python提取allure report报告中数据信息
通过分析,可以发现allure生成的报告,其数据保存在报告路径下的data中
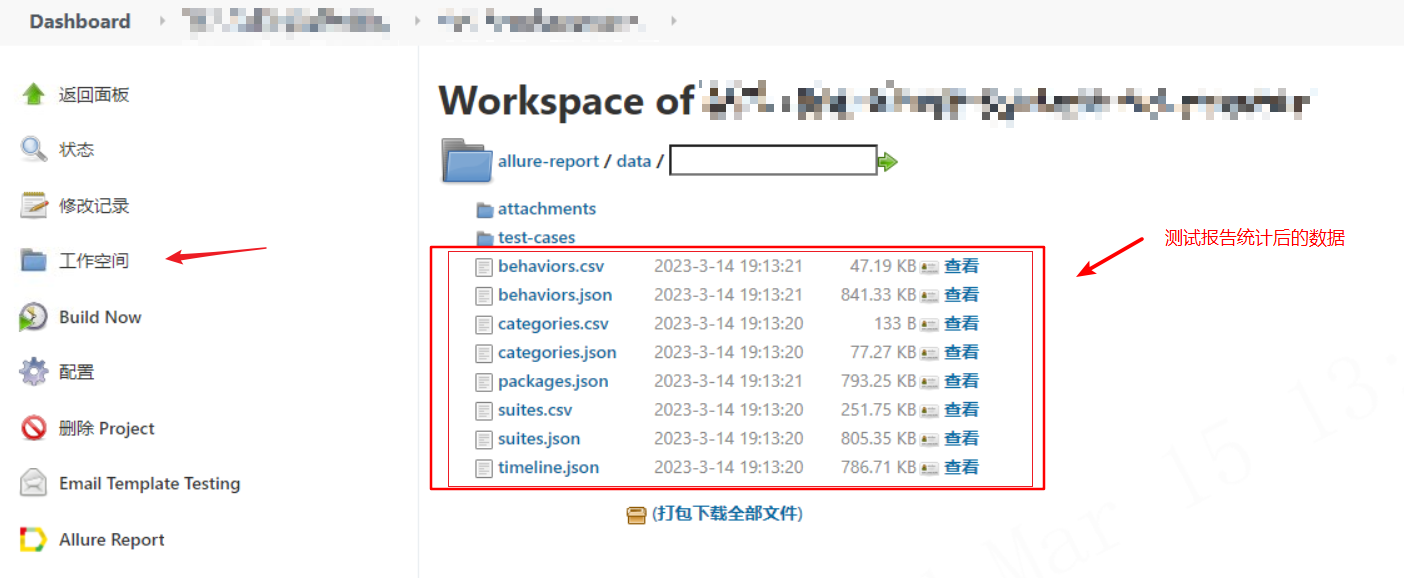
其,文件分别对应着报告结构中的这些项目
一、执行步骤
1、读取Allure报告中的文件
读取Allure报告中的json文件
def get_json_data(file_path):
"""
读取json文件中的数据
:param file_path: 文件路径
:return:
"""
if os.path.exists(file_path):
files = os.path.splitext(file_path)
filename, suffix = files # 获取文件后缀
if suffix == '.json':
with open(file_path, 'r', encoding="utf-8") as fp:
data = json.load(fp)
else:
log.error('文件后缀名错误')
else:
log.error('文件路径不存在')
return data
2、提取测试用例信息
test_cases = soup.find_all('test-case')
for test_case in test_cases:
name = test_case.get('name')
description = test_case.description.text
status = test_case.status.get('status')
# 输出测试用例信息
print('Test Case Name: ' + name)
print('Description: ' + description)
print('Status: ' + status)
3、提取测试步骤信息
steps = test_case.find_all('step')
for step in steps:
name = step.name.text
status = step.status.get('status')
# 输出测试步骤信息
print('Step Name: ' + name)
print('Status: ' + status)
4、提取测试执行时间信息
time = test_case.time.get('duration')
# 输出测试执行时间信息
print('Test Execution Time: ' + time + ' ms')
5、提取测试结果统计信息
test_suite = soup.find('test-suite')
passed = test_suite.statistic.get('passed')
failed = test_suite.statistic.get('failed')
skipped = test_suite.statistic.get('skipped')
# 输出测试结果统计信息
print('Tests Passed: ' + passed)
print('Tests Failed: ' + failed)
print('Tests Skipped: ' + skipped)
通过以上步骤,我们可以在Allure报告中提取更加丰富的数据信息,包括测试执行时间、测试失败和测试中断等信息。同时,需要注意Allure报告的xml文件结构可能会随着版本更新而发生变化,因此要根据不同版本的报告进行适当的修改。这些数据信息可以作为分析和优化测试用例的依据,帮助测试人员更好地发现和修复测试问题,提高测试效率和质量。
二、参考
1、allure官网:https://docs.qameta.io/allure-report/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号