python基础知识点(一)
自己开始学python时的一些笔记,当时写了word文档,现在在博客里整理一下,有点乱,也有点长,希望能帮助大家,也方便自己查询(ps:只适合初学者,大佬直接跳过就OK了)。
1.Python中的列表,非常适合实现栈的入栈和出栈操作:
列表的append()方法对应入栈操作,列表的pop()方法对应出栈操作
s=[]
s.append(1)#在列表的末尾填上元素1
s.append(2)
print(s)#结果为[1,2]
s.pop() #返回列表最后一个元素并删除


2.队列核心操作:尾部添加,首部删除


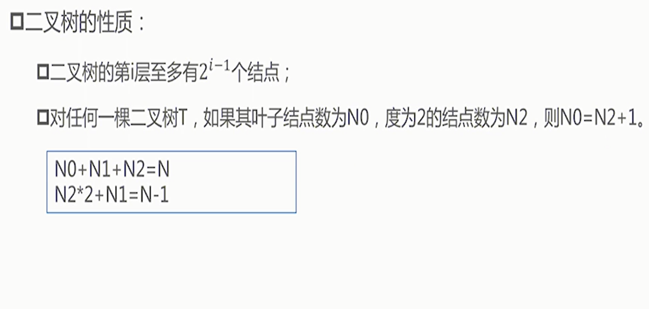
3.如果一个树的每个节点,都至多有两个子节点,则成为二叉树。
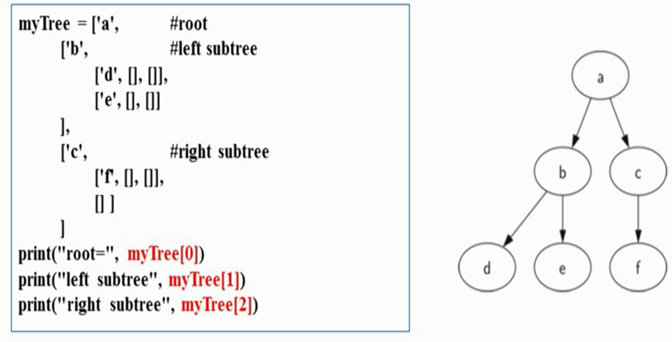
如何使用嵌套列表实现二叉树:以根节点,左子树,右子树为顺序,依次写出。
4.字典类型{}操作函数和方法



5.python第三方库,jieba,中文分词,其中最重要的函数就是jieba.lcut()可以以列表形式将一句话返回具体的分词结果。

6.文本词频统计
# 此程序用来统计英文著作中出现的最多的单词前几名及对应的次数

>>> dic={'apple':1,'book':2,'money':10}
>>> dic.items()
dict_items([('apple', 1), ('book', 2), ('money', 10)])
>>> items=list(dic.items())
>>> items
[('apple', 1), ('book', 2), ('money', 10)]
>>> items.sort(key=lambda x:x[1],reverse=True)
>>> items=list(dic.items()) #counts是一个字典,items将字典以列表形式返回,items就是一个列表
>>> items.sort(key=lambda x:x[1],reverse=True)
>>> items
[('money', 10), ('book', 2), ('apple', 1)]
>>> items[0]
('money', 10)
>>>
1)lambda功能:创建匿名函数(lambda只是一个表达式,而def则是一个语句)
这里,lambda匿名函数和matlab中的匿名函数@一样,fun=@(x,y) x+y

2) items函数,将一个字典以列表的形式返回,因字典是无序的返回的列表也是无序的
>>> dic={'apple':1,'book':2,'money':10}
>>> dic.items()
dict_items([('apple', 1), ('book', 2), ('money', 10)])
>>>
7.文件的打开和关闭
文件打开<变量名>=open(<文件名>,<打开模式>)


文件关闭
<变量名>.close() #这里变量名是文件句柄



文件句柄.read(2) #一次读入文件的前两个字节,只要读入的不为空就继续读入,属于分批处理。

上图为分行读入,逐行处理


8.二维数据的遍历:二维数据中每一个元素也是列表类型

9.词云

(1)先引入词云库,wordcloud
(2)wordcloud.WordCloud()生成一个词云对象赋给变量c
(3)使用c.generate()将一段文本加载到词云中
(4)c.to_file是输出词云文件

w设置了宽度为1000,高度为700,字体为微软雅黑;
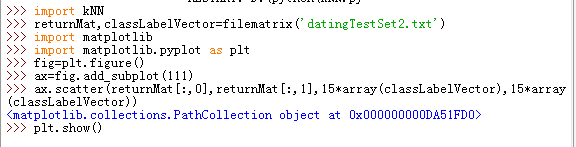
中文文本需要自己分词,这里使用第三方库jieba,jieba.lcut()得到的是一列表,用.join()方法将列表以空格划分赋给generate,再输出词云文件,下图是效果


10.k-近邻算法(kNN)
工作原理:存在一个训练样本集,样本集中每个数据都存在标签。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,算法提取样本集中特征最相似数据的分类标签,一般只选择数据集中前k个最相似的数据。

一个简单程序如下
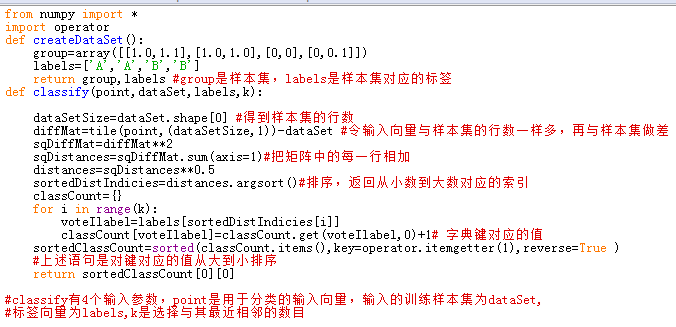
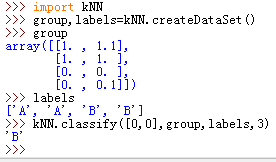

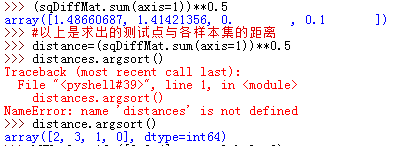
定义一个空字典,取k为3,首先,k=0,sortedDistIndicies[0]=2,然后labels[2]=B,

11.分类器的错误率:分类器给出错误结果的次数除以测试执行的总次数。
12. 1)strip()函数默认删除首尾所有空字符 ‘\n\t空格‘
>>>s='\n 0000this is string example0000wow!!!0000\n \t'
>>> s.strip()
'0000this is string example0000wow!!!0000'
2)#首尾端'0'被删除,中间不动
>>> t='0000this is string example0000wow!!!0000'
>>> t.strip('0')
'this is string example0000wow!!!'
split():拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
13.readline()方法用于从文件读取整行,包括换行字符\n。若指定了一个非负的参数,则返回指定大小的字节数,包括\n字符。
文件test.txt的内容为:
1:xinyingyuexinguowan
2:xinyingyuexinguowan
3:xinyingyuexinguowan

for i in range(5):
print(i,end=’,’)
结果:0,1,2,3,4,
14.from os import listdir
原型为os.listdir(path)# listdir()函数用来获取指定目录的内容。Eg:trainingFileList=listdir('D:/python/trainingDigits')
15.如下
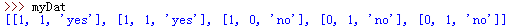

myDat是个列表,要求列表中的每个元素也是列表,且长度相同。[example[0] for example in myDat]是将myDat中每一个列表的第一个元素提取出来。


16.列表中[:0]是将列表置成空列表,列表名[:1]是将列表的第一个元素赋给列表。列表名[:n]是将列表中的前n个元素取出。列表名[n:]是将索引n及n以后的元素都取出。


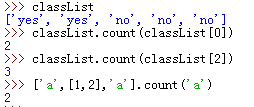
17.count()是列表中的元素次数统计函数。
18. a|b #a,b是两个集合,a|b是两个集合的并集;list(a)是将一个集合变成一个列表。



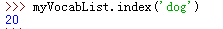
列表名.index(列表中的元素)#返回列表中的元素所在的索引值
19.对于一个文本字符串,python的string.split()方法可以按空格将其拆分,缺点是包含了标点。

20. random.uniform(x,y)#方法将随机生成一个实数,它在[x,y)之间,x是随机数的最小值,包含该值,y是随机数的最大值,不包含该值。


上图随机生成的3*3数组和mat(数组)后虽然显示的东西一样,但类型不一样,用mat函数转换为矩阵之后才可以进行一些线性代数的操作。
21. m,n=shape(A)#得到矩阵A的大小,即行数与列数
ones((3,1))得到的是3行1列的全1数组,shape(shuzu)[0]得到的是数组的行数。
ones(5) 结果: array([ 1., 1., 1., 1., 1.]) #生成全为1 的行向量数组

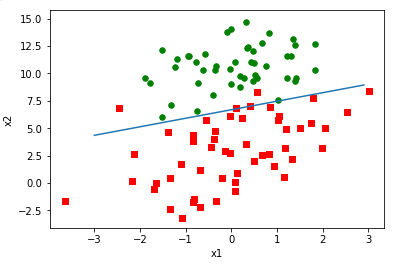
22.下图是实现的logistics回归问题,要注意:坐标x,y的对应维度要相等,x=np.arange(-3.0,3.0,0.1) shape(x)的结果是(60,),数组行向量y要将其转置为列向量,y=np.array(y).transpose()
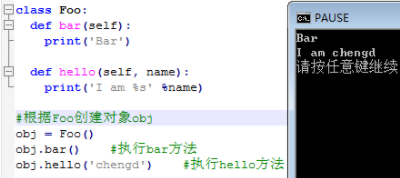
23.Python 中定义私有变量只需要在变量名或函数名前加上“_ _”两个下划线。在外部,使用 _类名_ _变量名即可访问双下横线开头的私有变量了。
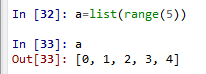
24.A是一个矩阵,100行3列,则A[0]即为矩阵的第一行,A[3]即为矩阵的第4行数值。矩阵的第100行和一个数组相乘,结果为对应元素分别相乘

25.sigmoid函数导函数的取值范围是多少,首先g(z)=1/(1+exp(-z)),其导数是g’(z)=exp(-z)/(1+exp(-z))**2,取值范围就是(0,1/4]

26.一个数乘个列表list,是把列表重复这么多次,一个数乘个数组array,才能把每个元素都乘对应的数。
27.支持向量机的优缺点:

28.如下图,定义函数即使是pass,没有return,函数依旧会返回一个None对象。类型为noneType,但type(f)就是一个函数类型。


29.python的getattr,hasattr,和setattr()方法详解
博客:https://www.cnblogs.com/cenyu/p/5713686.html

30.字典添加元素


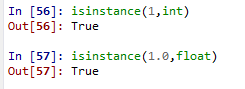
31.isinstance(object, classinfo)
如果参数object是classinfo的实例,或者object是classinfo类的子类的一个实例, 返回True。如果object不是一个给定类型的的对象, 则返回结果总是False。
32. param1参数在本例中对应的传入参数apples,而后边的'bananas', 'cherry', 'kiwi'均被打包进param2中,因为在函数定义时param2的前边有*号表示这是一个不定长定位参数,会将后边的不定长个定位参数打包为一个tuple。因为B选项正确。


33.join函数:连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串。
#对序列进行操作(分别使用' '与':'作为分隔符)
>>> seq1 = ['hello','good','boy','doiido']
>>> print ' '.join(seq1)
hello good boy doiido
>>> print ':'.join(seq1)
hello:good:boy:doiido
#对字符串进行操作
>>> seq2 = "hello good boy doiido"
>>> print ':'.join(seq2)
h:e:l:l:o: :g:o:o:d: :b:o:y: :d:o:i:i:d:o
#对元组进行操作
>>> seq3 = ('hello','good','boy','doiido')
>>> print ':'.join(seq3)
hello:good:boy:doiido
#对字典进行操作
>>> seq4 = {'hello':1,'good':2,'boy':3,'doiido':4}
>>> print ':'.join(seq4)
boy:good:doiido:hello
#合并目录
>>> import os
>>> os.path.join('/hello/','good/boy/','doiido')
'/hello/good/boy/doiido'
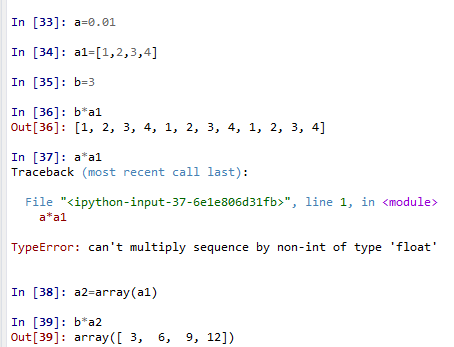
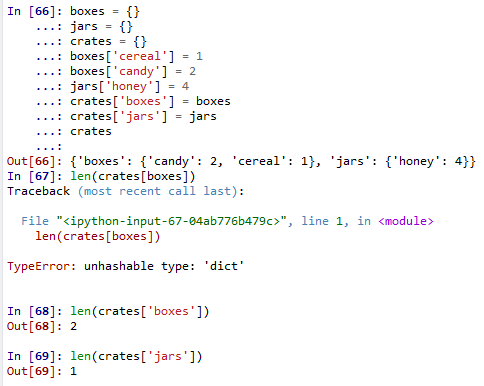
34.字典中的key值不能为字典。字典中key,可以是字符串,数字等不可变类型,它们都是hashable的。而字典,列表等可变类型是不能够作为key值的。因此最后一句crates[boxes] 中的boxes类型为dict,会直接报错。


35.字典中confusion[1]和confusion[1.0]是一样的,会重新赋值。

36. 数据保存和加载。
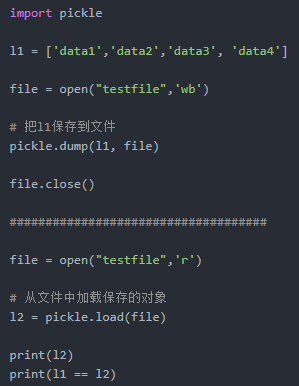

37.定义在类中的方法之外的变量是(类变量)。在Python类中,公有/私有变量是通过_ _进行区别,而在方法之外的变量均为类变量,实例变量均在方法中进行定义且以self.开始。

38.list对象仅能与list对象进行相加。与其它类型对象相加均会报出如unsupported operand type(s) for +: 'int' and 'list'的错误。列表l1=[1,2,3],则表达式1+l1结果异常。
39. fromkeys是字典对象提供的方法,用于创建一个新字典,以第一个参数中的元素做字典的键,第二个参数为字典所有键对应的初始值。
{}. formkeys((1,2),3)返回{1:3,2:3}
40. python中的子类调用父类的方法,需要使用函数super。在类的继承中,如果重定义某个方法,该方法会覆盖父类的同名方法,但有时我们又希望能同时实现父类的功能,我们就需要调用父类的方法了,可通过使用 super 来实现。
41. Python中,关键字__ __可以定义一条异常,引发异常(raise)。python会自动引发异常,也可以通过raise显式地引发异常。一旦执行了raise语句,raise后面的语句将不能执行。
42. python3中每一个字符的长度都被计算为1(包括标点)。字符串"人生苦短,我用Python"的长度是多少?答案是13。
43. chr()函数用一个范围在range(256)内的(就是0~255)整数作参数,返回一个对应的字符。unichr()跟它一样,只不过返回的是Unicode字符。ord()函数是chr()函数(对于8位的ASCII字符串)或unichr()函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的ASCII数值,或者Unicode数值,如果所给的Unicode字符超出了你的Python定义范围,则会引发一个TypeError的异常。

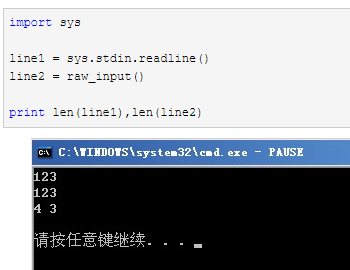
44.关于raw_input()和sys.stdin.readline()的区别:
https://www.cnblogs.com/dolphin0520/archive/2013/03/27/2985492.html
sys.stdin.readline( )会将标准输入全部获取,包括末尾的'\n',因此用len计算长度时是把换行符'\n'算进去了的,但是raw_input( )获取输入时返回的结果是不包含末尾的换行符'\n'的。
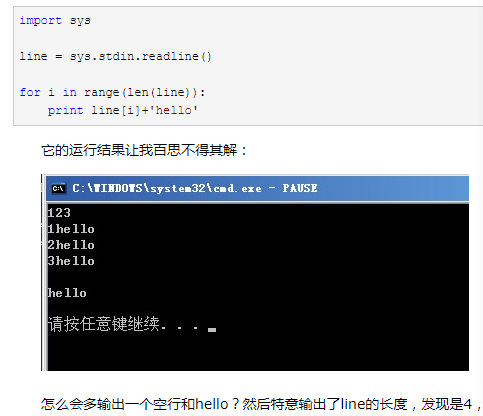
45.字符串逆序方法:
https://blog.csdn.net/seetheworld518/article/details/46756639
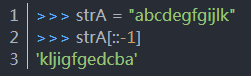
46. input().split(‘ ’)将输入的字符串按空格分割成了列表。列表也可以使用[::-1]实现逆序输出。

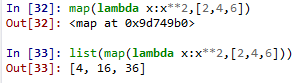
47.在python3里面,map()的返回值已经不再是list,而是iterators, 所以想要使用,只用将iterator 转换成list 即可,比如 list(map()) 。
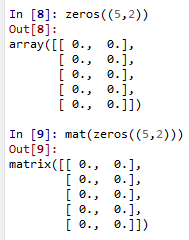
48. mat可以将数组转化为列表类型,相当于矩阵。
49. 列表不能dataMat[ : ,0]这样用,先将其转换为矩阵才能这样用,得到矩阵的第一列。min得到第一列中最小的值。

50. rand()生成0,1内的随机数

51. 数组过滤

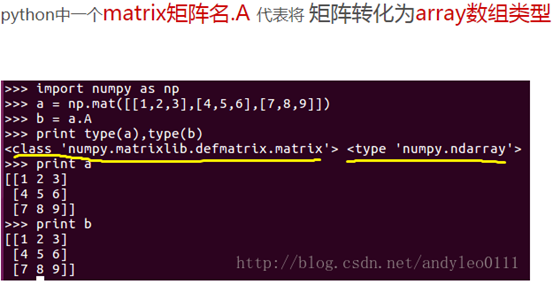
52.矩阵名.A将一个矩阵转换为array数组。
53. nonzeros(a)返回数组a中值不为零的元素的下标。


二维数组的话,即b2[0,0],b2[0,2],b2[1,0]的元素不为0。
具体实现


54. 列表可以转化为数组和矩阵,tolist()实现功能将数组、矩阵转换为列表。对于一维矩阵,tolist()[0]才能转化为列表。

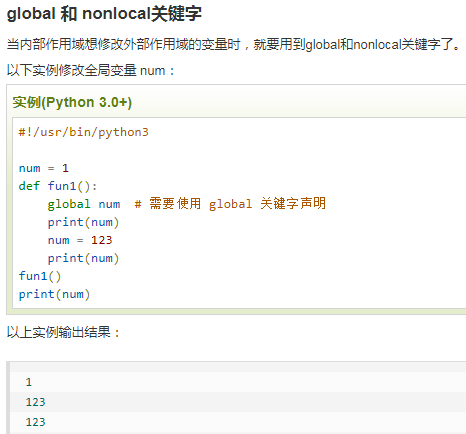
55.global能将函数内的局部变量变成全局变量。
56. for i in (1,2,3): 此时,i取值1,2,3.

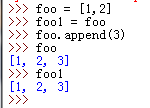
57. python中字符串前面加一个r代表原始字符串标识符;=属于引用,foo变的话,foo1也变,foo1变foo也变;元组属于不可变类型。


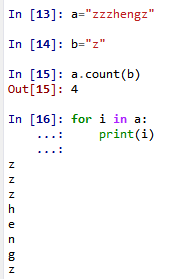
58. a.count(b)用来统计在字符串a中字符b出现的次数。
59. bin(N)将十进制转换为二进制,oct(N)把十进制转换为八进制,hex(N)是把十进制转换成16进制。
60. 对于二维列表,len(列表名)得到列表的行数,len(列表名[0])得到列表的列数。

61. 替换字符串中的某个字符,用replace,str=”xxy”,即str.replace(“x”,”z”) returns zzy

62.代码中判断变量是否为空None,有以下三种写法:
(1)if x is None:
(2)if not x: # 如果x 为False,则not x为True,则执行if语句
(3)if not x is None:
63. index用于返回列表中值对应的索引。

64. _ _init_ _()方法称为构造方法,功能是只要实例化一个对象,这个方法就会在对象被创建时自动调用。
65. 列表的pop()方法用于删除列表的元素,并返回该元素,不指定索引默认删除最后一个元素。

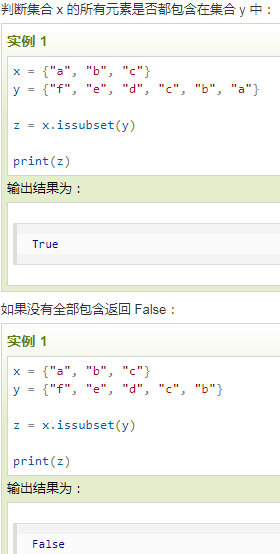
66. issubset用于判断一些集合元素是否在指定集合中,是则返回True,否则返回False.
67. 列表可以指定位置利用insert插入元素,例如z.insert(2,78)则将78插入到索引为2的位置。

68.列表可以指定得到前n个元素,具体如下图,z=[列表元素][:2]表示取列表的前两个元素,前零个元素为空。

69. dict.update(dict2)即将字典dict2添加到字典dict中。若添加的字典中的键在原字典中已存在,则改变其键值。

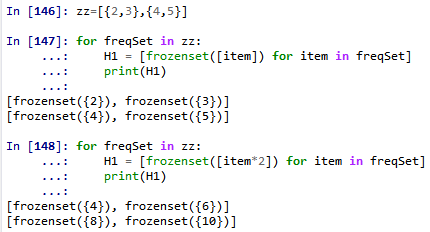
70.语句H1 = [frozenset([item*2]) for item in freqSet]中freqSet先取集合{2,3},for item in freqSet 取值为2,3将其处理成不可变的单个集合元素。
71. 集合可以进行相减操作。

许多事都不是因为喜欢才做,而是因为责任。--------2019.2.23
72. 字典中,字典名[键]即得到键对应的值。当键为data,target时都是字符串型,要加双引号,即键必须是不可变类型。
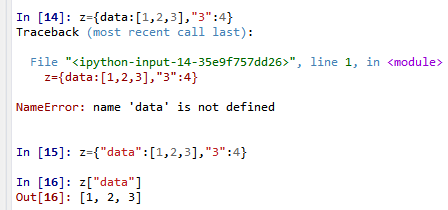
73. 函数原型,vstack(tup),参数tup 可以是元组,列表或者numpy数组。

74. python位操作符左移和右移运算
左移<<:写成二进制后向左移动对应的位数,高位移出舍弃,低位的空位补零。
eg:3<<2将3左移2位。3的二进制为00000011 向左移动两位,变成
00001100,十进制为12。
数学意义:没有溢出的前提下,对于正数和负数,左移n位就相当于乘以2的n次方。
右移>>:按二进制形式把所有的数字向右移动对应的位数,低位移出舍弃,高位的空位正数补0,负数补1。
eg.11>>2:11的二进制为00001011,将其向右移动两位,低位移出舍弃,高位因为11是正数,补0,即 00000010 ,换成二进制是2。即右移一位相当于除以2,右移n位相当于除以2的n次方。这里,结果取的是商,而不是余数。
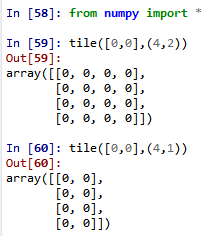
75. tile将对应的点复制对应的次数,并返回数组array类型。
76. 7和5按位异或,7的二进制为00000111, 5的二进制为00000101,异或操作规则,
0^0=0, 0^1=1, 1^0=1 1^1=0 ; 0xFFFFFFFF是16进制中边界数,其值转换为十进制是4294967294,正数和它做与操作,结果还是这个正数,负数和它做与操作,结果就是0xFFFFFFFF本身。

77. 64行是按照字典键对应的值进行从大到小的排序。
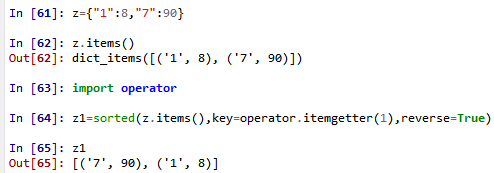
78.对字典取列表,得到以字典的键为元素的列表;对字典的items()取列表,形式如下。

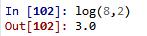
79. log()不能直接使用,需要导入math模块,底数可以设置,默认为e.例如以2为底,8的对数。
列表尾部添加元素。

80.下面119行语句可以得到信息增益最大的特征,比较的每一对数值的第二个元素。如果简单的取max,将得到第一个数最大的。
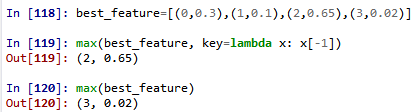
81. python中的.loc和.iloc的区别。loc:通过行标签索引数据,例如,df.loc[1]表示索引出第一行的数据。df.loc[‘ a’]是按标签索引,而iloc只能通过行号索引,df.iloc[0]是对的,而df.iloc[‘a’]是错误的。详细见如下博客。
https://www.cnblogs.com/ghllfl/p/8481576.html
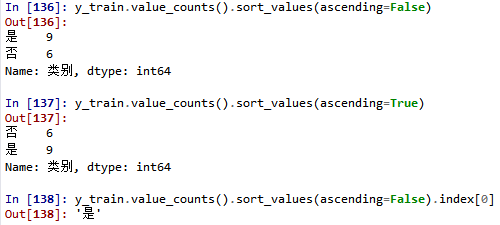
82. value_counts()是查看表格中某列有多少个不同值的方法,并返回对应的个数。.sort_values(ascending=False)是将数据从大到小排列。
附:1.简历模板网址:https://www.zhihu.com/question/49065128
数据分析软件SPSS链接:https://pan.baidu.com/s/1pfGuDzfpLSubQwPCPQbHmA 密码:0d4k
1)MXNet:基于神经网络的深度学习的计算框架,python的第三方库

2)Panda3D


 浙公网安备 33010602011771号
浙公网安备 33010602011771号