子节点head下的子节点script
46
47 // 遍历Header节点下的Response节点
48 while (iters.hasNext()) {
49
50 Element itemEle = (Element) iters.next();
51
52 String username = itemEle.elementTextTrim("username"); // 拿到head下的子节点script下的字节点username的值
53 String password = itemEle.elementTextTrim("password");
54
55 System.out.println("username:" + username);
56 System.out.println("password:" + password);
57 }
58 }
59 Iterator iterss = rootElt.elementIterator("body"); ///获取根节点下的子节点body
60 // 遍历body节点
61 while (iterss.hasNext()) {
62
63 Element recordEless = (Element) iterss.next();
64 String result = recordEless.elementTextTrim("result"); // 拿到body节点下的子节点result值
65 System.out.println("result:" + result);
66
67 Iterator itersElIterator = recordEless.elementIterator("form"); // 获取子节点body下的子节点form
68 // 遍历Header节点下的Response节点
69 while (itersElIterator.hasNext()) {
70
71 Element itemEle = (Element) itersElIterator.next();
72
73 String banlce = itemEle.elementTextTrim("banlce"); // 拿到body下的子节点form下的字节点banlce的值
74 String subID = itemEle.elementTextTrim("subID");
75
76 System.out.println("banlce:" + banlce);
77 System.out.println("subID:" + subID);
78 }
79 }
80 } catch (DocumentException e) {
81 e.printStackTrace();
82
83 } catch (Exception e) {
84 e.printStackTrace();
85
86 }
87 }
88
89 /**
90 * @description 将xml字符串转换成map
91 * @param xml
92 * @return Map
93 */
94 public static Map readStringXmlOut(String xml) {
95 Map map = new HashMap();
96 Document doc = null;
97 try {
98 // 将字符串转为XML
99 doc = DocumentHelper.parseText(xml);
100 // 获取根节点
101 Element rootElt = doc.getRootElement();
102 // 拿到根节点的名称
103 System.out.println("根节点:" + rootElt.getName());
104
105 // 获取根节点下的子节点head
106 Iterator iter = rootElt.elementIterator("head");
107 // 遍历head节点
108 while (iter.hasNext()) {
109
110 Element recordEle = (Element) iter.next();
111 // 拿到head节点下的子节点title值
112 String title = recordEle.elementTextTrim("title");
113 System.out.println("title:" + title);
114 map.put("title", title);
115 // 获取子节点head下的子节点script
116 Iterator iters = recordEle.elementIterator("script");
117 // 遍历Header节点下的Response节点
118 while (iters.hasNext()) {
119 Element itemEle = (Element) iters.next();
120 // 拿到head下的子节点script下的字节点username的值
121 String username = itemEle.elementTextTrim("username");
122 String password = itemEle.elementTextTrim("password");
123
124 System.out.println("username:" + username);
125 System.out.println("password:" + password);
126 map.put("username", username);
127 map.put("password", password);
128 }
129 }
130
131 //获取根节点下的子节点body
132 Iterator iterss = rootElt.elementIterator("body");
133 // 遍历body节点
134 while (iterss.hasNext()) {
135 Element recordEless = (Element) iterss.next();
136 // 拿到body节点下的子节点result值
137 String result = recordEless.elementTextTrim("result");
138 System.out.println("result:" + result);
139 // 获取子节点body下的子节点form
140 Iterator itersElIterator = recordEless.elementIterator("form");
141 // 遍历Header节点下的Response节点
142 while (itersElIterator.hasNext()) {
143 Element itemEle = (Element) itersElIterator.next();
144 // 拿到body下的子节点form下的字节点banlce的值
145 String banlce = itemEle.elementTextTrim("banlce");
146 String subID = itemEle.elementTextTrim("subID");
147
148 System.out.println("banlce:" + banlce);
149 System.out.println("subID:" + subID);
150 map.put("result", result);
151 map.put("banlce", banlce);
152 map.put("subID", subID);
153 }
154 }
155 } catch (DocumentException e) {
156 e.printStackTrace();
157 } catch (Exception e) {
158 e.printStackTrace();
159 }
160 return map;
161 }
162
163 public static void main(String[] args) {
164
165 // 下面是需要解析的xml字符串例子
166 String xmlString = "<html>" + "<head>" + "<title>dom4j解析一个例子</title>"
167 + "<script>" + "<username>yangrong</username>"
168 + "<password>123456</password>" + "</script>" + "</head>"
169 + "<body>" + "<result>0</result>" + "<form>"
170 + "<banlce>1000</banlce>" + "<subID>36242519880716</subID>"
171 + "</form>" + "</body>" + "</html>";
172
173 /*
174 * Test2 test = new Test2(); test.readStringXml(xmlString);
175 */
176 Map map = readStringXmlOut(xmlString);
177 Iterator iters = map.keySet().iterator();
178 while (iters.hasNext()) {
179 String key = iters.next().toString(); // 拿到键
180 String val = map.get(key).toString(); // 拿到值
181 System.out.println(key + "=" + val);
182 }
183 }
184
185 }
实例二:
1 /**
2 * 解析包含有DB连接信息的XML文件
3 * 格式必须符合如下规范:
4 * 1. 最多三级,每级的node名称自定义;
5 * 2. 二级节点支持节点属性,属性将被视作子节点;
6 * 3. CDATA必须包含在节点中,不能单独出现。
7 *
8 * 示例1——三级显示:
9 * <db-connections>
10 * <connection>
11 * <name>DBTest</name>
12 * <jndi></jndi>
13 * <url>
14 * <![CDATA[jdbc:mysql://localhost:3306/db_test?useUnicode=true&characterEncoding=UTF8]]>
15 * </url>
16 * <driver>org.gjt.mm.mysql.Driver</driver>
17 * <user>test</user>
18 * <password>test2012</password>
19 * <max-active>10</max-active>
20 * <max-idle>10</max-idle>
21 * <min-idle>2</min-idle>
22 * <max-wait>10</max-wait>
23 * <validation-query>SELECT 1+1</validation-query>
24 * </connection>
25 * </db-connections>
26 *
27 * 示例2——节点属性:
28 * <bookstore>
29 * <book category="cooking">
30 * <title lang="en">Everyday Italian</title>
31 * <author>Giada De Laurentiis</author>
32 * <year>2005</year>
33 * <price>30.00</price>
34 * </book>
35 *
36 * <book category="children" title="Harry Potter" author="J K. Rowling" year="2005" price="$29.9"/>
37 * </bookstore>
38 *
39 * @param configFile
40 * @return
41 * @throws Exception
42 */
43 public static List<Map<String, String>> parseDBXML(String configFile) throws Exception {
44 List<Map<String, String>> dbConnections = new ArrayList<Map<String, String>>();
45 InputStream is = Parser.class.getResourceAsStream(configFile);
46 SAXReader saxReader = new SAXReader();
47 Document document = saxReader.read(is);
48 Element connections = document.getRootElement();
49
50 Iterator<Element> rootIter = connections.elementIterator();
51 while (rootIter.hasNext()) {
52 Element connection = rootIter.next();
53 Iterator<Element> childIter = connection.elementIterator();
54 Map<String, String> connectionInfo = new HashMap<String, String>();
55 List<Attribute> attributes = connection.attributes();
56 for (int i = 0; i < attributes.size(); ++i) { // 添加节点属性
57 connectionInfo.put(attributes.get(i).getName(), attributes.get(i).getValue());
58 }
59 while (childIter.hasNext()) { // 添加子节点
60 Element attr = childIter.next();
61 connectionInfo.put(attr.getName().trim(), attr.getText().trim());
62 }
63 dbConnections.add(connectionInfo);
64 }
65
66 return dbConnections;
67 }
