Python读取Excel时如何避免数据类型被修改
一、背景
在做数据分析时,有时候Python的Pandas会把Excel中的文本数据(例如编号,身份证号)识别为’float’或’int’类型,导致数据类型出现错误,我们不希望它改变数据的类型。比如:卡号的数据类型是字符串,我们不希望它读取后,类型改为数字类型
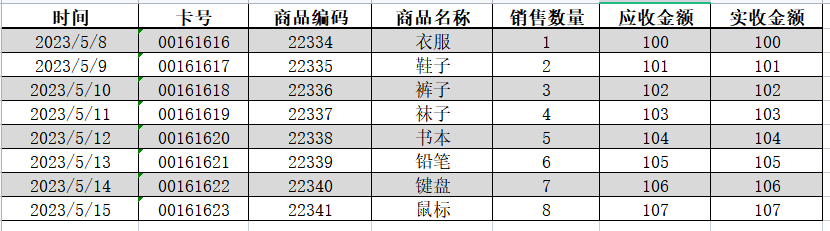
二、脚本编写
1、错误演示
在不做任何特殊处理的时候,卡号的数据类型是字符串,会改为数字类型
import os
import pandas as pd
# 获取当前文件路径
current_dir = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(current_dir, "test_data", 'data.xlsx')
# 读取Excel文件
data = pd.read_excel(file_path)
data.info()
# 以表格形式打印数据
print(data)
结果:
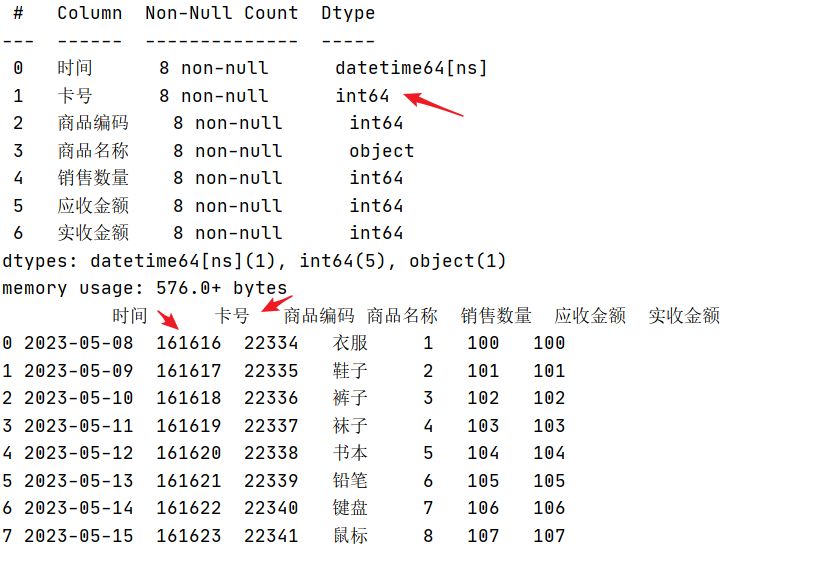
可以看到卡号列的数据被改为int类型,展示的时候卡号前两位00不见了。
2、正确演示
在编写脚本时,我们制定对应列的类型,然后就可以避免此类错误的出现,具体如下:
dtype = {
'卡号': str
}
data = pd.read_excel(file_path, dtype=dtype)
详细代码:
import os
import pandas as pd
# 获取当前文件路径
current_dir = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(current_dir, "test_data", 'data.xlsx')
dtype = {
'卡号': str
}
# 读取Excel文件
data = pd.read_excel(file_path, dtype=dtype)
data.info()
# 以表格形式打印数据
print(data)
结果:
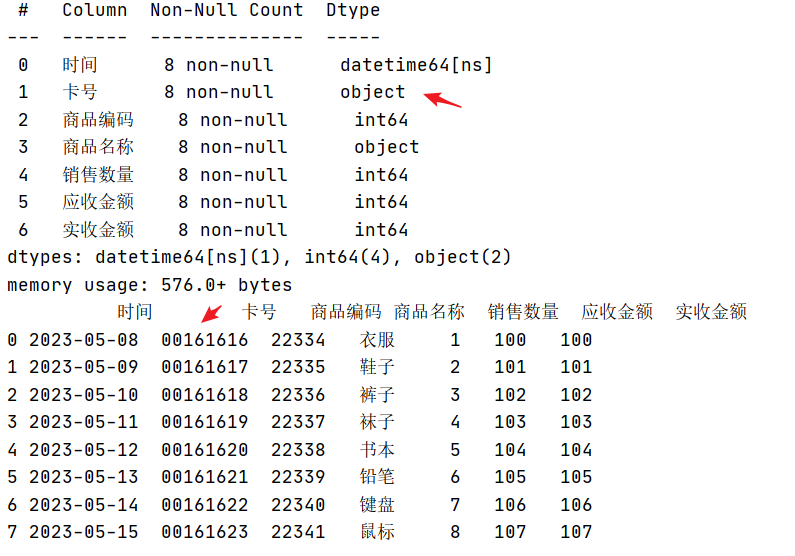
现在是完全满足我们的需求了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号