List和Map集合详细分析
1.Java集合主要三种类型(两部分):
第一部分:Collection(存单个数据,只能存取引用类型)
(1).List :是一个有序集合,可以放重复的数据;(存顺序和取顺序相同)
(2).Set :是一个无序集合,不允许放置重复的数据;(存顺序和取顺序不一定相同)
(3).SortedSet:无序不可重复,存进去的元素可以按照元素的大小自动排序。
第二部分:Map(存成对数据)
(1).Map: 是一个无序集合,集合中包含一个键对象,一个值对象,键对象不允许重复,值对象可以重复(身份证号-姓名)。
2.Java集合存取数据类型及结构
2.1 常见集合的继承结构-Collection

2.1.1、集合中常用实现类的数据结构分析:
(1)List集合
List集合继承了Collection接口,因此包含了collection中所有的方法,此外,List接口还定义了以下两个非常重要的方法:
(a)get(int index):获得指定索引位置的元素
(b)set(int index,Object obj):将集合中指定索引位置的对象修改为指定对象。
(2)ArrayList
采用数组存储元素,适合查询,不适合随机增删元素。(常用)。是可变数组,允许保存所有的元素,包括null,并可以根据索引位置对集合进行快速的随机访问:缺点是指定的索引位置插入对象或删除对象的速度较慢。
(3)LinkedList
底层采用双向链表数据结构存储数据,适合频繁的增删元素,不适合查询元素。
(4)Vector
底层和ArrayList集合相同,但是 Vector是线程安全的,效率较低。(不常用)
(5)Set集合
Set集合中的元素不按特定的方式排序,只是简单地把对象加入集合,Set集合中不能包含重复对象。set集合有Set接口的实现类组成,set接口继承了Collection接口,因包含了Collction接口的所有方法。 Set的构造方法有一个约束条件,传入的Collection对象不能把有重复值,必须小心操作可变对象(Mutable Object)。如果一个Set中可变元素改变了自身状态导致Object。equals(Object) = true,则会出现一些问题。
(6)HashSet
哈希表/散列表,底层是一个HashMap。HashSet有以下特点:
a. 不能保证元素的排列顺序,顺序有可能发生变化
b.不是同步的
c. 集合元素可以是null,但只能放入一个null
当向HashSet结合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。
简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相 等。
注意,如果要把一个对象放入HashSet中,重写该对象对应类的equals方法,也应该重写其hashCode()方法。
其规则是如果两个对 象通过equals方法比较返回true时,其hashCode也应该相同。另外,对象中用作equals比较标准的属性,都应该用来计算 hashCode的值。
(5)TreeSet:
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式, 自然排序 和定制排序,其中自然排序为默认的排序方式。向TreeSet中加入的应该是同一个类的对象。
自然排序使用要排序元素的CompareTo(Object obj)方法来比较元素之间大小关系,然后将元素按照升序排列。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现了该接口的对象就可以比较大小。
obj1.compareTo(obj2)方法如果返回0,则说明被比较的两个对象相等,如果返回一个正数,则表明obj1大于obj2,如果是 负数,则表明obj1小于obj2。
如果我们将两个对象的equals方法总是返回true,则这两个对象的compareTo方法返回应该返回0
b.定制排序
定制排序是根据集合元素的大小,以升序排列,如果要定制排序,应该使用Comparator接口,实现 int compare(T o1,T o2)方法
2.1.2、Collection接口中的方法分析:
(1).list集合


1 package list; 2 import java.util.*; 3 import java.util.ArrayList; 4 public class Gather { // 创建类Gather 5 public static void main(String[] args) { // 主方法 6 List<String> list = new ArrayList<>();//创建集合对象 7 list.add("a"); 8 list.add("b"); 9 list.add("c"); 10 //获得0~2之间随机数 11 int i = (int)(Math.random()*(list.size() - 1)); 12 System.out.println("随机数组中的元素: "+list.get(i)); 13 list.remove(2);//将指定索引位置的元素从集合中移除 14 System.out.println("将索引是2的元素从数组中移除后数组中的元素是:"); 15 for(int j = 0;j < list.size();j++){//循环遍历结合 16 System.out.println(list.get(j)); 17 } 18 } 19 20 } 21 /* 22 运行结果: 23 24 随机数组中的元素: a 25 将索引是2的元素从数组中移除后数组中的元素是: 26 a 27 b 28 */
(2)set集合
1 import java.util.*; 2 /** 3 * 在项目中创建类UpdateStu,实现Comparable接口,重写该接口中的compareTo()方法。在主方法中 4 * 创建UpdateStu对象,创建集合,并将UpdataStu对象添加到集合中,遍历该集合中的全部元素,以及通过 5 * headSet(),subSet()方法获得的全部的部分集合。 6 * @author z 7 * 8 */ 9 public class UpdateStu implements Comparable<Object> { 10 String name; 11 long id; 12 public UpdateStu(String name, long id) { 13 this.id = id; 14 this.name = name; 15 } 16 public int compareTo(Object o) { 17 UpdateStu upstu = (UpdateStu) o; 18 int result = id > upstu.id ? 1 : (id == upstu.id ? 0 : -1); 19 return result; 20 } 21 public long getId() { 22 return id; 23 } 24 public void setId(long id) { 25 this.id = id; 26 } 27 public String getName() { 28 return name; 29 } 30 public void setName(String name) { 31 this.name = name; 32 } 33 public static void main(String[] args) { 34 UpdateStu stu1 = new UpdateStu("李同学", 01011); 35 UpdateStu stu2 = new UpdateStu("陈同学", 01021); 36 UpdateStu stu3 = new UpdateStu("王同学", 01051); 37 UpdateStu stu4 = new UpdateStu("马同学", 01012); 38 TreeSet<UpdateStu> tree = new TreeSet<>(); 39 tree.add(stu1); 40 tree.add(stu2); 41 tree.add(stu3); 42 tree.add(stu4); 43 Iterator<UpdateStu> it = tree.iterator(); 44 System.out.println("Set集合中的所有元素:"); 45 while (it.hasNext()) { 46 UpdateStu stu = (UpdateStu) it.next(); 47 System.out.println(stu.getId() + " " + stu.getName()); 48 } 49 it = tree.headSet(stu2).iterator(); 50 System.out.println("截取前面部分的集合:"); 51 while (it.hasNext()) { 52 UpdateStu stu = (UpdateStu) it.next(); 53 System.out.println(stu.getId() + " " + stu.getName()); 54 } 55 it = tree.subSet(stu2, stu3).iterator(); 56 System.out.println("截取中间部分的集合"); 57 while (it.hasNext()) { 58 UpdateStu stu = (UpdateStu) it.next(); 59 System.out.println(stu.getId() + " " + stu.getName()); 60 } 61 } 62 } 63 /* 64 运行结果: 65 66 67 68 Set集合中的所有元素: 69 521 李同学 70 522 马同学 71 529 陈同学 72 553 王同学 73 截取前面部分的集合: 74 521 李同学 75 522 马同学 76 截取中间部分的集合 77 529 陈同学 78 79 分析:存入TreeSet类实现的Set集合必须实现Comparable接口,该接口中的compareTo(Object o)方法比较此对象与指定对象的顺序,如果该对象小于,等于,或大于指定对象,则分别返回负整数,0或正整数。 80 */
(3)contains方法:boolean contains(object o);判断集合中是否包含某个元素
1 import java.util.*; 2 3 class Collection01 4 { 5 //重写equals方法 6 7 public static void main(String[] args) 8 { 9 //创建集合 10 Collection c = new ArrayList(); 11 //创建Integer类型对象 12 Integer i1 = new Integer(10); 13 //添加元素 14 c.add(i1); 15 //判断集合中是否包含i1 16 System.out.println(c.contains(i1));//true 17 18 Integer i2= new Integer(10); 19 System.out.println(c.contains(i2));//true 20 21 Manager m1=new Manager(100,"JACK"); 22 c.add(m1); 23 //contasins方法调用底层的是equals方法,如果equals方法返回True,就是包含 24 System.out.println(c.contains(m1));//true 25 26 Manager m2=new Manager(100,"JACK"); 27 //重写equas方法之前返回false,(比较内存地址) 28 //System.out.println(c.contains(m2));//false 29 //重写equas方法之后返回True,集合中的对象都要重写equalos方法(比较内容) 30 System.out.println(c.contains(m2));//true 31 32 } 33 } 34 class Manager 35 { 36 int no; 37 String name; 38 Manager(int no,String name) 39 { 40 this.no=no; 41 this.name=name; 42 } 43 public boolean equals(Object o) 44 { 45 if(this==o) return true; 46 if(o instanceof Manager) 47 { 48 Manager m = (Manager)o; 49 if(m.no == this.no && m.name.equals(this.name)) 50 { 51 return true; 52 } 53 } 54 return false; 55 } 56 57 }
(4)remove方法:boolean remove(object o);删除集合中的某个元素
1 import java.util.*; 2 /* 3 boolean remove(Object o) 4 集合中的元素都需要重写equals方法,在Object的equals方法比较内存地址,在解决实际问题的时候应该比较内容 5 */ 6 7 class Remove 8 { 9 public static void main(String[] args) 10 { 11 Collection c = new ArrayList(); 12 Integer i1 = new Integer(10); 13 c.add(i1); 14 Integer i2=new Integer(10); 15 c.remove(i2); 16 System.out.println(c.size());//0 17 Manager m2=new Manager(100,"ZHANG"); 18 c.remove(m2); 19 System.out.println(c.size());//0 20 } 21 } 22 class Manager 23 { 24 int no; 25 String name; 26 Manager(int no,String name) 27 { 28 this.no=no; 29 this.name=name; 30 } 31 32 }
(5)两种remove方法的区别
a.迭代器的remove方法
1 import java.util.*; 2 3 class Remove1 4 { 5 public static void main(String[] args) 6 { 7 Collection c = new ArrayList(); 8 c.add(1); 9 c.add(2); 10 c.add(3); 11 Iterator it = c.iterator(); 12 while(it.hasNext()) 13 { 14 Object element = it.next(); 15 it.remove(); 16 } 17 System.out.println(c.size()); 18 } 19 }
b.集合自身带的remove方法
1 import java.util.*; 2 3 class Remove1 4 { 5 public static void main(String[] args) 6 { 7 Collection c = new ArrayList(); 8 c.add(1); 9 c.add(2); 10 c.add(3); 11 Iterator it = c.iterator(); 12 while(it.hasNext()) 13 { 14 Object element = it.next(); 15 c.remove(element); 16 //集合自身带的remove在将元素删除后,迭代器失效,需要重新获得迭代器,若不添加此语句,则会出现异常 17 it = c.iterator(); 18 } 19 System.out.println(c.size()); 20 } 21 }
2.1.3、List接口中的方法分析:(有序可重复)
(1).添加元素,遍历元素
1 import java.util.*; 2 3 class Main //有序可重复 4 { 5 public static void main(String[] args) 6 { 7 List L = new ArrayList(); 8 L.add(100); 9 L.add(200); 10 L.add(1300); 11 L.add(120); 12 L.add(100); 13 Iterator it = L.iterator(); 14 while (it.hasNext()) 15 { 16 Object element = it.next(); 17 System.out.println(element); 18 } 19 20 } 21 }
(2)ArrayList底层原理
1 package shili; 2 3 import java.util.*; 4 /** 5 * ArrayList底层集合是数组 6 * ArrayList默认容量是10,扩容后的新容量是原容量的1.5倍 7 * vector集合底层默认初始容量是10,扩容后是原容量的2倍。 8 * 如果优化ArrayList和Vector? 9 * 尽量减少扩容操作,扩容需要拷贝数组,拷贝很消耗内存,一般在创建集合时指定初始化 10 */ 11 class Main 12 { 13 public static void main(String[] args) 14 { 15 //创建List集合 16 List l = new ArrayList(); 17 l.add(10); 18 l.add(20); 19 l.add(30); 20 //在下标为1的位置上添加100 21 l.add(1,100); 22 //获取第一个元素 23 System.out.println(l.get(0)); 24 //便利(List集合特有的便利方式) 25 System.out.println("--------------------"); 26 for(int i=0;i<l.size();i++){ 27 Object element= l.get(i); 28 System.out.println(element); 29 } 30 31 } 32 }
(3)ArrayList与Vector的区别
a.Vector是线程安全的,Arrayliast是线程不安全的 。
b.ArrayList在底层数组不够用的时候扩展为原来的1.5倍,Vector默认扩展为你原来的2倍。
对于第一点可以通过原码来观察:
vector原码:
1 public class Vector<E> 2 extends AbstractList<E> 3 implements List<E>, RandomAccess, Cloneable, java.io.Serializable 4 { 5 /** 6 * The array buffer into which the components of the vector are 7 * stored. The capacity of the vector is the length of this array buffer, 8 * and is at least large enough to contain all the vector's elements. 9 * 10 * <p>Any array elements following the last element in the Vector are null. 11 * 12 * @serial 13 */ 14 protected Object[] elementData;
Vector的add方法:
1 public synchronized boolean add(E e) { 2 modCount++; 3 ensureCapacityHelper(elementCount + 1); 4 elementData[elementCount++] = e; 5 return true; 6 }
ArrayList的add方法
1 public boolean add(E e) { 2 ensureCapacityInternal(size + 1); // Increments modCount!! 3 elementData[size++] = e; 4 return true; 5 }
分析:从add方法中可以看到,vector的add方法中添加了synchronized关键字来保证vector的线程是安全的。
其实vector的其他方法中,也都加了synchronized关键字。
2.1.4 set接口中的方法分析:(无序不可重复)
(1).HasHset

1 /* 2 set集合中存储元素,该元素的hashCode和equals方法 3 HashMap中有一个put的方法,put(key,value) key是无序不可重复的 4 存储在hashSet集合或者HashMap集合Key部分的元素,需要同时重写hashCode方法和equals方法 5 */ 6 import java.util.*; 7 class SetTest 8 { 9 public static void main(String[] args) 10 { 11 //创建集合 12 Set es =new HashSet(); 13 Employee e1 = new Employee("1000","u1"); 14 Employee e2 = new Employee("1001","u2"); 15 Employee e3 = new Employee("2000","u3"); 16 Employee e4 = new Employee("2001","u4"); 17 Employee e5 = new Employee("2001","u4"); 18 19 es.add(e1); 20 es.add(e2); 21 es.add(e3); 22 es.add(e4); 23 es.add(e5); 24 System.out.println(es.size()); 25 26 } 27 } 28 29 //员工编号1000~9999 30 class Employee 31 { 32 String no; 33 String name; 34 Employee(String no,String name) 35 { 36 this.no=no; 37 this.name=name; 38 } 39 //重写equals方法,如果员工编号相同,并且名字相同,则是同一个对象 40 public boolean equals(Object o) 41 { 42 if(this == o) { 43 return true; 44 } 45 if(o instanceof Employee){ 46 Employee e= (Employee)o; 47 if(e.no.equals(this.no) && e.name.equals(this.name)){ 48 return true; 49 } 50 } 51 return false; 52 } 53 //重写hashCode方法 54 public int hashCode() 55 { 56 return no.hashCode(); 57 } 58 59 }
(2)SortedSet
1 /* 2 java.util.Set; 3 java.util.SortSet;无序不可重复,但是进去的元素可以按照元素的大小顺序自动进行排序 4 java.util.TreeSet; 5 */ 6 import java.util.*; 7 import java.text.*; 8 class SortSettest 9 { 10 public static void main(String[] args) throws ParseException 11 { 12 //创建集合 13 SortedSet ss = new TreeSet(); 14 //天加元素 自动装箱 15 ss.add(30); 16 ss.add(20); 17 ss.add(33); 18 ss.add(10); 19 ss.add(60); 20 ss.add(8); 21 //遍历 22 Iterator it = ss.iterator(); 23 while(it.hasNext()){ 24 Object e = it.next(); 25 System.out.println(e); 26 } 27 //String 28 SortedSet str = new TreeSet(); 29 str.add("zhangsan"); 30 str.add("lisi"); 31 str.add("wangwu"); 32 str.add("maliu"); 33 str.add("liuba"); 34 //遍历 35 it = str.iterator(); 36 while(it.hasNext()){ 37 Object e = it.next(); 38 System.out.println(e); 39 } 40 //Date 41 SortedSet times = new TreeSet(); 42 String t1 = "2009-10-01"; 43 String t2 = "2012-01-01"; 44 String t3 = "2014-06-08"; 45 String t4 = "2018-07-01"; 46 String t5 = "2008-08-08"; 47 //设置格式 48 SimpleDateFormat def = new SimpleDateFormat("yyyy-MM-dd"); 49 //日期格式化 50 Date ut1 = def.parse(t1); 51 Date ut2 = def.parse(t2); 52 Date ut3 = def.parse(t3); 53 Date ut4 = def.parse(t4); 54 Date ut5 = def.parse(t5); 55 //添加 56 times.add(ut1); 57 times.add(ut2); 58 times.add(ut3); 59 times.add(ut4); 60 times.add(ut5); 61 //遍历 62 63 it = times.iterator(); 64 while(it.hasNext()){ 65 Object e = it.next(); 66 if(e instanceof Date){ 67 Date d = (Date)e; 68 System.out.println(def.format(d)); 69 } 70 71 } 72 73 74 } 75 }
(3)SortedSet内部的比较方法compareTo()
1 /* 2 SortedSet集合存储元素内部排序方法 3 sun编写TreeSe集合添加元素的时候,会调用compareTo方法完成比较 4 */ 5 import java.util.*; 6 class SortSet 7 { 8 public static void main(String[] args) 9 { 10 SortedSet users = new TreeSet(); 11 User u1 = new User(10); 12 User u2 = new User(20); 13 User u3 = new User(13); 14 User u4 = new User(15); 15 User u5 = new User(2); 16 users.add(u1); 17 users.add(u2); 18 users.add(u3); 19 users.add(u4); 20 users.add(u5); 21 //遍历 22 Iterator it = users.iterator(); 23 while(it.hasNext()) 24 { 25 System.out.println(it.next()); 26 } 27 } 28 } 29 class User implements Comparable //必须实现comparable接口 30 { 31 int age; 32 User(int age) 33 { 34 this.age=age; 35 } 36 public String toString(){ 37 return "User[age="+age+"]"; 38 } 39 //实现java.lang.Comparable;接口中的comparable方法 40 //按照user的age进行排序 41 @Override 42 public int compareTo(Object o) { 43 // TODO 自动生成的方法存根 44 int age1=this.age; 45 int age2=((User)o).age; 46 return age2-age1; 47 } 48 }
(4)SortedSet内部的比较方法Comparator
1 /* 2 SortedSet集合存储元素内部排序方法 3 */ 4 import java.util.*; 5 import java.util.Comparator; 6 class Main 7 { 8 public static void main(String[] args) 9 { 10 //创建TreeSet集合的时候提供一个比较器 11 SortedSet products = new TreeSet(new ProductComparator()); 12 Product p1 = new Product(2.0); 13 Product p2 = new Product(3.0); 14 Product p3 = new Product(1.0); 15 Product p4 = new Product(6.0); 16 Product p5 = new Product(5.0); 17 //添加元素 18 products.add(p1); 19 products.add(p2); 20 products.add(p3); 21 products.add(p4); 22 products.add(p5); 23 //遍历 24 Iterator it = products.iterator(); 25 while(it.hasNext()){ 26 System.out.println(it.next()); 27 } 28 } 29 } 30 31 32 class Product 33 { 34 double price; 35 Product(double price) 36 { 37 this.price=price; 38 } 39 public String toString(){ 40 return price + ""; 41 } 42 } 43 44 45 class ProductComparator implements Comparator 46 { 47 @Override 48 public int compare(Object o1, Object o2) { 49 // TODO 自动生成的方法存根 50 double price1 = ((Product)o1).price; 51 double price2 = ((Product)o2).price; 52 if(price1 == price2){ 53 return 0; 54 } 55 else if(price1>price2){ 56 return 1; 57 } 58 else{ 59 return -1; 60 } 61 } 62 }
2.2 常见集合的继承结构-Map

2.2.1 Map集合中常用实现类的数据结构及特点
(1)HashMap :
哈希表/散列表,底层是一个哈希表,HashMap中的Key等同一个Set集合(无序不重复,结构如下图),允许key或vaue为空,线程不安全。如果要使map线程安全,方法参考:http://www.cnblogs.com/cloudwind/archive/2012/08/30/2664003.html
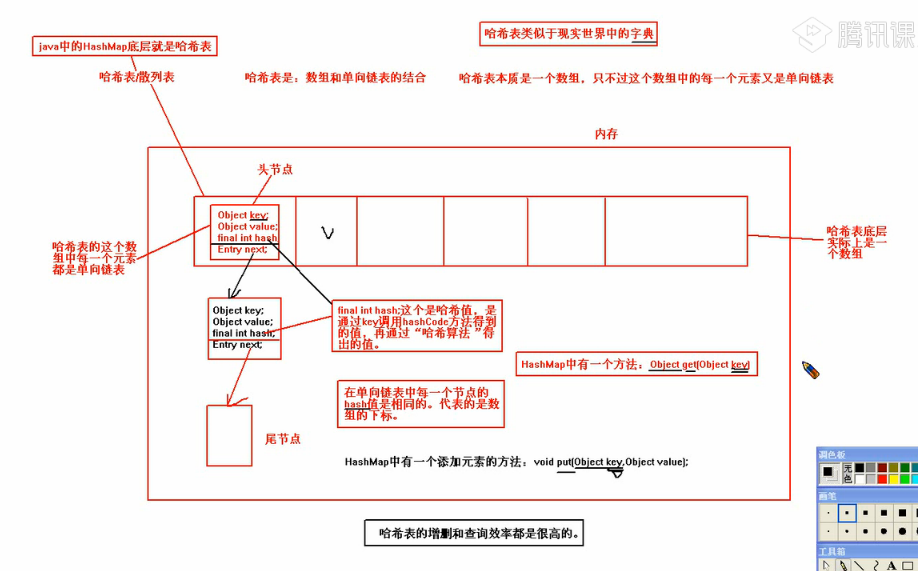
图. 哈希表/散列表
(2)Hashtable
线程安全的效率低。不允许key或vaue为空,线程安全。
(3)Properties
属性类,也可以是Key 和value的方式存储元素,但是Key 和value只能是字符串类型。Properties是HashTable的子类,不过Properties添加了两个方法,load()和store()可以直接导入或者将映射写入文件。
(4)SortedMap
SortedMap中的key存储元素的特点是:无序不可重复,但可以按照元素的大小进行自动排序,SortedMap中的key等同于SortedSet。
(5)TreeMap
TreeMap的Key就是一个TreeSet。
(6)LinkedHashMap
详解:http://www.cnblogs.com/chenpi/p/5294077.html
2.2.2、 Map集合中常用的方法分析

1 /* 2 Map中常用的方法举例 3 *存储在Map集合key部分的元素需要重写hashCode+equals方法 4 */ 5 import java.util.*; 6 class Maptest 7 { 8 public static void main(String[] args) 9 { 10 //创建Map集合 11 Map persons = new HashMap();//HashMap的默认初始化容量是16,默认加载因子是0.75 12 //存储键值对 13 persons.put("10000","lisi"); 14 persons.put("10001","张三"); 15 persons.put("10002","wangwu"); 16 persons.put("10003","maliu"); 17 persons.put("10004","zhaoqi"); 18 //判断键值对你的个数,map中的key是无序不可重复的,和HashSet相同 19 System.out.println(persons.size()); 20 21 System.out.println(persons.containsKey("10000")); 22 23 System.out.println(persons.containsValue("张三")); 24 25 System.out.println(persons.get("10000")); 26 27 persons.remove("10004"); 28 System.out.println(persons.size()); 29 30 //获取所有的value 31 Collection value = persons.values(); 32 Iterator it = value.iterator(); 33 while(it.hasNext()) 34 { 35 System.out.println(it.next()); 36 } 37 //获取所有的Key 38 Set keys = persons.keySet(); 39 Iterator it2 = keys.iterator(); 40 while(it2.hasNext()) 41 { 42 Object id = it2.next(); 43 Object name = persons.get(id); 44 System.out.println(id+"->"+name); 45 } 46 //返回此映射中包含的映射关系的Set图 47 Set entrySet = persons.entrySet(); 48 Iterator it3 = entrySet.iterator(); 49 while(it3.hasNext()) 50 { 51 System.out.println(it3.next()); 52 } 53 /* 54 输出结果 55 10001=张三 56 10002=wangwu 57 10000=lisi 58 10003=maliu 59 */ 60 } 61 }
(1)Hashtable集合中常用的方法分析
1 /* 2 HashMap默认初始化容量是16,默认加载因子是0.75 3 Hashtable 默认初始化容量是11,默认家在因子是0.75 4 java.util.Properties,是由key和value都是字符串类型 5 */ 6 import java.util.Properties; 7 class MapProperties 8 { 9 public static void main(String[] args) 10 { 11 //创建属性类对象 12 Properties p = new Properties(); 13 //存数据 14 p.setProperty("1000","z"); 15 p.setProperty("1001","d"); 16 p.setProperty("1002","s"); 17 p.setProperty("1003","j"); 18 //遍历,通过key获取value 19 String v1 = p.getProperty("1000"); 20 String v2 = p.getProperty("1001"); 21 String v3 = p.getProperty("1002"); 22 String v4 = p.getProperty("1003"); 23 24 System.out.println(v1); 25 System.out.println(v2); 26 System.out.println(v3); 27 System.out.println(v4); 28 } 29 } 30 /* 31 运行结果 32 z 33 d 34 s 35 j 36 */
(2)SortedMap集合的用法
1 import java.util.*; 2 3 /* 4 SortedMap中的key特点:无序不可重复,但存进去的元素可以按照大小自动排序 5 key的特点:1.实现Comparable接口2,,单独写一个比较器 6 */ 7 class SortedMaptest02 8 { 9 10 public static void main(String[] args) 11 { 12 //Map,Key存储Product,value个数 13 SortedMap<Product, Double> product = new TreeMap<Product, Double>(); 14 //准备对象 15 Product p1 = new Product("肉1",12.0); 16 Product p2 = new Product("肉2",10.0); 17 Product p3 = new Product("肉3",11.0); 18 Product p4 = new Product("肉4",15.0); 19 Product p5 = new Product("肉5",17.0); 20 21 product.put(p1,2.0); 22 product.put(p2,2.0); 23 product.put(p3,2.0); 24 product.put(p4,2.0); 25 product.put(p5,2.0); 26 //遍历 27 Set keys = product.keySet(); 28 Iterator it = keys.iterator(); 29 while(it.hasNext()) 30 { 31 Object k = it.next(); 32 Object v = product.get(k); 33 System.out.println(k+"..."+v); 34 } 35 } 36 } 37 //实现Comparable接口 38 class Product implements Comparable 39 { 40 String name; 41 double price; 42 Product(String name,double price){ 43 this.name = name; 44 this.price = price; 45 } 46 public String toString() 47 { 48 return "Product[name = "+name+",price = "+price+"]"; 49 } 50 //实现compareo方法,按照商品价格进行排序 51 public int compareTo(Object o) 52 { 53 double price1 = this.price; 54 double price2 = ((Product)o).price; 55 if(price1>price2) 56 return 1; 57 else if(price2>price1) 58 return -1; 59 else return 0; 60 61 } 62 }
2.3 Collections集合工具类的用法
1 package test; 2 3 /* 4 1.集合工具类 java.util.Collections (类) 5 2.Java.util.Collection 接口 6 */ 7 import java.util.*; 8 class Main 9 { 10 @SuppressWarnings("unchecked") 11 public static void main(String[] args) 12 { 13 @SuppressWarnings("rawtypes") 14 List list = new ArrayList(); 15 list.add("5"); 16 list.add("9"); 17 list.add("8"); 18 list.add("4"); 19 list.add("6"); 20 @SuppressWarnings("rawtypes") 21 Iterator it = list.iterator(); 22 while(it.hasNext()){ 23 System.out.println(it.next()); 24 } 25 System.out.println("........................."); 26 Collections.sort(list); 27 it = list.iterator(); 28 while(it.hasNext()){ 29 System.out.println(it.next()); 30 } 31 32 //对set集合进行排序 33 Set s = new HashSet(); 34 s.add("3"); 35 s.add("1"); 36 s.add("8"); 37 s.add("4"); 38 s.add("6"); 39 System.out.println("........................."); 40 //不能更直接使用Collections。sort(s)进行排序 41 //将Set集合转换成List集合 42 List lists = new ArrayList(s); 43 Collections.sort(lists); 44 it = lists.iterator(); 45 while(it.hasNext()){ 46 System.out.println(it.next()); 47 } 48 //将ArrayList转换成线程安全的 49 List mylist = new ArrayList<>(); 50 Collections.synchronizedList(mylist); 51 52 } 53 }
3.泛型
泛型是Java SE 1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。 JAVA语言引入泛型的好处是安全简单。在Java SE 1.5之前,没有泛型的情况的下,通过对类型Object的引用来实现参数的“任意化”,“任意化”带来的缺点是要做显式的强制类型转换,而这种转换是要求开发者对实际参数类型可以预知的情况下进行的。对于强制类型转换错误的情况,编译器可能不提示错误,在运行的时候才出现异常,这是一个安全隐患。
package test; /* JDk5.0新特性:泛型(编译阶段的语法,在编译阶段同一集合中的类型) 1.语法实现 2.优点:使集合中的元素的类型统一,减少强制类型转换 3.缺点:只能存储一种数据类型 */ import java.util.*; class Main { public static void main(String[] args) { //创建一个List集合,只能存储字符串类型 List <String> str = new ArrayList<String>(); str.add("sd"); str.add("sfhj"); str.add("dsf"); str.add("hjk"); str.add("sdf"); Iterator <String> it = str.iterator(); while(it.hasNext()){ String s = it.next(); System.out.println(s); } } }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号